






降维
数据降维:将原始数据映射到低维子空间,以达到降低维数的目的,但是这个过程中数据的特征发生了本质的变化,新的子空间的特征再是原来的特征,所以通常不容易赋予经过降维后的数据新特征的物理意义。解释出处
例如,你有一个包含身高和体重这两个个特征的数据集,每个样本代表一个人。你使用pca后保留一个主成分,假设第一主成分 = 0.6 * 身高 + 0.3 * 体重,这样就把一个二维数据,变为一维了(这就是降维了!!!)。给一个简单的示意图(代码一,在最后)。
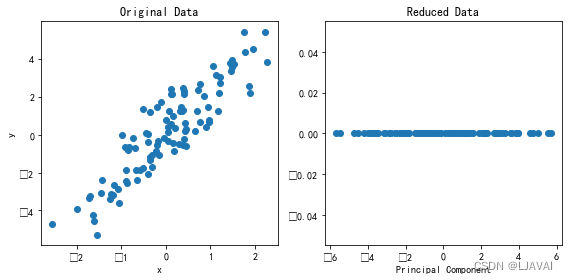
特征提取:提取重要的特征进行分析。
例如,你有一个语文,数学,英语,体育,音乐和地理六个特征的数据集,你觉得语文,数学和英语对成绩总分的影响大然后把它三个提取出来进行处理。
PCA属于是数据降维。
得出的主成分有什么作用呢?
第一主成分 = 0.6 * 身高 + 0.3 * 体重,例如这个,它没有什么意义,就是一个降维,但是你可以用它来判断一个人是否太重或太矮了。
例子
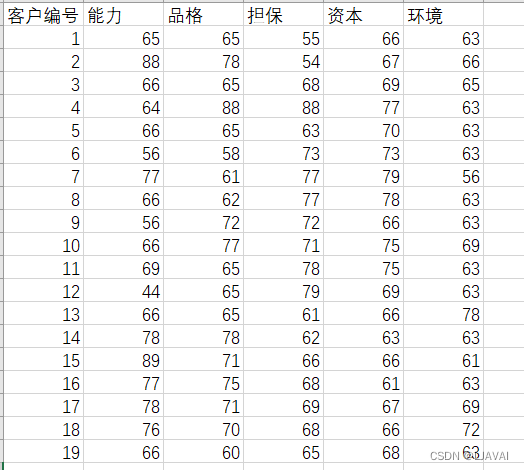
这是我造的一个例子,用以下代码读取
# 读取数据
file_path = r'C:\Users\27388\Desktop\测试数据.xlsx'
data = pd.read_excel(file_path)
data = data.drop("客户编号", axis=1)如果变量之间都是没有任何相关关系的,用pca是没有用的,例如男生性别和女生性别之间的关系,这是不相关的。所以用pca前先做相关性分析,下面画热力图。
# 计算相关系数矩阵
corr_matrix = data.corr()
# 绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm")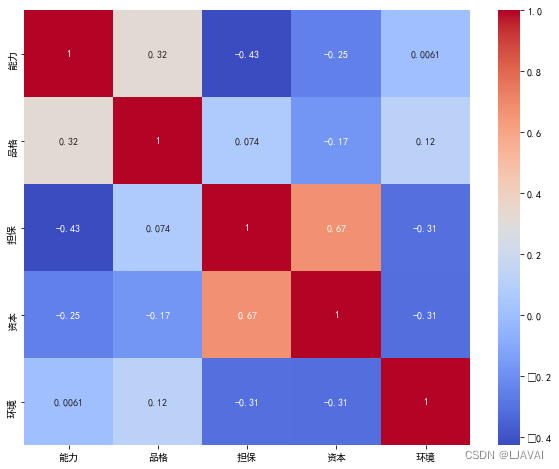
可以看出,资本和担保之间相关性还是相对较强的,所以我们进行下一步。
接着对数据进行标准化。
# 数据标准化
scaler = StandardScaler()
data_normalized = scaler.fit_transform(data)执行pca。
# 执行 PCA
pca = PCA() # 不设置 n_components 参数,默认保留所有主成分
pca.fit(data_normalized)查看每个主成分的贡献率,得到下图数据。
# 每个主成分的贡献率
er = pca.explained_variance_ratio_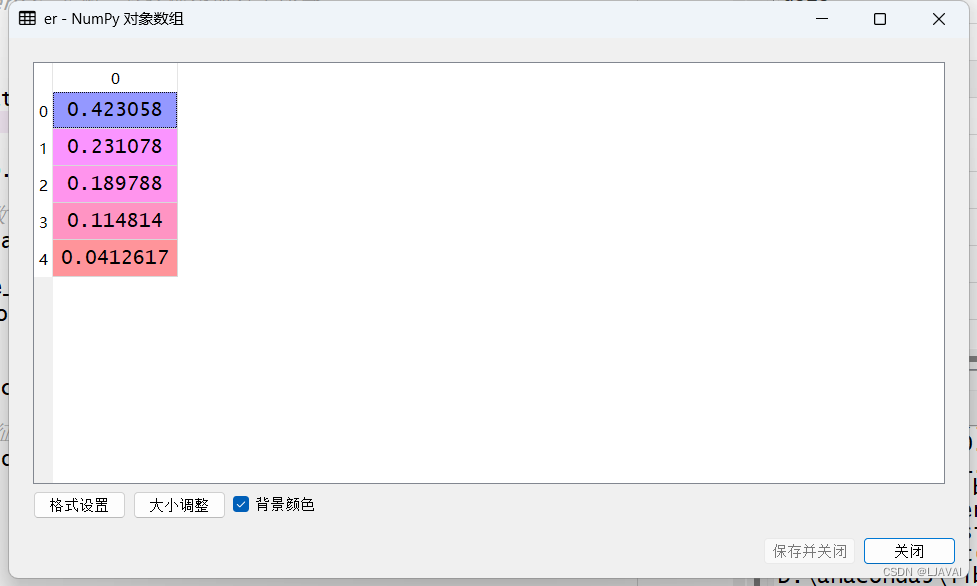
然后确定主成分个数,找到累积贡献率大于80的就好了。(累积贡献率就是上面各个主成分贡献相加)
# 找到累积贡献率达到80%的主成分个数
n_components = np.argmax(cumulative_variance_ratio >= 0.8) + 1
print("累积贡献率:", cumulative_variance_ratio)
print("选取主成分个数:", n_components)
然后输出对应主成分的特征变量,也就是第一主成分 = 0.6 * 身高 + 0.3 * 体重中的0.6和0.3这些是怎么来的。
# 输出对应主成分的特征向量
components = pd.DataFrame(pca.components_, columns=data.columns)
# 获取前n_components个主成分的特征向量
top_components = components.iloc[:n_components]
print("对应主成分的特征向量:")
print(top_components)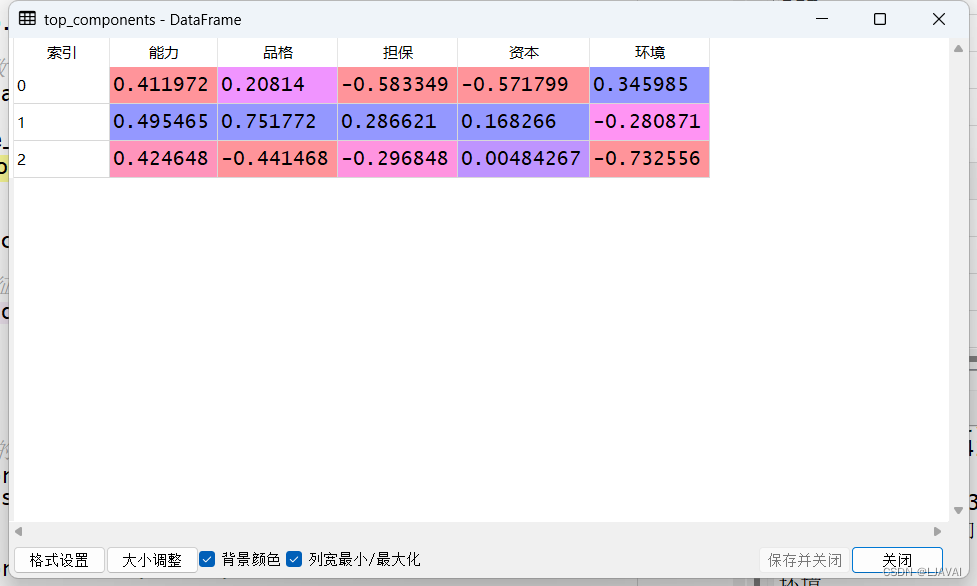
到这里就可以得到
第一主成分 = 0.41 *能力 + 0.20 * 品格 - 0.58 * 担保 - 0.57 * 资本 + 0.34 * 环境
这里看到,它居然有负数的权重,它并不代表负面影响,而是表示某个特征与其他特征之间存在反向关系。
然后我们查看每个人在主成分上的得分
# 使用PCA对数据进行降维 n_components是前面选的的
pca = PCA(n_components=n_components)
data_pca = pca.fit_transform(data_normalized)
# 将得分添加到原始数据
# 将每个主成分的得分添加到原始数据
for i in range(n_components):
data[f'主成分{i+1}得分'] = data_pca[:, i]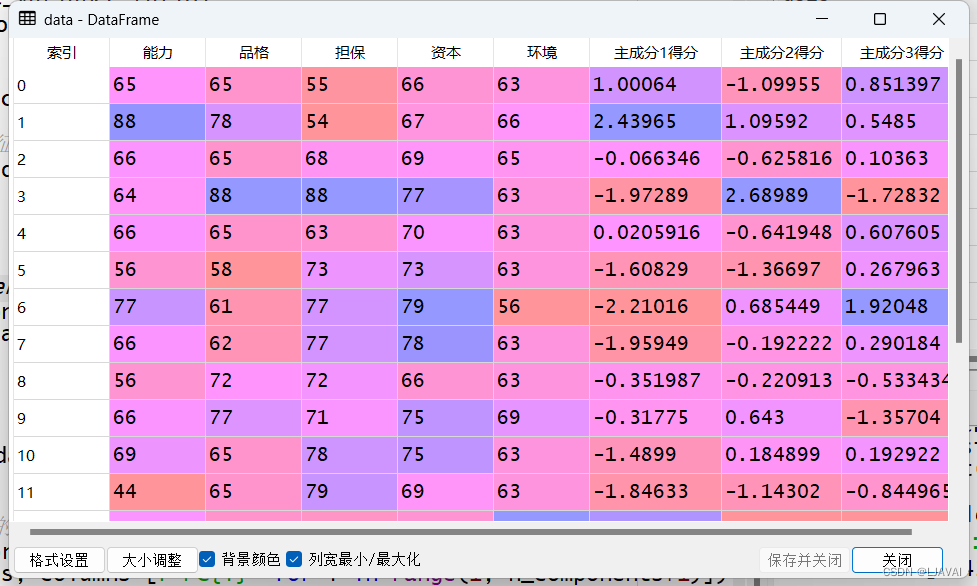
最后,我们就可以根据结果进行分析了,注意:主成分分析的结果并不一定总是清晰明确地指出哪些特征起到了主要作用。有时候,多个特征的权重可能接近,或者存在其他因素使得解释权重变得复杂。因此,在解释主成分分析的结果时,需要结合领域知识和其他分析方法来进行综合判断。
结果解释
因为我的数据是随便造的,所以结果可能有点问题,就不按照运行出来的结果解释了,下面给个类似的解释:
-
第一个主成分(PC1):该主成分具有较大的正权重与收入、教育程度和职业地位相关,而具有较大的负权重与年龄相关。这可能意味着PC1代表了一个人的社会经济地位,高收入、高教育程度和高职业地位的人在该主成分上得分较高,而年轻人在该主成分上得分较低。PC1的方差解释率为30%,说明它能解释原始数据方差的30%。
-
第二个主成分(PC2):该主成分具有较大的正权重与健康状况和生活方式相关,而具有较大的负权重与消费支出相关。这可能意味着PC2代表了一个人的生活质量,健康状况良好、有良好生活习惯的人在该主成分上得分较高,而高消费支出的人在该主成分上得分较低。PC2的方差解释率为20%,说明它能解释原始数据方差的20%。
-
第三个主成分(PC3):该主成分具有较大的正权重与兴趣爱好和社交活动相关,而具有较大的负权重与工作时间相关。这可能意味着PC3代表了一个人的个人兴趣和社交程度,对兴趣爱好和社交活动投入较多的人在该主成分上得分较高,而工作时间较长的人在该主成分上得分较低。PC3的方差解释率为15%,说明它能解释原始数据方差的15%。
综合分析这三个主成分的含义,可以初步得出结论:PC1代表社会经济地位,PC2代表生活质量,PC3代表个人兴趣和社交程度。
宇宙级免责声明: 仅作个人笔记,不能确保全部内容一定正确,如有错误欢迎指出。
参考文章
原理+代码|Python基于主成分分析的客户信贷评级实战(附代码与源数据)
数据降维(data dimension reduction)
运行代码
代码一
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 生成随机数据
np.random.seed(0)
n_samples = 100
x = np.random.randn(n_samples)
y = 2 * x + np.random.randn(n_samples)
# 创建数据集
data = np.array([x, y]).T
# 使用PCA进行降维
pca = PCA(n_components=1)
reduced_data = pca.fit_transform(data)
# 可视化原始数据和降维后的数据
plt.figure(figsize=(8, 4))
plt.subplot(121)
plt.scatter(data[:, 0], data[:, 1])
plt.xlabel('x')
plt.ylabel('y')
plt.title('Original Data')
plt.subplot(122)
plt.scatter(reduced_data, np.zeros_like(reduced_data))
plt.xlabel('Principal Component')
plt.title('Reduced Data')
plt.tight_layout()
plt.show()
例子代码
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import seaborn as sns
import matplotlib.pyplot as plt
# 用于中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
# 读取数据
file_path = r'C:\Users\27388\Desktop\测试数据.xlsx'
data = pd.read_excel(file_path)
data = data.drop("客户编号", axis=1)
# 大于0.7,才有做PCA的必要
#sns.heatmap(data.corr(), annot=True)
# 计算相关系数矩阵
corr_matrix = data.corr()
# 绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap="coolwarm")
# 数据标准化
scaler = StandardScaler()
data_normalized = scaler.fit_transform(data)
# 执行 PCA
pca = PCA() # 不设置 n_components 参数,默认保留所有主成分
pca.fit(data_normalized)
# 每个主成分的贡献率
er = pca.explained_variance_ratio_
# 计算累积贡献率
cumulative_variance_ratio = np.cumsum(pca.explained_variance_ratio_)
# 找到累积贡献率达到80%的主成分个数
n_components = np.argmax(cumulative_variance_ratio >= 0.8) + 1
print("累积贡献率:", cumulative_variance_ratio)
print("选取主成分个数:", n_components)
# 输出对应主成分的特征向量
components = pd.DataFrame(pca.components_, columns=data.columns)
# 获取前n_components个主成分的特征向量
top_components = components.iloc[:n_components]
print("对应主成分的特征向量:")
print(top_components)
# 使用PCA对数据进行降维 n_components是前面选的的
pca = PCA(n_components=n_components)
data_pca = pca.fit_transform(data_normalized)
# 将得分添加到原始数据
# 将每个主成分的得分添加到原始数据
for i in range(n_components):
data[f'主成分{i+1}得分'] = data_pca[:, i]
# 获取前n_components个主成分对应的得分
scores = pca.transform(data_normalized)[:, :n_components]
scores_df = pd.DataFrame(scores, columns=[f'PC{i}' for i in range(1, n_components+1)])
# 获取总分
scores_df['Total Score'] = scores_df.sum(axis=1)
print("主成分得分:")
print(scores_df)
















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









