







0.上篇:滑动窗口


0.1分析
这道题要求的是一个区间 是区间就有【第一个元素】 即起始位置
0.2 暴力求解【超时】
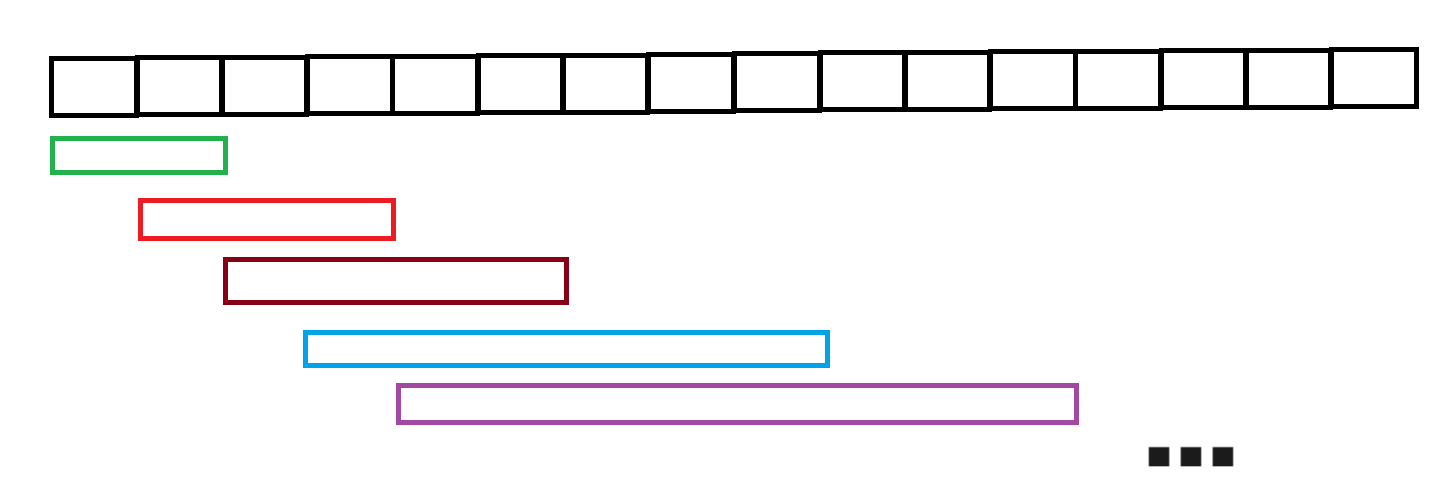
这道题是要找一个子区间,使得这个区间的所有数 >= target;
把数组中的每⼀个元素作为一个区间的起始位置,每次往这个区间里加一个数,直到这个区间的数和>=target;将所有元素作为起始位置所得的结果中,找到「最⼩值」即为最短子区间。
class Solution
{
public:
int minSubArrayLen(int target, vector<int> &nums)
{
// 记录结果
int ret = INT_MAX;
int n = nums.size();
for (int start = 0; start < n; start++)
{
int sum = 0;
for (int end = start; end < n; end++)
{
sum += nums[end];
if (sum >= target)
{
ret = min(ret, end - start + 1);
break;
}
}
}
return ret == INT_MAX ? 0 : ret;
}
};
0.3 滑动窗口
铺垫
滑动窗口的思想实际上是基于【暴力求解】的优化。一般人/普通人在解这类题时,一般直接想到的解决方案就是【暴力求解】,但是我们都知道,【暴力求解】通常不是一个问题的最优方案。基于【暴力求解】,佬们就总结出来在【暴力求解】基础之上的优化,这个优化对于有“算法”思想的人来说不难想到/理解,关键在于有没有用心思考更优解。
讲解
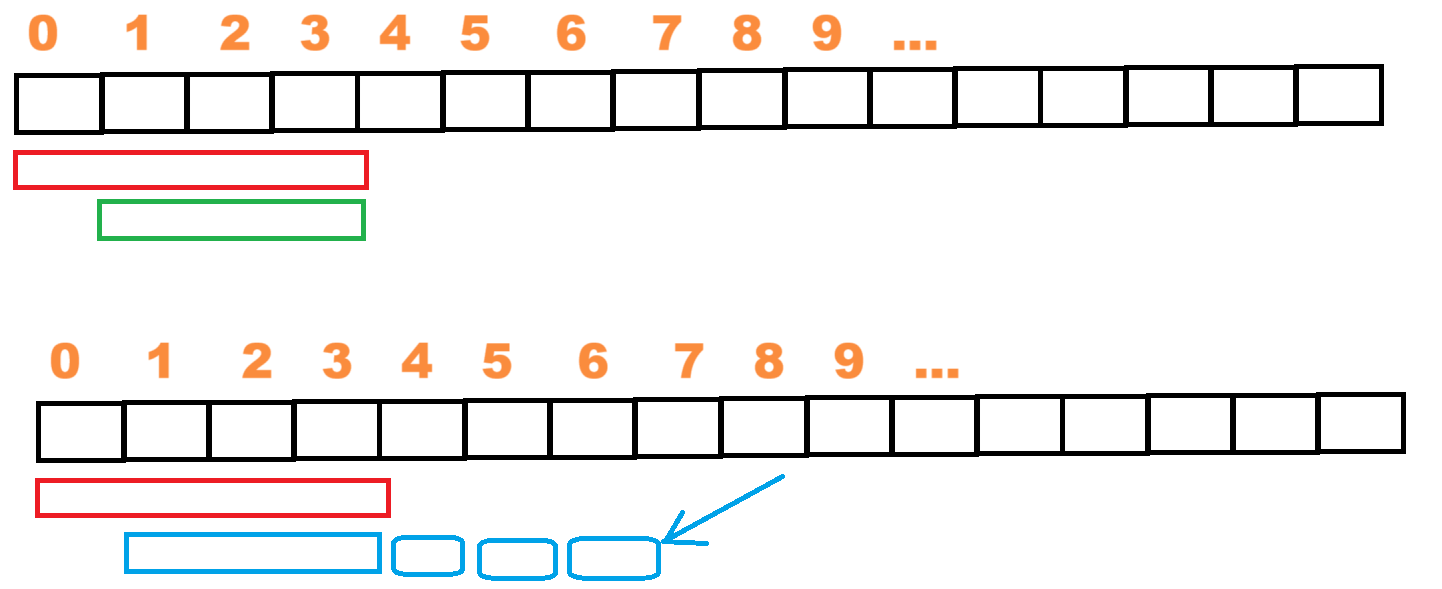
【暴力求解】中提到,遍历数组,把每一个元素作为【结果区间】的首元素,依次顺序添加直到满足条件,记录将该元素作为【结果区间】首元素下【结果区间】的长度,遍历结束后,在取这些值的最小值即为结果。
现在我们细思【暴力求解】的过程,当把arr[0]作为【结果区间】的首元素时,我们计算求和了一部分值,当下一轮把arr[1]作为【结果区间】的首元素时,我们又重新计算了在第一轮中计算过的值,这就是【暴力求解】效率低下的原因。
学过数据结构我们知道,提升一个算法的时间复杂度,我们可以通过减少语句的执行/循环的次数/递归的次数等。在这道题中,有没有一种方法,使得我们能够减少计算的次数?
解答

第一个区间计算完之后,计算第二个区间时,实际上就是把【该区间首元素的前一个元素】即(遍历的上一个元素)移除,对于移除后的新区间
- 仍有可能满足条件【左端元素可能很小,划出去之后依旧满⾜条件】
- 不满足,即变小了。我们不再从arr[1]开始继续往后添加元素,而是把第一个区间去除arr[0]的剩余元素直接拿过来用,在这个【旧区间】的基础上再添加。
如此大大的减少了计算的次数。
代码
class Solution
{
public:
int minSubArrayLen(int target, vector<int> &nums)
{
int n = nums.size(), sum = 0, len = INT_MAX;
for (int left = 0, right = 0; right < n; right++)
{
sum += nums[right];
while (sum >= target)
{
len = min(len, right - left + 1);
sum -= nums[left++];
}
}
return len == INT_MAX ? 0 : len;
}
};


1.暴力+哈希
枚举「从每⼀个位置」开始往后,⽆重复字符的⼦串可以到达什么位置。找出其中⻓度最⼤的即可。
在往后寻找⽆重复⼦串能到达的位置时,可以利⽤「哈希表」统计出字符出现的频次,来判断什么时候⼦串出现了重复元素。
class Solution
{
public:
int lengthOfLongestSubstring(string s)
{
int ret = 0;
int n = s.length();
for (int i = 0; i < n; i++)
{
int hash[128] = {0};
for (int j = i; j < n; j++)
{
hash[s[j]]++;
if (hash[s[j]] > 1)
break;
ret = max(ret, j - i + 1);
}
}
return ret;
}
};
2.滑动窗口
left:固定目前在访问的子串的起始位置
right:加入到滑动区间的元素下标。
将每一个元素x作为起始位置,right不断向字串添加元素,如果不重复则记录长度,如果重复了,left++表示当前的x作为起始位置的【无重复字符的最长子串】已找到,继续遍历,把下一个字符作为起始位置。【用while不用if】这里的while代码有两个作用:1. 原先的left推测出窗口,它对应的字符个数应当–;2. 原来子串中出现了重复字符,不知道与right重复的字符在哪里,例如:abcdd,a做起始位置的【长度】为4,a出窗口,b作为起始位置,仍有重复字符,b直接出窗口==》b在a后面,b到right的长度肯定小于a到right,顾只要没有去除重复字符,就一直往后移动就行了,不用更新b做起始位置的长度。
class Solution
{
public:
int lengthOfLongestSubstring(string s)
{
int hash[128] = {0};
int n = s.size();
int ret = 0;
for (int left = 0, right = 0; right < n; right++)
{
hash[s[right]]++;
while (hash[s[right]] > 1)
hash[s[left++]]--;
ret = max(ret, right - left + 1);
}
return ret;
}
};

















 196
196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











