







迭代
迭代协议
1.python中没有接口,有协议protocol
2.可迭代:实现了迭代协议这个功能
如何就是实现了迭代协议:?
对象中支持_next_0方法,能够获取到下一个元素。
验证:
f = open('data.txt',encoding='utf8')
f._next_() #调用该方法
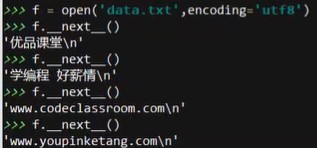
将file中的内容都调用完,会抛出异常:stopIteration:停止遍历
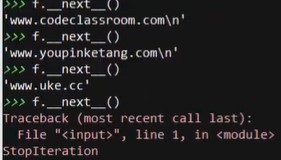
全局函数next:
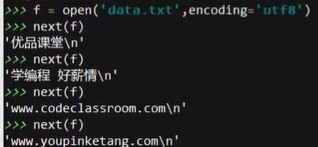
用for循环:
将file中内容读取到列表中:用readlines方法——返回一个列表,将file中内容都找到放到list中
可迭代的对象,或者实现迭代器协议的对象,支持遍历/循环。
英文:iteration,iterate,iterative
3.使用迭代对象的优势:
迭代工具:for循环

迭代器对象 自己实现了_next_方法
file,已经实现了迭代,本身具备_next_方法
验证:
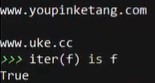
f = open('data.txt',encoding='utf8')
iter(f) is f
# f本身是不是就是一个迭代器?
可迭代对象
用iter()–>iter()方法将其转化为迭代器对象,在用for时往对象自动添加了iter()方法,将其转化为迭代器对象
验证:
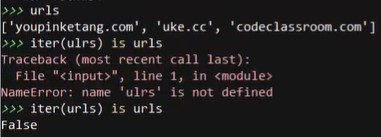
urls=['youpinketang','uke.cc']
iter(urls) is urls
# urls本身是不是一个迭代器
所以:urls不能调用_next_方法。
通过iter函数将其转化为迭代器对象,就可以使用next()函数。
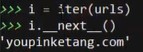
i = iter(urls)
i._next_()
1.列表中括号[]
2.元组括号()
3.字典表视图花括号{}
将字典表的 键/值 输出为字典表视图,看着像列表
# 打印出来只有键没有值
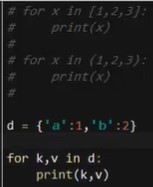
d = {'a':1,'b':2}
for k in d:
print(k)
# 键和值一起打印,操作不了,python3不支持
d = {'a':1,'b':2}
for k,v in d:
print(k,v)
4.文件也是可迭代对象file
创建文件data.txt
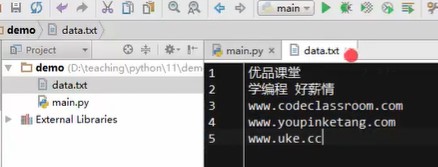
保存,关闭该文件
接下来:打开该文件,操作
# 直接写'data.txt',因为pycharm已经把环境路径配置好了,新建文件就在打开时的路径,操作文件也在这个路径
f = open('data.txt',encoding = 'utf8')
# 读取所有信息,打印所有信息
print(f.read())
# 或者可以读取一行
print(f.readline())
# 或者将读取的信息都放到一个列表list中,可以遍历列表
f = open('data.txt',encoding = 'utf8')
print(f.readlines())
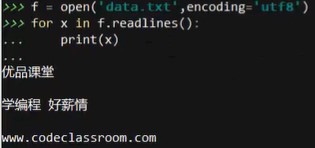
for x in f.readlines()
# 或者遍历该文件,打印
for line in f:
print(line)
# 打印结果每一行中间空一行,等于每一行字符串后面有两个/n,原因:data.txt文件中每一行后面原本就有一个/n,现在print打印会默认在后面再加上一个终止符/n。
# 现在可以改变以下print后面的终止符
for line in f:
print(line,end=' ')


实际开发中,for x in f.readlines():/for line in f: 哪个好?后面不用readlines的好,因为readlines时将file中所有内容塞到列表中,新生成一个对象,占用内存,效率不高。
实例
列表使用for和不适用for
# 列表使用for,默认使用iter
l = [1,2,3]
res = []
for x in l:
res.append(x**2)
res
# 列表不适用for,先使用iter将本身转化为迭代器对象,再用next
i = iter(l) #用iter将list转化为迭代器对象,装到i中
while True: #此处必须大写,这是死循环,终止条件在后面
try:
x = res.append(next(i)**2)
except StopIteration:
break
# 实际开发中用列表推导,效率更高
resut = [x**2 for x in l]
字典表dict
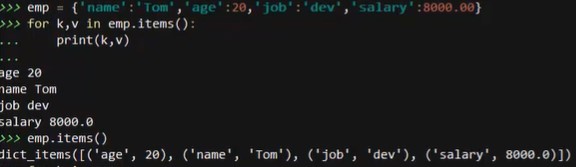
emp = {'name':'tom','age':20,'job':'dev','salary':8000.00}
for k,v in emp.items():
print(k,v)
# 看item是什么类型
emp.items()
# 打印字典的键,不加上items
for k in emp:
print(k)
#看打印出来的键是什么类型
emp.keys()
emp.values()
# dict本身不是迭代器对象,dict的键、值也不是,需要用iter将其转换为迭代器对象
keys = emp.keys()
keys
iter(keys) is keys
i = iter(keys)
i._next_()
next(i)


推导

urls =['youpinketang.com','uke.cc','codeclassr']
# 将urls列表中的小写转换为大写
res3 = [url.upper() for url in urls]
#筛选,前面是返回的结果,for是遍历的过程,if是条件过滤。可迭代对象都可以放到推导的表达式的集合中
res4 = [url for url in urls if url.endswith('.com')]
# 将上面的推导还原为之前的笨方法
res =[]
for x in urls:
if x.endswith('.com'):
res5.append(x)
# 如果逻辑特别长,就要考虑下是否还能把条件放到推导中
import this:可以看到python设计的语言哲学
内置可迭代对象
1.range
range本身是一个类型,不是list
for i in range(1,11):
print(x)
result = [x**2 for x in range(1,6)]
# range本身不是迭代器对象,需要用iter转化
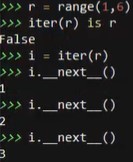
r = range(1,6)
iter(r) is r
i = iter(r)
i._next_()
next(i)
2.函数中使用的内置迭代工具
可以帮助批量操作
zip
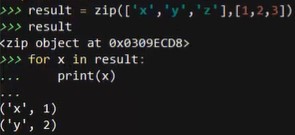
# zip,将两个集合合成一个,并对应起来
result = zip(['x','y','z'],[1,2,3])
for x in result:
print(x)
# 结果为元组,结构:x与1对应,y与2对应,z与3对应,
其本身是迭代器对象,自动具有_next_()方法
map
def double_number(x):
return x*2
l = [1,2,3,4,5]
result = list(map(double_number,1))
# 调用double_number函数,不用在函数后面加括号。map(函数,可迭代对象),将可迭代对象输入到前面函数中
print(result)

函数定义与参数
函数定义
函数:封装我们需要的语句,形成一个整体的逻辑,我们需要的时候再去直接调用这个方法名。
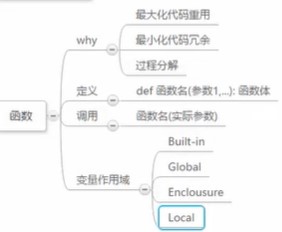
1.原则
最大化代码重用:dry-don’t repeat yorself
最小化代码冗余
过程分解
为啥那么使用函数
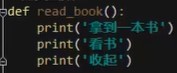
定义一个函数,def,有括号(),但是函数中的语句,没有要传递的参数。
定义一个函数,函数括号()中定义了参数,这些参数会传到函数中的语句中,函数中的语句,用format格式化方法将参数传进去。
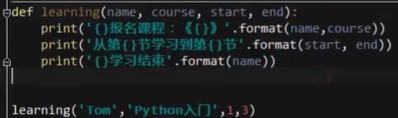
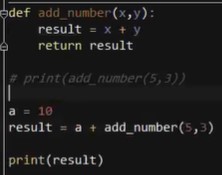
2.定义:def函数名(参数1,…):函数体
函数体逻辑简单的话可以直接放到方法名后面

3.调用 函数名(实际参数)
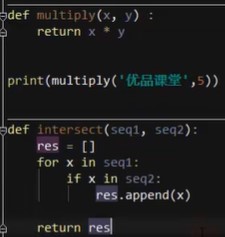
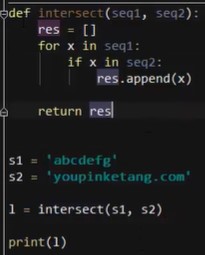
4.函数变量作用域local
Enclousure:封装,使用这个,协商nonlocal
外面的变量:global全局
Built-in:内置的
作用范围越来越大
def func():
global x
x = 99
print(x)
# 缩进部分是函数内容,函数缩进完的这里结束

在函数中定义全局变量,

使用封装变量:

只调用了func()函数,x=100

nested:嵌套的,内置的
将nested()写进去,就是调用了nested()函数。nested()函数外面的那个x就是封装。
打印x的顺序与函数写的顺序无关,只是与执行打印顺序有关,上面是先执行的nested函数。
也可以将fun()函数中的print()写到前面,就可以先执行func(),将nested()函数写道后面,就是后执行nested()函数

上面为函数套函数
参数
参数的传置方式
1.参数——传递
不可变类型
int型,float浮点型,字符串型str,元组tuple
这些都是实际对象,给变量赋值时,每次改变一个赋值对象,都会更改变量的指定。

传递副本给函数,函数内操作不影响原始值,因为不变类型是直接操作值。
int型

字符串str型:

可变类型
列表list,字典表dict

这些是引用对象,原来有一个值,变量赋值时是引用原来的值,成为副本。
传递地址引用,函数内操作可能会影响原始值,因为对值的副本操作,副本值可变。
列表list:

不改变list中值的方法:

操作的就是l的副本,不影响l的原来值。















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









