







进程控制核心话题
- 进程创建
- 进程终止
- 进程等待
- 进程程序替换
下面就开始详细介绍
一.进程创建
1. fork函数初识
- fork函数初识
在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include <unistd.h>
pid_t fork(void);
返回值:子进程中返回0,父进程返回子进程pid,出错返回-1(失败的原因:内存不够;进程太多)
-
进程调用fork,当控制转移到内核中的fork代码后,内核做:
1.分配新的内存块和内核数据结构给子进程
2.将父进程部分数据结构内容拷贝至子进程
3.添加子进程到系统进程列表当中
4.fork返回,开始调度器调度 -
fork的运行规则【重点】:以父进程为模板,创建子进程
1.会把父进程的PCB(描述进程——task_struct)拷贝一份,稍加修改(如PID,PPID…),成为子进程的PCB
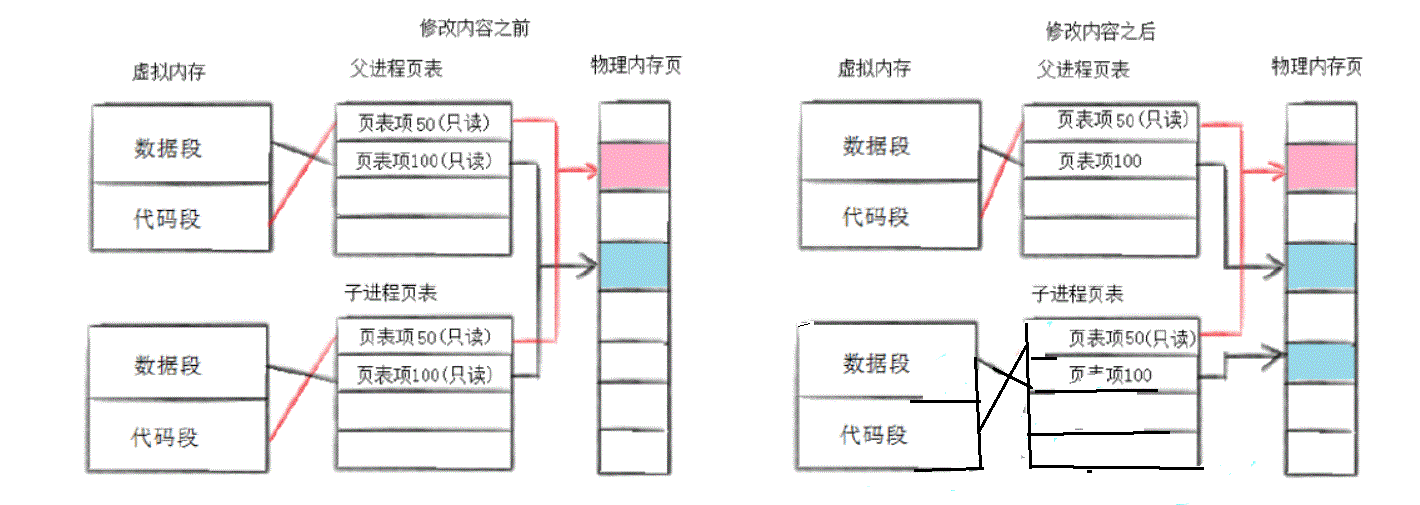
2.会把父进程的虚拟地址空间(代码,数据,堆,栈…)拷贝(写时拷贝)一份,作为子进程的地址空间
写时拷贝=》通常情况下,父子进程共用一份代码,各自有一份数据
【会把父进程的虚拟地址空间拷贝一份作为子进程的地址空间,但是此时的拷贝只是浅拷贝,为的就是节省时间提高效率,等到对子进程的虚拟地址空间中的内容要去修改的时候,此时就会触发写时拷贝。通常代码是在代码段,只会被读,所以一采用写时拷贝提高了效率,,但是代码段也不是百分之百不会被下修改。因为病毒软件就是修改代码段,此时也就会触发写时拷贝了。】
由于大部分的内存空间可能被拷贝,创建进程开销仍然比较高【和线程相比】
在有些场景下,线程的创建也会被认为开销比较高(和协程相比 )
3.fork()返回会在父子进程中分别返回
父子进程中返回子进程的pid,子进程返回0
在fork()后面继续往下执行
4.父子进程的执行顺序没有先后关系,全靠调度器来实现
看例题来理解fork的运行规则
1 #include<stdio.h>
2 #include<unistd.h>
3
4 int main()
5 {
6 int i = 0;
7 for(i=0;i<2;++i)
8 {
9 fork();
10 printf("=");
11 }
12 return 0;
13 }
执行结果:打印了八个=
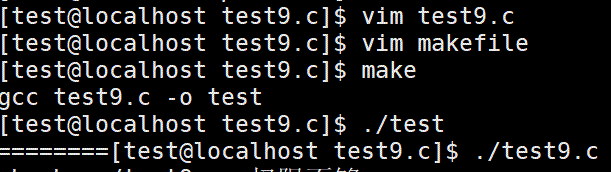
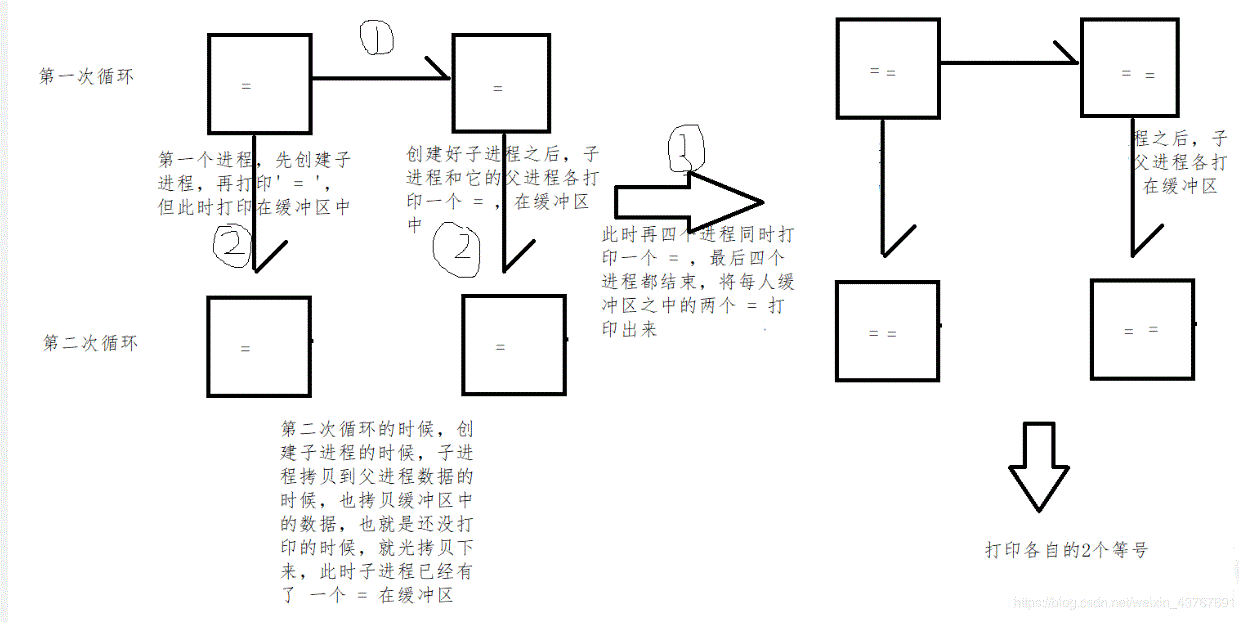
执行过程:
1 #include<stdio.h>
2 #include<unistd.h>
3
4 int main()
5 {
6 int i = 0;
7 for(i=0;i<2;++i)
8 {
9 fork();
10 printf("=");
11 fflush(stdout);
12 }
13 return 0;
14 }
执行结果:六个=
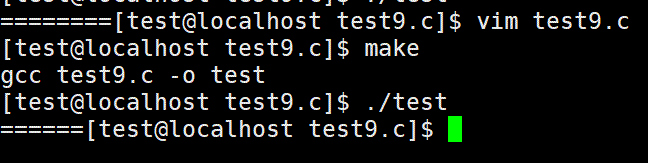
上面两段代码充分说明了fork()的继承关系,第一段代码会打印8个 ‘=’,第二段代码会打印6个‘=’原因就是是否刷新缓冲区问题。 而第二段代码,再刷新缓冲区之后, = 就不会被继承
缓冲区就是内存,进程在创建的时候会把父进程内存里的东西都“拷贝”一份给子进程
2.fork函数返回值
- 父进程返回子进程pid【反之不行,一个父亲可以有好几个儿子,但是一个儿子只能有一个父亲】
- 子进程中返回0
- 出错返回-1(失败的原因:内存不够;进程太多)
3.写时拷贝(懒加载的思想)
有些情况下如果数据不发生改变,也就没有必要进行拷贝,从而也就提高效率。具体见下图:
4.fork调用失败的原因
失败返回-1
- 系统中有太多的进程【进程太多】
- 实际用户的进程数超过了限制【内存不够】
fork是Linux上的系统调用,在其他的系统上也有类似的功能,例如windows上也可以用一个进程来创建一个进程,但是不叫fork,系统调用指的是和系统密切相关的,系统变了,就算是类似的功能,但是名字可能不一样,用法可能不一样,注意事项也就不一样。
创建图形化界面:
c#【只支持windows】
MFC(C++)【凉】
GTK©【凉】
wxWidget(C++)【凉】
Qt(发音同cute)[1991]
当前创建图形化界面采用的是混合式开发(html/css/js),换句话说桌面开发的技术栈和网页开发的技术栈已经完成了统一,都是同一套体系,桌面开发也可以并到前端开发这个领域。前端开发还是很厉害的,不管是桌面端还是手机端,很多APP,很多应用程序。底层都是借助html/css/js这样的技术来实现的。
二.进程终止
1.进程退出场景(方式)
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码没有执行完,异常终止
2.代码执行完的情况
-
main函数返回,返回值叫做进程的退出码,通过这个退出码表示运行结果是否正确
约定:
退出码为0,表示结果正确。
退出码非0,表示结果不正确。
$?这是bash中的一个特殊变量,这个变量表示上个命令对应的进程的退出码【$?是bash的功能】
用echo $?这个命令可以查看进程的退出码在Linux中输入echo $?按下回车就会打印出上一个进程的退出码, $?只是bash的特殊变量,也许你换一个shell结果就不一样了。0表示正确非0表示不正确。
标准库函数的意思是,只要他是一个标准的(C语言)的编译器,那么就可以使用这个库函数
- exit进程退出(库函数)
exit(退出码)和return相比,exit更方便一些,return的话,只有从main函数返回之后才退出进程。而exit只要你调用,这个函数,无论你是在main函数中还是在main函数调用的其他的函数之中,都会直接让进程退出,并且返回你所给的退出码。可以使用echo $?.
但是不推荐使用,因为代码量大的话拍错的话就不太好排查,可以用但是最好不要滥用
exit本质上也是调用了_exit,
exit多做了以下这些事情
1.exit关闭流并且刷新缓冲区【关闭流,这个流指的是文件流,文件不是直接写在磁盘上,而是先写在缓冲区里,也就是在关闭流的时候,缓冲区上的内容会刷新到文件或者显示器上】,_exit则不能【main函数退出也能刷新缓冲区,exit关闭流并且刷新缓冲区,_exit则不能刷新缓冲区】
2.exit还多调用了结束函数
- _exit进程退出(系统调用)
3.代码未执行完的情况:【异常终止】
- ctrl + c,信号终止
- 访问了非法内存(NULL),此时出现了段错误
【段错误就叫做访问内存出错,在Linux下就是进程异常退出,我们访问的一般就是虚拟内存地址,当我们在虚拟内存地址中,访问的内存在页表上无法对对应物理内存上的地址,那么就是访问非法内存。MMU这个硬件设备就是专门在虚拟内存和物理内存之间进行翻译和转换,所以就是MMU发现了你访问了非法内存,然后上报操作系统,操作系统将出错的进程强行干掉。或者也可以捕获异常再自己处理。】
三.进程等待
进程等待归根结底,是为了解决僵尸进程这样的问题,创建出子进程是为了让子进程干活,干完活,要把这样的结果返回给父进程,所以需要有子
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









