







Kruskal克鲁斯卡尔算法理论
Kruskal克鲁斯卡尔算法是处理边的,所以在稀疏的边比较少的连通网中,用Kruskal克鲁斯卡尔算法效率就比较高。
在边比较多的连通网中,用Prim普里姆算法效率比较高。

所选边的2个顶点应属于两棵不同的树,意思是,不能形成回路。
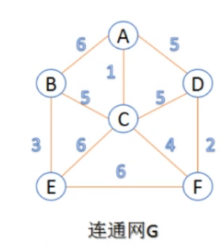
首先,A-C边的权值最小,所以我们选择A-C边,在A和C没有连接起来的时候,A和C哪里都去不了,所以A和C连起来是没有回路的。
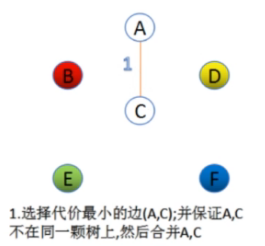
然后D-F边的权值最小,我们选出来。
而且D-F连接起来也不产生回路。
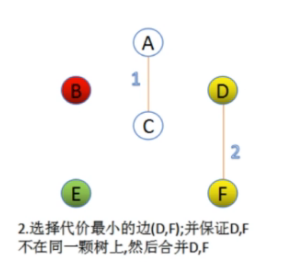
然后此时B-E边的权值最小,我们选择B-E,B-E连接起来也没有回路
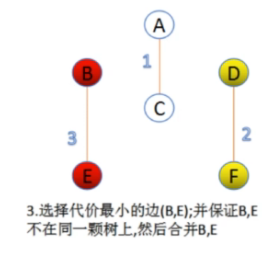
然后此时C-F的边的权值最小,我们选择C-F,而且C-F连接起来没有回路。
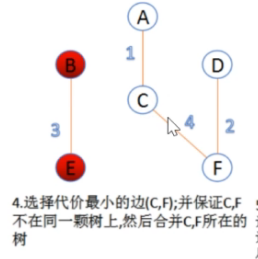
然后此时B-C,C-D,A-D的权值都是5,都是当前权值最小的边。
但是C-D或者A-D一连起来,就形成回路了。
所以我们选择B-C,因为B-C连接起来形成回路。

克鲁斯卡尔算法的两个操作
1、记录2个点之间,判断连接会不会形成回路。
2、对带权值的边集进行排序,从小到大选择边,打印边。
怎么判断会不会形成回路?
就是看它俩从原来位置出发,能不能到达同一个地方。
比如说,我是一个点,你是一个点,咱俩在连接之前,咱俩从各自所属的边上去行走的时候,会不会到达同一个地方,如果到达同一个地方,咱俩一连,肯定形成回路了。
如果咱俩在连接之前,在自己所属的边上去走的话,走到头,都走不到一块,说明咱俩是碰不到一起的,所以咱俩一连接,肯定不会形成回路。

假如说,我们已经有边集数组,并且已经排好序了,首先我们第一个选择的是权值是1的A-C边了,

数组的每个元素都初始化为-1,-1表示这个节点哪也去不了
A-C先不着急连接,因为连起来可能产生回路,所以我们先判断在连接之前,A和C按照原来各自的走向,能不能走到同一个地方,A的编号是0,我们看数组0号下标的值是-1,代表哪也去不了,C的编号是2,我们看数组2号下标的值是-1,代表哪也去不了,也就是说,在A-C连接之前,A和C哪也去不了,所以,A-C连接以后不会产生回路,所以我们选择A-C,并且进行打印。
用完了以后,执行
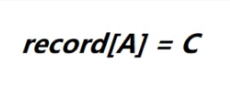
也就是把数组0号下标的值改为2
然后我们选择此时权值最小的边:D-F,我们先判断,数组3号下标和5号下标对应的值是-1,表示D和F在连接之前,哪也去不了,所以我们选择D-F边,连接起来不会产生回路。我们选择D-F,并且打印

打印后,执行
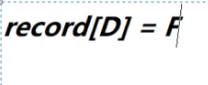
在数组的3号下标的值改为5
然后我们选择此时权值最小的边:B-E,我们先判断,我们看数组1号下标的值是-1,数组4号下标的值也是-1,说明B和E在连接之前,哪也去不了。
所以我们选择B-E,B-E连接起来不会产生回路,我们打印B-E
然后执行

在数组1号下标的值改为4

然后我们选择此时权值最小的边:C-F,我们先不连接,进行判断,我们看数组2号下标的值是-1,数组5号下标的值是-1
所以C和F在连接之前,哪也去不了
所以我们选择C-F连接起来,不会形成回路,然后打印,
然后执行
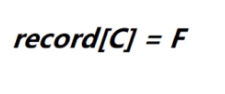
就是把数组2号下标的值改为5
然后此时权值最小的边有:A-D,C-D,B-C
我们先判断A-D,数组0号下标的值是2,0可以到达2,即A-C是连着的,然后我们看2,2可以到达5,即C-F是连着的,我们再来看5,是-1,5走不了,即F走不了,也就是说,最终是0可以走到5,即A可以走到F,我们现在看数组下标为3的值是5,即3可以到达5,即D可以到达F,即A-F,D-F,A和D在连接之前就可以走到同一个位置了,连接以后,肯定就形成回路了。

我们现在看C-D,我们看数组下标为2的值是5,2可以走到5,即C可以走到F,我们看下标5的位置是-1,F走不了,
我们看数组下标是3的值是5,3可以走到5,即D可以走到F,即C和D在连接之前是可以走到同一个位置F的,所以C和D连接后肯定形成回路。
我们现在看B-C。我们看数组下标是1的值是4,1可以走到4,即B可以走到E,然后我们看下标为4的值是-1,即E哪也走不了。
我们看数组下标为2的值是5,即2可以走到5,即C可以走到F,下标为5的值是-1,说明F哪也走不了。所以在B-C连接之前,B只能走到E,C只能走到F,是不会相遇的,走不到同一个地方,所以B-C连接起来不会形成回路的。
所以我们选择B-C,打印

Kruskal克鲁斯卡尔算法代码实现
package com.fixbug;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.Scanner;
/**
* 描述: 最小生成树 - 克鲁斯卡尔算法代码实现
*
* @Author shilei
*/
public class Kruskal {
/**
* 定义边的类型
*/
static class Edge{
int start;//表示边的起点
int end;//表示边的终点
int cost;//表示边的权值
public Edge(int start, int end, int cost) {//构造函数
this.start = start;
this.end = end;
this.cost = cost;
}
@Override
public String toString() {//转成字符串
return "Edge{" +
"start=" + start +
", end=" + end +
", cost=" + cost +
'}';
}
}
public static void main(String[] args) {
//定义顶点信息和顶点的个数
char[] vertics = {'A', 'B', 'C', 'D', 'E', 'F'};
int number = vertics.length;
//定义边集数组,存储所有边的信息
ArrayList<Edge> edgeList = new ArrayList<>(number);
//手动输入边的信息,建立边集数组
Scanner in = new Scanner(System.in);
System.out.print("输入边的个数:");
int edgeNumber = in.nextInt();
in.nextLine();//把读完整数,缓冲区剩余的回车读掉
System.out.println("输入边的信息:");
for (int i = 0; i < edgeNumber; i++) {
String line = in.nextLine();
String[] infos = line.trim().split(" ");
//获取起点和终点的编号
int start = 0, end = 0;
for (int j = 0; j < vertics.length; j++) {
if(vertics[j] == infos[0].charAt(0)){
start = j;
} else if(vertics[j] == infos[1].charAt(0)){
end = j;
}
}
//获取输入的权值
int cost = Integer.parseInt(infos[2]);
//把边的信息添加到边集数组当中
edgeList.add(new Edge(start, end, cost));
}
//对边集数组按边的权值,小到大进行排序
Collections.sort(edgeList, (a, b)->{
return Integer.valueOf(a.cost).compareTo(b.cost);
});
/*edgeList.forEach((a)->{
System.out.println(a.start + " " + a.end + " " + a.cost);
});*/
//开始根据Kruskal算法挑选最小生成树的边
//record用来记录某个顶点最终能跑到的顶点的编号
int[] record = new int[number];
Arrays.fill(record, -1);//初始化为-1
for (int i = 0; i < edgeList.size(); i++) {
Edge edge = edgeList.get(i);
int m = findPath(record, edge.start);
int n = findPath(record, edge.end);
if(m != n){ //m == n 表示连接edge.start和edge.end,会产生回路
//表示edge.start和edge.end走不到同一个顶点,所以连接起来没有回路
record[m] = edge.end;
System.out.println(vertics[edge.start] + " -> " +
vertics[edge.end] + " cost: " + edge.cost);
}
}
}
/**
* 找id编号的顶点最终能走到哪个顶点去,返回该顶点的编号
* @param record
* @param id
* @return
*/
private static int findPath(int[] record, int id) {
while(record[id] != -1){
id = record[id];
}
return id;
}
}


















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











