






文章目录
爬虫第一天
1.准备工作
首先,肯定是得先下载好python,PyCharm
接着,在网上找找如何配置一个相对舒服的编码环境
下载库’requests’
打开我们的PyCharm然后在终端输入 `python -m pip install requests`回车,
等待库的下载下载以后我们就可以开始了。
2.开爬
目标网址的查找
这需要我们找到我们的目标网址,我是用的是edge浏览器,因为能力有限先以我的浏览器为例。
找到一个网址,为了防止侵犯到网站作者的权益,下面的我仅仅会截图一点重要的点。
老师教的第一次爬的是一些照片,先找到目标照片所在的网址,然后右键点检查
接着点击那个网络按钮,找不到的话就是那个WiFi的标志,为了更加清晰和防止其他无关数据影响我们,可以先点左上角第二个的禁止标志,然后我们往下面拉出来类似中括号的就是我们需要找的目标by_search....然后那个请求url就是我们的目标网址,老师讲的是这个链接有一部分是无关紧要的可以不用放到我们的url里面。

接着就是放到我们的小爬虫代码里面
先导入我们的一些库文件,接着把我们的目标网址放到一个url的字符串里面
from urllib.request import urlretrieve
import requests
# 1. 目标网址
url = 'https://www.duitang.com/napi/blogv2/list/by_search/?kw=一二&after_id=0&type=feed'
可以看到只截取了我们上一个图片的请求url的一部分,kw=与=之间的部分就是我们想要爬取的目标内容范围。
模拟浏览器发生请求,接收返回响应内容
这就开始使用我们刚开始说的那个库文件
# 2. 模拟浏览器发生请求,接收返回响应内容
response = requests.get(url)
data = response.json()
解析网页内容,提取数据
如果我们这时候直接把我们的data打印出来我们就得到这些
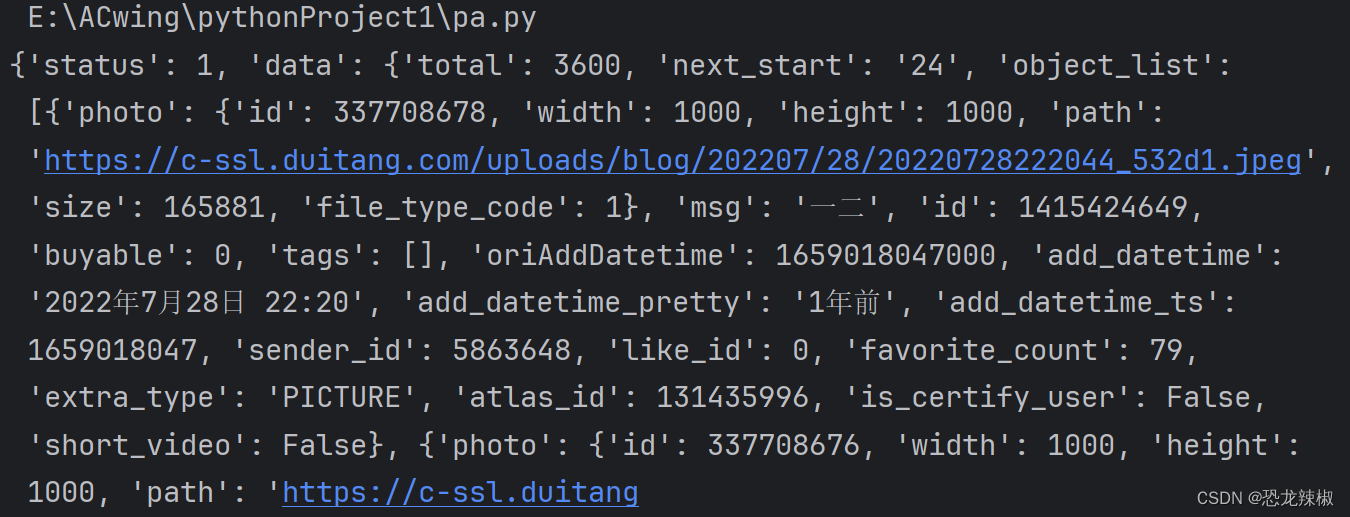
这些当然不是我们想要的照片,这就需要我们对信息进行提取,与对图片的下载使用urlretrieve函数
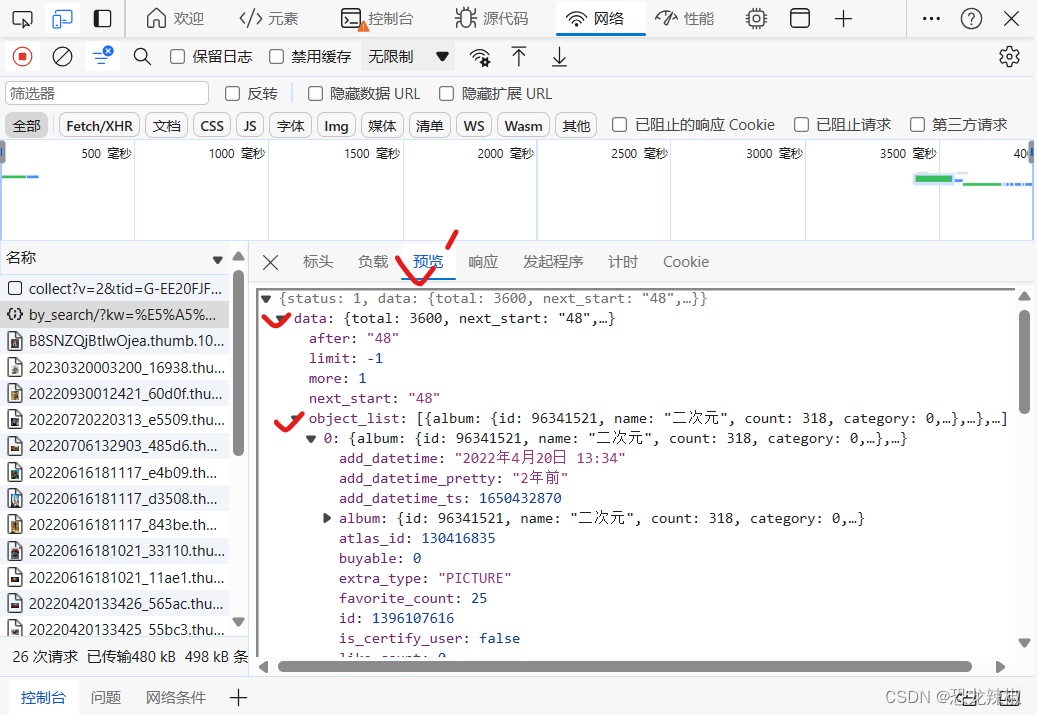
接着就是我们需要找我们想要的东西的位置,位置在预览–>data–>object_list里面所以在我们题去的时候就有我们的目标了
# 3. 解析网页内容,提取数据
num = 1
for i in data['data']['object_list']:
link = i['photo']['path']
# 4. 数据保存
urlretrieve(link,'img/{}.png'.format(num))
print('第{}张图片下载完成'.format(num))
num += 1
因为网站不可能一张照片把所有的数据都放到一个页面,就像我们在手机上看小说一样,
我们一直往下拉一直会有,其实本质上是我们再快拉到底的时候下一个页面就会加载出来,
让我们接连不断的能一直的阅读下去。
以上方法是只能爬取一页包含的所有图片的内容,要想爬取多页的更多的内容,那只需要把我们最初的那个URL的最后给改改数字,数字几就代表是第几页,当然也是可以找规律的,这个方法就是我们在找我们的目标网址的时候多往下滑一滑,就会出现多个by_search....我们可以发现有绝大的一部分是相同的,不同的是末尾的那几个数字。就是字符串的操作,爬完一页接着改一下url那个目标网址字符串的页码部分,当然一个for循环就可以了。
------------------------------------------分界线-------------------------------------------
下面的是我学的爬取的文本数据
我们需要把他转换为手机的试图。

接着还是刚才的方法
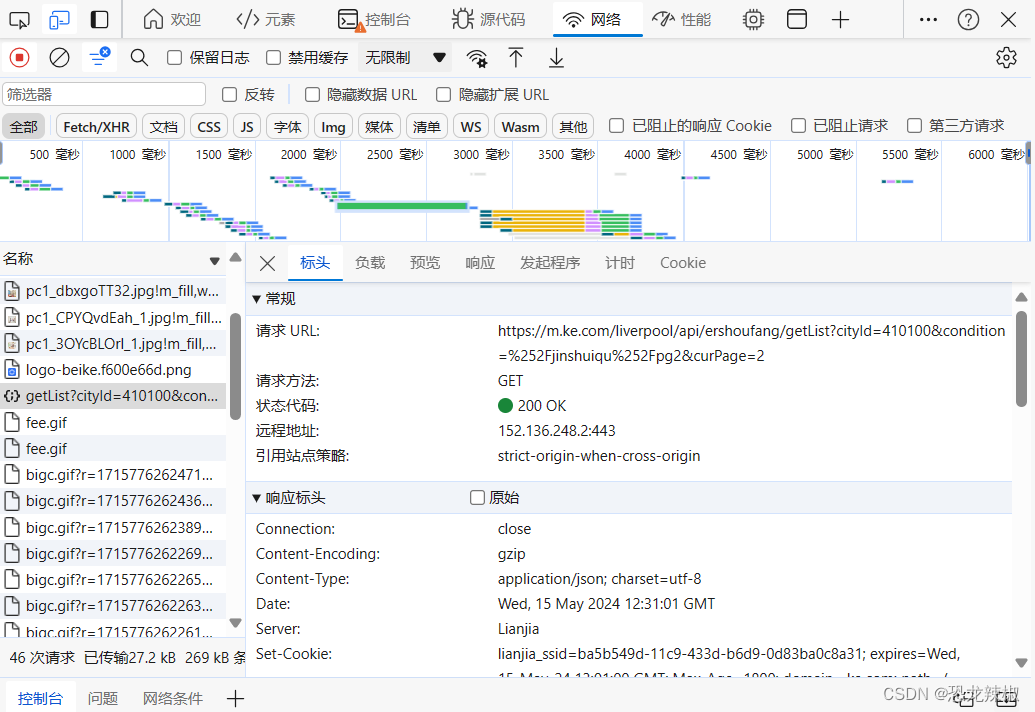
接着就是我们对目标网址的寻找
找到以后我们就开始了
from urllib.request import urlretrieve
import requests
import csv
#用来存放我们的数据以方便我们存放
data_list= []
下面的直接上代码,一些注释掉的代码是老师留下的作业,因为老师的方法最优所以我就换成了老师的方法,把我的方法注释掉了(我直接使用文件处理把数据放到一个记事本里面,老师的方法是直接放到了一个表格里面)。
from urllib.request import urlretrieve
import requests
import csv
data_list= []
for pg in range(0,10):
# 1. 目标网址
url='https://m.ke.com/liverpool/api/ershoufang/getList?cityId=410100&condition=%252Fzhongyuanqu1%252Fl1pg'+'pg'+'&curPage'+'pg'
# url = 'https://m.ke.com/liverpool/api/ershoufang/getList?cityId=410100&condition=%252Fjinshuiqu%252Fl1pg'+'pg'+'&curPage'+'pg'
# 2. 模拟浏览器发生请求,接收返回响应内容
#请求头
headers={
#用户代理
'User-Agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 Mobile/15E148 Safari/604.1 Edg/124.0.0.0'
}
resp = requests.get(url,headers=headers)
data = resp.json()
num=1
#3- 解析提取数据
for i in data['data']['data']['getErShouFangList']['list']:
item = {}
item['标题']= i['title']
item['单价'] = i['unitPrice']
item['总价'] = i['totalPrice']
item['区域详情'] = i['recoDesc']
item['区域位置'] = i['desc']
data_list.append(item)
# Title =i['title']
# UnitPrice=i['unitPrice']
# TotalPrice=i['totalPrice']
# RecoDesc=i['recoDesc']
# Desc=i['desc']
# filename = 'text1/{}.text'.format(num)
# with open(filename ,'w',encoding='utf-8')as f :
# f.write('Title:{}:\n'.format("标题"))
# num+=1
# 4- 保存数据
f=open('郑州二手房.csv','w',encoding='utf-8-sig',newline='')
#创建写入对象
writer=csv.DictWriter(f,fieldnames=['标题','单价','总价','区域详情','区域位置'])
#写入列名称
writer.writeheader()
#写入数据
writer.writerows(data_list)
后面 是可视化界面的实现,因为我们总合到一起的文件数据太多不方便读取,所以就需要用到另一个东西,pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple然后找到对应的文件在我的电脑的位置,在上边输入cmd进入然后输入jupyter notebook进入我们的可视化界面,有的是会直接弹出进入一个浏览器界面,有的是需要在cmd里面找到一个网址,手动的复制到浏览器上打开。
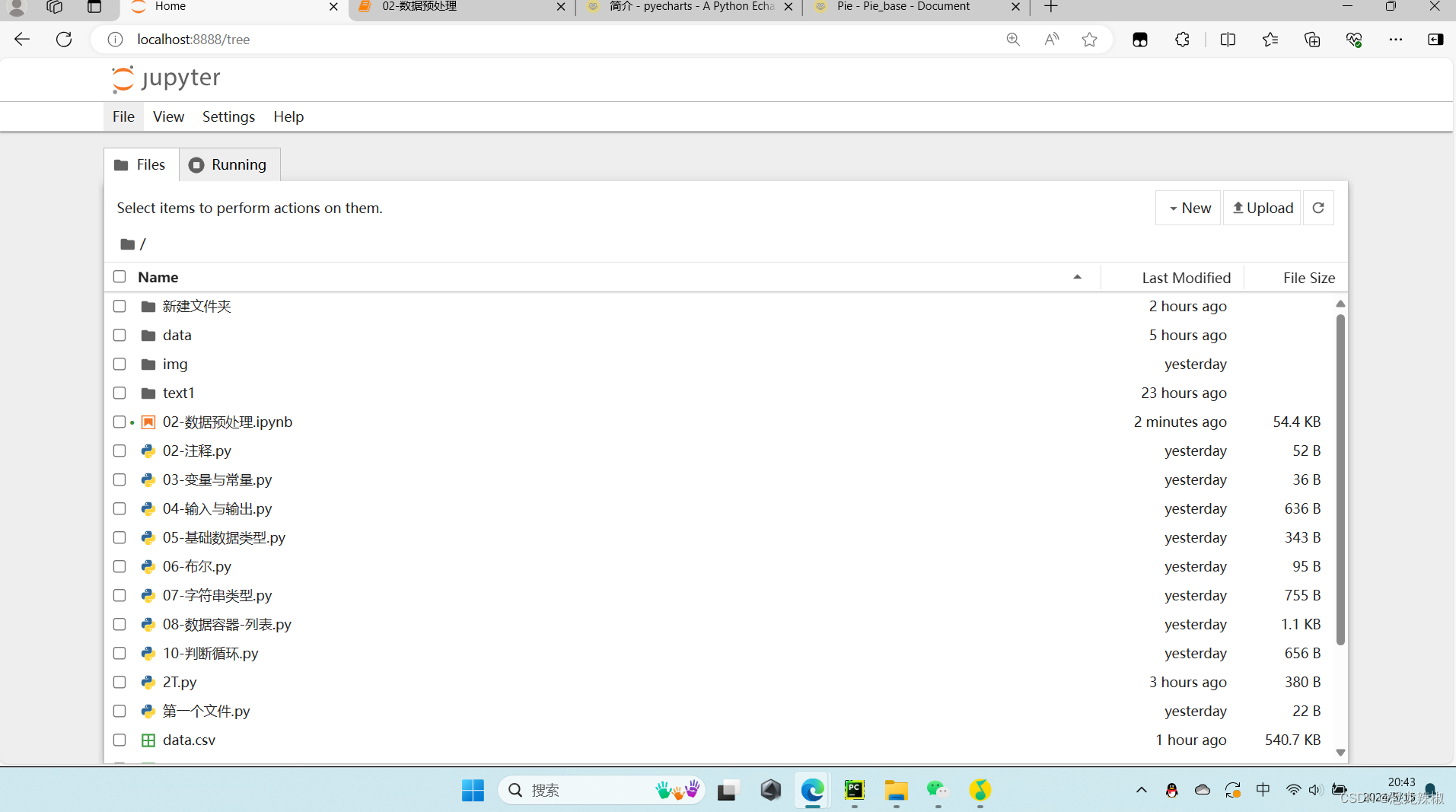
打开以后就是这样的,接着我们点击New创建一个新的python3的文件
import numpy as np
import pandas as pd
加载数据
df = pd.read_csv('data(2).csv',encoding='utf-8-sig')
df
数据清洗
df.info()
# 缺失值
df.isnull().sum()
#重复值监测
df.duplicated().sum()
df['区域'] = df ['区域位置'].apply(lambda x:x.split(' ')[0])
df['小区'] = df ['区域位置'].apply(lambda x:x.split(' ')[1].split('/')[0])
#df['楼层'] = df ['区域位置'].apply(lambda x:x.split('/')[-2].split(' ')[-1][1:-1])
df['楼层'] = df ['区域位置'].apply(lambda x:x.split('/')[1].split(' ')[0])
# 数据的整理
df['户型']= df ['详情'].apply(lambda x:x.split('/')[0])
df['面积']= df ['详情'].apply(lambda x:x.split('/')[1])
df['朝向']= df ['详情'].apply(lambda x:x.split('/')[2])
df
#删除数据( 默认行,列为axis=1)
df = df.drop({'区域位置','详情'},axis=1)
df
#更改数据类型
df['总价']=df['总价'].str[:-1].astype(float)
df
#更改数据类型
df['单价']=df['单价'].str.replace(',','').str[:-3].astype(float)
df.head()
#平均总价
df['总价'].mean()
#平均单价
df['单价'].mean()
df['户型'].value_counts()
df['区域'].value_counts()
df.groupby('区域')[('单价')].mean()
#增加视图
pip install pyecharts















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









