






去重策略
1)
使用scrapy自带的set集合去重,当程序结束的时候会被清空,缺点:再次运行会导致数据重复。
2)
使用mysql做去重,对url地址进行md5,base64加密,加密之后会得到一串字符,判断字符串
是否在mysql表中,如果在表示已经爬取过了,如果不在,表示没有爬取,执行请求,将加密后的url
地址存入表中。缺点: 但是这个方法对mysql压力过大,导致崩溃,不推荐
3)
使用scrapy_redis的去重策略,会将已经爬取的url地址经过编码后存入redis,并且会做数据持久化,当爬虫再次启动时,会重新加载本地的数据,对爬虫的url做去重。缺点:如果数据量较大的时候,会占用较多的内存空间4)
使用布隆去重,采用多重哈希,将url地址映射到位阵列中的某个点上,空间和时间利用率更高(推荐)
布隆去重的优点和缺点
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash 函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势
缺点
但是布隆过滤器的缺点和优点一样明显。误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
课件3.26
打开项目,把scrapy_redis从环境文件中拷贝一份粘贴到scrapy项目中,这样做的目的是为这个项目单独配置去重方案
而环境中的scrapy_redis却不会变,其他项目不用使用布隆去重方案。
下载 布隆过滤器py文件,将其拷贝至scrapy_redis包中。(这个py文件有很多大牛都有写,课件也有和这个稍有不同原理相同)

修改scrapy_reids中的dupefilter文件,修改其去重策略。
from .BloomfilterOnRedis import BloomFilter

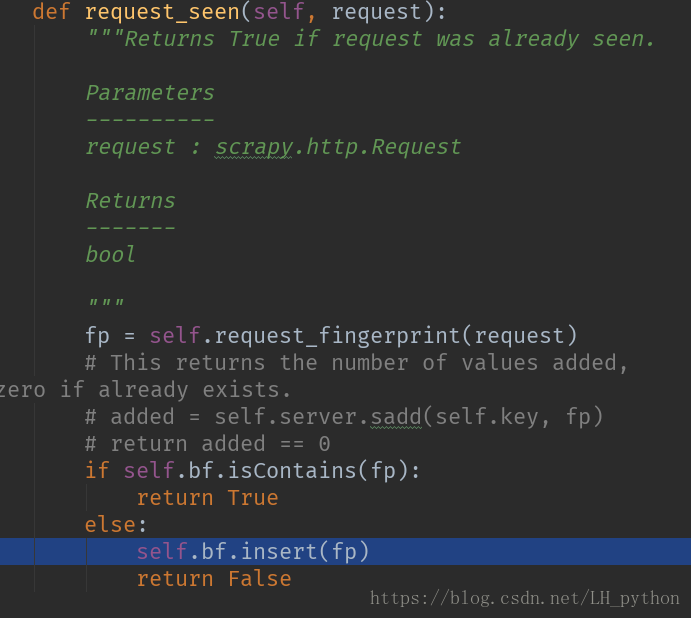
修改其 request_seen函数
if self.bf.isContains(fp):
return True
else:
self.bf.insert(fp)
return False
按照分布式爬虫部署步骤,继续进行即可使用布隆去重策略















 3377
3377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









