







数据文件的读写
文本文件读取
举例说明
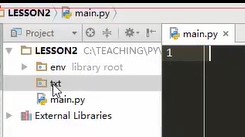
把不同文件的操作放到不同目录中,
project中点右键,添加一个目录
如果只是纯粹的一个文件,不存在包的概念的话,直接选directory,目录

创建txt文件目录
这样,不会在目录中创建__init__文件
将操作的文件放到txt目录中,不同文件在不同目录中操作
在txt目录上点右键

添加一个run.py文件。跟原来main.py文件没关系,直接在txt中操作
# 定义一个函数,可以在函数中写一个文档的字符串说明。这样,想查看这个函数的帮助,可以写help txt_writer(),就能看到这个函数的相关信息.
def txt_writer()
"""写文件"""
with open('data.txt','w',encoding='utf8') as f # 写到上下文里面,便于自动释放句柄/资源,f就是文件句柄。接下来写内容
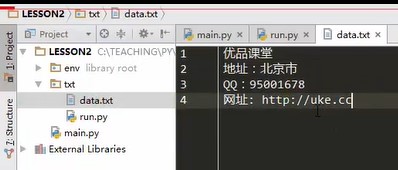
f.write('优品课堂\n') #write是写一行,写多行可以将其放到一个列表中,用writelines方法
lines = ['地址:北京市\n',
'QQ:95001678\n',
'网址:http://uke.cc']
f.writelines(lines) #writelines方法写入一个集合,将列表lines写入
# 上面写好一个函数,运行脚本不会执行,还需要写一个主函数
if __name__ == '__main__' # 这个代码片段常用,pycharm中已经集成好了,可以使用代码片段帮助快速生成。写main,按tab键就可以。
txt_writer()
运行上面的代码,结果,在txt目录下创建了data.txt文件,结果如下
读取:
def txt_writer()
"""写文件"""
with open('data.txt','w',encoding='utf8') as f
f.write('优品课堂\n')
lines = ['地址:北京市\n',
'QQ:95001678\n',
'网址:http://uke.cc']
f.writelines(lines)
def txt_read()
"""读文件"""
with open('data.txt','r',encoding='utf8') as f #接下来读取可以对其进行遍历,或用readlines将其读到一个集合中
for line in f #f是一个迭代器。read是一次性读取所有文字作为一个整体,readlines是将每一行读到一个列表中
print(line,end=' ') #print会自动在每一行后面加/n,而前面文件的内容也加入了/n,这样打印出来的结果可能是中间有2个换行。这样将print后面自带的/n换成空.
if __name__ == '__main__' # 这个代码片段常用,pycharm中已经集成好了,可以使用代码片段帮助快速生成。写main,按tab键就可以。
txt_writer()

实际开发中涉及不同数据源的数据交换,数据量大,比如从数据库中导出信息,或从网上下载了一些xsml或Json格式,如果都将这些文件换成.txt文件,以后解析读取麻烦,因为没有语义上的标签或意义在里面。
考虑用其他格式
不同语言框架平台之间交换数据,常见的有csv,
csv文件读取
定义
csv:
c,comma逗号,s,separate分隔,v,value值
逗号分隔的值
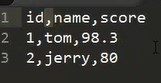
tsv
tab键分隔的值
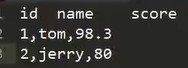
这种文件本质上还是文本文件,只是后缀叫csv/tsv,但是带有语义标签了,逗号是区分不同字段不同行不同列的
- csv文件从哪里来
数据来自于程序的输入输出,可能某个数据库导出
举例说明,从数据库中导出一张表的数据,将其变成csv,放到我的项目下面,对其进行操作
先创建一个directory目录
将数据库中的文件以csv格式导入到csv目录下

在csv目录下新建run.py文件,用来处理csv文件
基本读取
reader方法基本读取
- csv文件读取
csv文件操作不用第三方包/库,在内置模块中就有
csv包下的两个类,reader和write,product.csv文件是可迭代的
import csv
def csv_read():
"""csv基本读取"""
with open('product.csv',encoding='utf8') as f
# csv包下的两个类,reader和write,product.csv文件是可迭代的
reader = csv.reader(f) #下面先把第一行打印出来,由于是迭代器,迭代器可使用for遍历
headers = next(reader) #next全局函数,将第一行遍历出来。第一行遍历出来后,指针不会回去了,第一行就不能再无遍历了,下次遍历直接从第二行开始
print(heardes)
for row in reader
print(row)
if __name__ == '__main__'
csv_read()
运行出错

编码问题:
打开product.csv,看下其本质编码是什么
pycharm会提示编码是什么,pycharm右下角

在这里转换一下,
点击右下角的utf16,转换为utf8,
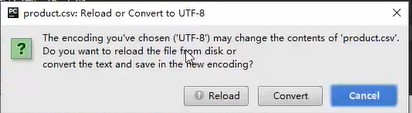
convert,转换为utf8
重新运行代码

就是将每一行做成一个列表,打印出来。这样知道了列表信息就可以随意检索了
一个row就是一个list
比如打印某一行的信息,或者给他格式化一下,
按照列表索引方式读取
reader读取结果本身是一个列表
- 打印一下一个字符串结果:
import csv
def csv_read():
"""csv基本读取"""
with open('product.csv',encoding='utf8') as f
reader = csv.reader(f) #
headers = next(reader)
print(heardes)
for row in reader
# 一个row就是一个list,打印一下一个字符串结果
print('编号:{}\t产品:{}\t单价:{}'.format(row[0],row[1],row[3]))
if __name__ == '__main__'
csv_read()

在数据库层面,最上面一行是来自数据库列头,但是到了csv文件中,变成了文本,变成文本之后跟下面就没关系了。实际操作中希望id跟下面的信息一一对应起来,可以用name.tuple,命名的元组,按照名称去找。上面写的话是索引,容易出错。

将reader读取出的内容给namedtuple
- namedtuple来映射一个列名
实际操作中希望id跟下面的信息一一对应起来,可以用namedtuple,命名的元组,按照名称去找。
namedtuple相当于定义一个简易的类,就是定义一个对象,
import csv
from collections import namedtuple
def csv_read():
"""csv基本读取"""
with open('product.csv',encoding='utf8') as f
reader = csv.reader(f) #
headers = next(reader)
print(heardes)
for row in reader
# 把这个对象起一个名称,忘了也不用担心。
def csv_read_by_namedtuple():
"""读取csv并用namedtuple映射列名"""
with open('product.csv',encoding='utf8') as f
reader = csv.reader(f)
headers = next(reader) #将第一行隔离开,否则把第一行也当作数据打印了。把头部列出来,读取第一行。接下来定义一个namedtuple对象
#Row = namedtuple('Row',['productID','Product'] ) # name对象,用namedtuple来定义,定义的名称就叫Row。在后面给他一个列表.后面列表给他的东西就是最终的对象,假定的这个类的成员。由于刚才已经读取了,在headers中,所以没必要再一个个去写,heardes本来就是一个列表,将headers列表赋予
Row = namedtuple('Row',headers) # 会将headers中读到的列作为Row的名称.接下来将每一列数据放到他的ID字段上去。比如将苹果汁放到productname这个字段上.声明的这个row tuple作为一个对象,只是一个带标签的框架结构,然后得到一行数据时是有值的,每遍历出一行就是创建 了一个实例,这个实例就使用声明的Row的结构,然后将遍历出来的一行跟结构标签一一对应起来。下面的循环中做的是这个。
for r in Reader #上面是声明了一个tuple,相当于一个类,现在是相当于创建类的实例。创建实例要传值.
row = Row(*r) #把刚才读到的列表信息r一起给他。方法参数传递,tuple或list可以用星号*来解包,自动会将列表中的每一列对应到Row里面的头部headers对应的每一列上。roe等于Row创建他的实例,把r的信息解包给它。
print(row)
print('编号:{}\t产品:{}\t单价:{}'.format(row[0],row[1],row[3]))
if __name__ == '__main__'
csv_read_by_namedtuple()
解释声明Row,Row = namedtuple(‘Row’,headers),遍历Row中的内容,for r in Row:
声明的这个row tuple作为一个对象,只是一个带标签的框架结构,然后得到一行数据时是有值的,每遍历出一行就是创建了一个实例,这个实例就使用声明的Row的结构,然后将遍历出来的一行跟结构标签一一对应起来。下面的循环中做
的是这个。

运行结果,打印出来是Row对象的类型

- namedtuple,可以像使用类的实例一样点出他的结果,上面打印时是为了省事写了一个row,需要的话可以任意。
比如:带格式化的,
用的时候不考虑是第几列,直接像使用类的实例一样,
import csv
from collections import namedtuple
def csv_read():
"""csv基本读取"""
with open('product.csv',encoding='utf8') as f
reader = csv.reader(f) #
headers = next(reader)
print(heardes)
for row in reader
def csv_read_by_namedtuple():
"""读取csv并用namedtuple映射列名"""
with open('product.csv',encoding='utf8') as f
reader = csv.reader(f)
headers = next(reader)
Row = namedtuple('Row',headers)
for r in Reader
row = Row(*r)
print('{} -> {} -> {}'.format(row.ProductID,row.ProductName,row.UnitPrice)
print('编号:{}\t产品:{}\t单价:{}'.format(row[0],row[1],row[3]))
if __name__ == '__main__'
csv_read_by_namedtuple()
将读取出的内容给字典
字典表自己的读取方法,csv.DictReader()
7. 字典表
mport csv
from collections import namedtuple
def csv_read_by_dict():
"""读取csv到字典表"""
with open('product.csv',encoding='utf8') as f
reader = csv.DictReader(f) # 用csv.reader(f),总是当作列表来包装,当作字典表用dictreader方法
for row in reader #每个row是一个字典表,再字典表中遍历
print(row)
print('{} -> {} ->{}'.format(row['ProductID'],row.get('ProductName','未填写'},row.get{'UnitPrice',0.0}

这样处理就是将文本文件中原本用逗号分隔开的文本当作python对象去处理,之后,这样再去获取每一列,就可以操作了。
运行结果

不同的数据结构调用的方法不同
csv文件的写
读文件通过读取器,reader
写文件通过writer
python里面处理后的数据,将其保存为csv文件。
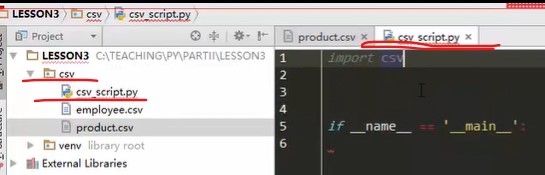
不要把文件名取为跟python已有的模块名一样的名称,否则在导入模块时,python搞不清在导入时到底导入哪一个。
比如,这里的文件名csv_script.py,名为csv.py的话,因为.py文件本身就既是脚本也是模块,因而在csv.py中写入代码import csv时,会出错。
不要定义python内置模块或第三方模块已有的名称。
将list中内容写入
import csv
def csv_write()
"""写入csv文件""" #和文本文件类似,操作要通过open方法,找到一个上下文对象,命名为f。写之前先把数据准备好,将外面得到的数据整理为python的数据结构,比如说有头部,就将头部放到heades列表中
headers = ['编号'.'课程','讲师'] #头部,表头。接下来有若干条数据,类似于数据库中的行/列,最典型的就是tuple
rows = [(1,'Python','Eason'),
(2,'C#','Eason'),
(3,'Django','Eason'),
(4,'.NET','Eason')]
#头部放到一个列表,一个行中放了多个元组,1个元组有3列,跟上面对应, 多个元组放到1个list中。
#现在有两个数据结构:1个是单行多列,一个列表,2个是 多行,tuple适合描述数据表里的行.数据库读写操作python里返回的行也是tuple
#数据可以赋值,pycharm中ctrl+d
#接下来将他们写到文件中。不是写入已有文件,是自己创建一个
with open('my_course.csv','w',encoding='utf8') as f
# with不是必须的,但是可以完成创建、读写、关闭一条龙,代码写完会自动close
#上面写好了表头和底下的内容,接下来写入,要构造写入器
writer = csv.writer(f) #接下来文件的写操作交给csv包装以后的写入器writer来帮助搞定
writer.writerow(headers) #写入方法,写一行,先将表头写入,
writer.writerows(rows) #写入列表中的多行,
if __name__ == '__main__'
csv.write()
运行结果:

少了一个r,
更改后,运行结果
 运行结果没啥变化,但是左边项目文件中多了一个my_course.csv,打开如右图。结果中文本每一行之间多加了一个空行。
运行结果没啥变化,但是左边项目文件中多了一个my_course.csv,打开如右图。结果中文本每一行之间多加了一个空行。
那么在刚才创建文件时,在后面加上newline=’ ',空字符,newline后面默认是/n,将其换掉。
with open('my_course.csv','w',encoding='utf8',newline=' ') as f
运行结果

结果,文本中的逗号不是tuple中的逗号,而是由包装后的csv.write创建的。
读写放到一起
import csv
def csv_reader()
"""读取csv"""
with open('my_course.csv',encoding='utf8') as f
reader=csv.reader(f)
headers = next(reader)
print(headers)
for row in reader
print(row)
def csv_write()
"""写入csv"""
headers = ['编号'.'课程','讲师']
rows = [(1,'Python','Eason'),
(2,'C#','Eason'),
(3,'Django','Eason'),
(4,'.NET','Eason')]
with open('my_course.csv','w',encoding='utf8') as f
writer = csv.writer(f)
writer.writerow(headers)
writer.writerows(rows)
if __name__ == '__main__'
csv.write()
运行结果

字典表内容写入
import csv
def csv_reader()
"""读取csv"""
with open('my_course.csv',encoding='utf8') as f
reader=csv.reader(f)
headers = next(reader)
print(headers)
for row in reader
print(row)
def csv_write_dict()
"""以dict形式写入csv""" #准备数据时就准备为字典表形式
headers = ['ID'.'Title','Org','Url']#在list内,底下的rows中内容外面还是列表,里面换成dict。
rows = [{'ID':1,'title':'Python','Org':'Youpinketang','Url':'http://uke.cc'}
{'ID':1,'title':'Python','Org':'Youpinketang','Url':'http://uke.cc'}
{'ID':1,'title':'Python','Org':'Youpinketang','Url':'http://uke.cc'}
{'ID':1,'title':'Python','Org':'Youpinketang','Url':'http://uke.cc'}
dict(ID:1,title:'Python',Org:'Youpinketang',Url:'http://uke.cc')
dict(ID:1,title:'Python',Org:'Youpinketang',Url:'http://uke.cc')]
#字典表声明方法,直接写花括号/写dict函数
with open('my_course2.csv','w',encoding='utf8',newline=' ') as f
writer = csv.DictWriter(f,headers) #把headers作为参数传给函数的第二个参数,这样用DictWriter构造出来文件,就知道headers是表头。仅是知道,还没写
writer = csv.writer(f)
writer.writeheader() #写入器方法writeheader
writer.writerows(rows)
if __name__ == '__main__'
csv.writer_dict()
#字典表仅是代码中有这个概念,写到csv中后格式都是统一的,以逗号隔开,不存在字典表这回事

已有的在写一次,会把原来写入的给覆盖掉。
JSON文件处理
json简介
JSON也是在不同程序或框架语言之间交换数据的标准格式,本质是一个文本文件,其实是javaScript描述的注释的一个文档。
json的格式,不论以后做什么语言的web开发,都会用到。因为它们开放的API返回的都是JSON,
XML,相对结构复杂,解析时麻烦一些,JSON比较轻量级。
json在做web开发时是做一些API的接口,就是放到互联网上,发布一个公开的URL地址,如果别人请求,要提交数据/传参数,传到这个URL地址后,在浏览器中会返回一个json的文档,这个文档就是一个字符串,格式看起来很像,但是不一样。
如果想把python里面的字典表转换成json格式描述的对象的话,可以可以:声明一个json格式的字符串,来自于刚才的data。使用json.dumps方法,dump(倾泻倾倒),加一个s不是复数,他是把括号中传的内容变为字符串形式。
格式类似于python中的字典表,也有些差异,
举例:
打开网址json.org,有详细介绍
字典表转换为json数据
把python里面的字典表转换成json格式描述的对象的话,可以可以:声明一个json格式的字符串,来自于刚才的data。使用json.dumps方法,dump(倾泻倾倒),加一个s不是复数,他是把括号中传的内容变为字符串形式。
新建工作目录和文件
import json
def json_basic()
data = {'ID':1,
'课程':'Python精讲',
'机构':'优品课堂',
'单价':98.00,
'网址':'http://codr.cn'}
print('原始数据')
print(data)
print('-'*20)#分割线
# 把python里面的字典表转换成json格式描述的对象的话,可以:声明一个json格式的字符串,来自于刚才的data。使用json.dumps方法,
json_str = json.dumps(data) #把data字典表数据变为json格式的字符串,还没写入文件
print(json_str) #想对比一下的话,可以打印出来之前的data
运行结果

上面一行时原始数据,下面一行是json格式数据的字符串,还做了utf8编码。
由图可知,字典表的结构和json的结构是一致的,语义上不同,json属于json的字符串,字典就是python的字典表。
将json字符串返回为python的字典表
json数据转换为dict, json_data = json.loads ,s不是第三人称单数,是字符串string的意思。
import json
def json_basic()
data = {'ID':1,
'课程':'Python精讲',
'机构':'优品课堂',
'单价':98.00,
'网址':'http://codr.cn'}
print('原始数据')
print(data)
print('-'*20)#分割线
# 把python里面的字典表转换成json格式描述的对象的话,可以:声明一个json格式的字符串,来自于刚才的data。使用json.dumps方法,
json_str = json.dumps(data) #把data字典表数据变为json格式的字符串,还没写入文件
print(json_str) #想对比一下的话,可以打印出来之前的data
print('--'*20)
# json数据转换为dict
json_data = json.loads(json_str) #从刚才json_str字符串里面还原为python字典表结果
print(json_data)
运行结果

json文档操作
写人json文档
json.dump(data,f)
从json文档中读
json.load()
实际开发中,更多是要将其写到文件里面,后面做web编程时,有一个请求api,这边返回一个json文档到你的浏览器上,让你显示,所以这个文档直接保存为json文档也可以,这届写到网页上也可以。
接下来将其当作文件来操作
import json
def json_writer_file()
"""写入json文档"""
data = {'ID':1,
'课程':'Python精讲',
'机构':'优品课堂',
'单价':98.00,
'网址':'http://codr.cn'}
with open('data.json','w',encoding='utf8') as f
json.dump(data,f) #dump不加s,因为不是将其写到字符串里,直接写到文档中。把data写到f里面。
if __name__ == '__main__'
json_writer_file()
运行结果

这个结果就可以拿出来放到网上,作为对外发布的一个接口的数据。做web api,最后还是要输出到网页html上,
import json
def json_writer_file()
"""写入json文档"""
data = {'ID':1,
'课程':'Python精讲',
'机构':'优品课堂',
'单价':98.00,
'网址':'http://codr.cn'}
with open('data.json','w',encoding='utf8') as f
json.dump(data,f) #dump不加s,因为不是将其写到字符串里,直接写到文档中。把data写到f里面。
def json_read_file()
"""读取json文件"""
with open('data.json','r',encoding='utf8') as f
data = json.load(f)
print(data)
if __name__ == '__main__'
json_writer_file()
运行结果

数据还原为python的dict
dict和json类型差异:true/false,null写法不同
import json
def json_type_diff()
""" 类型差异"""
print(json.dumps(False))
print(json.dumps(None))
data = {'Discontinued':False,
'Title':'iphone7s',
'Category':None,
'Price':5999.00}
print(json.dumps(data))
if __name__ == '__main__'
json_type_diff()
python中False,json中false
None----null

其他操作。比如将json的键值对放到类里面,作为类的成员来载入
excel文件读取
安装xlrd
excel文件也可以通过数据库导出
python没有内置模块专门处理excel,安装第三方包,命令行下使用pip安装,pycharm中直接在界面安装,搜索xlrd(读取的包),xlwr(写入的包),更多操作用xlutils(工具包)
目前只用读取的包xlrd

读取
- 表格信息

如果在一个脚本中写入了很多方法,不同方法处理不同文档,有的处理json,有的处理csv,导入包不放到最上面导入也行,写入到函数中
def xl_read()
"""excel读取"""
import xlrd #在函数中导入,只在当前函数中有效,在外面用不着
book =xlrd.open_workbook('product.xls')#xlrd.openworkbook 方法,打开一个表格 #下一步要找到要操作的工作簿sheet
for sheet in book.sheets() #book.sheets方法,名称上看出sheets是一个集合,这个方法函数可以将所有工作表标签找到,遍历工作表中的sheet,
print(sheet.name) #工作簿,sheet,以面向对象形式给他写了属性,打印出sheet的属性name
if __name__ == '__main__'
xl_read()
结果,工作表中的每一个工作簿名称出来了

- 打印数据
def xl_read()
"""excel读取"""
import xlrd #在函数中导入,只在当前函数中有效,在外面用不着
book =xlrd.open_workbook('product.xls')
for sheet in book.sheets()
print(sheet.name)
def xl_read_data()
"""数据读取"""
book = xlrd.open_workbook('product.xls')
sheet = book.sheet_by_name('Product') #过滤出我要操作的哪个sheet,.sheet_by_index方法,按照索引找,.sheet_by_name方法,按照sheet的名称找
print('工作簿:{}'.format(sheet.name))
print('数据行数:{}'.format(sheet.nrows))
# 遍历,用for遍历就可以,但是excel中数据可能很大,for一次性读取,效率低。知道行数以后,可以循环指定次数,只找到指定行
print('产品数据')
print('=' * 50)
for i in range((sheet.nrows))
print(sheet.row_values(i)) #获取索引指定的数据行。.row_values方法
if __name__ == '__main__'
xl_read()
运行

int不能遍历,用range,for i in range((sheet.nrows))
打印结果:

- 只要特定的一行,可以进一步遍历,循环嵌套,循环到这一行,再循环一下这一行的每一列。某一行循环出来是一个列表,这个列表中过的每一列还可以循环出来















 2286
2286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









