







一、平移变换
假定有一个点的坐标是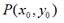 ,将其移动到
,将其移动到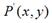 ,再假定在x轴和y轴方向移动的大小分别为:
,再假定在x轴和y轴方向移动的大小分别为:
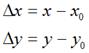
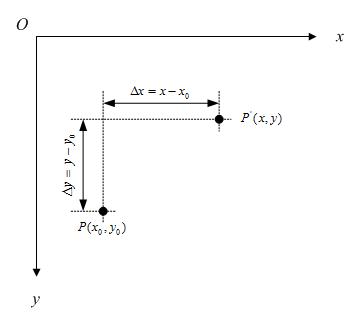
不难知道:
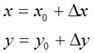
如果用矩阵来表示的话,就可以写成:
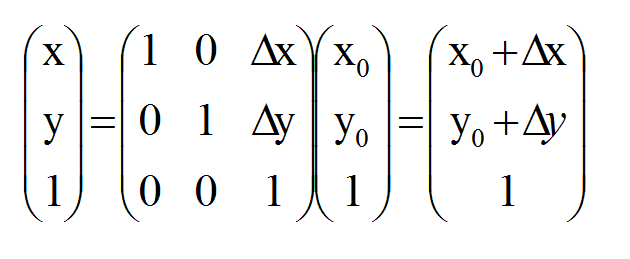
二、旋转变换
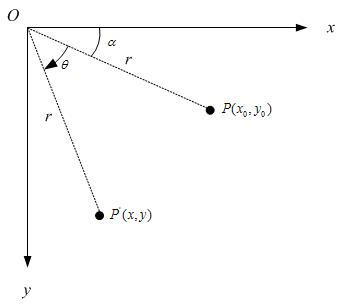
围绕坐标原点旋转
假定有一个点 ,相对坐标原点顺时针旋转 后的情形,同时假定P点离坐标原点的距离为r,如下图:
后的情形,同时假定P点离坐标原点的距离为r,如下图:
那么,
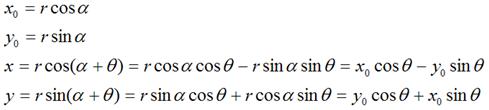
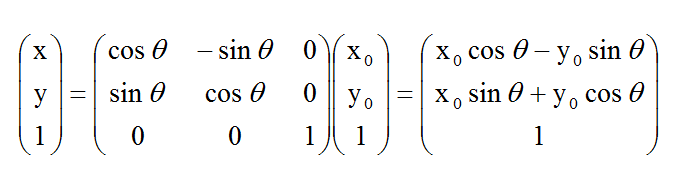
围绕某个点旋转
如果是围绕某个点 顺时针旋转,那么可以用矩阵表示为:
顺时针旋转,那么可以用矩阵表示为:
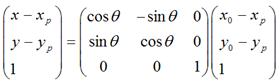
可以化为:
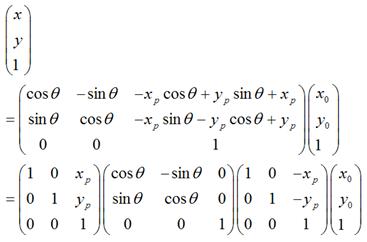
很显然,
1.
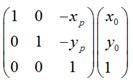 是将坐标原点移动到点后, 的新坐标。
是将坐标原点移动到点后, 的新坐标。
2.
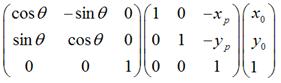
是将上一步变换后的,围绕新的坐标原点顺时针旋转 。
3.
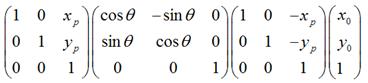
经过上一步旋转变换后,再将坐标原点移回到原来的坐标原点。
所以,围绕某一点进行旋转变换,可以分成3个步骤,即首先将坐标原点移至该点,然后围绕新的坐标原点进行旋转变换,再然后将坐标原点移回到原先的坐标原点。
三、缩放变换
理论上而言,一个点是不存在什么缩放变换的,但考虑到所有图像都是由点组成,因此,如果图像在x轴和y轴方向分别放大k1和k2倍的话,那么图像中的所有点的x坐标和y坐标均会分别放大k1和k2倍,即
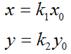
用矩阵表示就是:

缩放变换比较好理解,就不多说了。
四、错切变换
错切变换(skew)在数学上又称为Shear mapping(可译为“剪切变换”)或者Transvection(缩并),它是一种比较特殊的线性变换。错切变换的效果就是让所有点的x坐标(或者y坐标)保持不变,而对应的y坐标(或者x坐标)则按比例发生平移,且平移的大小和该点到x轴(或y轴)的垂直距离成正比。错切变换,属于等面积变换,即一个形状在错切变换的前后,其面积是相等的。
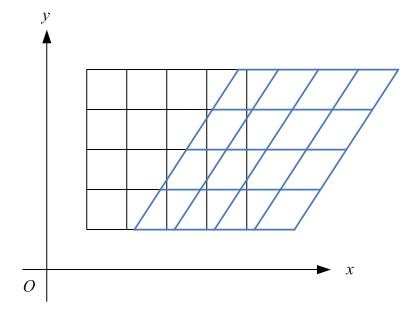
比如下图,各点的y坐标保持不变,但其x坐标则按比例发生了平移。这种情况将水平错切。
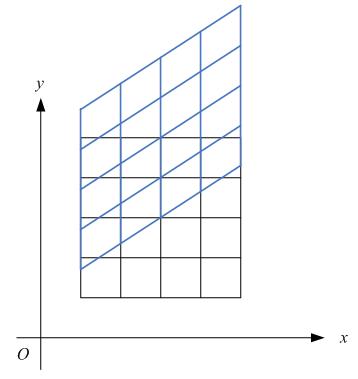
下图各点的x坐标保持不变,但其y坐标则按比例发生了平移。这种情况叫垂直错切。
假定一个点经过错切变换后得到,对于水平错切而言,应该有如下关系:
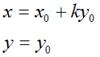
用矩阵表示就是:
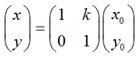
扩展到3 x 3的矩阵就是下面这样的形式:
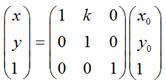
同理,对于垂直错切,可以有:
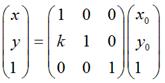
在数学上严格的错切变换就是上面这样的。在Android中除了有上面说到的情况外,还可以同时进行水平、垂直错切,那么形式上就是:

五、对称变换
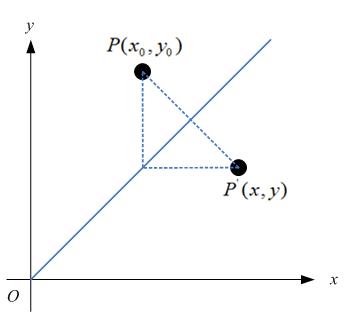
除了上面讲到的4中基本变换外,事实上,我们还可以利用Matrix,进行对称变换。所谓对称变换,就是经过变化后的图像和原图像是关于某个对称轴是对称的。比如,某点 经过对称变换后得到,
如果对称轴是x轴,难么,
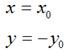
用矩阵表示就是:
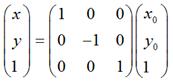
如果对称轴是y轴,那么,
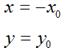
用矩阵表示就是:
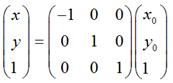
如果对称轴是y = x,如图:
那么,
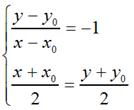
很容易可以解得:
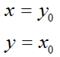
用矩阵表示就是:
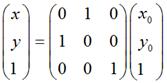
同样的道理,如果对称轴是y = -x,那么用矩阵表示就是:
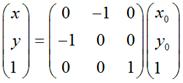
特殊地,如果对称轴是y = kx,如下图:
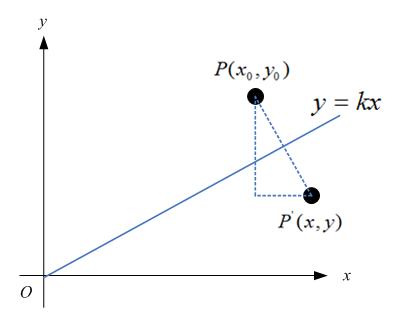
那么,
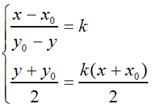
很容易可解得:
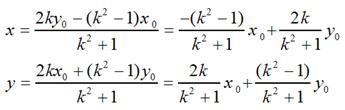
用矩阵表示就是:
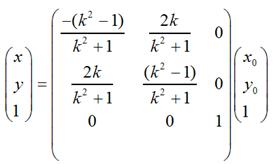
当k = 0时,即y = 0,也就是对称轴为x轴的情况;当k趋于无穷大时,即x = 0,也就是对称轴为y轴的情况;当k =1时,即y = x,也就是对称轴为y = x的情况;当k = -1时,即y = -x,也就是对称轴为y = -x的情况。不难验证,这和我们前面说到的4中具体情况是相吻合的。
如果对称轴是y = kx + b这样的情况,只需要在上面的基础上增加两次平移变换即可,即先将坐标原点移动到(0, b),然后做上面的关于y = kx的对称变换,再然后将坐标原点移回到原来的坐标原点即可。用矩阵表示大致是这样的:
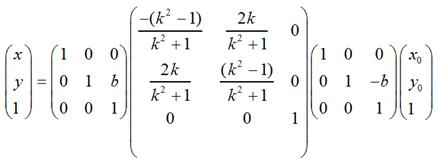
需要特别注意:在实际编程中,我们知道屏幕的y坐标的正向和数学中y坐标的正向刚好是相反的,所以在数学上y = x和屏幕上的y = -x才是真正的同一个东西,反之亦然。也就是说,如果要使图片在屏幕上看起来像按照数学意义上y = x对称,那么需使用这种转换:
要使图片在屏幕上看起来像按照数学意义上y = -x对称,那么需使用这种转换:
关于对称轴为y = kx 或y = kx + b的情况,同样需要考虑这方面的问题。
public class MatrixActivity extends GraphicsActivity implements
OnTouchListener {
private TransformMatrixView view;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
view = new TransformMatrixView(this);
view.setScaleType(ImageView.ScaleType.MATRIX);
view.setOnTouchListener(this);
setContentView(view);
}
class TransformMatrixView extends ImageView
{
private Bitmap bitmap;
private Matrix matrix;
public TransformMatrixView(Context context)
{
super(context);
bitmap = BitmapFactory.decodeResource(getResources(), R.drawable.image01);
matrix = new Matrix();
}
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
canvas.drawBitmap(bitmap, 0, 0, null);
canvas.drawBitmap(bitmap, matrix, null);
}
@Override
public void setImageMatrix(Matrix matrix) {
this.matrix.set(matrix);
super.setImageMatrix(matrix);
}
public Bitmap getImageBitmap() {
return bitmap;
}
}
private void showMatrixEveryValue(Matrix matrix){
Log.d("TransformMatrixView", matrix.toString());
}
public boolean onTouch(View v, MotionEvent e) {
if(e.getAction() == MotionEvent.ACTION_UP){
Matrix matrix = new Matrix();
//1.简单的平移
//matrix.postTranslate(view.getImageBitmap().getWidth(), view.getImageBitmap().getHeight());
// 2. 旋转(围绕图像的中心点)
//matrix.setRotate(45f, view.getImageBitmap().getWidth() / 2f, view.getImageBitmap().getHeight() / 2f);
// 做下面的平移变换,纯粹是为了让变换后的图像和原图像不重叠
//matrix.postTranslate(view.getImageBitmap().getWidth() * 1.5f, 0f);
// 3. 旋转(围绕坐标原点) + 平移(效果同2)
//matrix.setRotate(45f);
//matrix.preTranslate(-1f * view.getImageBitmap().getWidth() / 2f, -1f * view.getImageBitmap().getHeight() / 2f);
//matrix.postTranslate((float)view.getImageBitmap().getWidth() / 2f, (float)view.getImageBitmap().getHeight() / 2f);
// 做下面的平移变换,纯粹是为了让变换后的图像和原图像不重叠
//matrix.postTranslate((float)view.getImageBitmap().getWidth() * 1.5f, 0f);
// 4. 缩放
//matrix.setScale(2f, 2f);
// 做下面的平移变换,纯粹是为了让变换后的图像和原图像不重叠
//matrix.postTranslate(view.getImageBitmap().getWidth(), view.getImageBitmap().getHeight());
// 5. 错切 - 水平
//matrix.setSkew(0.5f, 0f);
// 做下面的平移变换,纯粹是为了让变换后的图像和原图像不重叠
//matrix.postTranslate(view.getImageBitmap().getWidth(), 0f);
// 6. 错切 - 垂直
//matrix.setSkew(0f, 0.5f);
// 做下面的平移变换,纯粹是为了让变换后的图像和原图像不重叠
//matrix.postTranslate(0f, view.getImageBitmap().getHeight());
//7. 错切 - 水平 + 垂直
//matrix.setSkew(0.5f, 0.5f);
// 做下面的平移变换,纯粹是为了让变换后的图像和原图像不重叠
//matrix.postTranslate(0f, view.getImageBitmap().getHeight());
// 8. 对称 (水平对称)
//float matrix_values[] = {
// 1f, 0f, 0f,
// 0f, -1f, 0f,
// 0f, 0f, 1f};
//matrix.setValues(matrix_values);
// 做下面的平移变换,纯粹是为了让变换后的图像和原图像不重叠
//matrix.postTranslate(0f, view.getImageBitmap().getHeight() * 2f);
// 9. 对称 (垂直对称)
//float matrix_values[] = {-1f, 0f, 0f, 0f, 1f, 0f, 0f, 0f, 1f};
//matrix.setValues(matrix_values);
// 做下面的平移变换,纯粹是为了让变换后的图像和原图像不重叠
//matrix.postTranslate(view.getImageBitmap().getWidth() * 2f, 0f);
// 10. 对称(对称轴为直线y = x)
float matrix_values[] = {0f, -1f, 0f, -1f, 0f, 0f, 0f, 0f, 1f};
matrix.setValues(matrix_values);
// 做下面的平移变换,纯粹是为了让变换后的图像和原图像不重叠
matrix.postTranslate(view.getImageBitmap().getHeight() + view.getImageBitmap().getWidth(),
view.getImageBitmap().getHeight() + view.getImageBitmap().getWidth());
view.setImageMatrix(matrix);
showMatrixEveryValue(matrix);
view.invalidate();
}
return true;
}
}
参考:http://www.cnblogs.com/qiengo/archive/2012/06/30/2570874.html#code















 2146
2146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









