







如果数据序列是无序的,我们采用的是线性搜索,时间复杂度是O(n)

二分搜索算法(折半查找)
是基于有序序列的搜索

我们定义2个下标,first和last
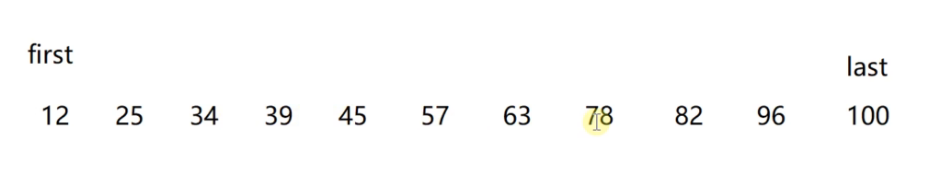
first初始值是0,last初始值是10
每次进行搜索,采用的策略是:
首先,计算出1个中间值:
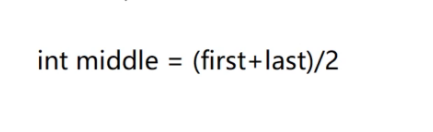
(0+10)/2=5
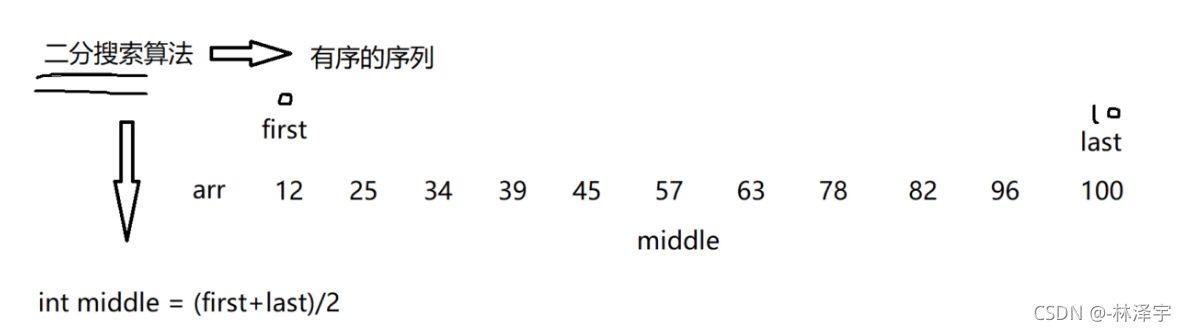
然后把中间的值57和我们要搜索的元素val值比较

如果我们要搜索的元素的值是57,等于这个中间值,那么就找到了。
如果我们要搜索的元素的值大于这个中间值57
因为是数据有序的序列,所以我们要搜索的元素值大于这个中间值57的话,我们要搜索的元素肯定在57的右边。就不用在57的左边序列中去找。

如果我们要搜索的元素的值小于这个中间值57
因为是数据有序的序列,所以我们要搜索的元素值小于这个中间值57的话,我们要搜索的元素肯定在57的左边。就不用在57的右边序列中去找。
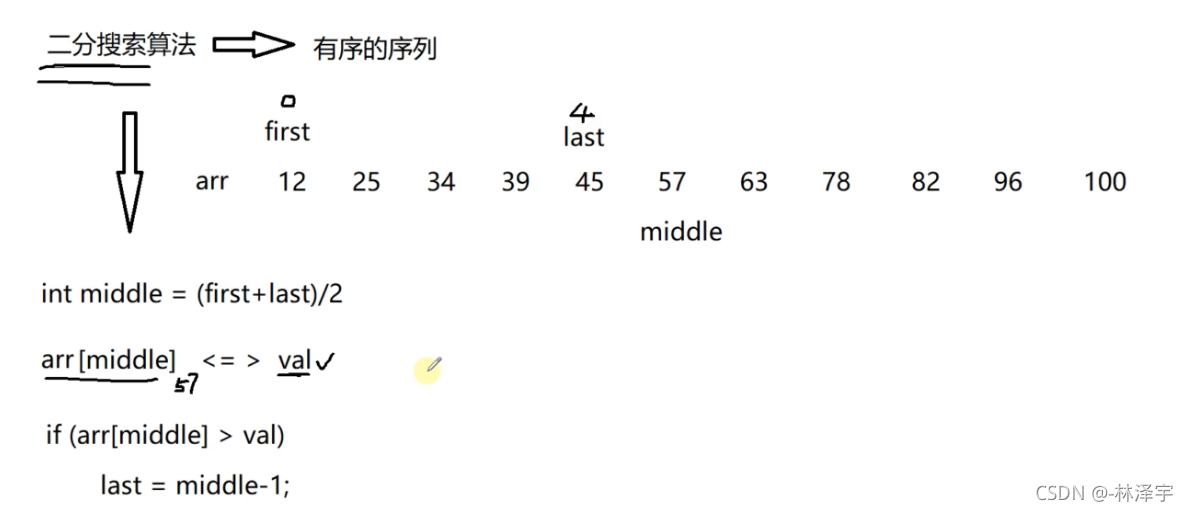
然后又来计算新的middle值
(0+4)/2=2

然后拿要搜索的元素的val值和这个中间值34对比
如果这个val值大于这个中间值34

然后计算新的middle值(3+4)/2=3

然后val值和这个中间值39比较,
如果这个val值小于这个中间值39,如果执行last=middle-1的话

这样是错误的,因为first是起始下标,last是末尾下标。说明这次找的是34-39之间的数字,所以在序列中不存在,找不到!
如果这个val值大于这个中间值39
first=middle+1
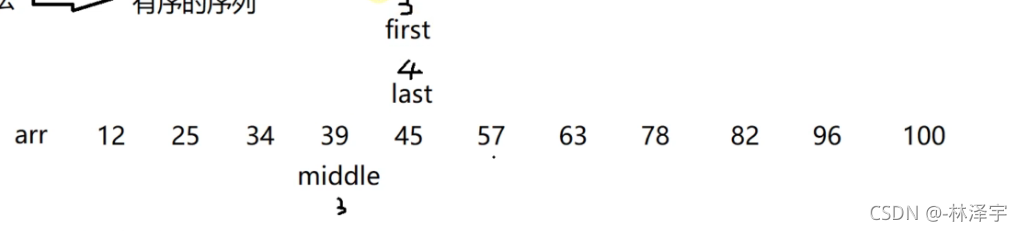
现在first和last相等了,如果找的是45,就找到了,如果比45小,或者比45大,就是表示在序列中找不到了,继续调整下标了,就是非法了,使first和last位置顺序乱套了,退出while循环,return -1了。
所以,我们规定:

二分搜索算法非递归实现
//二分搜索非递归实现
int BinarySearch(int arr[], int size, int val)
{
int first = 0;
int last = size - 1;
while (first <= last)
{
int mid = (first + last) / 2;
if (arr[mid] == val)
{
return mid;//找到了,返回下标
}
else if (arr[mid] > val)//要找的元素的值比中间值小
{
last = mid - 1;//到中间值的左边序列搜索
}
else//要找的元素的值比中间值大
{
first = mid + 1;//到中间值的右边序列搜索
}
}
return -1;//找不到,返回-1
}
二分搜索算法的时间复杂度
为什么在有序的序列里,我们要使用二分搜索,而不使用线性搜索?
线性搜索的时间复杂度是O(n)
二分搜索的时间复杂度是O(logn)
对数时间比线性时间好的多
为什么二分搜索的时间是对数时间呢?
它是怎么搜索的?
因为刚开始first是0,last是10,(0+10)/2=5,所以它先搜的是57,它拿57作为入口,如果搜索的元素的值==57,就搜到了,就走人了
如果搜索的元素值小于57,就(0+4)/2=2,就和2号位置的34比较
如果搜索的元素的值小于34,就(0+1)/2=1,和1号位置的25比较
如果搜索的元素的值小于25,first和last都跑到0号位置了,就和0号位置的12比较,如果相等就找到了,如果不相等就是找不到。
如果搜索的元素的值大于34,first=3,(3+4)/2=3,和39比较,
如果比39小,就没了,first就跑到last的后面了,
如果比39大,first和last跑到45元素了,和45比较。

如果搜索的元素值大于57,first跑到6号位置,(6+10)/2=8,比较元素82,
如果搜索的元素比82小,last跑到7号位置,(6+7)/2=6,和63比较
如果比63小,就没有了,first跑到last的后面了,结束了。
如果比63大,first和last跑到7号位置,和78比较
如果比82大,first跑到9号位置,(9+10)/2=9,可以和96比较
比96小就没了,比96大,还可以和100比较
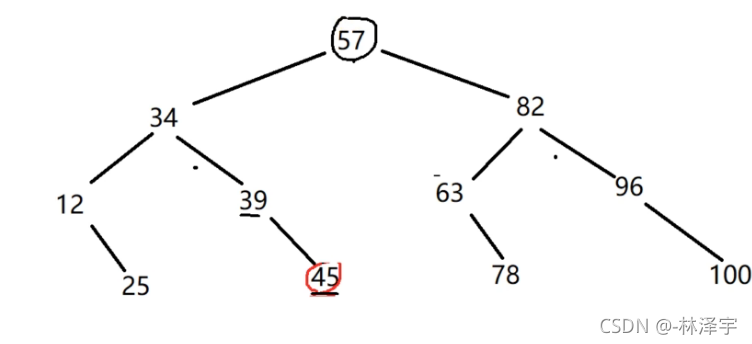
二分搜索相当于就是从这棵二叉树的根节点开始时,沿着某一个路径进行搜索的过程,最多搜到叶子节点上。
这是一棵BST树,二叉搜索树
左孩子的值小于父节点的值,父节点的值小于右孩子的值。
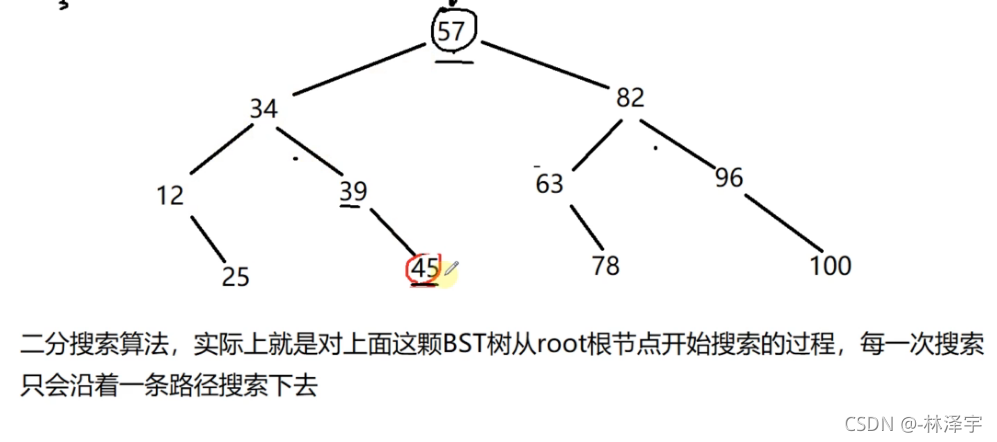
二分搜索在每一层只会搜索1个节点
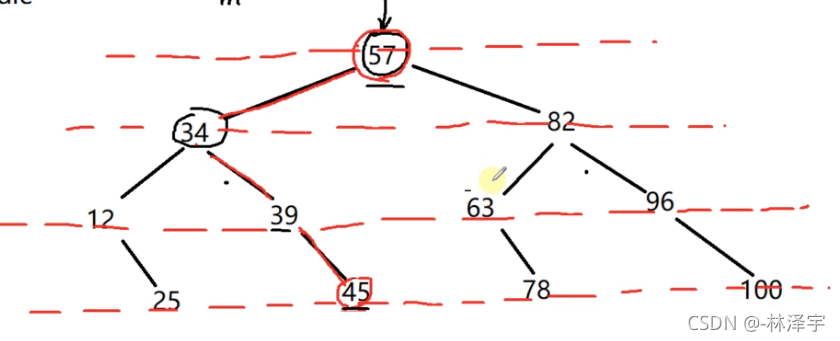
所以,
二叉树的层数和对应的节点数的关系:
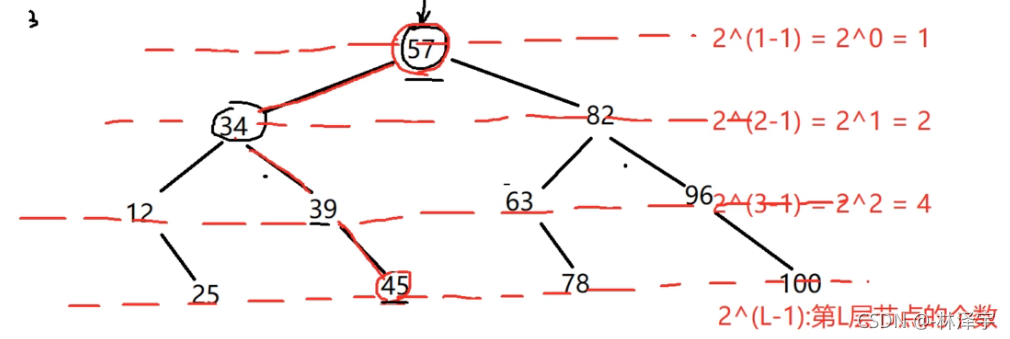
n就是节点总个数
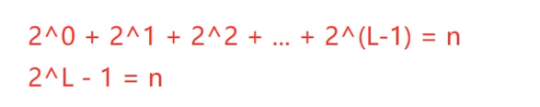
我们可以把1省略掉,因为这个1相当于根节点,根节点肯定是最先走的节点,我们就省略掉。
树的层数:L


二分搜索的高效率应用场景
如果我们有100w个数据,是有序的,最多搜log以2为底的100w


最多搜索20次就可以了!
在有序的1000w个数据中搜索,最多搜索24次就可以了!

递归复习图解
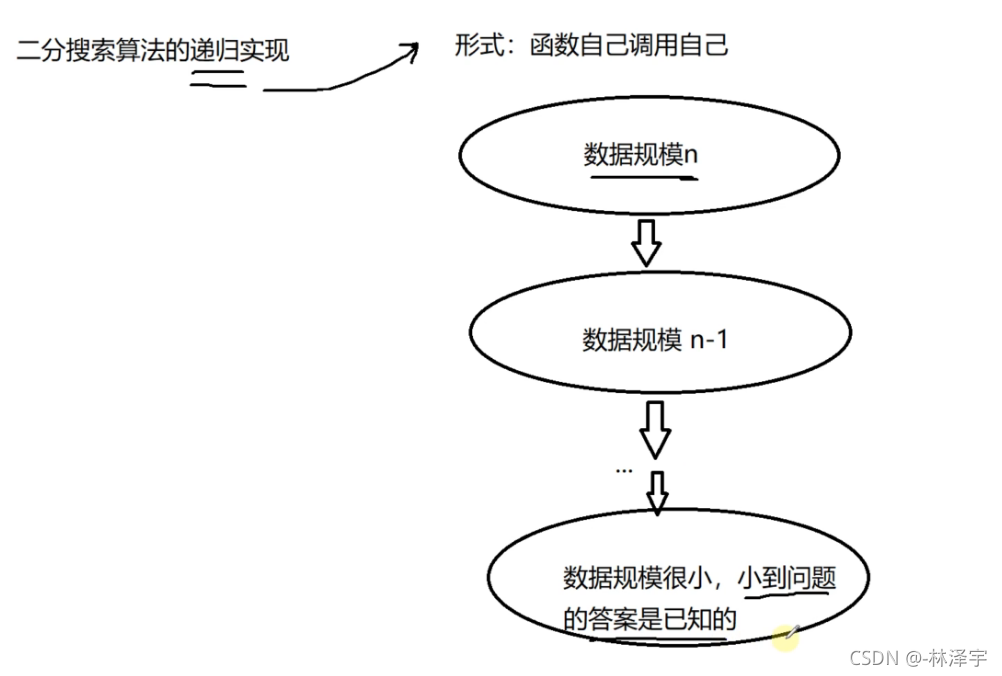
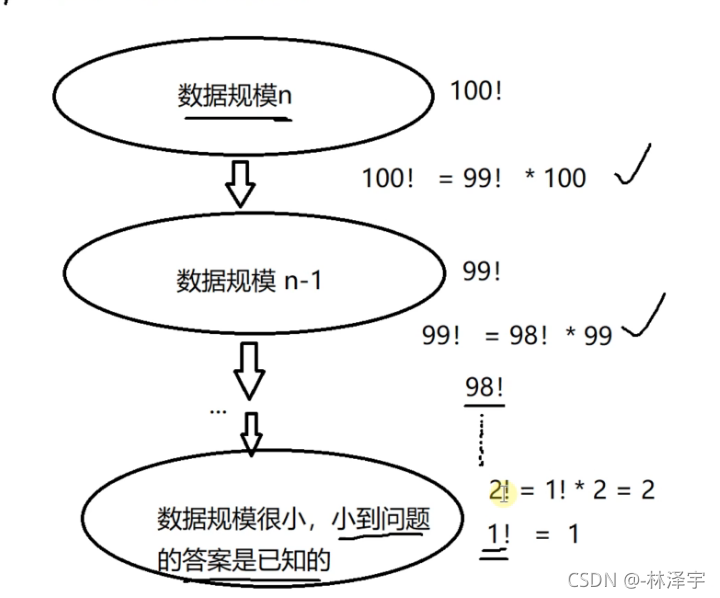
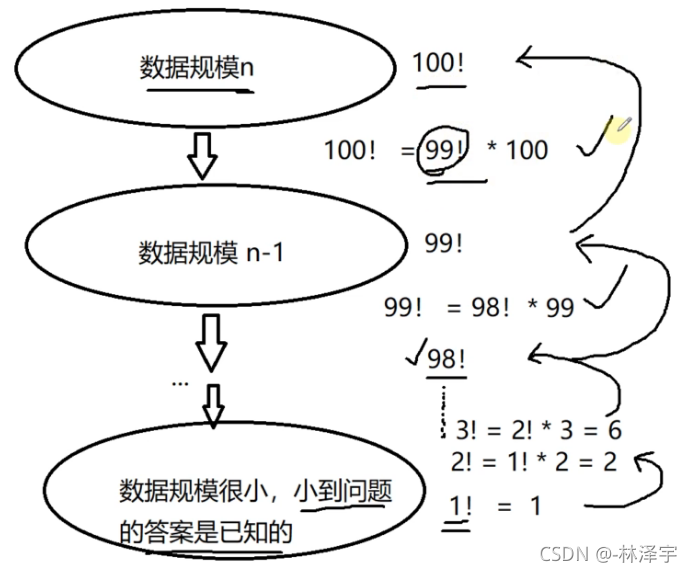
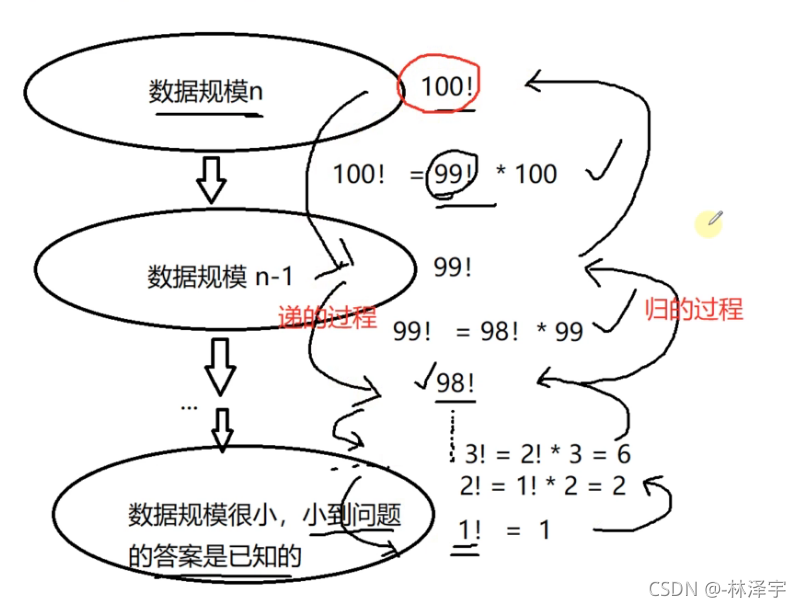
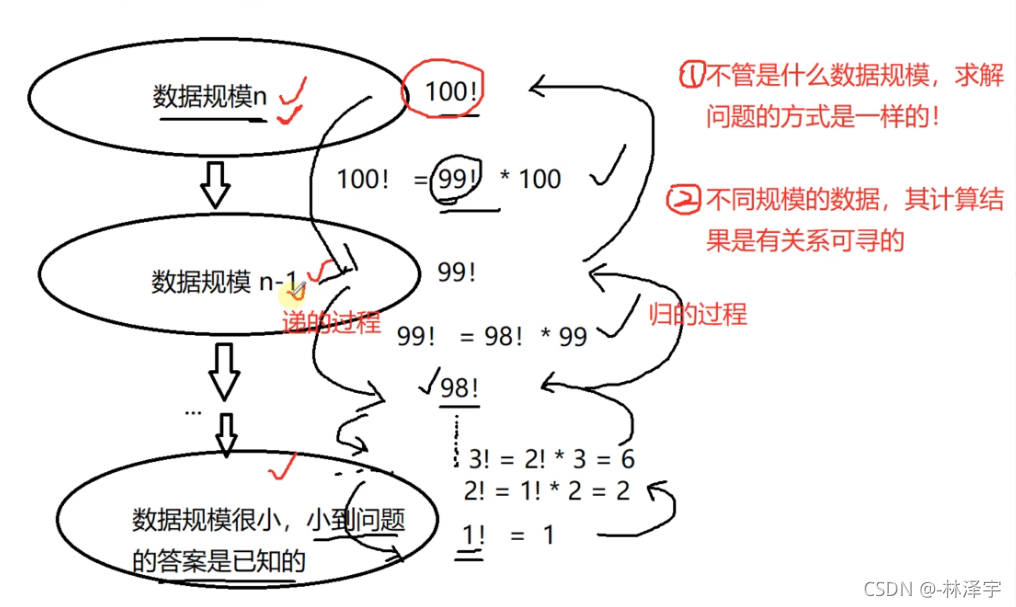
递的过程是在不断缩小问题的规模,缩小问题规模的过程中,不同数据规模之间,它们求解的结果是有关系的,
递不是无穷无尽的递,递一次就要开辟一次空间,栈的空间是比较小的,所以对于大数据处理,最好使用非递归方法处理 ,递的过程,一定会有递的规模,数据规模小到问题的结果是已知的
递到最后最小问题规模的结果是已知的,然后把每一层的结果一直向上归回去,最后n问题规模的解就解出来了

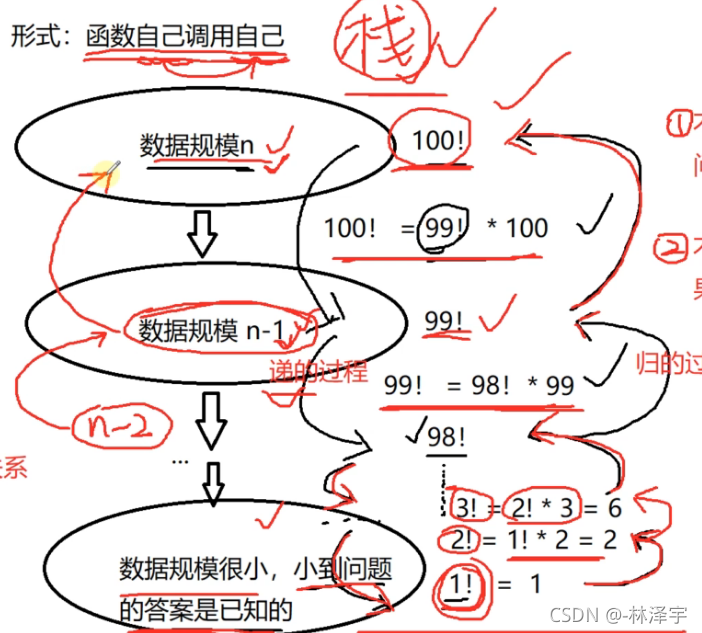

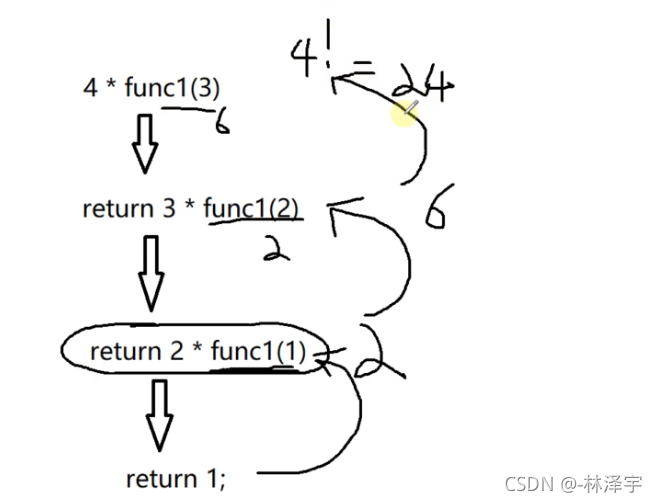
求n的阶乘:

二分搜索算法的递归实现


第一步:

第二步:

第三步:
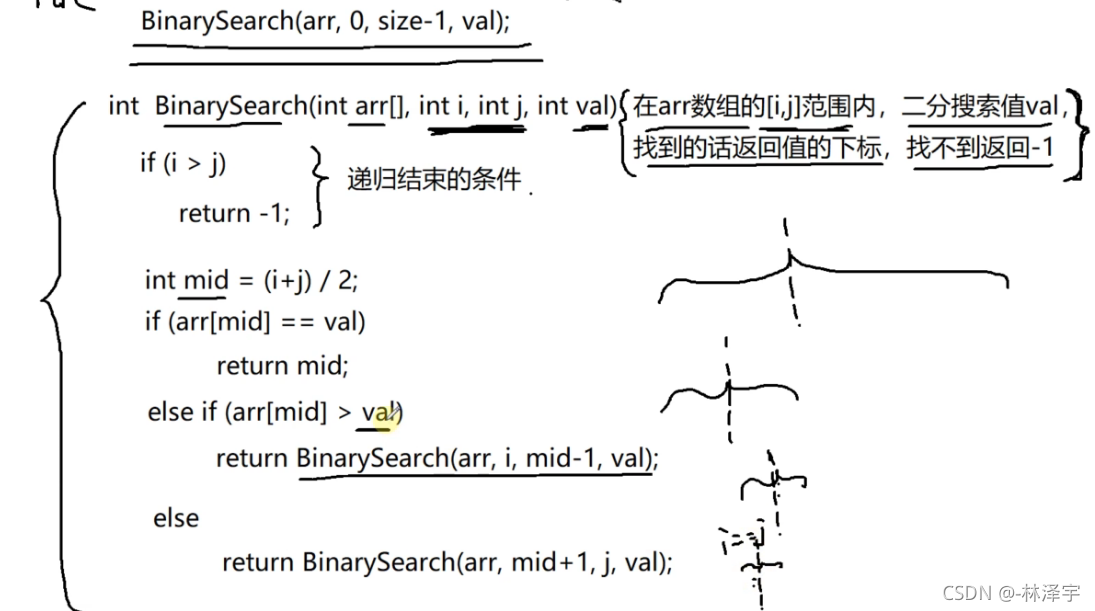
如果找到了,就把mid一直返回去
如果找不到,就把-1一直返回去
#include <iostream>
using namespace std;
//二分搜索递归代码
int BinarySearch(int arr[], int i, int j, int val)
{
if (i > j)//递归结束的条件
return -1;
int mid = (i + j) / 2;
if (arr[mid] == val)
{
return mid;
}
else if (arr[mid] > val)
{
return BinarySearch(arr, i, mid - 1, val);
}
else
{
return BinarySearch(arr, mid + 1, j, val);
}
}
//二分搜索非递归实现
int BinarySearch(int arr[], int size, int val)
{
return BinarySearch(arr, 0, size - 1, val);
}
int main()
{
int arr[] = { 12, 25, 34, 39, 45, 57, 63, 78, 82, 96, 100 };
int size = sizeof arr / sizeof arr[0];
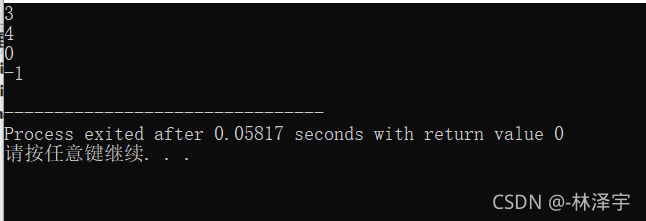
cout << BinarySearch(arr, size, 39) << endl;
cout << BinarySearch(arr, size, 45) << endl;
cout << BinarySearch(arr, size, 12) << endl;
cout << BinarySearch(arr, size, 64) << endl;
return 0;
}
















 1574
1574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











