






MongoDB 数据库简介、安装及使用
一.MongoDB是什么及其特点
-
MongoDB 是一个开源的、基于分布式的、面向文档存储的非关系型数据库。是非关系型数据库当中功能最丰富、最像关系数据库的。其主要特点如下:
-
查询丰富:MongoDB 最大的特点是支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
-
面向文档:文档就是存储在 MongoDB 中的一条记录,是一个由键值对组成的数据结构。
-
模式自由:MongoDB 每一个 Document 都包含了元数据信息,每个文档之间不强迫要求使用相同的格式,同时他们也支持各种索引。
-
高可用性:MongoDB 支持在复制集(Replica Set)通过异步复制达到故障转移,自动恢复,集群中主服务器崩溃停止服务和丢失数据,备份服务器通过选举获得大多数投票成为主节点,以此来实现高可用。
-
水平拓展:MongoDB 支持分片技术,它能够支持并行处理和水平扩展。
-
支持丰富:MongoDB 另外还提供了丰富的 BSON 数据类型,还有 MongoDB 的官方不同语言的 driver 支持(C/C++、C#、Java、Node.js、Perl、PHP、Python、Ruby、Scala)。
1. MongoDB 的优势
1、面向文档的存储:以 JSON 格式的文档保存数据。
2、 任何属性都可以建立索引。
3、 复制以及高可扩展性。
4、 自动分片。
5、 丰富的查询功能。
6、 快速的即时更新。
2.MongoDB 支持的常见数据类型
-
String:字符串。存储数据常用的数据类型。
-
Integer:整型数值。用于存储数值。
-
Boolean:布尔值。用于存储布尔值(真/假)。
-
Array:用于将数组或列表或多个值存储为一个键。
-
Date:日期时间。用 UNIX 时间格式来存储当前日期或时间。
-
Binary Data:二进制数据。用于存储二进制数据。
-
Code:代码类型。用于在文档中存储 JavaScript 代码。
-
Regular expression:正则表达式类型。用于存储正则表达式。
3.MongoDB 索引及其作用
-
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB 在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
-
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可能要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
-
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
常见索引
-
单字段索引(Single Field Indexes)
-
符合索引(Compound Indexes)
-
多键索引(Multikey Indexes)
-
全文索引(Text Indexes)
-
Hash 索引(Hash Indexes)
-
通配符索引(Wildcard Indexes)
4. MongoDB 适应的场景和不适用的场景
MongoDB 属于典型的非关系型数据库。
- 主要适应场景
1、网站实时数据:MongoDB 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
2、数据缓存:由于性能很高,MongoDB 也适合作为信息基础设施的缓存层。在系统重启之后,由 MongoDB 搭建的持久化缓存层可以避免下层的数据源过载。
3、高伸缩性场景:MongoDB 非常适合由数十或数百台服务器组成的数据库。
4、对象或 JSON 数据存储:MongoDB 的 BSON 数据格式非常适合文档化格式的存储及查询。
- 不适应场景
1、高度事务性系统:例如银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。
2、传统的商业智能应用:针对特定问题的 BI 数据库会对产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
3、需要复杂 SQL 查询的场景。
- MongoDB 中的库、集合、文档
1、库:MongoDB 可以建立多个数据库,MongoDB 默认数据库为"db"。MongoDB 的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
2、集合:MongoDB 集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库中的表格)。集合存在于数据库中,集合没有固定的结构。
3、文档:MongoDB 的 Document 是一组键值(key-value)对(即 BSON),相当于关系型数据库的行。且不需要设置相同的字段,并且相同的字段不需要相同的数据类型。
5.MongoDB 的复制过程
-
Primary 节点写入数据,Secondary 通过读取 Primary 的 oplog(即 Primary 的 oplog.rs 表)得到复制信息,开始复制数据并且将复制信息写入到自己的 oplog。如果某个操作失败,则备份节点停止从当前数据源复制数据。如果某个备份节点由于某些原因挂掉了,当重新启动后,就会自动从 oplog 的最后一个操作开始同步。同步完成后,将信息写入自己的 oplog,由于复制操作是先复制数据,复制完成后再写入 oplog,有可能相同的操作会同步两份,MongoDB 设定将 oplog 的同一个操作执行多次,与执行一次的效果是一样的。
-
当 Primary 节点完成数据操作后,Secondary 的数据同步过程如下:
-
检查自己 local 库的 oplog.rs 集合找出最近的时间戳。
-
检查 Primary 节点 local 库 oplog.rs 集合,找出大于此时间戳的记录。
-
将找到的记录插入到自己的 oplog.rs 集合中,并执行这些操作。
6.MongoDB 副本集及其特点
MongoDB 副本集是一组 Mongod 维护相同数据集的实例,副本集可以包含多个数据承载点和多个仲裁点。在承载数据的节点中,仅有一个节点被视为主节点,其他节点称为次节点。
主要特点:
-
N 个节点的集群,任何节点可作为主节点,由选举产生;
-
最小构成是:primary,secondary,arbiter,一般部署是:primary,2 secondary。
-
所有写入操作都在主节点上,同时具有自动故障转移,自动恢复;
-
成员数应该为奇数,如果为偶数的情况下添加 arbiter,arbiter 不保存数据,只投票。
MongoDB 复制(本)集原理
-
mongodb 的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
-
mongodb 各个节点常见的搭配方式为:一主一从、一主多从。
-
主节点记录在其上的所有操作 oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
MongoDB 有哪些特殊成员
MongoDB 中 Secondary 角色存在一些特殊的成员类型:
· Priority 0(优先级 0 型):不能升为主,可以用于多数据中心场景;
· Hidden(隐藏型):对客户端来说是不可见的,一般用作备份或统计报告用;
· Delayed(延迟型):数据比副集晚,一般用作 rolling backup 或历史快照。
· Vote(投票型):仅参与投票。
二.MongoDB 分片集群
MongoDB 分片集群(Sharded Cluster):主要利用分片技术,使数据分散存储到多个分片(Shard)上,来实现高可扩展性。
分片是将数据水平切分到不同的物理节点。当数据量越来越大时,单台机器有可能无法存储数据或读取写入吞吐量有所降低,利用分片技术可以添加更多的机器来应对数据量增加以及读写操作的要求。
1、MongoDB 分片集群相对副本集的优势
MongoDB 分片集群主要可以解决副本集如下的不足:
1、副本集所有的写入操作都位于主节点;
2、延迟的敏感数据会在主节点查询;
3、单个副本集限制在 12 个节点;
4、当请求量巨大时会出现内存不足;
5、本地磁盘不足;
6、垂直扩展价格昂贵。
2、MongoDB 分片集群的优势
MongoDB 分片集群主要有如下优势:
-
使用分片减少了每个分片需要处理的请求数:通过水平扩展,群集可以提高自己的存储容量。比如,当插入一条数据时,应用只需要访问存储这条数据的分片。
-
使用分片减少了每个分片存储的数据:分片的优势在于提供类似线性增长的架构,提高数据可用性,提高大型数据库查询服务器的性能。当 MongoDB 单点数据库服务器存储成为瓶颈、单点数据库服务器的性能成为瓶颈或需要部署大型应用以充分利用内存时,可以使用分片技术。
3、MongoDB 分片集群的架构组件
MongoDB 架构组件主要有:
-
Shard:用于存储实际的数据块,实际生产环境中一个 shard server 角色可由几台机器组成一个 replica set 承担,防止主机单点故障。
-
Config Server:mongod 实例,存储了整个 ClusterMetadata,其中包括 chunk 信息。
-
Query Routers:前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
4、MongoDB 分片集群和副本集群的区别
-
副本集不是为了提高读性能存在的,在进行 oplog 的时候,读操作是被阻塞的;
-
提高读取性能应该使用分片和索引,它的存在更多是作为数据冗余,备份。
5、MongoDB 的几种分片策略及其相互之间的差异
MongoDB 的数据划分是基于集合级别为标准,通过 shard key 来划分集合数据。
主要分片策略有如下三种:
1、 范围划分:**通过 shard key 值将数据集划分到不同的范围就称为基于范围划分。对于数值型的 shard key:可以虚构一条从负无穷到正无穷的直线(理解为 x 轴),每个 shard key 值都落在这条直线的某个点上,然后 MongoDB 把这条线划分为许多更小的没有重复的范围成为块(chunks),一个 chunk 就是某些最小值到最大值的范围。
2、散列划分:****MongoDB 计算每个字段的 hash 值,然后用这些 hash 值建立 chunks。基于散列值的数据分布有助于更均匀的数据分布,尤其是在 shard key 单调变化的数据集中。
3、自定义标签划分:****MongoDB 支持通过自定义标签标记分片的方式直接平衡数据分布策略,可以创建标签并且将它们与 shard key 值的范围进行关联,然后分配这些标签到各个分片上,最终平衡器转移带有标签标记的数据到对应的分片上,确保集群总是按标签描述的那样进行数据分布。标签是控制平衡器行为及集群中块分布的主要方法。
差异:
1、基于范围划分对于范围查询比较高效。假设在 shard key 上进行范围查询,查询路由很容易能够知道哪些块与这个范围重叠,然后把相关查询按照这个路线发送到仅仅包含这些 chunks 的分片。
2、基于范围划分很容易导致数据不均匀分布,这样会削弱分片集群的功能。
3、基于散列划分是以牺牲高效范围查询为代价,它能够均匀的分布数据,散列值能够保证数据随机分布到各个分片上。
6、MongoDB 分片集群采取什么方式确保数据分布的平衡
新加入的数据及服务器都会导致集群数据分布不平衡,MongoDB 采用两种方式确保数据分布的平衡:
拆分
- 拆分是一个后台进程,防止块变得太大。当一个块增长到指定块大小的时候,拆分进程就会块一分为二,整个拆分过程是高效的。不会涉及到数据的迁移等操作。
平衡
-
平衡器是一个后台进程,管理块的迁移。平衡器能够运行在集群任何的 mongd 实例上。当集群中数据分布不均匀时,平衡器就会将某个分片中比较多的块迁移到拥有块较少的分片中,直到数据分片平衡为止。
-
分片采用后台操作的方式管理着源分片和目标分片之间块的迁移。在迁移的过程中,源分片中的块会将所有文档发送到目标分片中,然后目标分片会获取并应用这些变化。最后,更新配置服务器上关于块位置元数据。
7、 MongoDB 备份及恢复方式
mongodb 备份恢复方式通常有以下三种:
1、文件快照方式:此方式相对简单,需要系统文件支持快照和 mongod 必须启用 journal。可以在任何时刻创建快照。恢复时,确保没有运行 mongod,执行快照恢复操作命令,然后启动 mongod 进程,mongod 将重放 journal 日志。
2、复制数据文件方式:直接拷贝数据目录下的一切文件,但是在拷贝过程中必须阻止数据文件发生更改。因此需要对数据库加锁,以防止数据写入。恢复时,确保 mongod 没有运行,清空数据目录,将备份的数据拷贝到数据目录下,然后启动 mongod。
3、使用 mongodump 和 mongorestore 方式:在 Mongodb 中我们使用 mongodump 命令来备份 MongoDB 数据。该命令可以导出所有数据到指定目录中。恢复时,使用 mongorestore 命令来恢复 MongoDB 数据。该命令可以从指定目录恢复相应数据。
三.MongoDB部署方案
1、上传压缩包并解压
tar zxvf mongodb-linux-x86_64-4.0.13.tgz
mv mongodb-linux-x86_64-4.0.13 mongodb #重命名
2、配置环境变量及配置文件
1.配置系统环境变量
vi /etc/profile
#mongodb
export PATH=$PATH:/opt/mongodb/bin #mongo安装路径

2 创建MongoDB数据存放文件夹和日志记录文件夹,为后面的配置文件使用
mkdir -p /data/db
mkdir -p /logs
3 创建MongoDB运行时使用的配置文件
cd /opt/mongodb/bin
vim /mongodb.conf
dbpath = /data/db #数据文件存放目录
logpath = /logs/mongodb.log #日志文件存放目录
port = 27017 #端口
fork = true #以守护程序的方式启用,即在后台运行
#auth=true #需要认证。如果放开注释,就必须创建MongoDB的账号,使用账号与密码才可远程访问,第一次安装建议注释
bind_ip=0.0.0.0 #允许远程访问,或者直接注释,127.0.0.1

3、启动mongodb
cd /opt/mongodb/bin
./mongod -f mongodb.conf #指定启动文件启动
netstat -nltp|grep mongod #查看服务

4、创建MongoDB的账号
cd /opt/mongodb/bin
./mongo #运行mongo命令
mongodb的用户分两种,一种是管理员,一种是普通用户。
管理员管理普通用户、普通用户管理数据库数据
先创建管理员
下面是db的命令行操作:
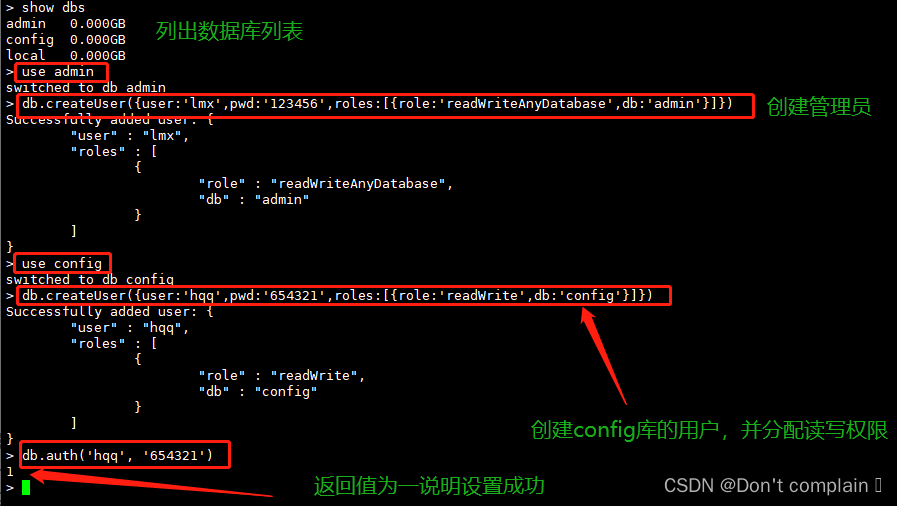
>show dbs(可以列出数据库列表,方便查看)
>use admin
>db.createUser({user:'lmx',pwd:'123456',roles:[{role:'readWriteAnyDatabase',db:'admin'}]})
创建指定数据库testdb的用户,并且分配权限
>use config (你要设置用户的数据库名称)
>db.createUser({user:'hqq',pwd:'654321',roles:[{role:'readWrite',db:'config'}]})
>db.auth('hqq', '654321')
#返回 1 ,则说明用户密码设置ok
用户创建成功后,ctrl+c退出shell进程
需要重新启动mongodb服务,使权限生效
cd /opt/mongodb/
bin/mongod --config /opt/mongodb/bin/mongodb.conf -shutdown #关掉服务
bin/mongod --config /opt/mongodb/bin/mongodb.conf -auth #开启权限认证服务,需要附加--auth

>use admin
>show collections #查看权限是否生效

5.Navicat 工具连接
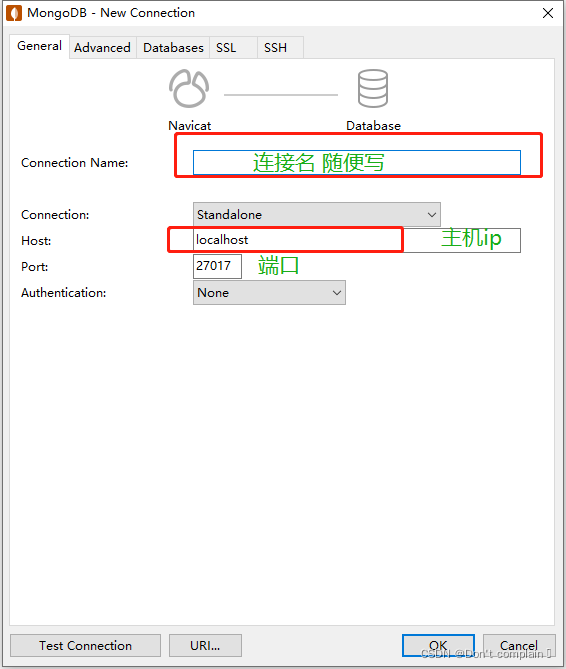
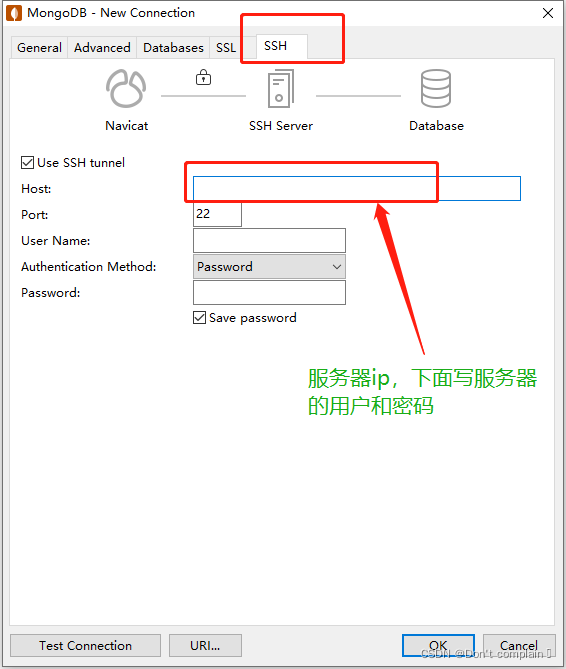
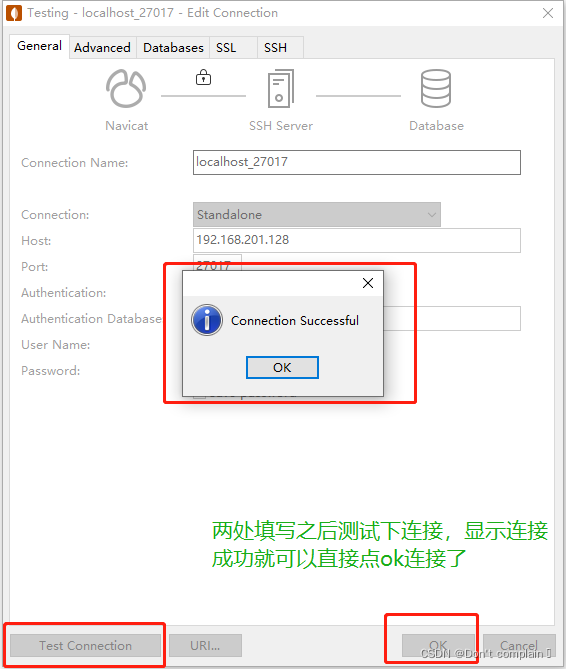














 5952
5952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









