








python部分整理 数据分析实战45讲 陈旸 + 七周成为数据分析师 秦路
BI弃坑
一、零碎知识点
快捷操作
shift+回车 执行并跳转到下一行
ctrl+回车 仅执行停留在当行
type()
% 余数
// 整除
None缺失
''空值
多变量同时赋值
a,b,c = 1,2,3
二、数据结构
1. 列表
# 取出第一个元素
list_name[0]
# 取出最后一个元素
list_name[-1]
# 左闭右开,起始位置~结束位置-1
list_name[起始:结束]
# 插入新的元素到列表指定位置【同时更新原有列表】
list_name.insert然后按住shift+tab可以调出帮助文件
Signature: num.insert(index, object, /)
Docstring: Insert object before index.
Type: builtin_function_or_method
# 插入新的元素到列表尾端【同时更新原有列表,且一次只能插入一个】
list_name.append()
# 插入多个值到末尾,但需要手动更新
old_list = old_list + [元素1,...]
# 删除
list_name.pop()
# 无参数默认删除最后一个
Signature: num.pop(index=-1, /)
Docstring:
Remove and return item at index (default last).
# set+list = 列表去重
a = [1,2,3,3]
b = [2,3,4]
# a + b = [1, 2, 3, 3, 2, 3, 4]
# 但想得到的是 [1,2,3,4] 去重的交集
# 集合去重
set(a)
# {1, 2, 3}
# 交集
set(a) & set(b)
# 并集
set(a) | set(b)
# 差集
set(a) - set(b)
2. 字典
没有顺序之分
# 创建字典
a = {'id':1, 'name':'gouzi', 'sex':'male'}
# 查看元素
a['id'] # 1
a['ID'] # error
# 提高容错
list_name.get()
Signature: a.get(key, default=None, /)
Docstring: Return the value for key if key is in the dictionary, else default.
a.get('ID',99999)
# 查找,有则返回值,如若没有则返回第二个参数
a.setdefault('id',2) #1
a.setdefault('age',0)
# {'id': 1, 'name': 'gouzi', 'sex': 'male', 'age': 0}
# 删除元素
a.pop('id')
# 添加元素
a['id'] = 2
# 提取标签
list(a.keys())
# 提取值
list(a.values())
# 同时提取
list(a.items())
3. 元组
tuples = ('tupleA','tupleB')
用圆括号表示,里面的元素不能够修改
4. 集合
s = set(['a', 'b', 'c'])
s.add('d')
s.remove('b')
三、控制流
1. if
if 判断条件: #注意这个英文冒号
xxxxx
2. while + break vs continue
一直执行直到判断条件为False
注意避免死循环

3. for + range/list…
range(stop) -> range object 输出 0 ~ (stop - 1)
range(start, stop[, step]) -> range object
# 除了 range和list 可以用for,字典也可以
for i in a.keys(): # values同理
print(i)
# 或者同时输出
for k,v in a.items():
print(k,v)
循环进阶:简化写法
list_1 = []
for i in range(1,11):
if i%2 == 0:
list_1.append(i)
# 简化写法
list_2 = [i for i in range(1,11) if i%2 == 0]
# 除了i,还可以是
list_3 = [i**2 for i in range(1,11) if i%2 == 0]
list_4 = ['str'+ str(i) for i in range(1,11) if i%2 == 0]
# 也可以用在字典上
dic = {'a':1,'b':2,'c':3}
list_5 = [i**2 for i in dic.values()]
四、函数
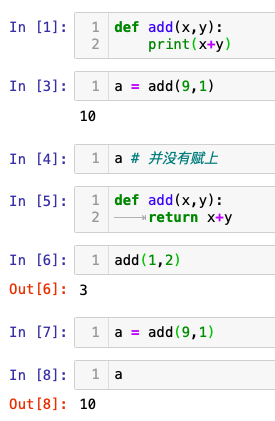
1. 自定义函数
def add(x,y):
return x+y #这样可以将函数返回的值赋给变量;如果是print(x+y)则不行
2. map函数
#求列表1~10中每个元素的平方
#方法一
[i**2 for i in range(1,11)]
#方法二
def squ(x):
return(x*x)
[squ(i) for i in range(1,11)]
#方法三 【用map函数:】
list(map(squ,range(1,11)))
3. 匿名函数
list(map(lambda x:x*x,[1,2,3]))
#输入x【冒号】输出x^2
#这样不用定义函数
4. 第三方包 numpy & pandas
# 想要计算列表中各个元素出现的次数
a = [2,1,5,6,0,2,4,6,7,7]
d = {} #空字典
for i in a:
if i in d.keys():
d[i] += 1
else:
d[i] = 1
# 第三方包
import collections
collections.Counter(a)
# 其他常用的包
import csv
import datetime
import math
import numpy as np #起别名
import pandas as pd
b = np.array([[1,2,3,4],[5,6,7,8]])
# 同样可以用【】进行切片
b.dtype #获取元素的属性
# dtype('int64')
b.shape
#函数shape属性获得数组的大小
# (2, 4)
⚠️list中数据类型不一定要一致,但是array中类型必须全部一致
pd.Series([1,2,3]) #注意大写S
# 索引 & 数值
# 可自定义索引
s1 = pd.Series([1,2,3],index = ['a','b','c'])
s1['a']
#可同时多个索引
s1[['a','c']]
/*
a 1
b 2
c 3
dtype: int64
*/
# 数据类型的转换,并没有更改原本的数据类型,只是预览
s1.astype('str')
# 也可以导入字典的形式
s2 = {'name':'QQ','age':18}
s3 = pd.Series(s2)
/*
name QQ
age 18
dtype: object
*/
# 数据框支持多种数据类型的输入
# 由字典导入,也可以列表然后自己定义index/columns

#查看具体信息
df = pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],columns=list('abc'))
df.info()
#提取列
df['a'] #由dataframe变成series
#或者
df.a
#提取行
df.ix[0:1]
# 单一条件查找
df[df.a == 1]
# 多条件查找
# 错误
df[df.a == 1 & df.b == 2]
# The truth value of a Series is ambiguous.
# 正确:要使用小括号
df[(df.a == 1) & (df.b == 2)]
# 或者
df.query('(a == 1) & (b == 2)') #需要用引号括起来
# 增
df.append #运算效率低
df.iloc[1] # 注意是【】,得到的是第二行数据
df.iloc[1:2] #也是一样的结果,因为右边2是开区间
df.iloc[1:2,1:2]
# 如果index是字符串,也可以使用
df.index = ['one','two','three']
df.loc['two']
df.loc['two','b']
df.loc['two',['b','c']]
/* df
a b c
one 1 2 3
two 4 5 6
three 7 8 9
*/
numpy
结构数组
import numpy as np
persontype = np.dtype({
'names':['name', 'age', 'chinese', 'math', 'english'],
'formats':['S32','i', 'i', 'i', 'f']})
# S32 :S后面添加数字,表示字符串长度,比如S3表示长度为三的字符串,不写则为最大长度
# i : int32的缩写
# f : float32
peoples = np.array([("ZhangFei",32,75,100, 90),("GuanYu",24,85,96,88.5),
("ZhaoYun",28,85,92,96.5),("HuangZhong",29,65,85,100)],
dtype=persontype)
peoples[:]['age'] #提取所有人的年龄
连续数组
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
np.arange 和 np.linspace 起到的作用是一样的,都是创建等差数组。这两个数组的结果 x1,x2 都是[1 3 5 7 9]。
arange() 类似内置函数 range(),通过指定初始值、终值、步长来创建等差数列的一维数组,默认是不包括终值的。linspace 是 linear space 的缩写,代表线性等分向量的含义。linspace() 通过指定初始值、终值、元素个数来创建等差数列的一维数组,默认是包括终值的
算术运算
x1 = np.arange(1,6) # 1,2,3,4,5
x2 = np.linspace(2,2,5) # 2,2,2,2,2
print(np.add(x1, x2))
print(np.subtract(x1,x2))
print(np.multiply(x1, x2))
print(np.divide(x1, x2))
print(np.power(x1, x2))
# 在 n 次方中,x2 数组中的元素实际上是次方的次数,x1 数组的元素为基数。
print(np.remainder(x1, x2)) #也可以用 np.mod(x1, x2) 取余数
统计函数
- 计数组 / 矩阵中的最大值函数 amax(),最小值函数 amin()
- amin() 用于计算数组中的元素沿指定轴的最小值
- amin(a,0) 是延着 axis=0 轴 「纵向」 的最小值,axis=0 轴是把元素看成了[1,4,7], [2,5,8], [3,6,9]三个元素,所以最小值为[1,2,3]
- amin(a,1) 是延着 axis=1 轴 「横向」 的最小值,axis=1 轴是把元素看成了[1,2,3], [4,5,6], [7,8,9]三个元素,所以最小值为[1,4,7]
a = np.array([[1,2,3], [4,5,6], [7,8,9]])
print(np.amin(a)) #取矩阵中的最小值
print(np.amin(a,0))
print(np.amin(a,1))
print(np.amax(a))
print(np.amax(a,0))
print(np.amax(a,1))
- 统计最大值与最小值之差 ptp()
print np.ptp(a) # 9-1
print np.ptp(a,0) # 7-1 = 8-2 = 9-3
print np.ptp(a,1) #3-1 = 6-4 = 9-7
- 统计数组的百分位数 percentile() 第p个百分位数
np.percentile(a, 50) # 5
np.percentile(a, 50, axis=0) #array([4., 5., 6.])
np.percentile(a, 50, axis=1) #array([2., 5., 8.])
- 统计数组中的中位数 median()、平均数 mean()
# 同理
np.median(a,axis = 0)
np.mean(a, axis=1)
- 统计数组中的加权平均值 average()
a = np.array([1,2,3,4])
wts = np.array([1,2,3,4])
print(np.average(a)) # 2.5
print(np.average(a,weights=wts)) #3 = 1*0.1+2*0.2+3*0.3+4*0.4
- 统计数组中的标准差 std()、方差 var()
np.std(a)
np.var(a)
- NumPy 排序
sort(a, axis =-1, kind=’quicksort’, order=None),默认情况下使用的是快速排序;
在 kind 里,可以指定 quicksort、mergesort、heapsort 分别表示快速排序、合并排序、堆排序。
以下解释均摘自于 littlelufisher🐂
快速排序流程如下:
(1)从数列中挑出一个基准值。
(2)将所有比基准值小的摆放在基准前面,所有比基准值大的摆在基准的后面(相同的数可以到任一边);在这个分区退出之后,该基准就处于数列的中间位置。
(3)递归地把"基准值前面的子数列"和"基准值后面的子数列"进行排序。
合并排序:基本思想是合并两个已经排序的表(如A和B)。合并的办法是用两个指针,在已经排序的A和B的开头,不断往前移,作比较,把A和B中的元素放到C中。真正实现算法时候,要用递归进行处理。其基本操作是合并,然后要不断递归,对越来越小的数组区域进行不断的合并。整个算法要分成两部分,一部分是归并操作,另一部分是总体的归并排序的操作。
堆排序:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
同样 axis 默认是 -1,即沿着数组的最后一个轴进行排序,也可以取不同的 axis 轴,或者 axis=None 代表采用扁平化的方式作为一个向量进行排序。另外 order 字段,对于结构化的数组可以指定按照某个字段进行排序。
a = np.array([[4,3,2],[2,4,1]])
print(np.sort(a)) #= print(np.sort(a, axis=1))
'''
[[2 3 4]
[1 2 4]]
'''
print(np.sort(a, axis=None))
# [1 2 2 3 4 4]
print(np.sort(a, axis=0))
'''
[[2 3 1]
[4 4 2]]
'''
五、实际案例
1. 导入数据
import pandas as pd
pd.read_csv('xx_utf.csv') #默认utf
# 如果是gbk(这里sample文件不是用逗号分割而是用\t,所以需要改sep)
df = pd.read_csv('xx_gbk.csv',encoding = 'gbk', sep = '\t')
# 还可以更改列名,添加参数names = list(...)
# 概览
df.info()
# 描述统计
df.describe()
df.head() #默认五行

2. 计算
df.tail() #默认五行
# 数据类型的修改
df.top = df.top.astype('str')
# 数据转置
df.T
# 单一字段排序
df.avg.sort_values() # 返回结果是数组
df.sort_values(by = 'avg',ascending = False) #返回结果是数据框
# by排序的依据
# 多个字段升降序
df.sort_values(['avg','city'],ascending = False)
df.sort_index()
# 排名
df.avg.rank(ascending = False, method = 'average')
# 如果出现多个值相同,排名则(min+max)/2
# e.g.四个值都并列第一,则(1+4)/2 = 2.5
# method还有max/min/first(不考虑并列,值相同时先遇到谁谁就是第一名[按照index])/last
# 唯一值
df.workYear.unique()
# 唯一值以及他们出现的次数
df.workYear.value_counts()
# 累计求和
df.avg.cumsum()
# 分段统计
# 错误写法
df.cut()
# 报错:Dataframe object has no attribute cut
# 正确写法
pd.cut(df.avg,bins = 20)
# 将数据分成20等分
# 参数labels = [...]可以写对应区间的标签 比如 低中高
# 一般为了方便查看会写成df['bins'] = pd.cut(df.avg,bins = 20)
# 也可以人工分割
pd.cut(df.avg,bins = [0,5,10,20,30,设置一个特别的的极大值],labels = ['0~5',...] )
# 分位法进行分割
pd.qcut(x数据,q几等分位,labels = None, retbins = False开区间闭区间,precision = 3, duplicates = 'raise' 去重操作)
3. 聚合函数
df.groupby(by = 'city').count()
df.groupby(by = 'city').max()
... ...
# 多字段
df.groupby(by = ['city','workYear']).mean()
# 算分组之后工资最大值和最小值的差
for k,v in df.groupby(by = ['city']):
print(max(v.avg) - min(v['avg']))
print('我是分割线')
4. 多表关联操作 concat/join/merge
因为没有数据,假设有两张表position和company
# merge 针对的是列
position.merge(right关联的表,how = 'inner'关联的方式,on关联条件【字段名字相同】,left_on = None, right_on = None【名字不一致时使用】, right_index = F)
pd.merge(left,right,how,...)
# join 针对的是索引
company.join(position)
# concat 堆叠 所有字段直接堆在一起,字段全部合并
pd.concat([company,pisition],axis = 0上下拼接/1左右拼接)
# 应用:每个月的销售表数据堆叠成大表
df1 = pd.DataFrame(
{
'A':list('abc'),
'B':list('efg'),
'C':list('hij')
}
)
df2 = pd.DataFrame(
{
'C':list('abc'),
'D':list('edf')
}
)

# 多重索引
# 想从分组结果中提取某分类数据
position.groupby(by = ['city','eduction']).mean().avg['上海']['博士']
# 按照第一/二重索引的顺序
position.groupby(by = ['city','eduction']).mean().loc['上海','博士']
# 如果不用groupby怎么设置多重索引
position.set_index(['city','education'])
# 但并没有排好序,没有合并,数据结果零散
position.sort_values(by = ['city','education']).set_index(['city','education']) #把列变成索引
# 把索引变成列
position.groupby(by = ['city','eduction']).mean().reset_index()
5. 文本函数
position.positionLabels.str.count('分析师')
# 表.字段.str.函数 ; str对值里面的字符串进行操作
# 统计每行有几个‘分析师’
position.positionLabels.str.find('分析师')
# 该字段出现的位置,显示为-1则表示未检索到
position.positionLabels.str[1:-1] #删除每个字符串的首尾字符
position.positionLabels.str[1:-1].str.replace("'","") #删除引号
6. 数据清洗
import numpy as np
# 人为使数据变脏
position.loc[position.city == '深圳',city] = np.NaN #比起None,推荐使用这个
# 填充
position.fillna(1) #将数据框中所有的空值填充为1
# 删除空值所在的行(默认),所在列(axis = 1)
position.dropna()
# 删除重复元素
position.duplicated() #返回bool
position = position[~position.duplicated()] #波浪号反向操作
# 更简单的方法
position.drop_duplicates()
7. apply
# 目标:在avg平均薪资数值后面加上‘k’
position.avg.astype('str')+'k' #不能直接相加,因为avg是浮点数
position.avg.apply(lambda x:str(x)+'k')
# axis = 0 对列使用 = 1 行
# 聚合apply
# 不同城市下薪资排名前几的职位
# sample
def func(x,n):
# x 数据集 l 排名的依据 n 排名
r = x.sort_values('avg', ascending = False)
return r[:n]
position.groupby('city').apply(func,n = 3)
# agg
position.groupby('city').agg('mean')
# 等价于 position.groupby('city').mean()
# 同时运用多个函数
position.groupby('city').agg(['mean','sum'])
# 自定义函数
position.groupby('city').agg(lambda x:max(x) - min(x))
8. 数据透视
position.pivot_table(index = ['city','education'],
columns = 'workYear',
values = ['avg','top'],
aggfunc = [np.mean,np.sum])
# margins汇总项要不要
# 对avg和top都进行mean和sum的操作
# 但如果想分别对avg进行mean操作,对top进行sum操作
# 字典!
position.pivot_table(index = ['city','education'],
columns = 'workYear',
values = ['avg','top'],
aggfunc = {'avg':np.mean,'top':np.sum})
# 导入数据透视表最好是先reset_index
position.pivot_table(index = ['city','education'],
columns = 'workYear',
values = ['avg','top'],
aggfunc = {'avg':np.mean,'top':np.sum}).reset_index().to_csv()
六、Python+数据库
1. 连接&读取数据库
# 终端
pip install pymysql #可能会安装在老版本下
pip3 install pymysql #安装在python3的文件下
方法一 : pymysql
import pymysql
# 创建连接
conn = pymysql.connect(
host = 'localhost', #主机,数据库所在的位置,一般直接输入localhost本地或者ip地址
user = 'root', #账户名
password = '123',
db = 'temp' , #连接的数据库schema
port = 3306, #端口默认3306
charset = 'utf8'# 文本编码
)
# 创建游标
cur = conn.cursor()
cur.execute('select * from Chars')
# 返回6,说明数据有6行
data = cur.fetchall() #调取结果
data
conn.commit() #如果对数据进行修改,记得commit
# 打开游标操作结束,记得关闭
cur.close()
conn.close()
方法二 : Pandas
import sqlalchemy #那么之后调用就是sqlalchemy.create_engine
# 如果写的是
from sqlalchemy import create_engine
# 则直接调用create_engine
import pandas as pd
sql = 'select * from Chars'
engine = create_engine('mysql+pymysql://root:password@localhost:3306/temp?charset=utf8')
# 用户名:密码@主机:端口/数据库?文本编码
data = pd.read_sql(sql,engine)
# 也可以写成函数的形式
def reader(query,db):
engine = create_engine('mysql+pymysql://root:password@localhost:3306/{0}?charset=utf8.format(db)')
df = pd.read_sql(query,engine)
return df
# 可以用来加载数据
reader(
"""
select
date(paidTime) as order_dt,
userId as user_id,
sum(price) as order_amount,
count(orderId) as order_products
from data.orderinfo
where isPaid = "已支付"
group by date(paidTime),userId
"""
)
2. 写入数据库
结果.to_sql(name = 想写入到哪个数据库,con = 'mysql+pymysql://root:password@localhost:3306/temp?charset=utf8')
# 1. if_exists参数:= fail如果原来就存在这个数据表,则写入失败
# = append 表存在插入数据;不存在则自动新建一张表
# 2. index = True 索引也作为字段写入(一般选择False)
# 建议在数据库里先建表再插入
七、实例✨
1. 数据清洗
import pandas as pd
import numpy as np
columns = ['user_id','order_dt','order_products','order_amount']
/*
user_id 用户ID
order_dt 购买日期
order_products 购买产品数
order_amount 购买金额
*/
df = pd.read_table('CDNOW_master.txt',names = columns, sep = '\s+')
# 通过多个字符串进行分割
# s+可以将tab和多个空格都当成一样的分隔符
# sep='\s+': 指代\f\n\t\r\v这些,分别为换页符,换行符,制表符,回车符,垂直制表符
df.info()
# 发现order_dt的类型应该为日期,但是显示为int
# 可以之后改,也可以在pd.read_table导入数据的时候,添加参数parse_dates(把哪个字段转化成日期格式),date_parser具体的时间类型(同to_datetime中的format)
df.head()
df.describe()
df['order_dt'] = pd.to_datetime(df.order_dt, format = '%Y%m%d')
# 后续需要使用月度进行数据分析,因此添加月份字段

# 上面dtype = datetime64[ns] ns是纳秒
df['month'] = df.order_dt.values.astype('datetime64[M]')
# 不要忘记values
/* 改为月份格式
array(['1997-01', '1997-01', '1997-01', ..., '1997-03', '1997-03',
'1997-03'], dtype='datetime64[M]')
*/
2. 进行用户消费趋势的分析(按月)
# (1)每月的消费总金额
# 我写的
df.groupby('month').agg('sum')['order_amount']
# 老师写的,后面使用更加方便
grouped_month = df.groupby('month')
order_month_amount = grouped_month.order_amount.sum()
order_month_amount.head()
# 加载数据可视化包
import matplotlib.pyplot as plt
# 可视化显示在页面上
%matplotlib inline
# 更改设计风格
plt.style.use('ggplot')
order_month_amount.plot() #折线图
# (2)每月的消费次数
grouped_month.user_id.count().plot()
# (3)每月的产品购买量
grouped_month.order_products.sum().plot()
# (4)每月的消费人数
# 我写的
result = grouped_month.user_id.unique().reset_index()
result.user_id.apply(lambda x:len(x)).plot()
# 老师写的
grouped_month.user_id.apply(lambda x:len(x.drop_duplicates())).plot()
# 或者用数据透视表 —— 清晰明了
df.pivot_table(index = 'month',
values = ['order_products','order_amount','user_id'],
aggfunc = {
'order_products' : 'sum',
'order_amount' : 'sum',
'user_id' : 'count'
}).head()
# 每月用户平均消费金额的趋势
grouped_month.order_amount.mean().plot()
# 每月用户平均消费次数的趋势
grouped_month.order_products.mean().plot()
3. 用户个体消费分析
# (1) 用户消费金额、消费次数的描述统计
grouped_user = df.groupby('user_id')
grouped_user.sum().describe()
# 结果显示:
# 用户平均购买了7张CD,但是中位数只有3,说明小部分用户购买了大量的CD
# 用户平均消费同理,有极值干扰
# (2)用户消费金额和消费次数的散点图(线性还是非线性)
# 知识点:散点图是plot.scatter; 过滤数据可以用query
grouped_user.sum().plot.scatter(x = 'order_amount', y ='order_products')
# 线性,但大部分数据集中在左下角,删除极值点再画一次图
grouped_user.sum().query('order_products < 400').plot.scatter(x = 'order_amount', y ='order_products')
#(3)用户消费金额的分布图(是否分布呈现梯度)
grouped_user.order_amount.sum().hist()
# bins参数:柱子的多少
# 从直方图可以看出,用户消费金额绝大部分呈现集中趋势,小部分异常值干扰了判断。可以使用过滤操作排除异常
# (4) 用户消费次数的分布图
grouped_user.sum().query('order_products < 100').order_products.hist()
# 这里的100可以大概通过切比雪夫定理来定
/*
适用于任何数据集,而不论数据的分布情况如何。
至少75%的数据值与平均数的距离在z=2个标准差之内;
至少89%的数据值与平均数的距离在z=3个标准差之内;
至少94%的数据值与平均数的距离在z=4个标准差之内;
易混淆
经验法则(Empirical Rule):需要数据符合正态分布。
大约68%的数据值与平均数的距离在1个标准差之内;
大约95%的数据值与平均数的距离在2个标准差之内;
几乎所有的数据值与平均数的距离在3个标准差之内;
*/
# 描述统计order_products的均值是7,std = 17,所以按94%计算4*17+7
# (5) 用户累计消费金额占比(百分之多少的用户占了百分之多少的消费额)
# ⚠️升序排列
user_cumsum = grouped_user.sum().sort_values('order_amount').apply(lambda x:x.cumsum()/x.sum())
user_cumsum.reset_index().order_amount.plot()
# 记住这里需要reset_index(),因为user_cumsum的索引是user_id,作图会出现问题
# 按用户消费金额进行升序排列,由图可知50%的用户仅贡献了15%的消费额度。而排名前5000的用户贡献了60%的消费额
4. 用户消费行为
- 用户第一次消费(首购)
- 用户最后一次消费
- 新老客户消费比
- 多少用户仅消费一次?
- 每月新客占比?
- 用户分层
- RFM
- 新、老、活跃、回流、流失
- 用户购买周期(按订单)
- 用户消费周期描述
- 用户消费周期分布
- 用户生命周期(按第一次&最后一次消费)
- 用户生命周期描述
- 用户生命周期分布
# 每天新客的数量变化
grouped_user.order_dt.min().value_counts().plot()
# 注意value_counts有s有括号
# 由图可知:用户第一次购买分布集中在前三个月;其中,在2月11日-25日有一次剧烈的波动
# 最后一次消费(流失)
grouped_user.order_dt.max().value_counts().plot()
# 用户最后一次购买的分布比第一次分布更广;
# 大部分最后一次购买集中在前三个月,说明有很多用户购买了一次就不再进行购买
# 随着时间的递增,最后一次购买数也在递增,消费呈现流失上升的状况
# 新老客户消费比
# 有多少用户仅消费一次?(老师是按照首次消费时间=最后一次消费时间,但万一一天内多次消费
user_life = grouped_user.order_dt.agg(['min','max'])
(user_life['min'] == user_life['max']).value_counts()
# 结论:有一半的用户就消费了一次
# 所以我写的是
temp = grouped_user.order_dt.count().reset_index()
temp[temp.order_dt == 1].count()
# 每月新客占比
# RFM
rfm = df.pivot_table(index = 'user_id',
values = ['order_dt','order_products','order_amount'],
aggfunc = {
'order_dt' : 'max',
'order_products' : 'sum',
'order_amount' : 'sum'
})
# (Recency):表示客户最近一次购买的时间有多远
# P.S. 数据是199X年的数据,距今太久,这里用max进行相减
rfm['R'] = (rfm.order_dt.max() - rfm.order_dt)/np.timedelta64(1,'D')
# 分子部分是有单位的,后面除以是去掉单位且除以1(该数值可以修改

图源自: RFM 秦路老师

# (Frequency):客户在最近一段时间内购买的次数
# (Monetary)
rfm.rename(columns = {'order_products':'F','order_amount':'M'},inplace = True)
# 🌟巧妙 不用多个ifelse
def rfm_func(x):
level = x.apply(lambda x:'1' if x>0 else '0')
label = level.R + level.F + level.M
d = {
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要挽留客户',
'001':'重要发展客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般挽留客户',
'000':'一般发展客户'
}
result = d[label]
return result
rfm['label'] = rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
# 使用plot.scatter自带的作图,点的颜色需要新加一列
rfm.loc[rfm.label == '重要价值客户','color'] = '#00CED1'
rfm.loc[~(rfm.label == '重要价值客户'),'color'] = '#DC143C'
# 也可以给每个类别上色,这里省略;后续的学习会使用Matplotlib
rfm.plot.scatter(x = 'F', y = 'R', c = rfm.color,alpha = 0.4)

rfm.groupby('label').count()
rfm.groupby('label').sum()
/*
注意使用平均值时,极值会有影响,所以RFM的划分标准应该以业务为准(可以改为中位数或者自己划分)
- 尽量用小部分的用户覆盖大部分的额度
- 不要为了数据好看划分等级
*/
# 用户分层:新客、老客、活跃、回流、流失
pivoted_counts = df.pivot_table(index = 'user_id',
columns = 'month',
values = 'order_dt',
aggfunc = 'count').fillna(0)
pivoted_counts.head()
# 每个月消费的次数
# 简化,只想知道这个月是否消费
df_purchase = pivoted_counts.applymap(lambda x:1 if x>0 else 0)
# 但有个问题需要注意:要区分是0是没消费还是这时候是非用户,首次消费在这之后,只是数据透视,自动用0补上了
def active_status(data):
status = []
for i in range(18):
#若本月没有消费,一直未注册?不活跃?
if data[i] == 0:
if len(status) > 0:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('inactive')
else:
status.append('unreg')
# 本月有消费:首次?回流?活跃
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'inactive':
status.append('return')
elif status[i-1] == 'unreg':
status.append('new')
else:
status.append('active')
return status
# result_type ='expand'!!!
purchase_status = df_purchase.apply(active_status,axis = 1,result_type ='expand')
purchase_status.columns = pivoted_counts.columns
总之,
- 若本月没有消费
- 若之前有消费,则为流失或者不活跃
- 其他则为未注册
- 若本月有消费
- 若是第一次消费或者上个月为未注册,则为新用户
- 若之前有过消费且上个月为不活跃,则为回流
- 其他则为活跃
实际业务中,通常用SQL来‘上个月的状态表left join这个月的消费情况’,而不是数据透视
# 未注册不希望被count,设置为np.NaN
purchase_status_ct = purchase_status.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x))
purchase_status_ct
purchase_status_ct.fillna(0).T.head()
# 面积图
# 会有遮挡,换一下列的顺序
cols = ['active','new','return','inactive']
new_status = purchase_status_ct.fillna(0).T[cols]
new_status.plot.area()

# 各个状态的占比 / 消费用户的构成
purchase_per = new_status.apply(lambda x:x/x.sum(),axis=1)
/*
活跃用户(持续消费的用户)对应的是消费运营的质量
回流用户(之前不消费本月才消费)对应的是唤回运营
不活跃用户 对应的是流失
*/
# 上个月的没有消费的用户有多少这个月回来了
# shift()错位,往下平移一个
purchase_per['return']/purchase_per['inactive'].shift()
# 用户购买周期(按订单来算,距离上一个订单的时间)
order_diff = grouped_user.apply(lambda x:x.order_dt - x.order_dt.shift())
order_diff.describe()
# 只保留数值,去除单位,画图
(order_diff / np.timedelta64(1,'D')).hist(bins=20)
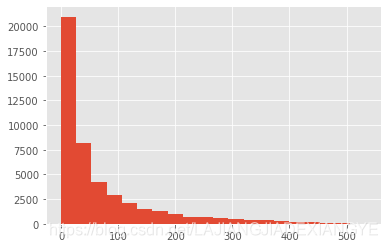
# 用户生命周期
(user_life['max'] - user_life['min']).describe()
# 大多数集中在0天,也就是只够买过一次,排除该部分数据再画图
u_l = ((user_life['max'] - user_life['min']).reset_index()[0] / np.timedelta64(1,'D'))
u_l[u_l > 0].hist(bins=40)
# 仍存在较短生命周期的用户,但也有不少的用户稳定
5. 复购率和回购率分析
- 复购率:自然月内,购买多次的用户占比
- 回购率:曾经购买过的用户在某一时期内的再次购买的占比
# 用透视表计算客户每个月的消费次数
pivoted_counts=df.pivot_table(index='user_id',
columns='month',
values='order_dt',
aggfunc='count').fillna(0)
pivoted_counts.head()
purchase_r = pivoted_counts.applymap(lambda x:1 if x>1 else np.NaN if x==0 else 0)
# 计算复购率:如果x>1,则赋值1 -> 表明消费次数在1次以上
# x==0赋值np.NaN,不会参与计算;其余情况赋值0
#计算复购率
(purchase_r.sum()/purchase_r.count()).plot(figsize = (10,4))
# 复购的人数/消费的人数NaN不计算在内
# 宽10高4
# 结论:复购率稳定在20%左右,前三个月因为有大量新用户涌入,而这批用户只购买了一次,所以导致复购率降低

def purchase_back(data):
status = []
for i in range(17):
if data[i] == 1: # 当月消费
if data[i+1] == 1: # 次月消费
status.append(1) #当月消费过,次月也消费了,回购用户1
if data[i+1] == 0:
status.append(0) # 次月未消费则为0,没有回购
else:
status.append(np.NaN) # 当月没消费
则不计NaN
status.append(np.NaN) # 因为最后一个月缺少下一个月的数据,填补为空
return pd.Series(status,df_purchase.columns)
#对透视表应用函数purchase_back:
purchase_b = df_purchase.apply(purchase_back, axis =1)
purchase_b.head()
# 对照原始表进行理解
df_purchase.head()
# 计算回购率:
(purchase_b.sum()/purchase_b.count()).plot(figsize=(10,4))
# 次月消费过的/本月消费用户数

八、可视化
1. Pandas
- 折线图 plot
- 柱形图 bar
- 直方图 hist
- 箱线图 box
- 密度图 kde
- 面积图 area
- 散点图 scatter
- 散点图矩阵 scatter_matrix
- 饼图 pie
import pandas as pd
# 没找到课件的数据集,自己对照着视频中的数据改造了下DataAnalyst数据集
df = pd.read_csv('position_gbk.csv',encoding = 'gbk')
%matplotlib inline
# 将matplotlib的图表直接显示在单元格里面
# 折线图
# 工资出现次数的折线显示乱七八糟是因为index无序
df.avg.value_counts().sort_index().plot()
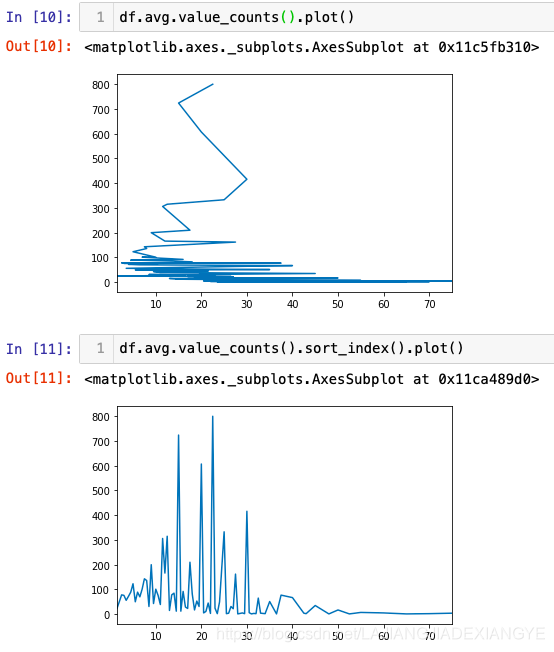
# 柱形图
df.avg.value_counts().sort_index().plot(kind = 'bar')
df.avg.value_counts().sort_index().plot.bar() #更好,可以调用参数
df.pivot_table(index = 'city', columns = 'education', values = 'avg', aggfunc = 'count').plot.bar()# 小方格是因为中文不兼容
# 堆积柱形图
df.pivot_table(index = 'city', columns = 'education', values = 'avg', aggfunc = 'count').plot.bar(stacked = True)
# 水平轴方向绘制 +h
df.pivot_table(index = 'city', columns = 'education', values = 'avg', aggfunc = 'count').plot.barh(stacked = True)

# 直方图
df.avg.hist() #有网格
df.avg.plot.hist()# 无网格
# 多重直方图(类似于面积图那种,同时画出好几个直方图叠加在一起)
# 数据要转换成多列,这个例子里以学历为列
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.hist(alpha = 0.5)
# unstack :series变成表格形式&行列转换
# 堆积
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.hist(alpha = 0.5,stacked = True, bins = 30)
# 横向转换用参数orientation = 'horizontal'


# 箱线图
# 首先得到一个多维度的数据框
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.box()
# 建议直接调用boxplot,更精简
df.boxplot(column = 'avg', by = 'education')
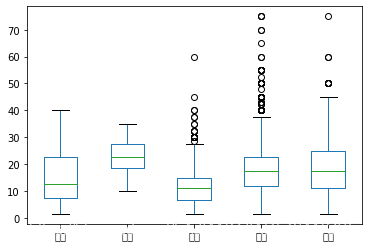

# 密度图
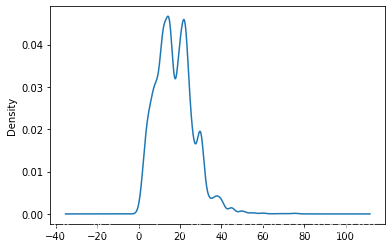
df.avg.plot.kde() #薪资的密度函数
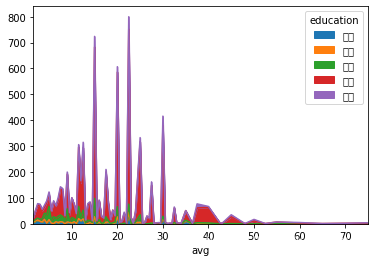
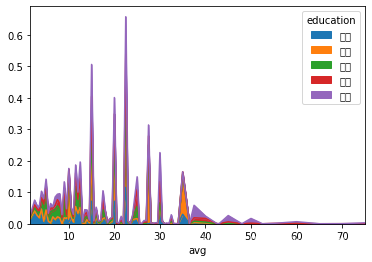
# 面积图
df.pivot_table(index = 'avg', columns = 'education', aggfunc = 'count', values = 'positionId').plot.area()
# 也可以对数据进行操作,变成百分比面积图
df.pivot_table(index = 'avg', columns = 'education', aggfunc = 'count', values = 'positionId').apply(lambda x:x/x.sum()).plot.area()
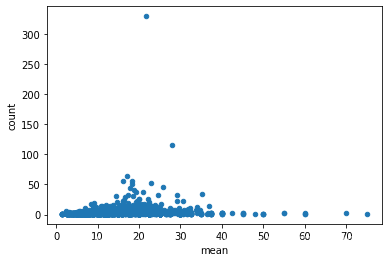
# 散点图
# 生成数据
df.groupby('companyId').aggregate(['mean','count']).avg.plot.scatter(x='mean',y='count')
# 散点矩阵图
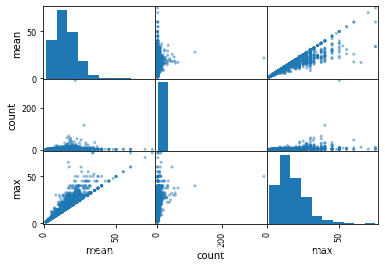
# 多个变量的关系;自身变量和自身变量则默认显示柱状图
matrix = df.groupby('companyId').aggregate(['mean','count','max']).avg
pd.plotting.scatter_matrix(frame = matrix)
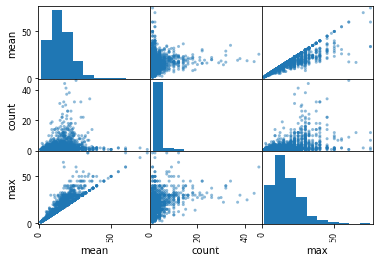
# 可以和数据清洗进行结合
pd.plotting.scatter_matrix(matrix.query('count < 50'))
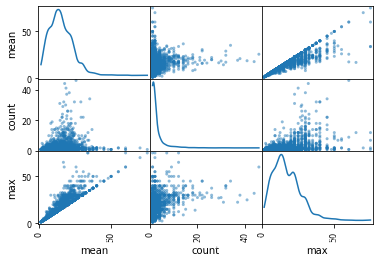
# 可以把柱状图变成密度图
pd.plotting.scatter_matrix(matrix.query('count < 50'),diagonal = 'kde')
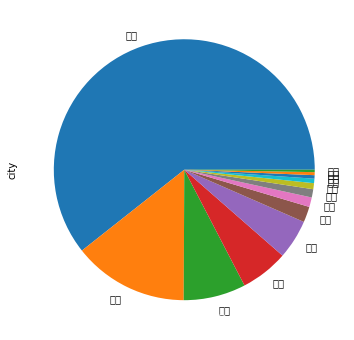
# 饼图
df.city.value_counts().plot.pie(figsize = (6,6))
2. matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotplib inline
# 解决问题:中文字符无法显示
plt.rcParams['font.sans-serif'] = ['SimHei']
grouped_city = df.groupby('city').avg.count()
plt.pie(grouped_city,labels = grouped_city.index)
# 默认字体改为黑体
这里存在的问题是运行了但是仍然不显示中文,
问题在字体库压根没这字体emm
step 1: 先找到自己的字体库路径
可输入代码 matplotlib.matplotlib_fname() 自己找找
e.g. /Users/user_name/opt/anaconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf
step 2: 去下载字体并放到当前路径,再运行结果还不行emm
n小时瞎搞瞎删的连pandas都用不了,然后卸载重新装了anaconda又成功了(迷
参考:
https://www.jianshu.com/p/15b5189f85a3
https://www.jianshu.com/p/d1eeaa58ff4e
# 解决问题:在坐标轴上能显示负数
plt.rcParams['axes.unicode_minus'] = False
plt.plot(np.random.random_integers(-20,20,20))
针对这种图像输出上显示内存地址,可以通过plt.show()不显示
# 几张图 & 画布的长和宽
plt.figure(1,figsize=(10,4))
plt.plot(np.random.random_integers(-20,20,20))
plt.title('折线图')
plt.xticks([0,15,20]) #调整x轴的刻度
plt.xlabel('x轴')
plt.show()

plt.plot(np.random.random_integers(-20,20,20))
plt.plot(np.random.random_integers(-20,20,20))
# 一层层叠加上去
# 增加图例
plt.legend(('No_1','No_2'))
# 两层括号,以元组的形式
plt.show()
# 或者
plt.plot(np.random.random_integers(-20,20,20),label = 'no1', color = 'r')
plt.plot(np.random.random_integers(-20,20,20),label = 'no2', color = 'b')
plt.legend()
plt.show()
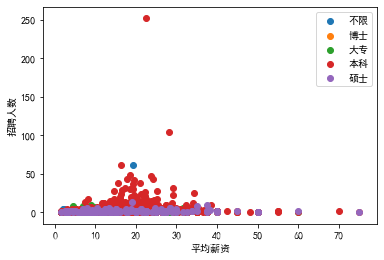
# 分类显示不同学历薪资分布
# 多重聚合记得用方括号
data = df.groupby(['education','companyId']).aggregate(['mean','count']).avg.reset_index()

for edu,grouped in data.groupby('education'):
#grouped:不同学历下面的数据框
x = grouped['mean']
y = grouped['count']
plt.scatter(x,y,label = edu)
plt.legend()
# plt.legend(loc = 'upper right')
plt.xlabel('平均薪资')
plt.ylabel('招聘人数')
plt.show()
# 绘制子图
plt.figure(figsize = (12,4))
plt.subplot(1,2,1) # 1行2列,此时绘制的是第一个图;可缩写成121
plt.plot(np.random.random_integers(-20,20,20),label = 'no1', color = 'r')
plt.subplot(1,2,2) # 1行2列,此时绘制的是第二个图
plt.plot(np.random.random_integers(-20,20,20),label = 'no2', color = 'b')
plt.legend()
plt.show()
plt.figure(figsize = (12,4))
# 第一张图
plt.subplot(221)
plt.plot(np.random.random_integers(-20,20,20),label = 'no1')
plt.plot(np.random.random_integers(-20,20,20),label = 'no2')
plt.legend()
# 第二张图
plt.subplot(222)
plt.plot(np.random.random_integers(-20,20,20),label = 'no3')
plt.plot(np.random.random_integers(-20,20,20),label = 'no4')
plt.legend()
# 第三张图
# 上面两张图不管,下面重置
plt.subplot(212)
plt.plot(np.random.random_integers(-20,20,20),label = 'no5')
plt.show()
python使用matplotlib:subplot绘制多个子图
plt.figure(figsize = (12,4))
# 第一张图
plt.subplot(221)
plt.plot(np.random.random_integers(-20,20,20),label = 'no1')
plt.plot(np.random.random_integers(-20,20,20),label = 'no2')
plt.legend()
# 第二张图
plt.subplot(223)
plt.plot(np.random.random_integers(-20,20,20),label = 'no3')
plt.plot(np.random.random_integers(-20,20,20),label = 'no4')
plt.legend()
# 第三张图
# 上面两张图不管,下面重置
plt.subplot(122)
plt.plot(np.random.random_integers(-20,20,20),label = 'no5')
plt.show()
data = df.groupby(['city','companyId']).aggregate(['mean','count']).avg.reset_index()
plt.figure(figsize = (16,8))
plt.subplot(121)
plt.plot(np.random.random_integers(-20,20,20),label = 'no1')
for city,grouped in data.groupby('city'):
#grouped:不同学历下面的数据框
x = grouped['mean']
y = grouped['count']
#⚠️放在这里
plt.subplot(122)
plt.scatter(x,y,label = city)
plt.legend()
# plt.legend(loc = 'upper right')
plt.xlabel('平均薪资')
plt.ylabel('招聘人数')
plt.show()

3. seaborn


- 分布
- distplot 概率分布图
- kdeplot 概率密度图
- joinplot 联合密度图
- pairplot 多变量图
- 分类
- boxplots 箱线图
- violinplots 提琴图
- barplot 柱形图
- factorplot 因子图
- 线性
- lmplot 回归图
- heatmap 热图
import seaborn as sns
columns = ['user_id','order_dt','order_products','order_amount']
df = pd.read_table('CDNOW_master.txt',names = columns, sep = '\s+')
# 直方图+概率密度图
sns.distplot(df.order_amount)
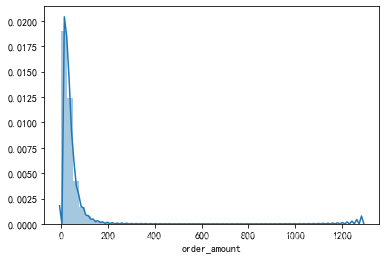
# 只有直方图
sns.distplot(df.order_amount,kde = False)
# 概率密度图
sns.kdeplot(df.order_amount)
# 联合密度图
grouped_user = df.groupby('user_id').sum()
sns.jointplot(grouped_user.order_products,grouped_user.order_amount, kind = 'reg')
# 默认散点图;order_products 销量 order_amount 金额
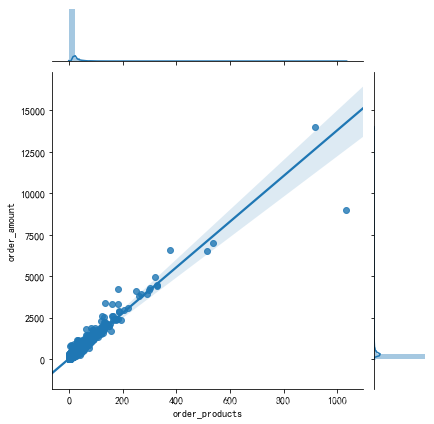
# 联合密度图
df['order_dt'] = pd.to_datetime(df.order_dt, format = '%Y%m%d')
rfm = df.pivot_table(index = 'user_id',
values = ['order_products','order_amount','order_dt'],
aggfunc = {
'order_dt' : 'max',
'order_amount' : 'sum',
'order_products' : 'sum'
})
rfm['R'] = (rfm.order_dt.max() - rfm.order_dt)/np.timedelta64(1,'D')
rfm.rename(columns = {'order_products':'F', 'order_amount':'M'}, inplace = True)
rfm.head()
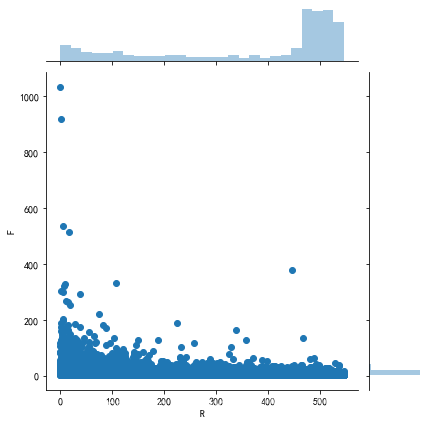
sns.jointplot(rfm.R,rfm.F)
# 三张表都加了元素
sns.jointplot(rfm.R,rfm.F,kind = 'reg')
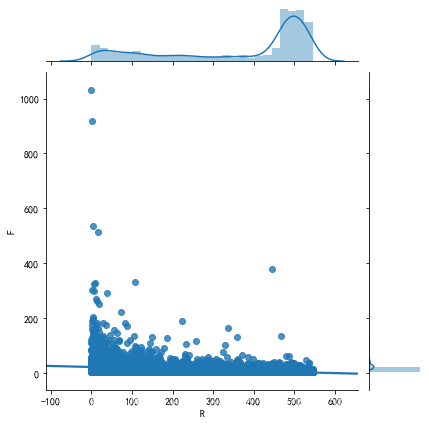
# 多变量图,类似于pandas的散点图矩阵
sns.pairplot(rfm)
# 其中参数hue是个分类变量,比如说男女,可以用不同的颜色来表示出来
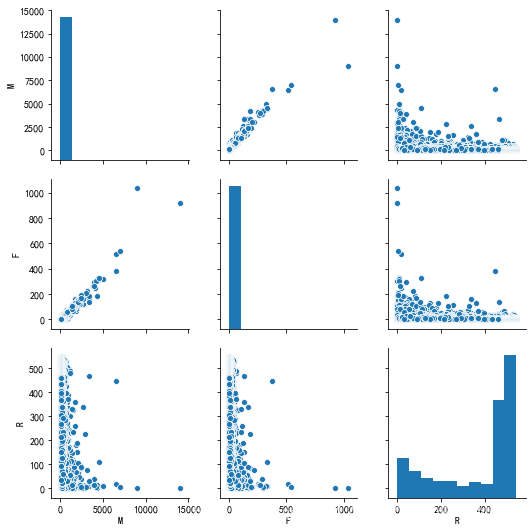
# 箱线图
df = pd.read_csv('cy.csv',encoding = 'gbk') # 餐饮数据
plt.figure(figsize = (20,5))
sns.boxplot(x = '类型', y = '口味', data = df)

df2 = df.query("(城市 == '上海') |(城市 == '北京')")
plt.figure(figsize = (20,5))
sns.boxplot(x = '类型', y = '口味', hue = '城市', data = df2)
# 增加一个对比的维度‘城市’

# 提琴图
plt.figure(figsize = (20,5))
sns.violinplot(x = '类型', y = '口味', data = df2)
# 数据集中 -> ‘胖瘦’程度

plt.figure(figsize = (20,5))
sns.violinplot(x = '类型', y = '口味', hue = '城市', data = df2)

# 拼接起来,比左右对比更加直观
plt.figure(figsize = (20,5))
sns.violinplot(x = '类型', y = '口味', hue = '城市', data = df2, split = True)

# 因子图
# 类似简化版的箱线图
# plt.figure(figsize = (20,5)) 画布拉大失效,因为因子图自带size参数(现在更名为height,aspect调整图片的高度
# 因子图 kind = 'box' 就会变成箱线图
sns.factorplot(x = '类型', y = '口味',data = df2, hue = '城市', height = 10, aspect = 2)

# 类似散点图矩阵的功能
sns.factorplot(x = '类型', y = '口味',data = df2, col = '城市', kind = 'violin',height = 5, aspect = 2)
# 当城市类别过多时,该函数仍然会机械的想把所有的图显示在一行,因此需要用到col_wrap参数
# hue是图表里面进行对比,col是整个图表进行对比
# 把col改成row则变成上下排列

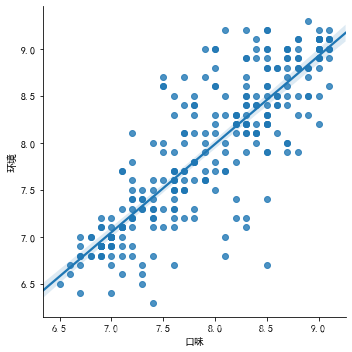
# 回归图
# 画出直线,不代表是线性关系,有可能是强行,一定要整体看
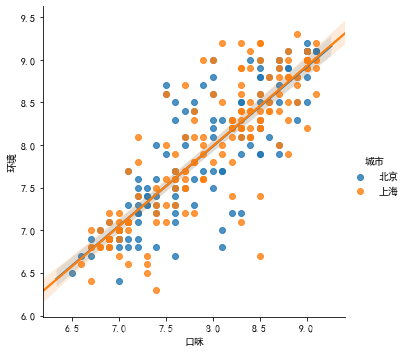
sns.lmplot(x = '口味', y = '环境', data = df2)
sns.lmplot(x = '口味', y = '环境', data = df2, hue = '城市')
# order = 1 默认为线性,可以进行修改
# 热力图
# 城市和餐厅类型是否与关联
pt = df.pivot_table(index = '城市', columns = '类型', values = '口味', aggfunc = 'mean')
plt.figure(figsize = (10,10))
sns.heatmap(pt)

sns.heatmap(pt,annot = True) #图上显示数值

4. python搭建BI —— superset
【世上无难事只要肯放弃 再见:> tableau我来了】
# 终端:创建虚拟环境
conda create -n superset python=3.7
# 激活虚拟环境
source activate superset
# 我用的是conda activate superset也可以
# 安装
/* 不是pip install superset
否则后面会报错
AttributeError: 'NoneType' object has no attribute 'auth_type'
但是按照网络教程的pip install superset==0.28.1
也会出现很多红字错误ERROR: Command errored out with exit status 1
*/
# 启动
# 到安装虚拟环境的路径
cd /opt/anaconda3/envs/superset
cd bin
python superset
# 最后一步会有些报错 no module named XXX 安装一下就好
# 初始化配置
fabmanager create-admin --app superset
# 创建账号,记住所输入的信息
/*
username[admin]:admin
user first name[admin]:shu
user last name[admin]:fen
email: sf@offer.com
password:offer
*/
⚠️注意,安装的时候 有个包怎么都装不上
No module named 'geohash’
解决办法:
- 改geohash所在的文件夹名字为Geohash「即首字母大写」
- 打开这个文件夹中的__init__.py,将第一行from geohash改为from .geohash
- 保存,再去终端pip install geohash
后来又出现了👇的问题
sqlalchemy_utils.exceptions.ImproperlyConfigured: 'cryptography' is required to use EncryptedType
就是缺少这个包 pip install cryptography就行
有问题戳这个链接:ubuntu16下部署apache superset趟坑指南(内有福利)
基本上都解决了
python superset db upgrade
python superset load_examples
python superset init
# 启动
python superset runserver #可能会说某个模块找不到,但是是linux的
python superset runserver -d #以开发者的形式进行激活














 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









