







1. 计算图优化背景
深度学习在各种实际应用中取得了巨大成功,使许多应用发生了革命性的变化,包括视频分析、自然语言处理等。随着可用的数据增多,硬件的计算能力增强,为了在复杂问题中取得好的表现,目前DNN框架变得越来越复杂,神经网络层数越来越多,神经网络参数越来越大。ILSVRC2015分类挑战赢家ResNet网络层数涉及多达152层,大的BERT模型具有3.4亿个网络参数。
随着深度神经网络层数变得越来越多,模型变得越来越深,DNN的推理与训练时间显著提升。在DNN中每一回合的推理或训练中的每一次迭代通常可以表示为计算图(Computational graphs:a common way to represent programs in deep learning frameworks),通过计算图优化可以提高DNN训练和推理的速度。
2. 计算图优化方法
计算图优化方法有很多,有很多种图优化手段:
Operator Fusion
Constant Parameter Path Pre-Computation
Static Memory Reuse Analysis
Data Layout Transformation
Alter Op Layout
Simplify Inference
Computation Graph Substitution
目前主流的框架Tensorflow、Pytorch、TVM等都是同时采用多种计算图优化手段进行加速计算,Tensorflow提供了图优化器的API,用户可以直接调用;TVM采用Op Fusion(Operator fusion:combine multiple operators together into a single kernel without saving the intermediate results back into global memory)等方法来进行计算优化。
本文将主要介绍computation graph substitution优化方法。
3. Computation graph substitution
computation graph substitution:source graph and target graph have equivalent calculation results
计算图替代就是找到另外一个计算图在功能上等效替代当前的计算图,在替代的同时可以减小计算时间以及计算量。下面是一个简单的图替代例子:
在图1中,计算图包含两个卷积运算(一个具有256个大小内核(3×3),另一个具有256个大小内核(1×1)),然后是连接操作。一个可能的图形替代序列是先将v3卷积的内核大小扩大到(3×3),然后将v2和v3的两个卷积合并为一个。
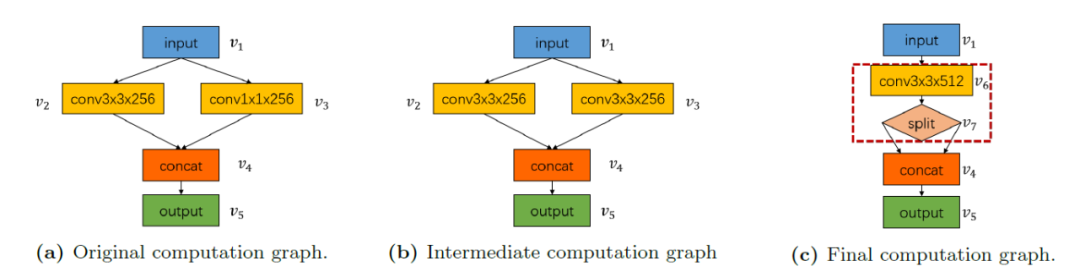
在NVIDIA Tesla P100 GPU输入一个张量为(1×256×14×14×14)的图像,由于放大卷积核,推理时间会增加0.04 ms,后续的卷积融合又会使推理时间减少0.07 ms,从而使图像的每个迭代的总运行时间降低0.03 ms。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2177
2177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











