







 本文介绍了CFAN(Coarse-to-Fine Auto-Encoder Networks)在实时人脸配准中的应用。该模型由四个级联的自编码器网络组成,逐步细化特征点定位。每个网络具有四层,使用sigmoid激活,最后一个层为线性激活。通过无监督预训练和有监督全局训练优化参数,以增强模型泛化能力。在测试中,模型展示了良好的性能。
本文介绍了CFAN(Coarse-to-Fine Auto-Encoder Networks)在实时人脸配准中的应用。该模型由四个级联的自编码器网络组成,逐步细化特征点定位。每个网络具有四层,使用sigmoid激活,最后一个层为线性激活。通过无监督预训练和有监督全局训练优化参数,以增强模型泛化能力。在测试中,模型展示了良好的性能。
实习要做的深度学习的项目,先看论文预热一下:
Coarse-to-Fine Auto-Encoder Networks (CFAN) for Real-Time Face Alignment
Jie Zhang 1,2 , Shiguang Shan 1 , Meina Kan 1 , and Xilin Chen 11 Key Lab of Intelligent Information Processing of Chinese Academy of Sciences
(CAS), Institute of Computing Technology, CAS, Beijing 100190, China
2 University of Chinese Academy of Sciences, Beijing 100049, China
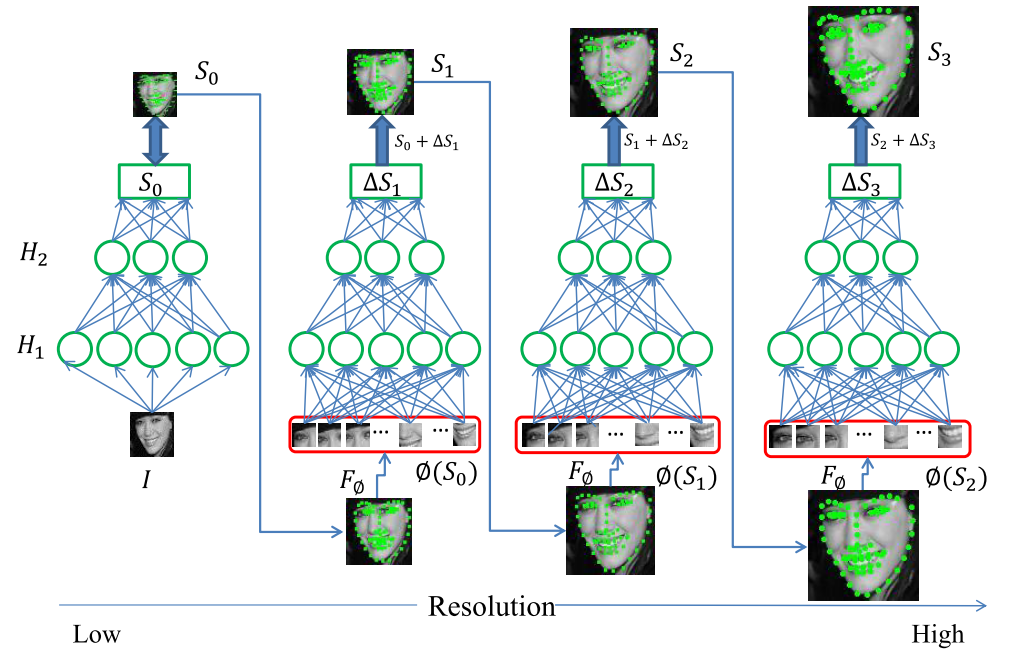
1.CFAN由4个级连的SAN网络构成,每个都是四层网络,三个隐层,用sigmoid激活,最后一层为线性激活。每一个SAN的输出图像分辨率逐渐变大,定位逐渐逼近精准。
第一个全局SAN用于粗定位68个形状特征点,输入为50*50的低分辨率图像,即2500个输入单元,最终输出为68个形状特征点的位置,即68*2=136个输出元素。中间层分别为1600,900,400个单元。
三个局部SAN的输入为68个特征点在高分辨率图中从周围区域提取出来的形状索引特征(SIFT)。输出仍然为逐步校正后的136个特征位置。原始输入应该是从每个形状特征点周围提取了128个SIFT特征,即共68*128=8704个特征,太大,采用PCA的方法,分别降维到了1695、2418、2440输入元素。中间层分别为1296,784,400个单元。
2.SAN的训练采用先用无监督的预训练进行分层训练,粗调参数(可采用sparse autoencoder的方法来预训练),然
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









