







1 索引类型
索引可以提升查询速度,会影响where查询,以及order by排序。MySQL索引类型如下:
从索引存储结构划分:B Tree索引、Hash索引、FULLTEXT全文索引、R Tree索引
从应用层次划分:普通索引、唯一索引、主键索引、复合索引
从索引键值类型划分:主键索引、辅助索引(二级索引)
从数据存储和索引键值逻辑关系划分:聚集索引(聚簇索引)、非聚集索引(非聚簇索引)
常见索引
普通索引
CREATE INDEX <index> ON tablename <field>;
ALTER TABLE tablename ADD INDEX <index> <field>;
CREATE TABLE tablename (, INDEX <index> <field>)
create table user(
id int primary key,
name varchar(20),
age int,
index nameidx (name)
) engine=innodb charset=utf8;
create index ageidx on user (age);
// 查看
show index from user;
唯一索引与”普通索引“类似,不同的就是:索引字段的值必须唯一,但允许有空值。
CREATE UNIQUE INDEX <索引的名字> ON tablename(字段名):
ALTER TABLE tablename ADD UNIQUE INDEX【索引的名字】(字段名);
CREATE TABLE tablename(,UNIQUE【索引的名字】(字段名)):
主键索引:特殊的唯一索引,不允许空值。
组合索引:效率高于多个单一索引。索引列是1-2列的是窄索引,大于2列的是宽索引。设计索引时,尽量采用窄索引。
全文索引(了解,使用ES等代替)
对于大量文本检索,使用like模糊查询,效率很低。采用全文索引可以提高查询速度。MySQL5.6之后,InnoDB和MyISAM都支持全文索引。
create fulltext index nameidx on user (name);
// 使用全文索引,默认是精准匹配。
select * from user where match(name) aginst('a*' in boolean mode);
注1:使用全文索引要注意最小和最大字符数限制。超过限制,不会建立索引。默认3-84个字符。
注2:注意切词,例如b+aaa,会切分成b和aaa。
注3:默认精准匹配,模糊查询需要在boolean mode下,并使用匹配符。
2 索引原理
MySQL官方对索引定义:是存储引擎用于快速查找记录的一种数据结构。需要额外开辟空间和数据维护工作。
-
索引是物理数据页存储,在数据文件中(InnoDB,ibd文件),利用数据页(page)存储。
-
索引可以加快检索速度,但是同时也会降低增删改操作速度,索引维护需要代价。
索引涉及的理论知识:二分查找法、Hash和B+Tree。
Hash结构
Hash底层实现是由Hash表来实现的,是根据键值<key,value>存储数据的结构。非常适合根据key查找value值,即等值查询。但是对于范围查询就需要全表扫描。MySQL中Hash结构主要应用在Memory原生的Hash索引、InnoDB自适应哈希索引。
InnoDB存储引擎结构分为内存结构和磁盘结构,内存结构有自适应哈希索引。当InnoDB注意到某些索引值访问非常频繁时,会在内存中基于B+Tree索引再创建一个哈希索引,使得内存中的B+Tree索引具备哈希索引的功能,即能够快速定值访问频繁访问的索引页。
原因:B+Tree的查询效率取决于树的高度。对于热点Page使用hash索引访问是,一次性查找就能定位数据,等值查询效率优于B+Tree。
show engine innodb status\G;
B-Tree结构
MySQL数据库索引采用的是B+Tree结构,在B-Tree结构上做了优化改造。
- 索引值和data数据分布在整棵树结构中;
- 每个节点可以存放多个索引值以及其对应的data数据;
- 一个树节点中多个索引值升序排列。
B树的搜索:从根节点开始,对节点内的索引值序列采用二分法查找,如果命中就结束查找。没有命中会进入子节点重复查找过程,直到所对应的的节点指针为空,或已经是叶子节点了才结束。
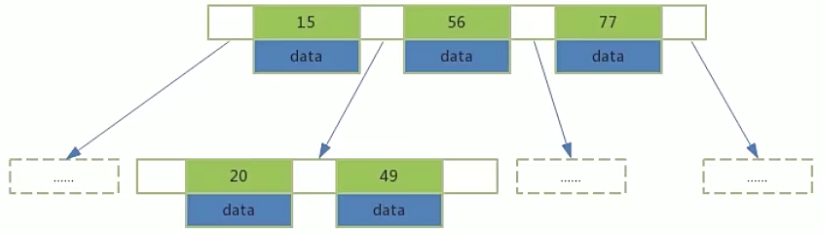
B+Tree结构
- 非叶子节点不存储data数据,只存储索引值,便于存储更多索引值;
- 叶子节点包含所有索引和data数据;
- 叶子节点用指针连接,用于提高区间的访问性能。
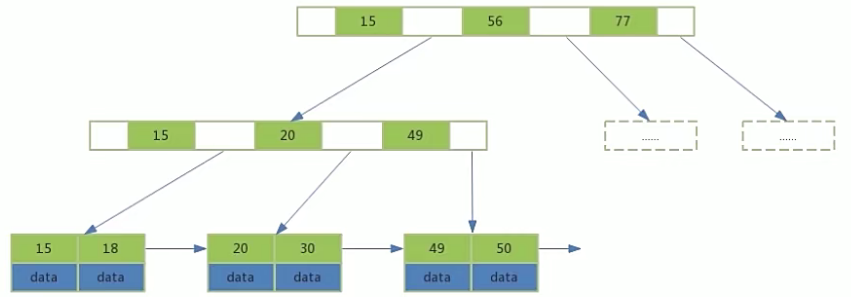
B+Tree主要在范围查询上做了提升。B+Tree只需要定位范围两侧索引,通过叶子节点查找数据;B-Tree则需要遍历范围中每一个节点和数据。
聚集索引和非聚集索引
聚簇索引和非聚簇索引:B+Tree的叶子节点存放主键索引值和行记录属于聚簇索引;如果索引值和行记录分开存放属于非聚簇索引。
主键索引和辅助索引:B+Tree的叶子节点存放的是主键字段值属于主键索引;如果存放的是非主键值就属于辅助索引(二级索引)。
在InnoDB引擎中,主键索引采用的就是聚簇索引结构存储。
聚簇索引(聚集索引)
聚簇索引是一种数据存储方式,InnoDB的聚簇索引就是按照主键顺序构建B+Tree结构。B+Tree的叶子节点就是行记录,行记录和主键值紧凑地存储在一起。这也意味着InnoDB的主键索引就是数据表本身,它按主键顺序存放了整张表的数据,占用的空间就是整个表数据量的大小。通常说的主键索引就是聚集索引。
InnoDB的表要求必须要有聚簇索引:如果表定义了主键,则主键索引就是聚簇索引;如果表没有定义主键,则第一个非空unique列作为聚簇索引;否则InnoDB会从建一个隐藏的row-id作为聚簇索引。
辅助索引
InnoDB辅助索引,也叫作二级索引,是根据索引列构建B+Tree结构。但在B+Tree的叶子节点中只存了索引列和主键的信息。二级索引占用的空间会比聚簇索引小很多,通常创建辅助索引就是为了提升查询效率。一个InnoDB表只能创建一个聚簇索引,但可以创建多个辅助索引。
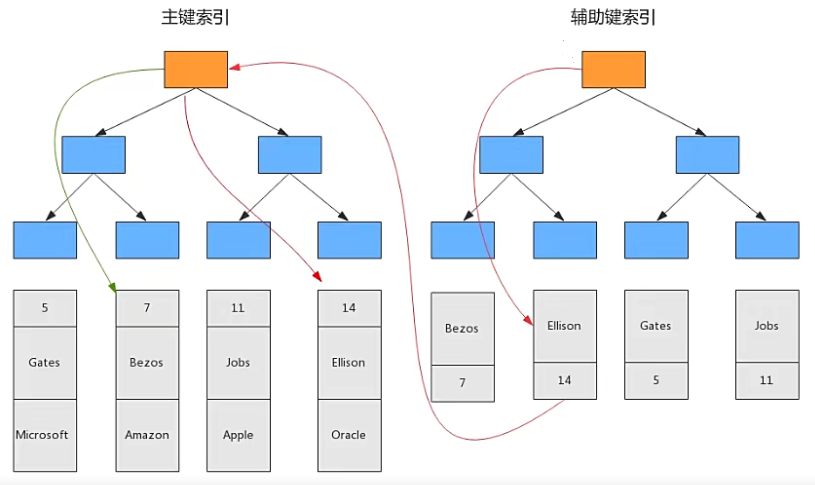
非聚簇索引
与InnoDB表存储不同,MyISAM数据表的索引文件和数据文件是分开的,被称为非聚簇索引结构。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









