







编码与字符集
什么把这个专题放在这,因为DataInputStream与DataOutputStream里有个
readUTF()或writeUTF(String str)方法。
由于这方面的内容我看的资料还有限,难免出错,看到下面的内容后自己去找资料证实。不要相信别人的话,要自己求证。以下内容仅供参考
编码和字符集不是一个概念,字符集表示码点与字符之间的映射关系,至于怎么存储,字符集也不关心,具体存储交给编码,但是编码要依赖于字符集。
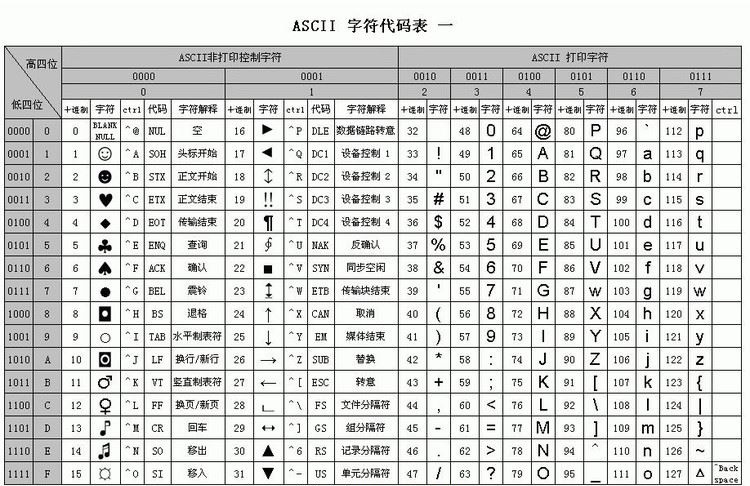
ASCII码
用一个字节存储字符,但是只用了7位,即27 = 128个字符
ASCII表上的数字0–31分配给了控制字符,用于控制像打印机等一些外围设备。
数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。
数字127代表 DELETE 命令。
扩展ASCII
扩展的ASCII字符满足了对更多字符的需求。扩展的ASCII包含ASCII中已有的128个字符(数字0–32显示在下图中),又增加了128个字符,总共是256个。即使有了这些更多的字符,许多语言还是包含无法压缩到256个字符中的符号。因此,出现了一些ASCII的变体来囊括地区性字符和符号。例如,许多软件程序把ASCII表(又称作ISO8859-1)用于北美、西欧、澳大利亚和非洲的语言。
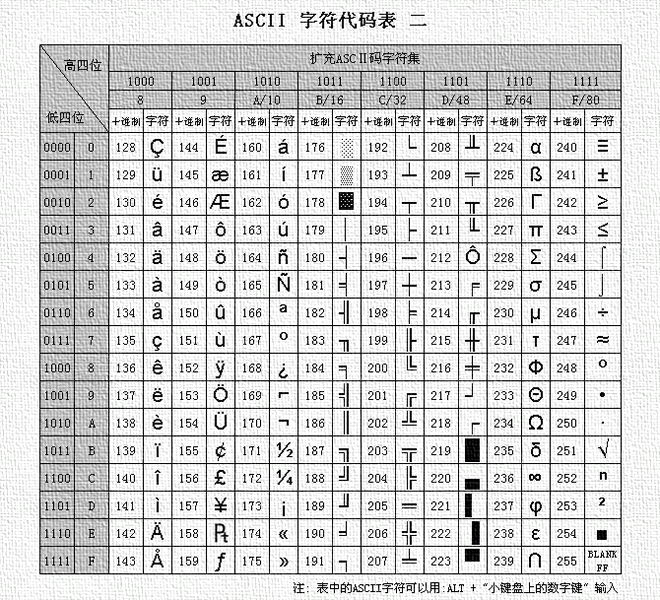
因为ASCII就一套,ASCII字符集也可以叫ASCII编码
Unicode字符集及其以Unicode字符集的编码
Unicode字符集下有多个编码方案UTF-8、UTF-16、UTF-32.
1.Unicode并不涉及字符是怎么在字节中表示的,它仅仅指定了字符对应的数字
2.Unicode只是一个用来映射字符和数字的标准。它对支持字符的数量没有限制,也不要求字符必须占两个、三个或者其它任意数量的字节。
3.目前Unicode码点的范围是U+0000~U+10FFFF。U+10FFFF是多大呢?大概是111万,按Unicode官方的说法,就这样了,以后也不扩充了,一百多万足够用了,目前也只是定义了10万多个字符左右
Unicode的范围目前是U+0000~U+10FFFF,理论大小为10FFFF+1=11000016。后一个1代表是65536,因为是16进制,所以前一个1是后一个1的16倍,所以总共有1×16+1=17个的65536的大小,粗略估算为17×6万=102万,所以这是一个百万级别的数。
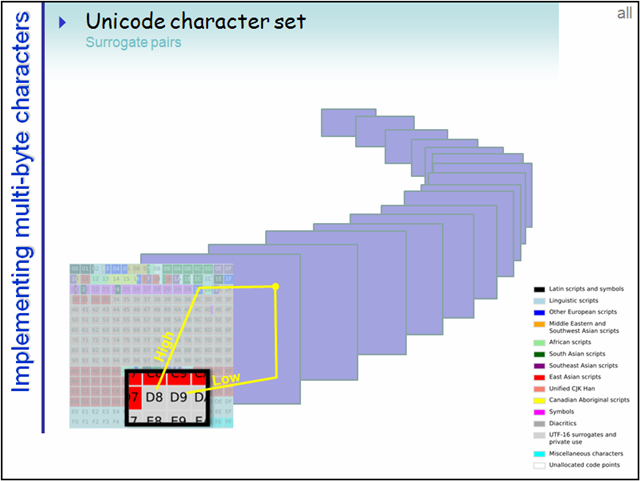
为了更好分类管理如此庞大的码点数,把每65536个码点作为一个平面,总共17个平面。
平面,BMP,SP
码点的全部范围可以均分成17个65536大小的部分,这里面的每一个部分就是一个平面(Plane)。编号从0开始,第一个平面称为Plane 0.
下图来自http://rishida.net/docs/unicode-tutorial/part2
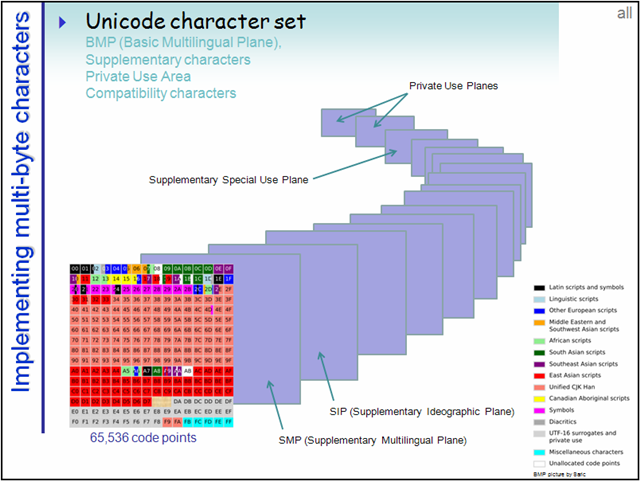
第一个平面即是BMP(Basic Multilingual Plane 基本多语言平面),也叫Plane 0,它的码点范围是U+0000~U+FFFF。这也是我们最常用的平面,日常用到的字符绝大多数都落在这个平面内。
UTF-16只需要用两字节编码此平面内的字符。
后续的16个平面称为SP(Supplementary Planes,增补平面)。显然,这些码点已经是超过U+FFFF的了,所以已经超过了16位空间的理论上限,对于这些平面内的字符,UTF-16采用了四字节编码。
其中很多平面还是空的,还没有分配任何字符,只是先规划了这么多。
另:有些还属于私有的,如上图中的最后两个Private Use Planes,在此可自定义字符。
BMP平面
下图来自:http://unifoundry.com/pub/unifont-7.0.03/unifont-7.0.03.bmp

正则表达式[\u4E00-\u9FA5]来匹配中文位置,严格来说这只是Unicode最主要的一段中文区域。
有的中文也落在了增补平面内。
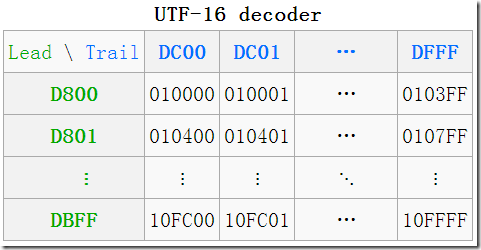
代理区

BMP缩略图中有一片空白,这就是所谓的代理区(Surrogate Area)
可以看到这段空白从D8~DF。其中D800–DBFF属于高代理区(High Surrogate Area),后面的DC00–DFFF属于低代理区(Low Surrogate Area),各自的大小均为4×256=1024。
还可以看到在它之前是韩文的区域,之后E0开始到F8的则是属于私有的(private),可以在这里定义自己专用的字符。
至此我们对Unicode的码点,平面都有了一定的了解,但我们还没有触及一个重要的方面,那就是码点到最终编码的转换,在Unicode中,这称为UTF。
UTF-32
我们说码点最大的10FFFF也就21位,而UTF-32采用的定长四字节则是32位,所以它表示所有的码点不但毫无压力,反而绰绰有余,所以只要把码点的表示形式以前补0的形式补够32位即可。这种表示的最大缺点是占用空间太大。
再来看稍复杂一点的UTF-8。
UTF-8
UTF-8是变长的编码方案,可以有1,2,3,4四种字节组合。在前面的定长与变长篇章我们提到UTF-8采用了高位保留方式来区别不同变长,如下:
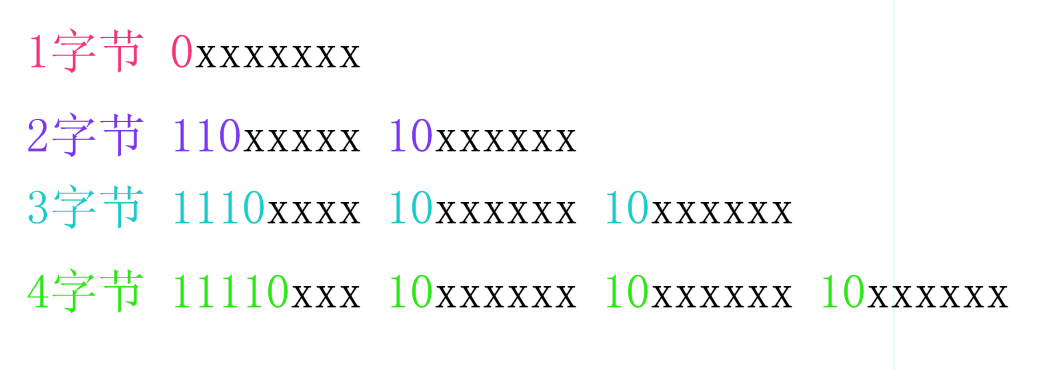
码点与字节如何对应?
哪些码点用哪种变长呢?可以先把码点变成二进制,看它有多少有效位(去掉前导0)就可以确定了。
- 一字节有效编码位有7位,27=128,码点U+0000~U+007F(0~127)使用一字节。
一字节留给了ASCII,所以UTF-8兼容ASCII。
- 二字节有效编码位只有5+6=11位,最多只有211=2048个编码空间,所以数量众多的汉字是无法容身于此的了。码点U+0080~U+07FF(128~2047)使用二字节。
注意:这里码点从128~2047,因为去掉了一字节的码点,所以不会占满2048个编码空间,是有冗余的,但你不能把适用于一字节的码点放到这里来编码。下同。
- 三字节模式可看到光是保留位就达到4+2+2=8位,相当一字节,所以只剩下两字节16位有效编码位,它的容量实际也只有65536。码点U+0800~U+FFFF(2048~65535)使用三字节编码。
一些汉字字典收录的汉字达到了惊人的10万级别。基本上,常用的汉字都落在了这三字节的空间里,这就是我们常说的汉字在UTF-8里用三字节表示。当然了,这么说并不严谨,如果这10万的汉字都被收录进来的话,那些偏门的汉字自然只能被挤到四字节空间上去了。
- 四字节的可以看到它的有效位是3+6+6+6=21位,前面说到最大的码点10FFFF也是21位,U+FFFF以上的增补平面的字符都在这里来表示。
UTF-16
UTF-16是一种变长的2或4字节编码模式。对于BMP内的字符使用2字节编码,其它的则使用4字节组成所谓的代理对来编码。
代理区是UTF-16为了编码增补平面中的字符而保留的,总共有2048个位置,均分为高代理区(D800–DBFF)和低代理区(DC00–DFFF)两部分,各1024,这两个区组成一个二维的表格,共有1024×1024=210×210=24×216=16×65536,所以它恰好可以表示增补的16个平面中的所有字符。
下面的图片来自wiki
下图来自http://rishida.net/docs/unicode-tutorial/part2
FilterOutputStream与FilterInputStream
这两个都分别是InputStream和OutputStream的子类。也是DataInputStream与DataOutputStream的父类,而且,FilterInputStream和FilterOutputStream是具体的子类,实现了InputStream和OutputStream这两个抽象类中为给出实现的方法。
但是,FilterInputStream和FilterOutputStream仅仅是“装饰者模式”封装的开始,它们在各个方法中的实现都是最基本的实现,都是基于构造方法中传入参数封装的InputStream和OutputStream的原始对象。
比如,在FilterInputStream类中,封装了这样一个属性
protected volatile InputStream in;
而对应的构造方法是:
protected FilterInputStream(InputStream in) {
this.in = in;
}
read()方法的实现则为:
public int read() throws IOException {
return in.read();
}
其它方法的实现,以及FilterOutputStream也都是同理类似的。
我们注意到FilterInputStream和FilterOutputStream并没给出其它额外的功能实现,只是做了一层简单地封装。那么实现额外功能的实际是FilterInputStream和FilterOutputStream的各个子类。
DataInputStream与DataOutputStream
这也是比较重要的一对Filter实现。那么说起功能,实际上就不得不提到他们除了extends FilterInputStream/FilterOutputStream外,还额外实现了DataInput和DataOutput接口。
我们可以先来看下DataInput和DataOutput这两个interface。
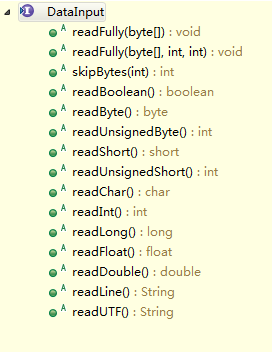

而DataInputStream/DataOutputStream这一对实际上所做的也就是这两个接口所定义的方法。再DataInputStream/DataOutputStream中,这些方法做了拼接和拆分字节的工作。通过这些方法,我们可以方便的读取、写出各种我们实际所面对的类型的数据,而不必具体去在字节层面上做细节操作。
public class DataInputStream extends FilterInputStream implements DataInput
public
class DataInputStream extends FilterInputStream implements DataInput {
//in:数据源
public DataInputStream(InputStream in) {
super(in);
}
//字节数组,80字节,当我们readUTF时,先不解码,直接把数据存进bytearr里,若果超过80,重新new一个更大的
private byte bytearr[] = new byte[80];
//上面的是原始数据字节,chararr是经过解码后的数据,若果超过80,重新new一个更大的
private char chararr[] = new char[80];
//把数据读进b[]数组里,循环读取,一个一个字节的读
public final int read(byte b[]) throws IOException {
return in.read(b, 0, b.length);
}
//把数据从b[]数组的off位置读进len个长度的字节,循环读取,一个一个字节的读
public final int read(byte b[], int off, int len) throws IOException {
return in.read(b, off, len);
}
//一次读取最多b.length个字节到b[]数组里
public final void readFully(byte b[]) throws IOException {
readFully(b, 0, b.length);
}
//一次读取最多len个字节到b[]数组里,偏移值off
//该方法与read(byte b[], int off, int len)签名很像,但是read是一个一字节(可能会出现循环)的读,readFully是整个数据块读
public final void readFully(byte b[], int off, int len) throws IOException {
if (len < 0)
throw new IndexOutOfBoundsException();
int n = 0;
while (n < len) {
int count = in.read(b, off + n, len - n);
if (count < 0)
throw new EOFException();
n += count;
}
}
//跳过多少字节,返回值是实际跳过多少字节取值范围[0,n]
public final int skipBytes(int n) throws IOException {
int total = 0;
int cur = 0;
//
while ((total<n) && ((cur = (int) in.skip(n-total)) > 0)) {
total += cur;
}
return total;
}
//读取一个boolean值,占据一个字节
public final boolean readBoolean() throws IOException {
int ch = in.read();
if (ch < 0)
throw new EOFException();
return (ch != 0);
}
//读取一个字节
public final byte readByte() throws IOException {
int ch = in.read();
if (ch < 0)
throw new EOFException();
return (byte)(ch);
}
//读取一个无符号的字节
public final int readUnsignedByte() throws IOException {
int ch = in.read();
if (ch < 0)
throw new EOFException();
return ch;
}
//读取一个short型 2个字节,分2步读取一个字节,然后把这2个字节合并,强转short
public final short readShort() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
if ((ch1 | ch2) < 0)
throw new EOFException();
return (short)((ch1 << 8) + (ch2 << 0));
}
//读取一个无符号short型 2个字节,分2步读取一个字节,然后把这2个字节合并
public final int readUnsignedShort() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
if ((ch1 | ch2) < 0)
throw new EOFException();
return (ch1 << 8) + (ch2 << 0);
}
//读取一个char ,2个字节,然后把这2个字节合并,强转char
public final char readChar() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
if ((ch1 | ch2) < 0)
throw new EOFException();
return (char)((ch1 << 8) + (ch2 << 0));
}
//读取一个int ,4字节,然后把这4个字节合并
public final int readInt() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return ((ch1 << 24) + (ch2 << 16) + (ch3 << 8) + (ch4 << 0));
}
//readLong(),readDouble() 时的缓冲区
private byte readBuffer[] = new byte[8];
//一次性读取一个long型值 ,8字节,然后把这8个字节合并
public final long readLong() throws IOException {
readFully(readBuffer, 0, 8);
return (((long)readBuffer[0] << 56) +
((long)(readBuffer[1] & 255) << 48) +
((long)(readBuffer[2] & 255) << 40) +
((long)(readBuffer[3] & 255) << 32) +
((long)(readBuffer[4] & 255) << 24) +
((readBuffer[5] & 255) << 16) +
((readBuffer[6] & 255) << 8) +
((readBuffer[7] & 255) << 0));
}
//读取一个float型的值,4字节
public final float readFloat() throws IOException {
return Float.intBitsToFloat(readInt());
}
//读取一个double型的值,8字节
public final double readDouble() throws IOException {
return Double.longBitsToDouble(readLong());
}
private char lineBuffer[];
@Deprecated
public final String readLine() throws IOException {
char buf[] = lineBuffer;
if (buf == null) {
buf = lineBuffer = new char[128];
}
int room = buf.length;
int offset = 0;
int c;
loop: while (true) {
switch (c = in.read()) {
case -1:
case '\n':
break loop;
case '\r':
int c2 = in.read();
if ((c2 != '\n') && (c2 != -1)) {
if (!(in instanceof PushbackInputStream)) {
this.in = new PushbackInputStream(in);
}
((PushbackInputStream)in).unread(c2);
}
break loop;
default:
if (--room < 0) {
buf = new char[offset + 128];
room = buf.length - offset - 1;
System.arraycopy(lineBuffer, 0, buf, 0, offset);
lineBuffer = buf;
}
buf[offset++] = (char) c;
break;
}
}
if ((c == -1) && (offset == 0)) {
return null;
}
return String.copyValueOf(buf, 0, offset);
}
public final String readUTF() throws IOException {
return readUTF(this);
}
public final static String readUTF(DataInput in) throws IOException {
//先读取2字节的utf的长度信息 2^16-1 = 65535
//因为writeUTF的时候长度不许>=64K(即65535个字节)
int utflen = in.readUnsignedShort();
byte[] bytearr = null;
char[] chararr = null;
// 如果in本身是“数据输入流”,
// 则,设置字节数组bytearr = "数据输入流"的成员bytearr
// 设置字符数组chararr = "数据输入流"的成员chararr
// 否则的话,新建数组bytearr和chararr
if (in instanceof DataInputStream) {
DataInputStream dis = (DataInputStream)in;
if (dis.bytearr.length < utflen){
dis.bytearr = new byte[utflen*2];
dis.chararr = new char[utflen*2];
}
chararr = dis.chararr;
bytearr = dis.bytearr;
} else {
bytearr = new byte[utflen];
chararr = new char[utflen];
}
//单字节、双字节、三字节
int c, char2, char3;
int count = 0;
int chararr_count=0;
// 从“数据输入流”中读取数据并存储到字节数组bytearr中;从bytearr的位置0开始存储,存储长度为utflen。
// 注意,这里是存储到字节数组!而且读取的是全部的数据。
in.readFully(bytearr, 0, utflen);
//如果是ascii码就直接存在bytearr里面了,毕竟老外写的源码,都是用ascii码机率比较高,就省去下面for中的判断了
// 将“字节数组bytearr”中的数据 拷贝到 “字符数组chararr”中
// 注意:这里相当于“预处理的输入流中单字节的符号”,因为UTF-8是1-4个字节可变的。
while (count < utflen) {
c = (int) bytearr[count] & 0xff;
// UTF-8的单字节数据的值都不会超过127;所以,超过127,则退出。
if (c > 127) break;
count++;
chararr[chararr_count++]=(char)c;
}
// 处理完输入流中单字节的符号之后,接下来我们继续处理。
while (count < utflen) {
// 下面语句执行了2步操作。
// (01) 将字节由 “byte类型” 转换成 “int类型”。
// 例如, “11001010” 转换成int之后,是 “00000000 00000000 00000000 11001010”
// (02) 将 “int类型” 的数据左移4位
// 例如, “00000000 00000000 00000000 11001010” 左移4位之后,变成 “00000000 00000000 00000000 00001100”
c = (int) bytearr[count] & 0xff;
switch (c >> 4) {
case 0: case 1: case 2: case 3: case 4: case 5: case 6: case 7:
/* 0xxxxxxx*/
// 若 UTF-8 是单字节,即 bytearr[count] 对应是 “0xxxxxxx” 形式;
// 则 bytearr[count] 对应的int类型的c的取值范围是 0-7。
count++;
chararr[chararr_count++]=(char)c;
break;
// 若 UTF-8 是双字节,即 bytearr[count] 对应是 “110xxxxx 10xxxxxx” 形式中的第一个,即“110xxxxx”
// 则 bytearr[count] 对应的int类型的c的取值范围是 12-13。
case 12: case 13:
/* 110x xxxx 10xx xxxx*/
count += 2;
if (count > utflen)
throw new UTFDataFormatException(
"malformed input: partial character at end");
char2 = (int) bytearr[count-1];
if ((char2 & 0xC0) != 0x80)
throw new UTFDataFormatException(
"malformed input around byte " + count);
chararr[chararr_count++]=(char)(((c & 0x1F) << 6) |
(char2 & 0x3F));
break;
// 若 UTF-8 是三字节,即 bytearr[count] 对应是 “1110xxxx 10xxxxxx 10xxxxxx” 形式中的第一个,即“1110xxxx”
// 则 bytearr[count] 对应的int类型的c的取值是14 。
case 14:
/* 1110 xxxx 10xx xxxx 10xx xxxx */
count += 3;
if (count > utflen)
throw new UTFDataFormatException(
"malformed input: partial character at end");
char2 = (int) bytearr[count-2];
char3 = (int) bytearr[count-1];
if (((char2 & 0xC0) != 0x80) || ((char3 & 0xC0) != 0x80))
throw new UTFDataFormatException(
"malformed input around byte " + (count-1));
chararr[chararr_count++]=(char)(((c & 0x0F) << 12) |
((char2 & 0x3F) << 6) |
((char3 & 0x3F) << 0));
break;
// 若 UTF-8 是四字节,即 bytearr[count] 对应是 “11110xxx 10xxxxxx 10xxxxxx 10xxxxxx” 形式中的第一个,即“11110xxx”
// 则 bytearr[count] 对应的int类型的c的取值是15
default:
/* 10xx xxxx, 1111 xxxx */
throw new UTFDataFormatException(
"malformed input around byte " + count);
}
}
// The number of chars produced may be less than utflen
return new String(chararr, 0, chararr_count);
}
}
public class DataOutputStream extends FilterOutputStream implements DataInput
public
class DataOutputStream extends FilterOutputStream implements DataOutput {
/**
* The number of bytes written to the data output stream so far.
* If this counter overflows, it will be wrapped to Integer.MAX_VALUE.
*/
protected int written;
/**
* bytearr is initialized on demand by writeUTF
*/
private byte[] bytearr = null;
public DataOutputStream(OutputStream out) {
super(out);
}
private void incCount(int value) {
int temp = written + value;
if (temp < 0) {
temp = Integer.MAX_VALUE;
}
written = temp;
}
public synchronized void write(int b) throws IOException {
out.write(b);
incCount(1);
}
public synchronized void write(byte b[], int off, int len)
throws IOException
{
out.write(b, off, len);
incCount(len);
}
public void flush() throws IOException {
out.flush();
}
public final void writeBoolean(boolean v) throws IOException {
out.write(v ? 1 : 0);
incCount(1);
}
public final void writeByte(int v) throws IOException {
out.write(v);
incCount(1);
}
public final void writeShort(int v) throws IOException {
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
incCount(2);
}
public final void writeChar(int v) throws IOException {
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
incCount(2);
}
public final void writeInt(int v) throws IOException {
out.write((v >>> 24) & 0xFF);
out.write((v >>> 16) & 0xFF);
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
incCount(4);
}
private byte writeBuffer[] = new byte[8];
public final void writeLong(long v) throws IOException {
writeBuffer[0] = (byte)(v >>> 56);
writeBuffer[1] = (byte)(v >>> 48);
writeBuffer[2] = (byte)(v >>> 40);
writeBuffer[3] = (byte)(v >>> 32);
writeBuffer[4] = (byte)(v >>> 24);
writeBuffer[5] = (byte)(v >>> 16);
writeBuffer[6] = (byte)(v >>> 8);
writeBuffer[7] = (byte)(v >>> 0);
out.write(writeBuffer, 0, 8);
incCount(8);
}
public final void writeFloat(float v) throws IOException {
writeInt(Float.floatToIntBits(v));
}
public final void writeDouble(double v) throws IOException {
writeLong(Double.doubleToLongBits(v));
}
public final void writeBytes(String s) throws IOException {
int len = s.length();
for (int i = 0 ; i < len ; i++) {
out.write((byte)s.charAt(i));
}
incCount(len);
}
public final void writeChars(String s) throws IOException {
int len = s.length();
for (int i = 0 ; i < len ; i++) {
int v = s.charAt(i);
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
}
incCount(len * 2);
}
public final void writeUTF(String str) throws IOException {
writeUTF(str, this);
}
static int writeUTF(String str, DataOutput out) throws IOException {
int strlen = str.length();
int utflen = 0;
int c, count = 0;
/* use charAt instead of copying String to char array */
for (int i = 0; i < strlen; i++) {
c = str.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
utflen++;
} else if (c > 0x07FF) {
utflen += 3;
} else {
utflen += 2;
}
}
if (utflen > 65535)
throw new UTFDataFormatException(
"encoded string too long: " + utflen + " bytes");
byte[] bytearr = null;
if (out instanceof DataOutputStream) {
DataOutputStream dos = (DataOutputStream)out;
if(dos.bytearr == null || (dos.bytearr.length < (utflen+2)))
dos.bytearr = new byte[(utflen*2) + 2];
bytearr = dos.bytearr;
} else {
bytearr = new byte[utflen+2];
}
bytearr[count++] = (byte) ((utflen >>> 8) & 0xFF);
bytearr[count++] = (byte) ((utflen >>> 0) & 0xFF);
int i=0;
for (i=0; i<strlen; i++) {
c = str.charAt(i);
if (!((c >= 0x0001) && (c <= 0x007F))) break;
bytearr[count++] = (byte) c;
}
for (;i < strlen; i++){
c = str.charAt(i);
if ((c >= 0x0001) && (c <= 0x007F)) {
bytearr[count++] = (byte) c;
} else if (c > 0x07FF) {
bytearr[count++] = (byte) (0xE0 | ((c >> 12) & 0x0F));
bytearr[count++] = (byte) (0x80 | ((c >> 6) & 0x3F));
bytearr[count++] = (byte) (0x80 | ((c >> 0) & 0x3F));
} else {
bytearr[count++] = (byte) (0xC0 | ((c >> 6) & 0x1F));
bytearr[count++] = (byte) (0x80 | ((c >> 0) & 0x3F));
}
}
out.write(bytearr, 0, utflen+2);
return utflen + 2;
}
public final int size() {
return written;
}
}
参考:字符集与编码















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}