







链表
一、链表概念特性
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 。

特点:
- 上图每个数据块是一个结点,这些结点一般是从堆上申请来的。
- 链式结构在逻辑上是连续的,但物理上不一定连续。
链表结构由【单向/双向;循环/非循环;带头/不带头】几种形式进行组合,共有2×2×2=8种不同结构,不过我们常用的主要是 单向不带头非循环链表 和 双向不带头非循环链表 。对于前者来说,结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。对于后者,在Java的集合框架库中LinkedList底层实现就是无头双向非循环链表。
接下来我们就以不带头单向非循环链表和不带头双向循环链表进行展开,分别模拟实现它们的主要功能。
二、不带头单向非循环链表实现
首先给出功能接口(实现时元素类型为int):
//1.打印链表
public void display() {}
//2.递归逆序打印链表
public void displayReverse(SingleLinkedList.ListNode node) {}
//3.头插法
public void addFirst(int data) {}
//4.尾插法
public void addLast(int data) {}
//5.任意位置插入,第一个数据节点为0号下标
public boolean addIndex(int index, int data) {}
//6.查找是否包含关键字key是否在单链表当中
public boolean contains(int key) {}
//7.删除第一次出现关键字为key的节点
public void remove(int key) {}
//8.删除所有值为key的节点
public void removeAllKey(int key) {}
//9.得到单链表的长度
public int size() {}
//10.清空链表
public void clear() {}
🍑1、定义结点
这里是将结点看做单链表SingleLinkedList的一部分,所以将结点定义为链表类-SingleLinkedList的内部类。
注意: 这里的head结点并不表示链表带有单独头结点(不管链表是否为空,均含有一个头结点),而是用来表示该链表的第一个结点。
public class SingleLinkedList {
static class ListNode {
public int val;//存储的数据
public ListNode next;//存储下一个节点的地址
//构造方法
public ListNode(int val) {
this.val = val;
}
}
public ListNode head;//表示当前链表的头结点
//一些功能接口……
}
🍑2、打印链表
思路:从头结点开始向后变历链表,直到结点为空,打印完毕。
public void display() {
ListNode cur = this.head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
🍑3、使用递归逆序打印链表
思路:利用递归思想,先递后归,实现倒序打印链表。
public void displayRecu(ListNode node) {
if (node == null) {
return;
}
if (node.next == null) {
System.out.print(node.val+" ");
return;
}
displayRecu(node.next);
System.out.print(node.val+" ");
}
🍑4、头插

//头插法【比较简单,整体也没有特殊情况,head=null也没问题!】
public void addFirst(int data) {
ListNode newNode = new ListNode(data);
newNode.next = head;
head = newNode;
}
🍑5、尾插
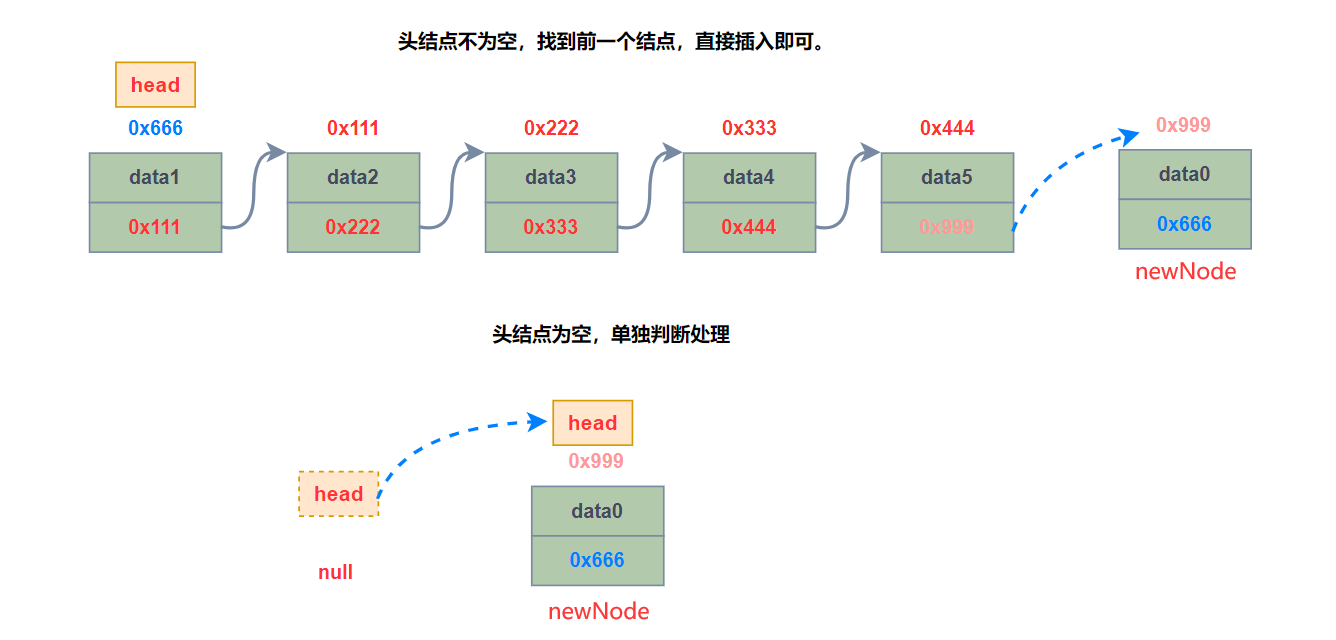
//尾插法【需要考虑头结点为null的情况】
public void addLast(int data) {
ListNode newNode = new ListNode(data);
ListNode cur = head;
//如果头结点为空,直接赋值
if (head == null) {
head = newNode;
return;
}
//找到尾结点
while (cur.next != null) {
cur = cur.next;
}
cur.next = newNode;
}
🍑6、指定位置插入

//下标合法性检测
private void checkIndex(int index) {
//这里的size()是自定义函数(后面讲解)
if (index < 0 || index > size()) {
throw new IndexOutOfException("下标越界!");
}
}
//找到 index-1位置的节点的地址
private ListNode findIndexSubOne(int index) {
ListNode cur = head;
int count = 0;
while (count != index - 1) {
cur = cur.next;
count++;
}
return cur;
}
//指定位置插入
public boolean addIndex(int index, int data) throws IndexOutOfException {
//判断坐标合法性
checkIndex(index);
//index=0这种情况需要特殊处理一下【1.head=null,index=0;2.head!=null,index=0】
if (index == 0) {
addFirst(data);
return true;
}
//尾插不用特殊考虑,以下包含了尾插
//中间插入
ListNode newNode = new ListNode(data);
ListNode cur = findIndexSubOne(index);
newNode.next = cur.next;
cur.next = newNode;
return true;
}
🍑7、查找是否包含关键字key是否在单链表当中
思路: 遍历链表,比对value值即可
public boolean contains(int key) {
ListNode cur = head;
while (cur != null) {
if (cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
🍑8、删除第一次出现关键字为key的节点

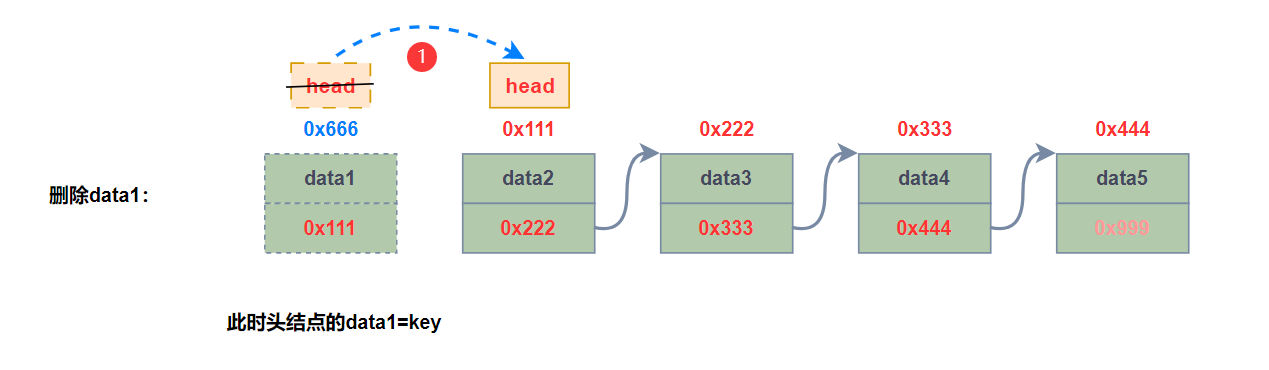
//删除第一次出现关键字为key的节点
public void remove(int key) {
//链表一个结点都没有
if (head == null) {
System.out.println("链表为空!");
return;
}
//判断头结点的val
if (head.val == key) {
head = head.next;
return;
}
//找到key的前驱结点
ListNode cur = head;
while (cur.next != null) {
if (cur.next.val == key) {
cur.next = cur.next.next;
return;
}
cur = cur.next;
}
System.out.println("未找到关键字" + key);
}
🍑9、删除所有值为key的节点
思路: 这个算法相比于“删除第一次出现关键字为key的节点”只需略微调整(划去return;单独判断头结点)
注意:这里头结点的判断放在了最后,因为这里是删除所有值为key的节点,由于head结点的特殊性(head结点的value=key),且head后对key值的删除处理具有同一性,所以这里就先一并处理head后结点,最后单独判断head结点。对于“删除第一次出现关键字为key的节点”,由于此时的场景是处理第一次出现的key值,所以就必须先处理head结点。
//删除所有值为key的节点
public void removeAllKey(int key) {
//为空情况
if (head == null) {
return;
}
//头结点后存在key值的情况
ListNode cur = head;
while (cur.next != null) {
if (cur.next.val == key) {
cur.next = cur.next.next;
} else {
cur = cur.next;
}
}
//头结点单独判断
if (head.val == key) {
head = head.next;
}
}
🍑10、得到单链表的长度
思路: 遍历链表,返回count计数值即可。
//得到单链表的长度
public int size() {
int count = 0;
ListNode cur = head;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
🍑11、清空链表
思路: 在Java中,当一个对象没有任何引用指向时,Java自带的垃圾回收机制会自动删除该对象。因此, 只要将链表的头节点赋值为空,链表的所有节点就会被视为不再被引用,可以通过垃圾回收机制来删除它们。
具体来说,当链表的头节点变成了null,链表的所有节点就不再有任何引用指向它们,这意味着这些节点成为Java内存中的"孤儿"节点,也就是不再被外部引用的节点。这时,Java垃圾回收机制会自动触发,将不再被引用的节点删除。
需要注意的是:如果链表中的节点存在其他引用指向它们,那么这些节点就不会被视为垃圾,也不会被自动删除。因此,在清空链表前需要确保没有其它引用指向链表中的任何一个节点,否则这些节点会一直被占用,浪费内存空间。
//清空链表
public void clear() {
head = null;
}
三、无头双向非循环链表
双向不带头非循环链表,与上述单向不带头非循环链表的主要差别体现在功能接口的实现上,特别是删除和插入操作时,不需要在保存前驱结点,可根据当前结点进行操作。
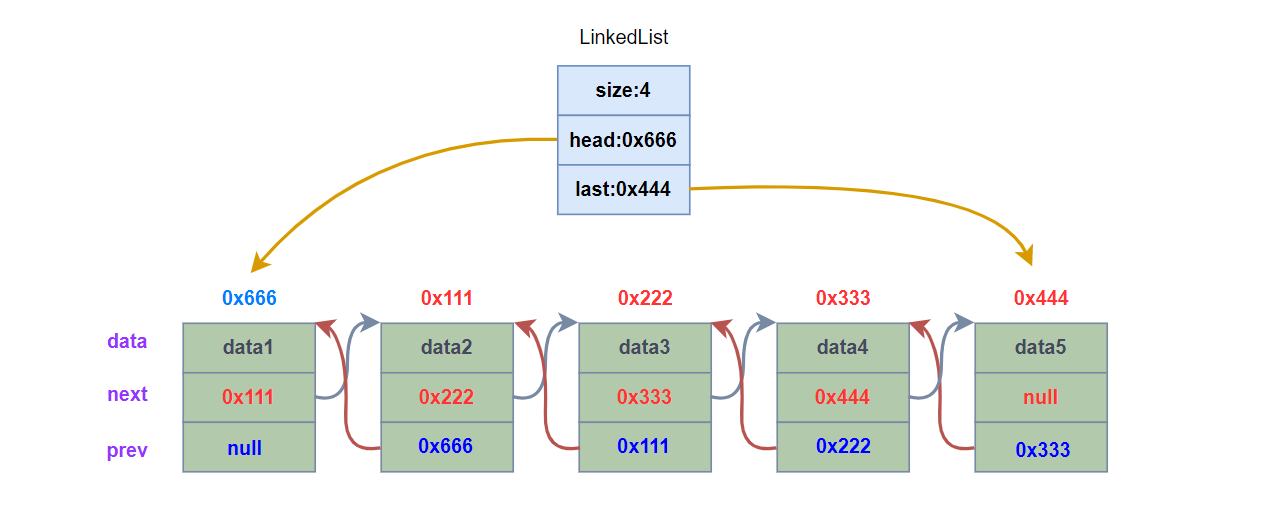
下面是无头双向非循环链表的代码实现,很多功能接口和上述单链表的实现多有雷同,并且下面代码中给出了详细的注释,大家可以参考理解:
// 2、无头双向链表实现
public class MyLinkedList {
static class Node {
// 数据
public int val;
// 前驱结点
public Node prev;
// 后继结点
public Node next;
// 结点构造
public Node(int val) {
this.val = val;
}
}
// 当前头结点
public Node head;
// 当前尾结点
public Node last;
//打印双向链表(同单向链表)
public void display() {
Node cur = head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
//头插法(思路同单向链表)
public void addFirst(int data) {
Node newnode = new Node(data);
if (head == null) {
head = newnode;
last = newnode;
} else {
newnode.next = head;
head.prev = newnode;
head = newnode;
}
}
//尾插法(思路同单向链表)
public void addLast(int data) {
Node newnode = new Node(data);
if (head == null) {
head = newnode;
last = newnode;
} else {
last.next = newnode;
newnode.prev = last;
last = newnode;
}
}
//得到双向链表的长度(同单链表)
public int size() {
int count = 0;
Node cur = head;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
//任意位置插入(注:第一个数据节点为0号下标)
public void addIndex(int index, int data) {
// 判断坐标合法性
if (index<0 || index>size()) {
throw new IndexOutOfException("坐标非法!");
}
// 构建新节点
Node newnode = new Node(data);
// 处理头插尾插特殊情况
if (index==0) {
addFirst(data);
return;
}
if (index==size()) {
addLast(data);
return;
}
// 处理在中间插入情况(这里体现了双向链表的优势)
// 将cur结点指向当前坐标
Node cur = head;
while (index!=0) {
cur = cur.next;
index--;
}
// 修改新节点的 next 域
newnode.next = cur;
// 修改 cur 结点的前驱结点的 next 域
cur.prev.next = newnode;
// 修改新节点的 prev 域
newnode.prev = cur.prev;
// 修改 cur 结点的 prev 域
cur.prev = newnode;
}
//查找是否包含关键字key是否在单链表当中(同单链表)
public boolean contains(int key) {
Node cur = head;
while (cur!=null) {
if (cur.val==key) {
return true;
}
cur = cur.next;
}
return false;
}
//删除第一次出现关键字为key的节点(体现双向链表优势)
public void remove(int key) {
Node cur = head;
while (cur!=null) {
if (cur.val==key) {
//如果只有一个结点(单链表不存在last所以不存在这一步)
if (head == last) {
head = null;
last = null;
return;
}
//如果cur是头结点
if (cur == head) {
head = head.next;
head.prev = null;
return;
}
//如果cur是尾结点
if (cur == last) {
last = last.prev;
last.next = null;
return;
}
// 如果cur是中间结点
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
return;
}
cur = cur.next;
}
}
//删除所有值为key的节点[对上面代码进行改进]
public void removeAllKey(int key) {
Node cur = head;
while (cur!=null) {
//满足条件开始删除
if (cur.val==key) {
if (head == last) {
// 如果只有1个结点
head = null;
last = null;
return;
} else if (cur == head) {
// 如果cur是头结点,并且节点数必定大于等于2
head = head.next;
if (head!=null) {
head.prev = null;
}
} else if (cur == last){
// 如果是尾巴结点
last = last.prev;
last.next = null;
} else {
// 如果是中间结点
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}
}
cur = cur.next;
}
}
//双向链表的清空操作
public void clear() {
Node cur = head;
while (cur!=null) {
Node curNext = cur.next;
cur.prev=null;
cur.next=null;
cur = curNext;
}
head=null;
last=null;
}
}
四、Java集合中的 LInkedList
java.util包下为我们提供了LinkedList集合类,它的底层就是一个无头双向非循环链表结构。并且这里的 LinkedList是以泛型方式实现的,使用时必须要先实例化,同时,它也实现了 List 接口,可以通过 List 接口接收LinkedList对象,并使用List方法操作LinkedList对象:
🍑1、LinkedList构造方法
| 方法 | 解释 |
|---|---|
| LinkedList() | 无参构造 |
| LinkedList(Collection<? extends E> c) | 使用其他集合容器中元素构造List |
🍑2、LinkedList常用方法
| 方法 | 描述 |
|---|---|
| boolean add(E e) | 在链表尾部插入元素 e。 |
| void add(int index, E element) | 将元素 element 插入到指定的 index 位置。 |
| void addFirst(E e) | 在该列表开头插入指定的元素。 |
| boolean addAll(Collection<? extends E> c) | 将集合 c 中的所有元素尾部插入链表。 |
| E remove(int index) | 删除指定 index 位置的元素,并返回被删除的元素。 |
| boolean remove(Object o) | 删除遇到的第一个等于 o 的元素,若删除成功则返回 true。 |
| E get(int index) | 获取指定 index 位置的元素。 |
| E set(int index, E element) | 将指定 index 位置的元素替换为新的元素 element,并返回原元素。 |
| void clear() | 清空链表中的所有元素。 |
| boolean contains(Object o) | 判断链表中是否包含元素 o,如果存在则返回 true。 |
| int indexOf(Object o) | 返回第一个出现的元素 o 的索引,如果不存在则返回 -1。 |
| int lastIndexOf(Object o) | 返回最后一个出现的元素 o 的索引,如果不存在则返回 -1。 |
| List subList(int fromIndex, int toIndex) | 截取链表部分元素,并返回一个新的 List 对象。 |
五、线性表总结:LinkedList和ArrayList区别
| 不同点 | ArrayList | LinkedList |
|---|---|---|
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持 O(1) | 不支持 O(N) |
| 头插或中间位置插入 | 需要搬移元素,效率低 O(N) | 只需修改引用的指向,时间复杂度为 O(1) |
| 空间 | 空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
说明: ArrayList支持随机访问,LinkedList不支持随机访问"的意思是指在数据结构中,ArrayList可以通过索引直接访问和获取元素,而LinkedList不能通过索引进行直接访问和获取。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











