







代码混淆
为了在阻止逆向人员进行分析,在源代码和中间层代码层面产生了代码混淆的概念
源码级混淆:
逆向分析容易
- 标识符重命名:将代码中的各种元素,如变量、函数、类的名字改写成 无意义的名字
- 等价表达式
- **代码重排:**打乱原有代码格式,比如将多行代码挤到一行代码中
- **花指令:**通过构造字节码插入程序的适当位置,使得反汇编器出错,产生无法反编译或者反编译出错的情况。
- **自解密:**通过对程序部分进行加密,在即将运行时代码进行自解密,然后执行解密之后的代码。
机器码混淆:
逆向分析难
- **平坦控制流:**就是将程序原有的顺序、选择、循环结构统一重构为switch结构,使得程序的结构图从原有正常形态转变为扁平状
- 伪造控制流: 构造出根本不会去真正执行的控制流,从而在静态分析时,会对分析形成强烈的干扰,增加逆向人员的分析工作量
- 指令替换 将原有的一条或者几条能形成某种功能的指令,替换为大量的指令,从而增加逆向分析的代码量,
混淆器:
对JS进行混淆的工具有诸如YUI Compressor,Google Closure Compiler,UglifyJS,JScrambler等
在windows下进行代码混淆最出名的工具:
-
VMProtect,VMP能够实现代码虚拟化将部分或者全部代码使用VMP混淆,将该部分代码转换为自身才能解释执行的代码,按照VMP自身实现的虚拟机架构去解释执行(相当于将中文转换为了英文,你只有掌握了英文的词,语法和句,才能看懂英文写的文章。)
-
**OLLVM混淆器:**LLVM 命名最早源自于底层虚拟机
-
Obfuscator-LLVM是一个开源项目适用于LLVM所支持的所有语言
1 花指令混淆
2022CTF培训(四)花指令&字符串混淆入门_polarctfjunkcode-CSDN博客
花指令原理
花指令通常用来抵御静态分析,通过花指令混淆的程序,会扰乱汇编代码的可读性。在静态分析下,使反汇编器无法正常解析,反编译器无法正常反编译。
在反汇编的过程中,存在一个数据与代码的区分问题。
而不同字节码包含的字节数不同,有单字节指令,也有多字节指令。如果首字节是多字节指令,反汇编器在确定了第一个指令,也就是操作码以后,就会确定该指令是包含多少字节码的指令,然后将这些字节码转化为一条汇编指令。
举个例子,0xE8是x86中call指令的操作码,它后面通常要跟4个字节码,当反汇编器解析到0xE8这个字节码之后,会 将后4个字节码连同0xE8一起转化为一条call指令。
汇编码(Assembly Code)是用人类可读的汇编语言助记符书写的代码。
机器码(Machine Code)是用硬件可执行的二进制表示的代码。
十六进制码(Hexadecimal Code)是用人类可读的十六进制表示的代码。
两类反汇编算法
线性扫描算法:
从第一个字节开始,以线性模式扫描整个代码段,将一条指令的结束作为另一条指令的开始,逐条反汇编每条指令,直到完成整个代码段的分析。由于没有考虑代码中可能混有的数据,容易出错。(假设都是代码)
递归行进算法:
对代码可能的执行路径进行扫描,当解码出分支指令后,就把这个分支指令的地址记录下来,并反汇编各个分支中的指令。 这种算法可以避免将代码中的数据作为指令解析。
常见花指令混淆手段
Call,Jmp类指令形成的混淆
更改IDA识别的栈指针,破坏栈平衡
更改IDA识别的函数参数个数
1.1 Call,Jmp类
CALL
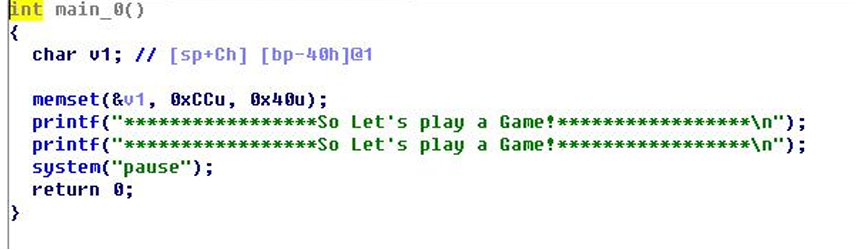
- Call指令混淆:CALL 0xE8 后面的四个字节是地址
- Jmp Short类型混淆: JMP 0xEB 后面的二个字节是偏移
- Jmp类型混淆 JMP 0xE9 后面的四个字节是偏移
混淆源代码:
#include<stdio.h>
#include<Windows.h>
int main(int argc,char*argv[]){
printf("*****************So Let's play a Game!*****************\n");
__asm
{
xor eax,eax
jz __label //jz跳转到下面的__label,导致__emit 0xE8无法执行,即混淆了
__emit 0xE8 //或.byte 0xE9;
}
__label:
printf("*****************So Let's play a Game!*****************\n");
system("pause");
return0;
}
__asm 关键字用于调用内联汇编程序,并且可在 C 或 C++ 语句合法时出现 __
emit 可以使数据以代码的形式写入到代码段,也就是 shellcode中。
用emit就是在当前位置直接插入数据(实际上是指令), 一般是用来直接插入汇编里面没有的特殊指令。
反汇编器的一种反汇编算法是线性扫描算法,当IDA解析到0xE8的时候,自动与其后4个字节码组成了一个call指 令,从而混淆了代码。
E8后面需要4个字节,由于程序解析多字节指令时,区分不了数据和代码产生的错误。
反汇编器不知道实际执行路径(即不知道 jz __label 实际跳转),它仍然会把 0xE8 后的 4 个字节解析为 CALL 的地址
反汇编器不会直接“识别”
__emit指令,因为__emit只是内嵌汇编的一种汇编器特性,能让我们手动插入任意字节。反汇编器只看到插入后的字节码。在这里,它仅仅看到0xE8,并将其解释为CALL的操作码。因此,反汇编器会误认为它是一个CALL指令,而不是数据。
Jmp Short类型混淆也是一样的道理
显示的字节码数量Number of Opcode bytes :从0改为8
反混淆:NOP(0x90)
OllyDbg则是使用的递归行进扫描算法:
使用递归行进扫描的OllyDbg,成功地把花指令识别了出来,因为递归行进扫描中对于任一条控制转移指令,其转移的目的地址都要能确定
要迷惑这类反汇编器,只需要让其转移的地址不确定即可,创建一个指向无效数据地址的汇编语句
#include<stdio.h>
#include<Windows.h>
int main(int argc,char*argv[]){
printf("*****************So Let's play a Game!*****************\n");
__asm
{
xor eax,eax
jz __label //jz直接跳转到__label,不会执行下一个jnz指令
jnz __label2 //动态实际不会执行此语句,只是在给静态分析增加迷惑性
__label2:
__emit 0xE8
}
__label:
printf("*****************So Let's play a Game!*****************\n");
system("pause");
return0;
}
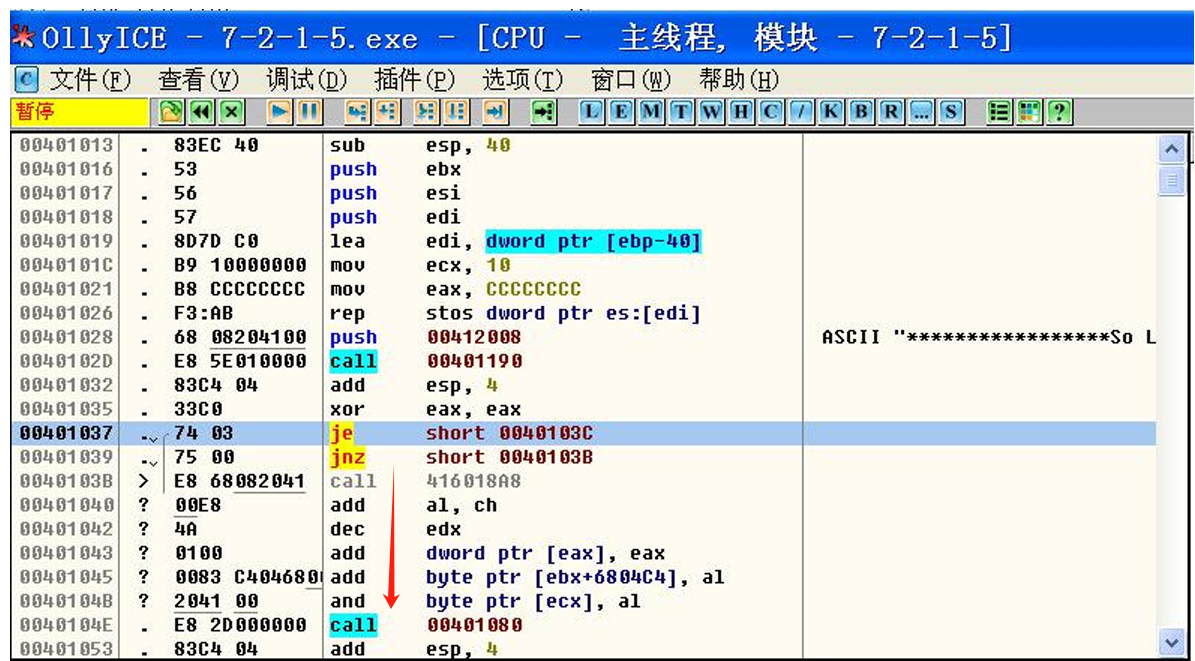
jz和jnz看似跳转到不同的位置,但由于地址极其接近,它们最终还是会在某个位置(如0x40103B或0x40103C)汇聚到相同的代码指令序列。这会让反汇编器产生误解,以为代码的执行路径存在多种可能性,并且其中一些路径会包含伪造的指令或无效数据。
1.2 破坏栈平衡
#include<stdio.h>
#include<Windows.h>
int main(int argc,char*argv[]){
printf("*****************So Let's play a Game!*****************\n");
__asm
{
xor eax,eax
jz __label
add esp,0x48
}
__label:
printf("*****************So Let's play a Game!*****************\n");
system("pause");
return0;
}
Option>general>选中stack pointer,可以查看栈帧的偏移地址
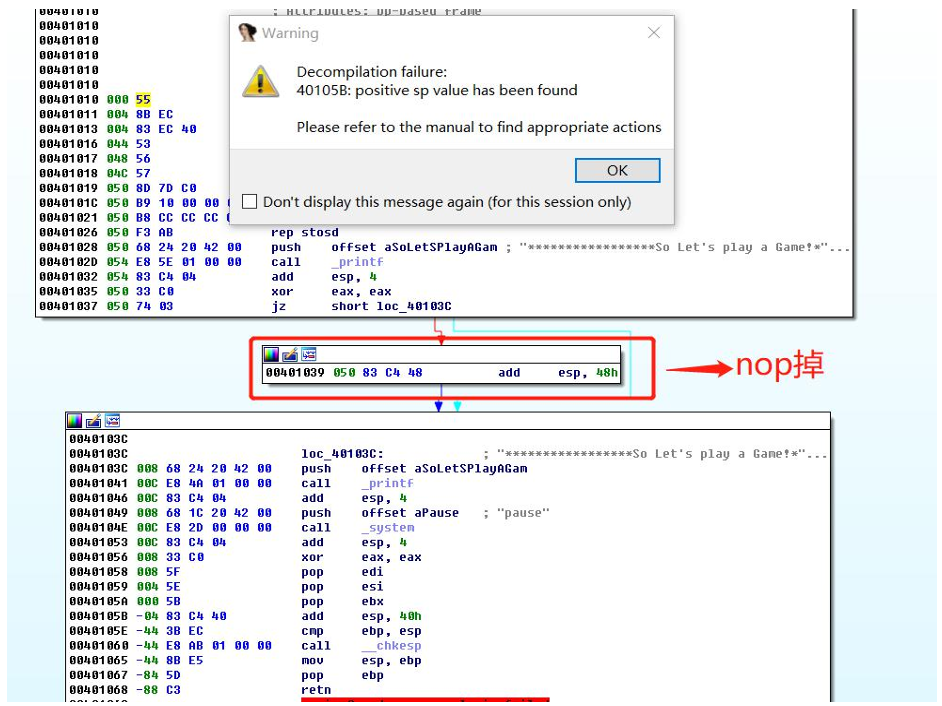
可以看到retn这条汇编指令的最左边显示的绿色值为-88h,正常情况下子函数返回时,堆栈弹出所有参数后,堆栈平衡,偏移为00h
当nop掉导致这一切的add esp,0x48以后,栈指针即可恢复正常,当nop掉导致这一切的add esp,0x48以后,栈指针即可恢复正常
1.3 更改函数参数个数
#include<stdio.h>
#include<Windows.h>
int main(int argc,char*argv[]){
printf("*****************So Let's play a Game!*****************\n");
__asm
{
xor eax,eax
jz __label
ret 248
}
__label:
printf("*****************So Let's play a Game!*****************\n");
system("pause");
return0;
}

当程序正常反编译以后,程序的参数变成了62个, 这是因为ret 248指令,其中248 = 4 * 62
stdcall函数调用约定,子函数压栈多少个参数(字节),ret返回参数时,就返回多个参数对应的字节。 在stdcall调用约定当中,这个平衡栈帧操作由被调用的子函数负责,因此,使得IDA才在反编译时,出现返回62个参数。
将ret 248 NOP掉即可
stdcall调用约定概述:在stdcall调用约定下,由被调用的函数负责清理栈。
- 当
ret X被执行时,它会清理掉X字节的栈空间,这通常意味着函数调用时传递的参数数量。.
ret 248的作用:ret 248指令会弹出 248 字节的栈空间(在返回之前从栈中移除248` 字节)。
2 SMC代码自修改
self-Modifying Code
在真正执行某一段代码时,程序会对自身的该段代码进行自修改,只有在修改后的代码才是可汇编, 可执行的
在程序未对该段代码进行修改之前,在静态分析状态下,均是不可读的字节码,IDA之类的反汇编器无法识别程序的正常逻辑。
SMC是一种局部代码加密技术,它可以将一个可执行文件的指定区段进行加密,使得黑客无法直接分析区段内的代码,从而增加恶意代码分析难度和降低恶意攻击成功的可能性。
SMC的基本原理是在编译可执行文件时,将需要加密的代码区段(例如函数、代码块等)单独编译成一个section(段),并将其标记为可读、可写、不可执行(readable, writable, non-executable),然后通过某种方式在程序运行时将这个section解密为可执行代码,并将其标记为可读、可执行、不可写(readable, executable, non-writable)。这样,攻击者就无法在内存中找到加密的代码,从而无法直接执行或修改加密的代码。
这类算法往往在函数我们反编译前,会执行一段代码,对原有代码进行加密,我们需要先对其进行解密,如果是IDA的话,解密后U(取消定义),C重新生成就可以得到正确的函数。
3 OLLVM混淆
这类进行反混淆一般需要使用工具,遇到上网查就行
LLVM是一个开源的编译器架构,利用虚拟技术对源代码提供现代化的、与目标无关的、针对多种CPU的,代码优化和代码生成功能。
LLVM采用经典的编译器三段式设计:
-
前端:前端解析源代码,由语法分析器和语义分析协同工作,检查语法错误,并构建语言的抽象语法树AST来表示输入代码,然后将分析好的代码转化为LLVM的中间表示IR;
通常但不总是先构建AST,然后将AST转换为LLVM IR–优化器
-
优化器通过一系列的Pass对中间代码IR进行优化,改善代码的运行时间使代码更高效;
-
后端 后端负责将优化器优化后的中间代码IR转换为目标机器的代码
LLVM IR是LLVM的中间表示,用来在编译器中表示代码的形式,优化器通过一系列的Pass对IR进行优化操作,直至生成后端可用的IR。
OLLVM工作在LLVM IR中间表示层,通过编写Pass来混淆IR,后端依照IR转换的目标机器的代码也就达到了混淆的目的。
因为OLLVM是基于LLVM设计的,因此它支持LLVM支持的所有编程语言(C,C ++,Objective-C,Ada和 Fortran)以及目标平台(x86,x86-64,PowerPC, PowerPC-64 ,ARM,Thumb,SPARC,Alpha, CellSPU,MIPS,MSP430,SystemZ和XCore)。
-
指令替换:参数为-sub
通过功能上等价的但更复杂的指令序列,替换标准二元运算符 (如加法、减法或布尔运算符),当有多个可用的等效指令序列时,随机选择一个
-
虚假控制流程:参数为- bcf
通过在当前基本块之前添加基本块来修改程序的控制流图,原始的基本块也会被克隆,并插入随机的垃圾指令。
-
控制流平展:参数为- fla
使用该模式后,程序的控制流图被完全压扁。
三个参数可以单独使用,也可以一起配合使用
#include<stdio.h>
#include<stdio.h>
int main(){
int a =200;
int b =100;
int c =0;
int d =0;
int e =0;
int i =10;
while(i >0){
if(a > b){
c = a + b;
d = a & b;
e = a ^ b;
}else{
c = a - b;
d = a | b;
}
i = i -1;
a = a -20;
b = b -5;
}
printf("c = %d\nd = %d\ne = %d\n",c,d,e);
return0;
}
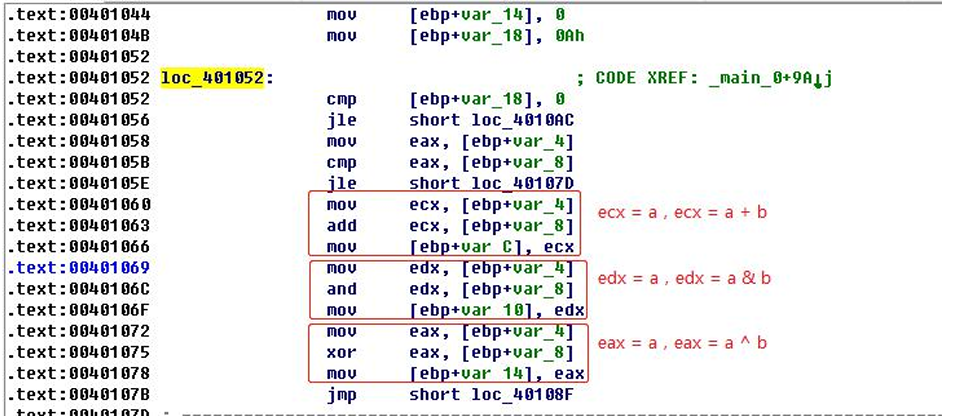
指令替换
例如: a=b+c
a =(b -(-c))
a =-(-b +(-c))
r = rand(); a = b + r; a = a + c; a = a - r
r = rand(); a = b - r; a = a + c; a = a + r
目前,OLLVM支持只有整数参与的加法、减法、 与、或、异或运算
#将test.c 置于 your_ollvm_path/build/test文件夹下
cd your_ollvm_path/build/bin./clang -m32 ../test/test.c -o ../test/test_sub -mllvm -sub
虚假控制流程
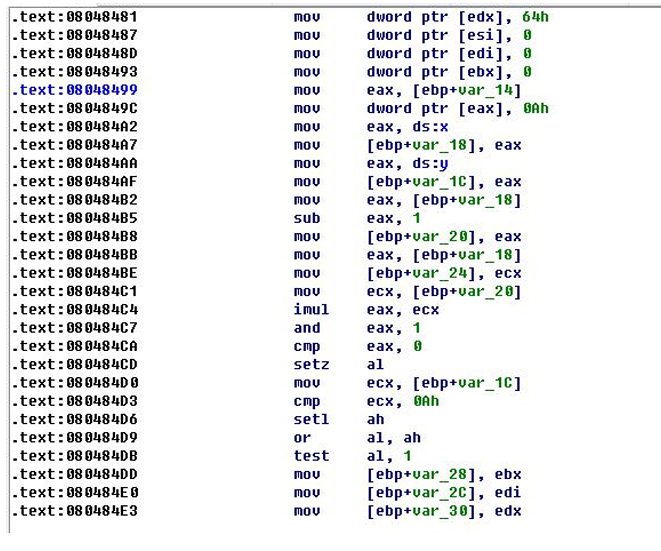
平坦控制流:
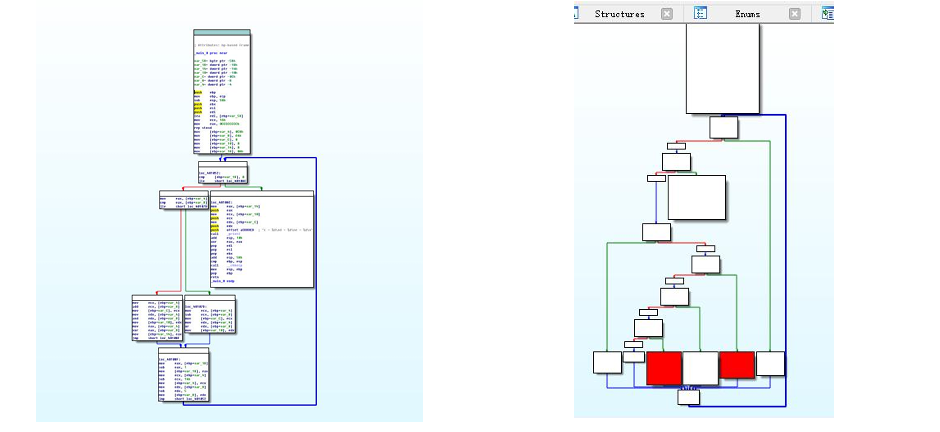
使用快捷键F5反编译后可以看到原来的if-else逻辑变成了switch循环
4 先进混淆技术
基于MBA变换的数据隐藏与代码混淆技术
在有限域GF§中,MBA变换可以将算数运算表达式(包括加、减、乘等运算)转换为等价的逻辑运 算表达式(包括与、或、非、异或等运算),且有完善的理论支撑

















 1655
1655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









