







之前快代理都是直接发在网页源码中的,现在它做了一点改变,将ip信息使用js进行填充,将ip信息放到网页中去的
一、对网站进行解析
首先我们使用的是chrom浏览器自带的抓包工具
在进入快代理的网页之后,右键点击,在弹出胡选项框中点击查看网页源代码,然后我们在原网页中复制一条ip在网页源代码使用ctrl+F进行查找,我们可以发现数据出现在js当中
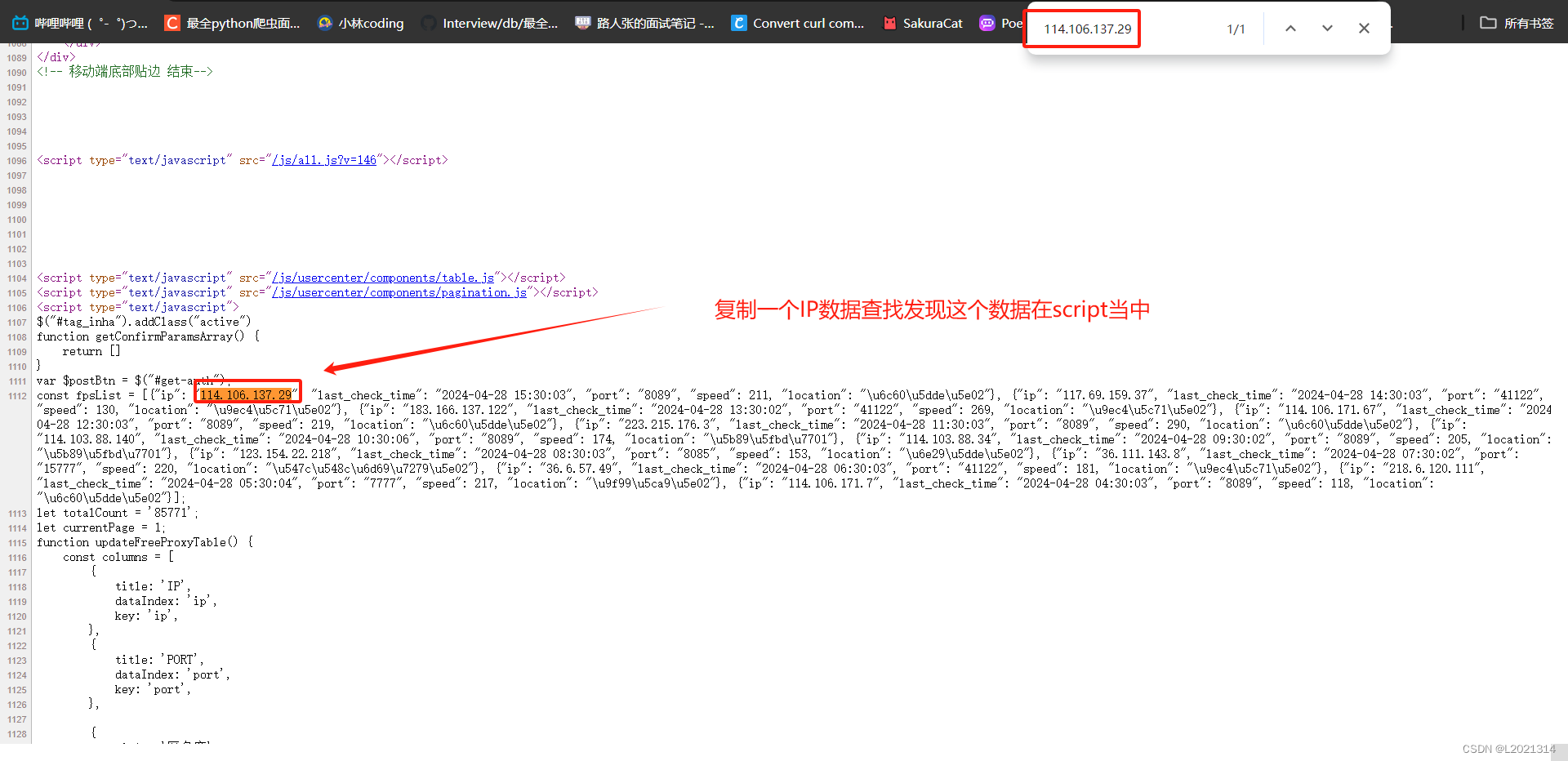
由于我们需要的数据在script当中,所以这时候使用正则表达式进行提取我们所需要的信息是比较方便的。
二、代码编写
思路分析
-
第一步:构造主页url地址,发送请求获取响应
-
第二步:解析数据
-
第三步:将数组的数据提取出来
-
第四步:检测代理IP的可用性
-
第五步:保存到文件中
第一步:构造主页url地址,发送请求获取响应
1.发送请求,获取响应
def send_request(self, page):
print("正在抓取第{}页".format(page))
# 目标网页,添加headers参数
base_url = 'https://www.kuaidaili.com/free/inha/{}/'.format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









