










我们就拿订单来说
订单数据非常庞大,将来一定会做分库分表。那么这种情况下, 要保证id的唯一,就不能靠数据库自增,而是自己来实现算法,生成唯一id。
雪花算法
用雪花算法生成唯一id:
雪花算法会生成一个64位的二进制数据,为一个Long型。(转换成字符串后长度最多19) ,其基本结构:
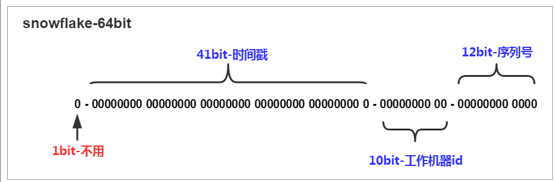
第一部分:备用
第二部分:41位为毫秒级时间(41位的长度可以使用69年)
第三部分:5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点)
第四部分:最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高。经测试snowflake每秒能够产生26万个ID。
全局高并发分布式ID
pom
<dependency>
<groupId>com.alanpoi</groupId>
<artifactId>alanpoi-common</artifactId>
<version>1.3.0</version>
</dependency>
使用
- 单节点可以可以直接使用 ID.getId.next(),多节点也可以使用,不能保证真正的分布式唯一
- 多节点通过配置alanpoi.serverid.enable=true,或者通过以下配置类Bean开启:
@Bean(destroyMethod = "destroy")
public ServerID initServerID(RedisTemplate redisTemplate) {
ServerID serverID = new ServerID(redisTemplate);
return serverID;
}
- 基础用法,ID.getId().next()、ID.getId.current()
##扩展
集成到Mybatis-plus(baomidou)
前提 :baomidou版本3.3.1.tmp或者以上
/**
* 注册ID生成器
* @return
*/
@Bean
public IdentifierGenerator idGenerator() {
return entity -> ID.getId().next();
}
配置类中加入上面这段代码,就会自动在实体注入ID属性值了
















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











