









(本文的多进程特指linux下的多进程,其他系统的没做过试验)
编写多进程或者多线程的程序总会有那些么一些些坑,一般来说是这样的,进程之间的地址空间是独享的,而线程是共享进程的地址空间,线程的资源比进程小,创建线程比创建进程快,线程间切换快,线程间通信快,线程资源利用率好。这样一说貌似好处全被多线程占尽,那么多进程岂不是没用,其实不然,多线程和多进程各有其用处,正如不要在脱离实际条件讨论select,poll的效率一样。虽然我所接触到的服务端的程序很多都是基于多线程的,但是也有很多的网络服务器是多进程的,著名的Nginx服务器便是使用多进程方式实现,还有我们用的FTP服务器,必须用多进程的方式实现。多线程也是存在不少坑的,多进程更有利于权限控制,通常web服务器的worker进程都会setuid到普通用户,避免拥有过高权限受到漏洞攻击,而master进程拥有root权限才能bind 80,这在FTP服务器上也是一样的。 多进程有利于架构级别的扩展,更利于部署,但多线程并不是影响这个问题的关键因素。
linux进程特性
linux下创建进程有好几种方式。fork()方式,vfork(),system()方式,exec()族函数,clone等等,这里谈的主要是fork。
linux进程产生过程
进程产生的方式很多中,但是其基本过程是一致的。
(1)首先复制其父进程的环境配置
(2)在内核中建立进程结构
(3)将结构插入到进程列表,便于维护
(4)分配资源给此进程
(5)复制父进程的内存映射信息
(6)管理文件描述符和链接点
(7)通知父进程
进程的终止方式
有5种方式可以使进程终止
(1)从main返回
(2)调用exit
(3)调用_exit
(4)调用abort
(5)由一个信号终止
在进程终止的时候,系统会释放进程所拥有的资源,例如内存,文件符。内核结构等等。
创建进程
linux下使用fork创建进程是一件很简单的事情,可如下实现
/**
*start from the very beginning,and to create greatness
*@author: LinChuangwei
*@E-mail:979951191@qq.com
*@brief:一个关于进程的小测试
*/
#include <sys/types.h>
#include <unistd.h>
#include <iostream>
int main(int argc, char const *argv[])
{
using namespace std;
pid_t pid,ppid;
pid = getpid();//当前进程id
ppid = getppid();//当前进程父进程的id
cout << "pid:" << pid <<" " << "ppid:" << ppid <<endl;
//分叉进程
pid = fork();
if (-1 == pid)
{//fork失败
cout << "fork failed.\n";
}
else if (0 == pid)
{
cout << "子进程pid:" << getpid() << " " << "其父进程pid:" << getppid() << endl;
}
else
{
cout << "父进程pid:" << getpid() << endl;
}
return 0;
}fork之后父进程和子进程返回不同的pid,为0是子进程。

写时拷贝 (copy- on-write)
传统的fork()系统调用直接把所有的资源复制给新 创建的进程。这种实现过于简单并且效率低下,因为它拷贝的数据或许可以共享(更糟糕的是,如果新进程打算立即执行一个新的映像,那么所有的拷贝都将前功尽弃。
Linux的fork()使用写时 拷贝 (copy- on-write)页实现。写时拷贝是一种可以推迟甚至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。只 用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共 享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。在页根本不会被写入的情况下—例如,fork()后立即执行exec(),地址空间 就无需被复制了。fork()的实际开销就是复制父进程的页表以及给子进程创建一个进程描述符。不妨看下下面的程序:
/**
*start from the very beginning,and to create greatness
*@author: LinChuangwei
*@E-mail:979951191@qq.com
*@brief:一个关于进程的小测试
*/
#include <sys/types.h>
#include <unistd.h>
#include <iostream>
char array[] = {"LinChuangwei"};
int main(int argc, char const *argv[])
{
using namespace std;
pid_t pid,ppid;
pid = getpid();//当前进程id
ppid = getppid();//当前进程父进程的id
cout << "pid:" << pid <<" " << "ppid:" << ppid <<endl;
//分叉进程
pid = fork();
if (-1 == pid)
{//fork失败
cout << "fork failed.\n";
}
else if (0 == pid)
{
cout << "子进程pid:" << getpid() << " " << "其父进程pid:" << getppid() << endl;
cout << "子进程array:" << array << endl;
array[0] = 'a';//修改array
cout << "子进程array:" << array << endl;
}
else
{
cout << "父进程pid:" << getpid() << endl;
sleep(2);//这里睡眠下让子进程修改并先输出
cout << "父进程array:" << array << endl;
}
return 0;
}
这里父进程创建进程后,子进程改变了array数组,父进程延时等待子进程修改数组并先输出
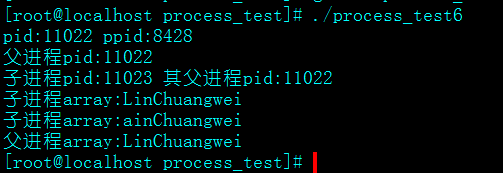
我们看到父进程并没有因为子进程的修改而改变数组,子进程和父进程的第一次输出都是直接拷贝,在子进程修改了array数组后,根据copy-on-write,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程,所以子进程这时才有了自己的array,如果子进程没有修改array,这时其实并没有真正的拷贝。这种方法提高了进程的效率。
当析构函数遇上多进程
子进程继承了父进程的什么
再看下下面的例子:
#include <sys/types.h>
#include <unistd.h>
#include <iostream>
int main(int argc, char const *argv[])
{
using namespace std;
pid_t pid,ppid;
pid = getpid();//当前进程id
ppid = getppid();//当前进程父进程的id
cout << "pid:" << pid <<" " << "ppid:" << ppid <<endl;
int lcw = 2015;
//分叉进程
pid = fork();
if (-1 == pid)
{//fork失败
cout << "fork failed.\n";
}
else if (0 == pid)
{
cout << "子进程pid:" << getpid() << " " << "其父进程pid:" << getppid() << endl;
cout << "子进程lcw:" << lcw <<" 地址:" << &lcw << endl;
lcw = 250;
cout << "子进程lcw:" << lcw <<" 地址:" << &lcw << endl;
}
else
{
cout << "父进程pid:" << getpid() << endl;
cout << "父进程lcw:" << lcw <<" 地址:" << &lcw << endl;
}
return 0;
}其输出结果为:
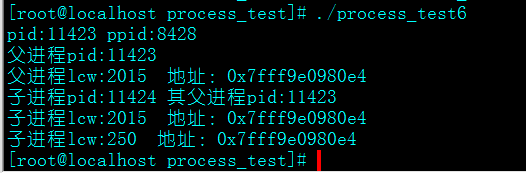
我们看到,父子进程的lcw变量的地址是相同的,但是其输出值不同。这里涉及到物理地址和逻辑地址(或称虚拟地址)的概念。可以参考下这里
总之就是fork时子进程获得父进程数据空间、堆和栈的复制,所以变量的地址(虚拟地址)也是一样的。还可以参考linux fork出的子进程从父进程继承些什么不继承什么
当析构函数遇上多进程
在C++中类的构造函数和析构函数在对象创建和析构的时候会被自动调用。那么构造函数和析构函数在进程创建的时候会有哪些表现呢?看下下面的程序:
/**
*start from the very beginning,and to create greatness
*@author: LinChuangwei
*@E-mail:979951191@qq.com
*@brief:一个关于进程的小测试
*/
#include <sys/types.h>
#include <unistd.h>
#include <iostream>
class process_test
{
public:
process_test():value(0)
{
std::cout << "process_test 构造函数\n";
}
~process_test()
{
std::cout << "process_test 析构函数\n";
}
void increase_value()
{
++value;
std::cout << "increase_value value:" << value << std::endl;
}
void decrease_value()
{
--value;
std::cout << "decrease_value value:" << value << std::endl;
}
private:
int value;
};
int main(int argc, char const *argv[])
{
using namespace std;
pid_t pid,ppid;
pid = getpid();//当前进程id
ppid = getppid();//当前进程父进程的id
cout << "pid:" << pid <<" " << "ppid:" << ppid <<endl;
process_test lcw_test;//定义一个类
cout << " &lcw_test:" << &lcw_test << endl;
//分叉进程
pid = fork();
if (-1 == pid)
{//fork失败
cout << "fork failed.\n";
}
else if (0 == pid)
{
cout << "子进程pid:" << getpid() << " " << "其父进程pid:" << getppid() << endl;
cout << "子进程 &lcw_test:" << &lcw_test << endl;
lcw_test.increase_value();
}
else
{
cout << "父进程pid:" << getpid() << endl;
cout << "父进程 &lcw_test:" << &lcw_test << endl;
lcw_test.decrease_value();
}
return 0;
}
结果如下:
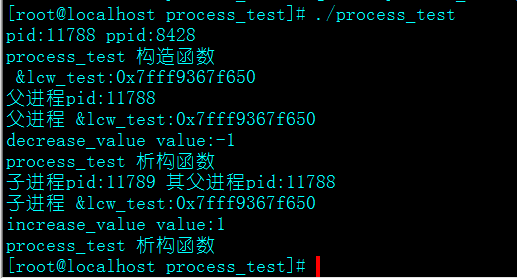
我们可以看到,这里构造函数调用了一次,而析构函数调用了两次(两个进程,如果是多个进程则会析构多次)。怎么回事?一般构造函数或和析构函数应该是成对出现的才对。会不会是调用了默认拷贝构造函数?于是我又做了如下的尝试:
/**
*start from the very beginning,and to create greatness
*@author: LinChuangwei
*@E-mail:979951191@qq.com
*@brief:一个关于进程的小测试
*/
#include <sys/types.h>
#include <unistd.h>
#include <iostream>
#include <stdlib.h>
#include <boost/shared_ptr.hpp>
class process_test
{
public:
process_test()
{
std::cout << "process_test 构造函数\n";
}
process_test(int b)
{
std::cout << "process_test 构造函数\n";
a = b;
}
~process_test()
{
std::cout << "process_test 析构函数\n";
}
process_test(const process_test& B)
{
std::cout << "process_test 拷贝构造函数\n";
a = B.a;
}
void show()
{
std::cout << "The value is:" << a << std::endl;
}
void set(int i)
{
a = i;
}
private:
int a;
};
int main(int argc, char const *argv[])
{
using namespace std;
pid_t pid,ppid;
pid = getpid();//当前进程id
ppid = getppid();//当前进程父进程的id
cout << "pid:" << pid <<" " << "ppid:" << ppid <<endl;
process_test lcw_test1(100);//调用构造函数
process_test lcw_test2 = lcw_test1;//调用拷贝构造函数
//分叉进程
pid = fork();
if (-1 == pid)
{//fork失败
cout << "fork failed.\n";
}
else if (0 == pid)
{
cout << "子进程pid:" << getpid() << " " << "其父进程pid:" << getppid() << endl;
lcw_test1.set(34);
lcw_test1.show();
}
else
{
cout << "父进程pid:" << getpid() << endl;
lcw_test1.set(68);
lcw_test1.show();
}
return 0;
}
结果如下:
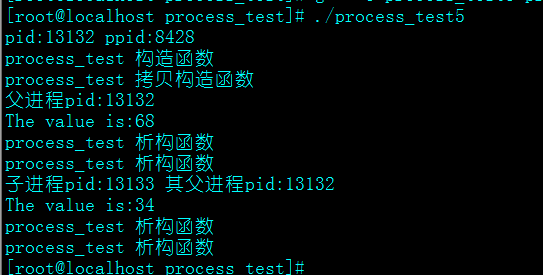
这里拷贝构造函数的调用是在主进程中调用的,fork的时候并不会调用拷贝构造函数。因为这里有两个对象两个进程所以析构了4次。进程创建时对象究竟是怎么复制的?为何会在每个进程中都析构一次呢?因为本人才疏学浅,这里还是不能够深入理解。希望知道的人能够告诉我一下。
单例类和进程
单例模式是软件设计中一种常用的设计模式,通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。单例类在多线程的程序里面无疑是很好用的,这里我自然在想,单例类能不能也用到多进程中呢?在现实生活中,肯定是需要单例的,例如有多个进程同时向一个文件中写入数据,或是多个进程同时对一台打印机进行操作,这里的打印机应该是进程空间所无法复制的。对于文件来说,首先父子进程的虚拟存储空间的用户空间是相同的,是将父进程的拷贝给子进程。同时父子进程对文件的操作是共享方式。因为父进程的文件描述符表被拷贝给了子进程。因此父进程打开的所有文件描述符都在子进程中保存了(每个进程都有独立的描述符表)。由于所有的进程共享文件表、v-node表,所以父子进程的描述符表也是相同的,所以父子进程对文件是以共享的方式存在的。为了防止多个进程同时操作一个文件,可以用文件读写锁等等。如果我们希望有一个对象,在所有进程中都是同一个,那么单例类能不能实现这个功能呢?看下下面的程序
/**
*start from the very beginning,and to create greatness
*@author: LinChuangwei
*@E-mail:979951191@qq.com
*@brief:一个关于进程的小测试
*/
#include <sys/types.h>
#include <unistd.h>
#include <iostream>
#include <stdlib.h>
class process_test
{
public:
~process_test()
{
std::cout << "process_test 析构函数\n";
}
void increase_value()
{
++value;
std::cout << "increase_value value:" << value << std::endl;
}
void decrease_value()
{
--value;
std::cout << "decrease_value value:" << value << std::endl;
}
static process_test& instance();
static void destroy();
static process_test* __self;
private:
int value;
process_test():value(0)
{
std::cout << "process_test 构造函数\n";
}
};
process_test* process_test::__self = NULL;
/**
*instance - 返回单例
*/
process_test& process_test::instance()
{
if (__self == NULL)
{
__self = new process_test();
std::cout << "process_test::instance()" << std::endl;
atexit(destroy);//在程序结束的时候会自动调用destroy
}
return *(__self);//返回引用
}
/**
*destroy - 释放内存
*/
void process_test::destroy()
{
if (__self != NULL)
{
delete __self;
__self = NULL;
std::cout << "process_test::destroy()" << std::endl;
}
}
int main(int argc, char const *argv[])
{
using namespace std;
pid_t pid,ppid;
pid = getpid();//当前进程id
ppid = getppid();//当前进程父进程的id
cout << "pid:" << pid <<" " << "ppid:" << ppid <<endl;
process_test& lcw_test(process_test::instance());//定义一个类
lcw_test.increase_value();//value加1,这里是1
cout <<"&lcw_test " <<&lcw_test <<endl;
//分叉进程
pid = fork();
if (-1 == pid)
{//fork失败
cout << "fork failed.\n";
}
else if (0 == pid)
{
cout << "子进程pid:" << getpid() << " " << "其父进程pid:" << getppid() << endl;
process_test& lcw_test1(process_test::instance());//定义一个对象。希望获得单例
lcw_test1.increase_value();//加1,这里应该是为2
cout <<"子进程&lcw_test1 " <<&lcw_test1 <<endl;
}
else
{
cout << "父进程pid:" << getpid() << endl;
sleep(5);//让子进程先执行
process_test& lcw_test2(process_test::instance());//定义一个对象。希望获得单例
lcw_test2.decrease_value();//减1,如果是之前的那个对象,这里应该是为1
cout <<"父进程&lcw_test2 " <<&lcw_test2 <<endl;
}
return 0;
}
结果如下:
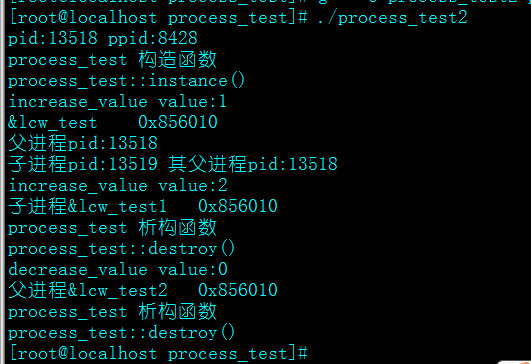
父进程的value为0,说明得到的已经不是之前那个对象了,这里应该都是虚拟内存搞的鬼。在这里顺便提醒下,使用单例类一定是返回指针或者引用,之前忘记加了结果出现了很多意想不到的情况。
神器shared_ptr又会是怎么样
C++ boost库里面额shared_ptr智能指针被称为神器,智能指针可以自动释放空间,shared_ptr有引用计数的功能,当引用计数为0时自动释放内存,多进程下的shared_ptr还能不能发挥作用呢?
/**
*start from the very beginning,and to create greatness
*@author: LinChuangwei
*@E-mail:979951191@qq.com
*@brief:一个关于进程的小测试
*/
#include <sys/types.h>
#include <unistd.h>
#include <iostream>
#include <stdlib.h>
#include <boost/shared_ptr.hpp>
class process_test
{
public:
process_test()
{
std::cout << "process_test 构造函数\n";
}
~process_test()
{
std::cout << "process_test 析构函数\n";
}
};
int main(int argc, char const *argv[])
{
using namespace std;
pid_t pid,ppid;
pid = getpid();//当前进程id
ppid = getppid();//当前进程父进程的id
cout << "pid:" << pid <<" " << "ppid:" << ppid <<endl;
boost::shared_ptr<process_test> lcw_test(new process_test);
cout << "lcw_test.use_count():" << lcw_test.use_count() << endl;//引用计数1
boost::shared_ptr<process_test> lcw_test1 = lcw_test;
cout << "lcw_test.use_count():" << lcw_test.use_count() << endl;//引用计数2
//分叉进程
pid = fork();
if (-1 == pid)
{//fork失败
cout << "fork failed.\n";
}
else if (0 == pid)
{
cout << "子进程pid:" << getpid() << " " << "其父进程pid:" << getppid() << endl;
cout << "子进程lcw_test.use_count():" << lcw_test.use_count() << endl;
boost::shared_ptr<process_test> lcw_test2 = lcw_test;
cout << "lcw_test2.use_count():" << lcw_test2.use_count() << endl;//这里应该是3
}
else
{
cout << "父进程pid:" << getpid() << endl;
sleep(2);//子进程先执行
cout << "父进程lcw_test.use_count():" << lcw_test.use_count() << endl;//这里?
}
return 0;
}结果如下:
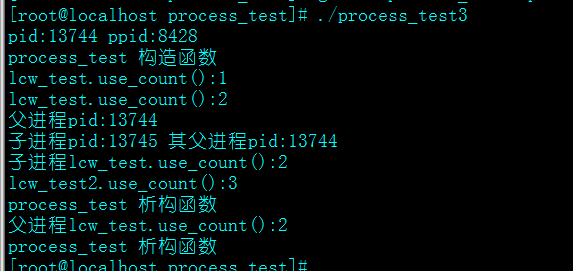
可以看到,父进程中的引用计数还是2,所以shared_ptr,还是只能够在单个进程里有效,同样被复制了一份。
上面都是我自己一些比较好奇的尝试而已,可能会有些好笑,请不要见怪。
linux下的进程间通信和同步
linux下的进程通信方式有很多种,管道,命令管道消息队列,信号量,共享内存等等,但都相对比较复杂和繁琐。我这里说下共享内存。因为共享内存共享内存是进程间通信中最简单的方式之一。共享内存允许两个或更多进程访问同一块内存,就如同 malloc() 函数向不同进程返回了指向同一个物理内存区域的指针。当一个进程改变了这块地址中的内容的时候,其它进程都会察觉到这个更改。这个特定就可以完成上面说的那种所有进程中只有一个实例的功能。
linux下进程的共享内存
linux下共享内存函数由shmget、shmat、shmdt、shmctl四个函数组成,要包括以下头文件
#include <sys/ipc.h>
#include <sys/shm.h>int shmget(key_t key, size_t size, int shmflg)
作用:用于创建一个新的共享内存段,或者访问一个现有的共享内存段
参数:
key: 如果是0(IPC_PRIVATE)会建立新共享内存对象,是大于0的32位整数会视参数shmflg来确定操作。通常要求此值来源于ftok返回的IPC键值
size:大于0的整数会新建的共享内存大小,以字节为单位。 如果是0只获取共享内存时指定为0
shmflg:是0的话取共享内存标识符,若不存在则函数会报错
IPC_CREAT:当shmflg&IPC_CREAT为真时,如果内核中不存在键值与key相等的共享内存,则新建一个共享内存;如果存在这样的共享内存,返回此共享内存的标识符
IPC_CREAT|IPC_EXCL:如果内核中不存在键值与key相等的共享内存,则新建一个消息队列;如果存在这样的共享内存则报错
返回值:成功返回共享内存的标识符,出错返回-1,错误原因存于error中
void *shmat(int shmid, const void *shmaddr, int shmflg)
作用:连接共享内存标识符为shmid的共享内存,连接成功后把共享内存区对象映射到调用进程的地址空间,随后可像本地空间一样访问
参数:
shmid:共享内存标识符,shmget返回
shmaddr:指定共享内存出现在进程内存地址的什么位置,直接指定为NULL让内核自己决定一个合适的地址位置
shmflg:SHM_RDONLY为只读模式,其他为读写模式
函数返回值:成功返回附加好的共享内存地址,出错返回-1,错误原因存于error中。
int shmdt(const void *shmaddr)
作用:与shmat函数相反,是用来断开与共享内存附加点的地址,禁止本进程访问此片共享内存
参数:
shmaddr:连接的共享内存的起始地址
函数返回值:成功返回0,出错返回-1,错误原因存于error中
(本函数调用并不删除所指定的共享内存区,而只是将先前用shmat函数连接(attach)好的共享内存脱离(detach)目前的进程)
int shmctl(int shmid, int cmd, struct shmid_ds *buf)
作用:完成对共享内存的控制
参数:
shmid:共享内存标识符
cmd:
IPC_STAT:得到共享内存的状态,把共享内存的shmid_ds结构复制到buf中
IPC_SET:改变共享内存的状态,把buf所指的shmid_ds结构中的uid、gid、mode复制到共享内存的shmid_ds结构内
IPC_RMID:删除这片共享内存
buf:共享内存管理结构体
返回值:成功返回0,出错返回-1,错误原因存于error中
下面编写一个简单的程序使用共享内存进行进程间通信,代码参考如下:
/**
*start from the very beginning,and to create greatness
*@author: LinChuangwei
*@E-mail:979951191@qq.com
*@brief:一个关于进程的小测试
*/
#include <sys/types.h>
#include <unistd.h>
#include <iostream>
#include <stdlib.h>
#include <string.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int main(int argc, char const *argv[])
{
using namespace std;
pid_t pid,ppid;
pid = getpid();//当前进程id
ppid = getppid();//当前进程父进程的id
cout << "pid:" << pid <<" " << "ppid:" << ppid <<endl;
key_t key;
int shmid;
int *shms,*shmc;
key = ftok("/ipc/sem",'a');//生成键值
shmid = shmget(key,sizeof(int),IPC_CREAT|IPC_EXCL|0600);//获得共享内存 足够保存int型字节即可
if (-1 == shmid)
{
cout << "shmid = -1\n";
return 0;
}
cout << "shmid:" << shmid << endl;
//分叉进程
pid = fork();
if (-1 == pid)
{//fork失败
cout << "fork failed.\n";
}
else if (0 == pid)
{
cout << "子进程pid:" << getpid() << " " << "其父进程pid:" << getppid() << endl;
shms = (int*)shmat(shmid,0,0);//挂接共享内存
*shms = 4;
(*shms)++;
cout << "子进程共享内存内容:" << *shms << endl;
shmdt(shms);//摘除共享内存
}
else
{
cout << "父进程pid:" << getpid() << endl;
shmc = (int*)shmat(shmid,0,0);//挂接共享内存
sleep(3);//等待另一个进程将数据写入
cout << "父进程共享内存内容:" << *shmc << endl;
shmdt(shmc);//摘除共享内存
}
//如果仍有别的进程与该共享内存保持连接,则调用IPC_RMID子命令后,
//该共享内存并不会被立即从系统中删除,而是被设置为IPC_PRIVATE状态,
//并被标记为”已被删除”(使用ipcs命令可以看到dest字段);直到已有连接全部断开,
//该共享内存才会最终从系统中消失。
//使用ipcrm -m 688137删除此共享内存
sleep(5);
shmctl(shmid,IPC_RMID,0);
return 0;
}程序比较简单,首先获得一段int型的共享内存,因为这里只是一个简单的例子,所以进程间共享的是一个int型的数据,然后子进程中将共享内存段的值赋为4,然后加1,即为5,然后父进程先延时,等待子进程赋值,最后输出也为5,说明父子进程实现了数据共享。使用后要记得使用shmid将内存删除,如果忘记了可以在终端下使用ipcrm -m 688137删除此共享内存,688137要换成具体的shmid。这样看起来好像比较不灵活,但是如果和信号量或是其他方式一起配合使用的话,就会比较灵活了。
未来的操作系统一定要更加强大!
















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









