









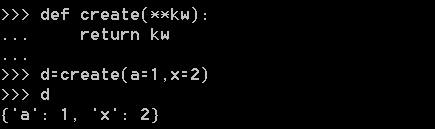
···关键字参数
【**kw本身就是dict类型的参数】,见下图:
··· 包装函数(访问限制)
属性是函数
class Student(object):
def __getattr__(self, attr):
if attr=='age':
return lambda: 25调用:
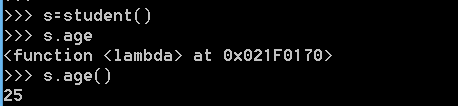
>>>s = Student()
>>>s.age()
解释:
age属性未定义,所以调用__getattr__()方法。此方法返回一个
函数lambda(也就是说属性age是一个函数),而函数必然是可执行的,
执行这个函数
s.age()才能得到函数的返回值。(相当于是
(s.age)() )

函数的包装
把需要调用的方法用匿名函数lambda包装起来,传递给有访问限制的私有类,引而不发,只有在调用私有类合适的方法的时候那个需要调用的方法才真正被调用出来。
class _Engine(object):
def __init__(self,connect):
self._connect=connect
print self._connect
def connect(self):
return self._connect()
engine=_Engine(lambda:25) #创建一个实例(对象object)
print engine
print engine.connect()
把lambda函数传递给私有类,这个类的构造函数把传递进来的lambda函数封装起来(访问限制),创建一个实例,这个实例就拥有了lambda 函数,调用这个实例的connect()方法来执行lambda 函数,即
print engine.connect() 就等价于print (lambda:25)()

user table的结构如下图:

执行下面一系列操作后得到结果:

cursor.description的结构是一个列表,表中元素是tuple,每个tuple的结构是:
mysql docs
(column_name,
type,
None,
None,
None,
None,
null_ok,
column_flags)
type,
None,
None,
None,
None,
null_ok,
column_flags)
所以cursor.description的结果就是对每一列的描述。每一列(tuple)的描述最重要的无非就是第一个元素column_name,那么我们把每一列的column_name和我们用cursor.fetchall()取得的具体的值一结合,就变成了这样的形式( column1_name , column2_name , column3_name , column4_name , column5_name )对应着
( 1 , u'zhuma' , none , none , none ),把这二者用我们自定义的类Dict组合即可得到形如
d = { column1_name :‘1’,column2_name:‘ u'zhuma' ’ , column3_name:none , column4_name: none , column5_name: none }的字典(实际就是
d = { u ' id ' :‘1’,u ' name ' :‘ u'zhuma' ’ , u ' email ' :none , u ' passwd ' : none , u ' last_modified ' : none }),这样我们就能用d.column1_name来获取查询结果了。
··· dict 的 pop() , values() , keys() , zip() 方法


dict 的 pop()方法说明:当key存在时,返回key相应的value;当key不存在时,返回pop(key , y)方法的第二个参数,即 y .
··· with方法 with
参考资料:
2.
S.O.
from __future__ import with_statement#for python2.5
class a(object):
def __enter__(self):
print 'sss'
return 'sss111'
#return self
def __exit__(self ,type, value, traceback):
print 'ok'
return False
with a() as s:
print s···完整源代码剖析:
#!/usr/bin/python
#-*-coding:utf-8-*-
#db.py
''' 设计数据库接口 以方便调用者使用 希望调用者可以通过:
from transwarp import db
db.create_engine(user='root',password='123456',database='test',host='127.0.0.1',port=3306)
然后直接操作sql语句
users=db.select('select * from user')
返回一个list 其中包含了所有的user信息。
其中每一个select和update等 都隐含了自动打开和关闭数据库 这样上层调用就完全不需要关心数据库底层连接
在一个数据库中执行多条sql语句 可以用with语句实现
with db.connection():
db.select('....')
db.update('....')
db.select('....')
同样如果在一个数据库事务中执行多个SQL语句 也可以用with实现
with db.transactions():
db.select('....')
db.update('....')
db.select('....')
'''
import time,uuid,functools,threading,logging
#Dict object : 重写dict 让其可以通过访问属性的方式访问对应的value
'''---------------------------------------------以下是Dict类的定义-----------------------------------------------------'''
class Dict(dict):
'''
一下是docttest.testmod()会调用作为测试的内容 也就是简单的unittest 单元测试
simple dict but spuport access as x.y style
>>> d1 = Dict()
>>> d1['x'] = 100
>>> d1.x
100
>>> d1.y = 200
>>> d1['y']
200
>>> d2 = Dict(a=1, b=2, c='3')
>>> d2.c
'3'
>>> d2['empty']
Traceback (most recent call last):
...
KeyError: 'empty'
>>> d2.empty
Traceback (most recent call last):
...
AttributeError: 'Dict' object has no attribute 'empty'
>>> d3 = Dict(('a', 'b', 'c'), (1, 2, 3))
>>> d3.a
1
>>> d3.b
2
>>> d3.c
3
'''
'''
@time 2015-02-10
@method __init__ 相当于其他语言中的构造函数
zip()将两个list糅合在一起 例如:
x=[1,2,3,4,5]
y=[6,7,8,9,10]
zip(x,y)-->就得到了[(1,6),(2,7),(3,8),(4,9),(5,10)]
'''
#创建实例的时候,第一个参数就是names(可以是list,也可以是tuple,它们是作为一个整体的参数出现的),第二个参数就是values,它们的默认参数都属都是空的tuple
#最后一个参数是关键字参数,即“a=1, b=2, c='3'”这样的
#特别提醒:【【【 如果是XXX=XXX这样形式的传入参数,只能是关键字参数,从而传值给**kw 】】】
def __init__(self,names=(),values=(),**kw): #自定义Dict是dict的派生类,python中的派生类不会自动调用基类构造函数__init__,所以要显式调用(用 super 方法更严谨)
super(Dict,self).__init__(**kw) #调用父类的构造方法
for k,v in zip(names,values):
self[k]=v
'''
@time 2015-02-10
@method __getattr__ 相当于新增加的get方法
如果对象调用的属性不存在的时候 解释器就会尝试从__getattr__()方法获得属性的值。
'''
#python获取属性的方法是d.a这样的形式,但dict本身不支持,所以可以调用__getattr__方法,返回d[a]
def __getattr__(self,key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Dict' object has no attribute '%s'" % key)
'''
@time 2015-02-10
@method __setattr__ 相当于新增加set方法,能用__setattr__是因为Dict继承自dict
'''
#形如d.a=1的属性设置(a是key,1是value),调用母类dict的方法使得d[a]=1
def __setattr__(self,key,values):
self[key]=values
'''---------------------------------------------以上是Dict类的定义-----------------------------------------------------'''
'''
@time 2015-02-10
@method next_id() uuid4() make a random UUID 得到一个随机的UUID
如果没有传入参数根据系统当前时间15位和一个随机得到的UUID 填充3个0 组成一个长度为50的字符串
'''
def next_id(t=None):
'''
Return next id as 50-char string
args:
t:unix timestamp,default to None and using time.time().
'''
if t is None:
t=time.time()
return '%015d%s000' %(int(t*1000),uuid.uuid4.hex)
'''
@time 2015-02-10
@method _profiling 记录sql 的运行状态
'''
def _profiling(start,sql=''):
'''
单下划线开头的方法名或者属性 不会在 from moduleName import * 中被导入 也就是说只有本模块中可以访问
'''
t=time.time()-start
if t>0.1:
logging.warning('[PROFILING] [DB] %s:%s' %(t,sql))
else:
logging.info('[PROFILING] [DB] %s:%s' %(t,sql))
#所有的异常默认都继承自Exception
class DBError(Exception):
pass
class MultiColumnsError(DBError):
pass
#global engine object 保存着mysql数据库的连接
engine=None
class _Engine(object):
def __init__(self,connect):
self._connect=connect
def connect(self):
return self._connect() #这里传入的参数connect是一个函数 将函数调用后 将函数的结果也是一个函数返回
#【【【关键字参数**kw本身就是dict类型的参数】】】
def create_engine(user,password,database,host='127.0.0.1',port=3306,**kw):
import mysql.connector #导入mysql模块
global engine #global关键字 说明这个变量在外部定义了 这是一个全局变量
if engine is not None:
raise DBError('Engine is already initialized') #如果连接已经存在表示连接重复 则抛出一个数据库异常
#params 和 defaults 都是 dict
#关于python mysql的参数设置可参考 http://dev.mysql.com/doc/connector-python/en/connector-python-connectargs.html
params=dict(user=user,password=password,database=database,host=host,port=port) #数据库基本的连接信息
defaults=dict(use_unicode=True,charset='utf8',collation='utf8_general_ci',autocommit=False) #数据库扩充的连接设置
'''
下面的循环是合并 defaults 和 kw 的 key-value 到 params 字典中
在kw中寻找defaults的key-value 对
如果kw中存在defaults的key,就返回kw(用户传入的参数)的value作为params的key值;
如果kw中不存在,就返回defaults的value作为params的key值。
'''
for key,value in defaults.iteritems():#将defaults和kw中的键值对保存到params中 如果有一个key两边都存在那么就保存kw的
params[key]=kw.pop(key,value)
#dict.update(dict2):update()函数把字典dict2的键/值对更新到dict里
params.update(kw)
params['buffered']=True #增加sql的参数
engine=_Engine(lambda:mysql.connector.connect(**params)) #这一句的目的就是包装,将数据库的连接方法私有化
#当调用engine.connect()的时候才真正的进行了数据库的连接,即mysql.connector.connect(**params)。
#转了一大圈就为了把mysql.connector.connect(**params)私有化,并方便使用engine.connect()来进行数据库连接
#test connection....
logging.info('Init mysql engine <%s> ok' % hex(id(engine))) #转化为十六进制
'''===================以上通过engine这个全局变量就可以获得一个数据库连接,重复连接抛异常============================='''
'''对数据库连接以及最基本的操作进行了封装'''
class _LasyConnection(object):
def __init__(self):
self.connection=None
def cursor(self):
if self.connection is None:
'''
哈哈哈,终于找到你了,就是这一句!
connection=engine.connect()
利用create_engine中创建出来的engine实例,而engine实例又是通过_Engine对象创建出来的
'''
connection=engine.connect() #等价于conn=mysql.connector.connect(*params)
logging.info('open connection <%s>...' % hex(id(connection)))
self.connection = connection
return self.connection.cursor() #把游标也对象化,相当于执行cursor=conn.cursor()
#conn.commit()和conn.rollback()是完全相反的操作,前者是把对数据库的操作提交并更新数据库,后者是撤销所有的数据库操作(不更新数据库)
def commit(self):
self.connection.commit() #相当于conn.commit(),提交更新事务
def rollback(self):
#print '================='
#print self.connection
self.connection.rollback() #相当于conn.rollback(), 回滚事务
def cleanup(self): #执行conn.close(),关闭连接
if self.connection:
connection = self.connection
self.connection=None #关闭连接
logging.info('close connection <%s>...' %hex(id(connection)))
connection.close() #相当于conn.close()
'''
下面的操作是针对每个数据库连接,即threadlocal,互不影响的,需要调用上面封装好的基本数据库操作
接下来解决对于不同的线程数据库连接应该是不一样的 于是创建一个变量 是一个threadlocal 对象
'''
class _DbCtx(threading.local):
'''Thread local object that holds connection info'''
def __init__(self):
self.connection=None #创建属性
self.transactions = 0
def is_init(self): #对于每个数据库连接来说
return not self.connection is None #判断是否已经进行了初始化,开了连接就返回 真
def init(self): #创建一个数据库连接对象(实例)
logging.info('open lazy connection...')
self.connection=_LasyConnection() #创建一个数据库连接对象(实例),这样self.connection就可以调用_LasyConnection()类定义的所有方法
#print threading.current_thread().name
#print id(self.connection)
self.transactions=0
def cursor(self):
'''return cursor'''
return self.connection.cursor() #这里调用的是_LasyConnection()类的cursor()方法
def cleanup(self):
self.connection.cleanup() #这里调用的是_LasyConnection()类的cleanup()方法
self.connection=None
#_db_ctx调用is_init(),init(),cleanup(),cursor()方法时,可以直接调用如_db_ctx.cleanup()
#但是_DbCtx()类中没写commit()和rollback()方法,若想调用_db_ctx.init(),就得在创建了_LasyConnection()类的self.connection对象后,用self.connection.commit()来调用_LasyConnection()类的commit()方法
#由于它继承threading.local 是一个threadlocal对象 所以它对于每一个线程都是不一样的。
#所以当需要数据库连接的时候就使用它来创建
_db_ctx=_DbCtx() #每个线程都有自己的_db_ctx实例(object 对象)
print '-------------------------------------------------------------------------------------'
print _db_ctx.connection, _db_ctx.transactions #connection和transactions都是 _db_ctx 的属性
print '-------------------------------------------------------------------------------------'
'''=====================================以上通过_db_ctx就可以打开和关闭连接=============================================='''
#通过with语句让数据库连接可以自动创建和关闭
'''
with 语句:
with 后面的语句会返回 _ConnectionCtx 对象 然后调用这个对象的 __enter__方法得到返回值 返回值赋值给as后面的变量 然后执行
with下面的语句 执行完毕后 调用那个对象的 __exit__()方法
'''
class _ConnectionCtx(object):
'''
_ConnectionCtx object that can open and close connection context._ConnectionCtx object can nested and only the most
outer connection has effect
with connection():
pass
with connection():
pass
'''
def __enter__(self):
global _db_ctx
self.should_cleanup=False
if not _db_ctx.is_init(): #如果没有连接数据库
_db_ctx.init() #创建数据库连接对象self.connection
self.should_cleanup=True
return self
def __exit__(self,type,value,trace):
global _db_ctx
if self.should_cleanup:
_db_ctx.cleanup()
def connection():
'''
return _ConnectionCtx object that can be used by 'with' statement :
with connection:
pass
'''
return _ConnectionCtx()
#采用装饰器的方法 让其能够进行共用同一个数据库连接
def with_connection(func): #定义with_connection装饰器函数,用于下面select_one(),select_int()等函数,【【【用于对这些函数执行额外的操作——with操作!】】】
''' #而with connection()中的connection()是上下文管理器【对象】,必须定义__enter__()和__exit__()方法,以保证func(*args,**kw)函数的正常退出
Decorater for reuse connection
@with_connection #相当于执行with_connection(func)
def func(*args,**kw):
...
...
'''
#@functools.wraps(func)
def wrapper(*args,**kw):
with connection(): #with 是对函数func 额外做的事情
return func(*args,**kw)
return wrapper
#================================================以下是事务处理=======================================================
'''知识点与数据库连接知识点相同
class _ConnectionCtx(object):
#_ConnectionCtx object that can open and close connection context._ConnectionCtx object can nested and only the most
#outer connection has effect
#with connection():
# pass
# with connection():
# pass
def __enter__(self):
global _db_ctx
self.should_cleanup=False
if not _db_ctx.is_init(): #如果没有连接数据库
_db_ctx.init()
self.should_cleanup=True
return self
def __exit__(self,type,value,trace):
global _db_ctx
if self.should_cleanup:
_db_ctx.cleanup()
'''
class _TransactionCtx(object):
'''
_transactionCtx object that can handle transactions
with _transactionCtx():
pass
'''
def __enter__(self):
global _db_ctx
#print '++++++++++++++++++++++++++++++++++++++++++++++++++'
self.should_close_conn = False
if not _db_ctx.is_init():
#needs open a connection first:
_db_ctx.init()
self.should_close_conn=True
_db_ctx.transactions=_db_ctx.transactions+1
'''
print '---------------------------------------------------------------------------'
print _db_ctx.transactions #_db_ctx.transactions的值只能是1
print '---------------------------------------------------------------------------'
'''
logging.info('begin transactions...' if _db_ctx.transactions==1 else 'join current transactions') #一般都是前者
#print '===========',_db_ctx.is_init()
return self
def __exit__(self,type,value,trace):
global _db_ctx
_db_ctx.transactions=_db_ctx.transactions-1
'''
print '---------------------------------------------------------------------------'
print _db_ctx.transactions #_db_ctx.transactions的值只能是0
print '---------------------------------------------------------------------------'
'''
try:
if _db_ctx.transactions==0:
#print '----------------type:',type
#print '----------------value:',value
#print '----------------trace:',trace
if type is None:
self.commit()
else:
self.rollback()
finally:
if self.should_close_conn:
_db_ctx.cleanup()
def commit(self): #写下面这两个方法,是为了给上面的__exit__()方法调用
global _db_ctx
logging.info('commit transaction....')
try:
_db_ctx.connection.commit()
logging.info('commit ok.')
except:
logging.warning('commit failed.try rollback...')
#print dir(_db_ctx.connection)
_db_ctx.connection.rollback()
logging.warning('rollback ok')
raise
def rollback(self):
global _db_ctx
logging.warning('rollback transaction....')
_db_ctx.connection.rollback()
logging.info('rollback ok...')
def transaction():
'''
Create a transaction object so can use with statement:
with transaction():
pass
测试对数据库事务的处理功能:
insert()和update()是两个事务,在本模块中它们都是调用了_update()函数,而在_update()函数中有很重要的一句:
if _db_ctx.transactions==0:
# no transaction enviroment:
logging.info('auto commit')
_db_ctx.connection.commit()
with transaction()后,调用__enter___方法,db_ctx.transactions=1在执行update_profile()中的insert()和update()中一直保持为1,所以不可能提交事务。
不提交就有rollback()的可能。
一旦在with后面的代码块抛出任何异常时,__exit__()方法被执行。异常抛出时,与之关联的type,value和trace传给__exit__()方法
type是传入的错误类型,如果没有错误,__exit__()方法正常调用commit()(第一个测试例子),否则rollback(),之前所做的事务全部撤销(第二个测试例子)
>>> def update_profile(id, name, rollback):
... u = dict(id=id, name=name, email='%s@test.org' % name, passwd=name, last_modified=time.time())
... insert('user', **u)
... r = update('update user set passwd=? where id=?', name.upper(), id)
... if rollback:
... raise StandardError('will cause rollback...') #raise给with调用者transaction()函数的__exit__()方法
>>> with transaction(): #测试1例
... update_profile(900301, 'Python', False)
>>> select_one('select * from user where id=?', 900301).name
u'Python'
>>> with transaction(): #测试2例
... update_profile(900302, 'Ruby', True)
Traceback (most recent call last):
...
StandardError: will cause rollback...
>>> select('select * from user where id=?', 900302) #因为rollback,所以并未实际插入900302的数据
[]
'''
return _TransactionCtx()
def with_transaction(func): #定义装饰器函数,用于对函数的with功能的包装
'''
A decorator that makes function around transaction.
>>> @with_transaction
... def update_profile(id, name, rollback):
... u = dict(id=id, name=name, email='%s@test.org' % name, passwd=name, last_modified=time.time())
... insert('user', **u)
... r = update('update user set passwd=? where id=?', name.upper(), id)
... if rollback:
... raise StandardError('will cause rollback...')
>>> update_profile(8080, 'Julia', False)
>>> select_one('select * from user where id=?', 8080).passwd
u'JULIA'
>>> update_profile(9090, 'Robert', True)
Traceback (most recent call last):
...
StandardError: will cause rollback...
>>> select('select * from user where id=?', 9090)
[]
'''
@functools.wraps(func)
def wrapper(*args,**kw):
_start=time.time()
with transaction():
return func(*args,**kw)
_profiling(_start)
return wrapper
#===============================以上是事务处理======================================================================
def _select(sql,first,*args): #由first 来决定是select_one还是 select(_all)
'execute select SQL and return unique result or list results'
global _db_ctx
cursor = None
sql = sql.replace('?','%s') #字符串方法:字符替换
logging.info('SQL:%s,ARGS:%s' %(sql,args))
try:
cursor = _db_ctx.cursor()
cursor.execute(sql,args) #数据库的原始操作(sql是格式化后的字符串'xxx',args是一个tuple)
if cursor.description:
names=[x[0] for x in cursor.description] #返回结果集的描述, cursor.description是一个list,元素由tuple组成,x[0]是描述结果集的 列名 column-name
if first:
values=cursor.fetchone() #fursor.fetchone() 想取回所有结果用fursor.fetchall()
if not values:
return None
return Dict(names,values) #names和values都是tuple,这是我们自定义Dict类的zip方法在起作用
return [Dict(names,x) for x in cursor.fetchall()]
'''
返回一个list,元素是 dict,形如
users =>
[
{ "id": 1, "name": "Michael"},
{ "id": 2, "name": "Bob"},
{ "id": 3, "name": "Adam"}
]
'''
finally:
if cursor:
cursor.close()
@with_connection
def select_one(sql,*args):
'''
Execute select SQL and expected one result.
If no result found, return None.
If multiple results found, the first one returned.
>>> u1 = dict(id=100, name='Alice', email='alice@test.org', passwd='ABC-12345', last_modified=time.time())
>>> u2 = dict(id=101, name='Sarah', email='sarah@test.org', passwd='ABC-12345', last_modified=time.time())
>>> insert('user', **u1)
1
>>> insert('user', **u2)
1
>>> u = select_one('select * from user where id=?', 100)
>>> u.name
u'Alice'
>>> select_one('select * from user where email=?', 'abc@email.com')
>>> u2 = select_one('select * from user where passwd=? order by email', 'ABC-12345')
>>> u2.name
u'Alice'
'''
return _select(sql,True,*args)
@with_connection
def select_int(sql, *args):
'''
Execute select SQL and expected one int and only one int result.
>>> n = update('delete from user')
>>> u1 = dict(id=96900, name='Ada', email='ada@test.org', passwd='A-12345', last_modified=time.time())
>>> u2 = dict(id=96901, name='Adam', email='adam@test.org', passwd='A-12345', last_modified=time.time())
>>> insert('user', **u1)
1
>>> insert('user', **u2)
1
>>> select_int('select count(*) from user')
2
>>> select_int('select count(*) from user where email=?', 'ada@test.org')
1
>>> select_int('select count(*) from user where email=?', 'notexist@test.org')
0
>>> select_int('select id from user where email=?', 'ada@test.org')
96900
>>> select_int('select id, name from user where email=?', 'ada@test.org')
Traceback (most recent call last):
...
MultiColumnsError: Expect only one column.
'''
d = _select(sql, True, *args)
if len(d)!=1:
raise MultiColumnsError('Expect only one column.')
return d.values()[0] #字典的values()方法,d.values()[0]得到的结果是id的值
@with_connection
def select(sql, *args):
'''
Execute select SQL and return list or empty list if no result.
>>> u1 = dict(id=200, name='Wall.E', email='wall.e@test.org', passwd='back-to-earth', last_modified=time.time())
>>> u2 = dict(id=201, name='Eva', email='eva@test.org', passwd='back-to-earth', last_modified=time.time())
>>> insert('user', **u1)
1
>>> insert('user', **u2)
1
>>> L = select('select * from user where id=?', 900900900)
>>> L
[]
>>> L = select('select * from user where id=?', 200)
>>> L[0].email
u'wall.e@test.org'
>>> L = select('select * from user where passwd=? order by id desc', 'back-to-earth')
>>> L[0].name
u'Eva'
>>> L[1].name
u'Wall.E'
'''
return _select(sql, False, *args)
'''
update('drop table if exists user')
update('create table user (id int primary key, name text, email text, passwd text, last_modified real)')
'''
@with_connection
def _update(sql, *args):
#print 'a++++++++++++++++++++++++++++'
global _db_ctx
cursor = None
sql = sql.replace('?', '%s')
logging.info('SQL: %s, ARGS: %s' % (sql, args))
try:
cursor = _db_ctx.cursor()
cursor.execute(sql, args)
r = cursor.rowcount
if _db_ctx.transactions==0:
# no transaction enviroment:
logging.info('auto commit')
_db_ctx.connection.commit()
return r
finally:
if cursor:
cursor.close()
'''
>>> u1 = dict(id=200, name='Wall.E', email='wall.e@test.org', passwd='back-to-earth', last_modified=time.time())
>>> u2 = dict(id=201, name='Eva', email='eva@test.org', passwd='back-to-earth', last_modified=time.time())
>>> insert('user', **u1)
1
>>> insert('user', **u2)
1
'''
def insert(table, **kw): #insert()函数把dict类型的数值转换为sql语句和待插入的数值,然后调用_update(sql, *args)执行正儿八经的sql语句进行插入
'''
Execute insert SQL.
>>> u1 = dict(id=2000, name='Bob', email='bob@test.org', passwd='bobobob', last_modified=time.time())
>>> insert('user', **u1)
1
>>> u2 = select_one('select * from user where id=?', 2000) #u2是个字典, 【u2==u1】
>>> u2.name
u'Bob'
>>> insert('user', **u2)
Traceback (most recent call last):
...
IntegrityError: 1062 (23000): Duplicate entry '2000' for key 'PRIMARY'
'''
#print '======================='
cols, args = zip(*kw.iteritems())
sql = 'insert into `%s` (%s) values (%s)' % (table, ','.join(['`%s`' % col for col in cols]), ','.join(['?' for i in range(len(cols))]))
return _update(sql, *args)
def update(sql, *args):
r'''
Execute update SQL.
>>> u1 = dict(id=1000, name='Michael', email='michael@test.org', passwd='123456', last_modified=time.time())
>>> insert('user', **u1)
1
>>> u2 = select_one('select * from user where id=?', 1000)
>>> u2.email
u'michael@test.org'
>>> u2.passwd
u'123456'
>>> update('update user set email=?, passwd=? where id=?', 'michael@example.org', '654321', 1000)
1
>>> u3 = select_one('select * from user where id=?', 1000)
>>> u3.email
u'michael@example.org'
>>> u3.passwd
u'654321'
>>> update('update user set passwd=? where id=?', '***', '123\' or id=\'456')
0
'''
#print sql,args
return _update(sql, *args)
'''
@with_connection
def a():
global _db_ctx
print _db_ctx.is_init()
'''
if __name__ == '__main__':
logging.basicConfig(level=logging.DEBUG)
#Dict()
#create_engine('root','123456','pythonstudy')
#print engine.connect()
#create_engine('root','123456','pythonstudy')
'''
import threading
d1=threading.Thread(target=_db_ctx.init)
d2=threading.Thread(target=_db_ctx.init)
d1.start()
d2.start()
d1.join()
d2.join()
这样测试可以看到每一个线程的数据库连接的id都不是一样的 可以知道每一个线程拥有不同的数据库连接
'''
create_engine('root', '19921005', 'test')
'''
a()
print _db_ctx
'''
'''
with transaction():
print 'dd'
u1=dict(id=900301,name='python',email='python@test.org' ,passwd='python',last_modified=time.time())
insert('user',**u1)
print 'hellp'
'''
update('drop table if exists user')
update('create table user (id int primary key, name text, email text, passwd text, last_modified real)')
import doctest
doctest.testmod()
关键字参数【**kw本身就是dict类型的参数】,见下图:
··· 包装函数(访问限制)
属性是函数class Student(object):
def __getattr__(self, attr):
if attr=='age':
return lambda: 25调用:
>>>s = Student()
>>>s.age()
解释:
age属性未定义,所以调用__getattr__()方法。此方法返回一个
函数lambda(也就是说属性age是一个函数),而函数必然是可执行的,
执行这个函数
s.age()才能得到函数的返回值。(相当于是
(s.age)() )
函数的包装
把需要调用的方法用匿名函数lambda包装起来,传递给有访问限制的私有类,引而不发,只有在调用私有类合适的方法的时候那个需要调用的方法才真正被调用出来。
class _Engine(object):
def __init__(self,connect):
self._connect=connect
print self._connect
def connect(self):
return self._connect()
engine=_Engine(lambda:25) #创建一个实例(对象object)
print engine
print engine.connect()
把lambda函数传递给私有类,这个类的构造函数把传递进来的lambda函数封装起来(访问限制),创建一个实例,这个实例就拥有了lambda 函数,调用这个实例的connect()方法来执行lambda 函数,即
print engine.connect() 就等价于print (lambda:25)()
user table的结构如下图:
执行下面一系列操作后得到结果:
cursor.description的结构是一个列表,表中元素是tuple,每个tuple的结构是:
mysql docs
(column_name,
type,
None,
None,
None,
None,
null_ok,
column_flags)
type,
None,
None,
None,
None,
null_ok,
column_flags)
所以cursor.description的结果就是对每一列的描述。每一列(tuple)的描述最重要的无非就是第一个元素column_name,那么我们把每一列的column_name和我们用cursor.fetchall()取得的具体的值一结合,就变成了这样的形式( column1_name , column2_name , column3_name , column4_name , column5_name )对应着
( 1 , u'zhuma' , none , none , none ),把这二者用我们自定义的类Dict组合即可得到形如
d = { column1_name :‘1’,column2_name:‘ u'zhuma' ’ , column3_name:none , column4_name: none , column5_name: none }的字典(实际就是
d = { u ' id ' :‘1’,u ' name ' :‘ u'zhuma' ’ , u ' email ' :none , u ' passwd ' : none , u ' last_modified ' : none }),这样我们就能用d.column1_name来获取查询结果了。
··· dict 的 pop() , values() , keys() , zip() 方法
dict 的 pop()方法说明:当key存在时,返回key相应的value;当key不存在时,返回pop(key , y)方法的第二个参数,即 y .
··· with方法 with
参考资料:
2.
S.O.
from __future__ import with_statement#for python2.5
class a(object):
def __enter__(self):
print 'sss'
return 'sss111'
#return self
def __exit__(self ,type, value, traceback):
print 'ok'
return False
with a() as s:
print s···完整源代码剖析:
#!/usr/bin/python
#-*-coding:utf-8-*-
#db.py
''' 设计数据库接口 以方便调用者使用 希望调用者可以通过:
from transwarp import db
db.create_engine(user='root',password='123456',database='test',host='127.0.0.1',port=3306)
然后直接操作sql语句
users=db.select('select * from user')
返回一个list 其中包含了所有的user信息。
其中每一个select和update等 都隐含了自动打开和关闭数据库 这样上层调用就完全不需要关心数据库底层连接
在一个数据库中执行多条sql语句 可以用with语句实现
with db.connection():
db.select('....')
db.update('....')
db.select('....')
同样如果在一个数据库事务中执行多个SQL语句 也可以用with实现
with db.transactions():
db.select('....')
db.update('....')
db.select('....')
'''
import time,uuid,functools,threading,logging
#Dict object : 重写dict 让其可以通过访问属性的方式访问对应的value
'''---------------------------------------------以下是Dict类的定义-----------------------------------------------------'''
class Dict(dict):
'''
一下是docttest.testmod()会调用作为测试的内容 也就是简单的unittest 单元测试
simple dict but spuport access as x.y style
>>> d1 = Dict()
>>> d1['x'] = 100
>>> d1.x
100
>>> d1.y = 200
>>> d1['y']
200
>>> d2 = Dict(a=1, b=2, c='3')
>>> d2.c
'3'
>>> d2['empty']
Traceback (most recent call last):
...
KeyError: 'empty'
>>> d2.empty
Traceback (most recent call last):
...
AttributeError: 'Dict' object has no attribute 'empty'
>>> d3 = Dict(('a', 'b', 'c'), (1, 2, 3))
>>> d3.a
1
>>> d3.b
2
>>> d3.c
3
'''
'''
@time 2015-02-10
@method __init__ 相当于其他语言中的构造函数
zip()将两个list糅合在一起 例如:
x=[1,2,3,4,5]
y=[6,7,8,9,10]
zip(x,y)-->就得到了[(1,6),(2,7),(3,8),(4,9),(5,10)]
'''
#创建实例的时候,第一个参数就是names(可以是list,也可以是tuple,它们是作为一个整体的参数出现的),第二个参数就是values,它们的默认参数都属都是空的tuple
#最后一个参数是关键字参数,即“a=1, b=2, c='3'”这样的
#特别提醒:【【【 如果是XXX=XXX这样形式的传入参数,只能是关键字参数,从而传值给**kw 】】】
def __init__(self,names=(),values=(),**kw): #自定义Dict是dict的派生类,python中的派生类不会自动调用基类构造函数__init__,所以要显式调用(用 super 方法更严谨)
super(Dict,self).__init__(**kw) #调用父类的构造方法
for k,v in zip(names,values):
self[k]=v
'''
@time 2015-02-10
@method __getattr__ 相当于新增加的get方法
如果对象调用的属性不存在的时候 解释器就会尝试从__getattr__()方法获得属性的值。
'''
#python获取属性的方法是d.a这样的形式,但dict本身不支持,所以可以调用__getattr__方法,返回d[a]
def __getattr__(self,key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Dict' object has no attribute '%s'" % key)
'''
@time 2015-02-10
@method __setattr__ 相当于新增加set方法,能用__setattr__是因为Dict继承自dict
'''
#形如d.a=1的属性设置(a是key,1是value),调用母类dict的方法使得d[a]=1
def __setattr__(self,key,values):
self[key]=values
'''---------------------------------------------以上是Dict类的定义-----------------------------------------------------'''
'''
@time 2015-02-10
@method next_id() uuid4() make a random UUID 得到一个随机的UUID
如果没有传入参数根据系统当前时间15位和一个随机得到的UUID 填充3个0 组成一个长度为50的字符串
'''
def next_id(t=None):
'''
Return next id as 50-char string
args:
t:unix timestamp,default to None and using time.time().
'''
if t is None:
t=time.time()
return '%015d%s000' %(int(t*1000),uuid.uuid4.hex)
'''
@time 2015-02-10
@method _profiling 记录sql 的运行状态
'''
def _profiling(start,sql=''):
'''
单下划线开头的方法名或者属性 不会在 from moduleName import * 中被导入 也就是说只有本模块中可以访问
'''
t=time.time()-start
if t>0.1:
logging.warning('[PROFILING] [DB] %s:%s' %(t,sql))
else:
logging.info('[PROFILING] [DB] %s:%s' %(t,sql))
#所有的异常默认都继承自Exception
class DBError(Exception):
pass
class MultiColumnsError(DBError):
pass
#global engine object 保存着mysql数据库的连接
engine=None
class _Engine(object):
def __init__(self,connect):
self._connect=connect
def connect(self):
return self._connect() #这里传入的参数connect是一个函数 将函数调用后 将函数的结果也是一个函数返回
#【【【关键字参数**kw本身就是dict类型的参数】】】
def create_engine(user,password,database,host='127.0.0.1',port=3306,**kw):
import mysql.connector #导入mysql模块
global engine #global关键字 说明这个变量在外部定义了 这是一个全局变量
if engine is not None:
raise DBError('Engine is already initialized') #如果连接已经存在表示连接重复 则抛出一个数据库异常
#params 和 defaults 都是 dict
#关于python mysql的参数设置可参考 http://dev.mysql.com/doc/connector-python/en/connector-python-connectargs.html
params=dict(user=user,password=password,database=database,host=host,port=port) #数据库基本的连接信息
defaults=dict(use_unicode=True,charset='utf8',collation='utf8_general_ci',autocommit=False) #数据库扩充的连接设置
'''
下面的循环是合并 defaults 和 kw 的 key-value 到 params 字典中
在kw中寻找defaults的key-value 对
如果kw中存在defaults的key,就返回kw(用户传入的参数)的value作为params的key值;
如果kw中不存在,就返回defaults的value作为params的key值。
'''
for key,value in defaults.iteritems():#将defaults和kw中的键值对保存到params中 如果有一个key两边都存在那么就保存kw的
params[key]=kw.pop(key,value)
#dict.update(dict2):update()函数把字典dict2的键/值对更新到dict里
params.update(kw)
params['buffered']=True #增加sql的参数
engine=_Engine(lambda:mysql.connector.connect(**params)) #这一句的目的就是包装,将数据库的连接方法私有化
#当调用engine.connect()的时候才真正的进行了数据库的连接,即mysql.connector.connect(**params)。
#转了一大圈就为了把mysql.connector.connect(**params)私有化,并方便使用engine.connect()来进行数据库连接
#test connection....
logging.info('Init mysql engine <%s> ok' % hex(id(engine))) #转化为十六进制
'''===================以上通过engine这个全局变量就可以获得一个数据库连接,重复连接抛异常============================='''
'''对数据库连接以及最基本的操作进行了封装'''
class _LasyConnection(object):
def __init__(self):
self.connection=None
def cursor(self):
if self.connection is None:
'''
哈哈哈,终于找到你了,就是这一句!
connection=engine.connect()
利用create_engine中创建出来的engine实例,而engine实例又是通过_Engine对象创建出来的
'''
connection=engine.connect() #等价于conn=mysql.connector.connect(*params)
logging.info('open connection <%s>...' % hex(id(connection)))
self.connection = connection
return self.connection.cursor() #把游标也对象化,相当于执行cursor=conn.cursor()
#conn.commit()和conn.rollback()是完全相反的操作,前者是把对数据库的操作提交并更新数据库,后者是撤销所有的数据库操作(不更新数据库)
def commit(self):
self.connection.commit() #相当于conn.commit(),提交更新事务
def rollback(self):
#print '================='
#print self.connection
self.connection.rollback() #相当于conn.rollback(), 回滚事务
def cleanup(self): #执行conn.close(),关闭连接
if self.connection:
connection = self.connection
self.connection=None #关闭连接
logging.info('close connection <%s>...' %hex(id(connection)))
connection.close() #相当于conn.close()
'''
下面的操作是针对每个数据库连接,即threadlocal,互不影响的,需要调用上面封装好的基本数据库操作
接下来解决对于不同的线程数据库连接应该是不一样的 于是创建一个变量 是一个threadlocal 对象
'''
class _DbCtx(threading.local):
'''Thread local object that holds connection info'''
def __init__(self):
self.connection=None #创建属性
self.transactions = 0
def is_init(self): #对于每个数据库连接来说
return not self.connection is None #判断是否已经进行了初始化,开了连接就返回 真
def init(self): #创建一个数据库连接对象(实例)
logging.info('open lazy connection...')
self.connection=_LasyConnection() #创建一个数据库连接对象(实例),这样self.connection就可以调用_LasyConnection()类定义的所有方法
#print threading.current_thread().name
#print id(self.connection)
self.transactions=0
def cursor(self):
'''return cursor'''
return self.connection.cursor() #这里调用的是_LasyConnection()类的cursor()方法
def cleanup(self):
self.connection.cleanup() #这里调用的是_LasyConnection()类的cleanup()方法
self.connection=None
#_db_ctx调用is_init(),init(),cleanup(),cursor()方法时,可以直接调用如_db_ctx.cleanup()
#但是_DbCtx()类中没写commit()和rollback()方法,若想调用_db_ctx.init(),就得在创建了_LasyConnection()类的self.connection对象后,用self.connection.commit()来调用_LasyConnection()类的commit()方法
#由于它继承threading.local 是一个threadlocal对象 所以它对于每一个线程都是不一样的。
#所以当需要数据库连接的时候就使用它来创建
_db_ctx=_DbCtx() #每个线程都有自己的_db_ctx实例(object 对象)
print '-------------------------------------------------------------------------------------'
print _db_ctx.connection, _db_ctx.transactions #connection和transactions都是 _db_ctx 的属性
print '-------------------------------------------------------------------------------------'
'''=====================================以上通过_db_ctx就可以打开和关闭连接=============================================='''
#通过with语句让数据库连接可以自动创建和关闭
'''
with 语句:
with 后面的语句会返回 _ConnectionCtx 对象 然后调用这个对象的 __enter__方法得到返回值 返回值赋值给as后面的变量 然后执行
with下面的语句 执行完毕后 调用那个对象的 __exit__()方法
'''
class _ConnectionCtx(object):
'''
_ConnectionCtx object that can open and close connection context._ConnectionCtx object can nested and only the most
outer connection has effect
with connection():
pass
with connection():
pass
'''
def __enter__(self):
global _db_ctx
self.should_cleanup=False
if not _db_ctx.is_init(): #如果没有连接数据库
_db_ctx.init() #创建数据库连接对象self.connection
self.should_cleanup=True
return self
def __exit__(self,type,value,trace):
global _db_ctx
if self.should_cleanup:
_db_ctx.cleanup()
def connection():
'''
return _ConnectionCtx object that can be used by 'with' statement :
with connection:
pass
'''
return _ConnectionCtx()
#采用装饰器的方法 让其能够进行共用同一个数据库连接
def with_connection(func): #定义with_connection装饰器函数,用于下面select_one(),select_int()等函数,【【【用于对这些函数执行额外的操作——with操作!】】】
''' #而with connection()中的connection()是上下文管理器【对象】,必须定义__enter__()和__exit__()方法,以保证func(*args,**kw)函数的正常退出
Decorater for reuse connection
@with_connection #相当于执行with_connection(func)
def func(*args,**kw):
...
...
'''
#@functools.wraps(func)
def wrapper(*args,**kw):
with connection(): #with 是对函数func 额外做的事情
return func(*args,**kw)
return wrapper
#================================================以下是事务处理=======================================================
'''知识点与数据库连接知识点相同
class _ConnectionCtx(object):
#_ConnectionCtx object that can open and close connection context._ConnectionCtx object can nested and only the most
#outer connection has effect
#with connection():
# pass
# with connection():
# pass
def __enter__(self):
global _db_ctx
self.should_cleanup=False
if not _db_ctx.is_init(): #如果没有连接数据库
_db_ctx.init()
self.should_cleanup=True
return self
def __exit__(self,type,value,trace):
global _db_ctx
if self.should_cleanup:
_db_ctx.cleanup()
'''
class _TransactionCtx(object):
'''
_transactionCtx object that can handle transactions
with _transactionCtx():
pass
'''
def __enter__(self):
global _db_ctx
#print '++++++++++++++++++++++++++++++++++++++++++++++++++'
self.should_close_conn = False
if not _db_ctx.is_init():
#needs open a connection first:
_db_ctx.init()
self.should_close_conn=True
_db_ctx.transactions=_db_ctx.transactions+1
'''
print '---------------------------------------------------------------------------'
print _db_ctx.transactions #_db_ctx.transactions的值只能是1
print '---------------------------------------------------------------------------'
'''
logging.info('begin transactions...' if _db_ctx.transactions==1 else 'join current transactions') #一般都是前者
#print '===========',_db_ctx.is_init()
return self
def __exit__(self,type,value,trace):
global _db_ctx
_db_ctx.transactions=_db_ctx.transactions-1
'''
print '---------------------------------------------------------------------------'
print _db_ctx.transactions #_db_ctx.transactions的值只能是0
print '---------------------------------------------------------------------------'
'''
try:
if _db_ctx.transactions==0:
#print '----------------type:',type
#print '----------------value:',value
#print '----------------trace:',trace
if type is None:
self.commit()
else:
self.rollback()
finally:
if self.should_close_conn:
_db_ctx.cleanup()
def commit(self): #写下面这两个方法,是为了给上面的__exit__()方法调用
global _db_ctx
logging.info('commit transaction....')
try:
_db_ctx.connection.commit()
logging.info('commit ok.')
except:
logging.warning('commit failed.try rollback...')
#print dir(_db_ctx.connection)
_db_ctx.connection.rollback()
logging.warning('rollback ok')
raise
def rollback(self):
global _db_ctx
logging.warning('rollback transaction....')
_db_ctx.connection.rollback()
logging.info('rollback ok...')
def transaction():
'''
Create a transaction object so can use with statement:
with transaction():
pass
测试对数据库事务的处理功能:
insert()和update()是两个事务,在本模块中它们都是调用了_update()函数,而在_update()函数中有很重要的一句:
if _db_ctx.transactions==0:
# no transaction enviroment:
logging.info('auto commit')
_db_ctx.connection.commit()
with transaction()后,调用__enter___方法,db_ctx.transactions=1在执行update_profile()中的insert()和update()中一直保持为1,所以不可能提交事务。
不提交就有rollback()的可能。
一旦在with后面的代码块抛出任何异常时,__exit__()方法被执行。异常抛出时,与之关联的type,value和trace传给__exit__()方法
type是传入的错误类型,如果没有错误,__exit__()方法正常调用commit()(第一个测试例子),否则rollback(),之前所做的事务全部撤销(第二个测试例子)
>>> def update_profile(id, name, rollback):
... u = dict(id=id, name=name, email='%s@test.org' % name, passwd=name, last_modified=time.time())
... insert('user', **u)
... r = update('update user set passwd=? where id=?', name.upper(), id)
... if rollback:
... raise StandardError('will cause rollback...') #raise给with调用者transaction()函数的__exit__()方法
>>> with transaction(): #测试1例
... update_profile(900301, 'Python', False)
>>> select_one('select * from user where id=?', 900301).name
u'Python'
>>> with transaction(): #测试2例
... update_profile(900302, 'Ruby', True)
Traceback (most recent call last):
...
StandardError: will cause rollback...
>>> select('select * from user where id=?', 900302) #因为rollback,所以并未实际插入900302的数据
[]
'''
return _TransactionCtx()
def with_transaction(func): #定义装饰器函数,用于对函数的with功能的包装
'''
A decorator that makes function around transaction.
>>> @with_transaction
... def update_profile(id, name, rollback):
... u = dict(id=id, name=name, email='%s@test.org' % name, passwd=name, last_modified=time.time())
... insert('user', **u)
... r = update('update user set passwd=? where id=?', name.upper(), id)
... if rollback:
... raise StandardError('will cause rollback...')
>>> update_profile(8080, 'Julia', False)
>>> select_one('select * from user where id=?', 8080).passwd
u'JULIA'
>>> update_profile(9090, 'Robert', True)
Traceback (most recent call last):
...
StandardError: will cause rollback...
>>> select('select * from user where id=?', 9090)
[]
'''
@functools.wraps(func)
def wrapper(*args,**kw):
_start=time.time()
with transaction():
return func(*args,**kw)
_profiling(_start)
return wrapper
#===============================以上是事务处理======================================================================
def _select(sql,first,*args): #由first 来决定是select_one还是 select(_all)
'execute select SQL and return unique result or list results'
global _db_ctx
cursor = None
sql = sql.replace('?','%s') #字符串方法:字符替换
logging.info('SQL:%s,ARGS:%s' %(sql,args))
try:
cursor = _db_ctx.cursor()
cursor.execute(sql,args) #数据库的原始操作(sql是格式化后的字符串'xxx',args是一个tuple)
if cursor.description:
names=[x[0] for x in cursor.description] #返回结果集的描述, cursor.description是一个list,元素由tuple组成,x[0]是描述结果集的 列名 column-name
if first:
values=cursor.fetchone() #fursor.fetchone() 想取回所有结果用fursor.fetchall()
if not values:
return None
return Dict(names,values) #names和values都是tuple,这是我们自定义Dict类的zip方法在起作用
return [Dict(names,x) for x in cursor.fetchall()]
'''
返回一个list,元素是 dict,形如
users =>
[
{ "id": 1, "name": "Michael"},
{ "id": 2, "name": "Bob"},
{ "id": 3, "name": "Adam"}
]
'''
finally:
if cursor:
cursor.close()
@with_connection
def select_one(sql,*args):
'''
Execute select SQL and expected one result.
If no result found, return None.
If multiple results found, the first one returned.
>>> u1 = dict(id=100, name='Alice', email='alice@test.org', passwd='ABC-12345', last_modified=time.time())
>>> u2 = dict(id=101, name='Sarah', email='sarah@test.org', passwd='ABC-12345', last_modified=time.time())
>>> insert('user', **u1)
1
>>> insert('user', **u2)
1
>>> u = select_one('select * from user where id=?', 100)
>>> u.name
u'Alice'
>>> select_one('select * from user where email=?', 'abc@email.com')
>>> u2 = select_one('select * from user where passwd=? order by email', 'ABC-12345')
>>> u2.name
u'Alice'
'''
return _select(sql,True,*args)
@with_connection
def select_int(sql, *args):
'''
Execute select SQL and expected one int and only one int result.
>>> n = update('delete from user')
>>> u1 = dict(id=96900, name='Ada', email='ada@test.org', passwd='A-12345', last_modified=time.time())
>>> u2 = dict(id=96901, name='Adam', email='adam@test.org', passwd='A-12345', last_modified=time.time())
>>> insert('user', **u1)
1
>>> insert('user', **u2)
1
>>> select_int('select count(*) from user')
2
>>> select_int('select count(*) from user where email=?', 'ada@test.org')
1
>>> select_int('select count(*) from user where email=?', 'notexist@test.org')
0
>>> select_int('select id from user where email=?', 'ada@test.org')
96900
>>> select_int('select id, name from user where email=?', 'ada@test.org')
Traceback (most recent call last):
...
MultiColumnsError: Expect only one column.
'''
d = _select(sql, True, *args)
if len(d)!=1:
raise MultiColumnsError('Expect only one column.')
return d.values()[0] #字典的values()方法,d.values()[0]得到的结果是id的值
@with_connection
def select(sql, *args):
'''
Execute select SQL and return list or empty list if no result.
>>> u1 = dict(id=200, name='Wall.E', email='wall.e@test.org', passwd='back-to-earth', last_modified=time.time())
>>> u2 = dict(id=201, name='Eva', email='eva@test.org', passwd='back-to-earth', last_modified=time.time())
>>> insert('user', **u1)
1
>>> insert('user', **u2)
1
>>> L = select('select * from user where id=?', 900900900)
>>> L
[]
>>> L = select('select * from user where id=?', 200)
>>> L[0].email
u'wall.e@test.org'
>>> L = select('select * from user where passwd=? order by id desc', 'back-to-earth')
>>> L[0].name
u'Eva'
>>> L[1].name
u'Wall.E'
'''
return _select(sql, False, *args)
'''
update('drop table if exists user')
update('create table user (id int primary key, name text, email text, passwd text, last_modified real)')
'''
@with_connection
def _update(sql, *args):
#print 'a++++++++++++++++++++++++++++'
global _db_ctx
cursor = None
sql = sql.replace('?', '%s')
logging.info('SQL: %s, ARGS: %s' % (sql, args))
try:
cursor = _db_ctx.cursor()
cursor.execute(sql, args)
r = cursor.rowcount
if _db_ctx.transactions==0:
# no transaction enviroment:
logging.info('auto commit')
_db_ctx.connection.commit()
return r
finally:
if cursor:
cursor.close()
'''
>>> u1 = dict(id=200, name='Wall.E', email='wall.e@test.org', passwd='back-to-earth', last_modified=time.time())
>>> u2 = dict(id=201, name='Eva', email='eva@test.org', passwd='back-to-earth', last_modified=time.time())
>>> insert('user', **u1)
1
>>> insert('user', **u2)
1
'''
def insert(table, **kw): #insert()函数把dict类型的数值转换为sql语句和待插入的数值,然后调用_update(sql, *args)执行正儿八经的sql语句进行插入
'''
Execute insert SQL.
>>> u1 = dict(id=2000, name='Bob', email='bob@test.org', passwd='bobobob', last_modified=time.time())
>>> insert('user', **u1)
1
>>> u2 = select_one('select * from user where id=?', 2000) #u2是个字典, 【u2==u1】
>>> u2.name
u'Bob'
>>> insert('user', **u2)
Traceback (most recent call last):
...
IntegrityError: 1062 (23000): Duplicate entry '2000' for key 'PRIMARY'
'''
#print '======================='
cols, args = zip(*kw.iteritems())
sql = 'insert into `%s` (%s) values (%s)' % (table, ','.join(['`%s`' % col for col in cols]), ','.join(['?' for i in range(len(cols))]))
return _update(sql, *args)
def update(sql, *args):
r'''
Execute update SQL.
>>> u1 = dict(id=1000, name='Michael', email='michael@test.org', passwd='123456', last_modified=time.time())
>>> insert('user', **u1)
1
>>> u2 = select_one('select * from user where id=?', 1000)
>>> u2.email
u'michael@test.org'
>>> u2.passwd
u'123456'
>>> update('update user set email=?, passwd=? where id=?', 'michael@example.org', '654321', 1000)
1
>>> u3 = select_one('select * from user where id=?', 1000)
>>> u3.email
u'michael@example.org'
>>> u3.passwd
u'654321'
>>> update('update user set passwd=? where id=?', '***', '123\' or id=\'456')
0
'''
#print sql,args
return _update(sql, *args)
'''
@with_connection
def a():
global _db_ctx
print _db_ctx.is_init()
'''
if __name__ == '__main__':
logging.basicConfig(level=logging.DEBUG)
#Dict()
#create_engine('root','123456','pythonstudy')
#print engine.connect()
#create_engine('root','123456','pythonstudy')
'''
import threading
d1=threading.Thread(target=_db_ctx.init)
d2=threading.Thread(target=_db_ctx.init)
d1.start()
d2.start()
d1.join()
d2.join()
这样测试可以看到每一个线程的数据库连接的id都不是一样的 可以知道每一个线程拥有不同的数据库连接
'''
create_engine('root', '19921005', 'test')
'''
a()
print _db_ctx
'''
'''
with transaction():
print 'dd'
u1=dict(id=900301,name='python',email='python@test.org' ,passwd='python',last_modified=time.time())
insert('user',**u1)
print 'hellp'
'''
update('drop table if exists user')
update('create table user (id int primary key, name text, email text, passwd text, last_modified real)')
import doctest
doctest.testmod()
















 4393
4393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









