







一、引言
Elasticsearch可以扩展到上百(甚至上千) 的服务器来处理PB级的数据 ,Elasticsearch为分布式而生, 而且它的设计隐藏了分布式本身的复杂性 :
- 将你的文档分区到不同的容器或者分片(shards)中, 它们可以存在于一个或多个节点中。
- 将分片均匀的分配到各个节点, 对索引和搜索做负载均衡。
- 冗余每一个分片, 防止硬件故障造成的数据丢失。
- 将集群中任意一个节点上的请求路由到相应数据所在的节点。
- 无论是增加节点, 还是移除节点, 分片都可以做到无缝的扩展和迁移
二、Node
一个节点(node)就是一个Elasticsearch实例,而一个集群(cluster)由一个或多个节点组成, 它们具有相同的 cluster.name ,它们协同工作, 分享数据和负载。 当加入新的节点或者删除一个节点时, 集群就会感知到并平衡数据
集群中一个节点会被选举为主节点(master),它将临时管理集群级别的一些变更, 例如新建或删除索引、 增加或移除节点等。主节点不参与文档级别的变更或搜索, 这意味着在流量增长的时候, 该主节点不会成为集群的瓶颈。 任何节点都可以成为主节点。
做为用户, 我们能够与集群中的任何节点通信, 包括主节点。 每一个节点都知道文档存在于哪个节点上, 它们可以转发请求到相应的节点上。 我们访问的节点负责收集各节点返回的数据, 最后一起返回给客户端。 这一切都由Elasticsearch处理
三、分片(shard)
-
分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分
-
分片就是一个Lucene实例, 并且它本身就是一个完整的搜索引擎
-
文档存储在分片中, 并且在分片中被索引, 但是我们的应用程序不会直接与它们通信, 取而代之的是, 直接与索引通信
-
分片是Elasticsearch在集群中分发数据的关键。 把分片想象成数据的容器。 文档存储在分片中, 然后分片分配到你集群中的节点上。 当你的集群扩容或缩小, Elasticsearch将会自动在你的节点间迁移分片, 以使集群保持平衡
-
每个文档属于一个单独的主分片, 所以主分片的数量决定了索引最多能存储多少数据,分片的最大容量完全取决于你的使用状况: 硬件存储的大小、 文档的大小和复杂度、 如何索引和查询你的文档, 以及你期望的响应时间
-
索引创建完成的时候, 主分片的数量就固定了, 但是复制分片的数量可以随时调整
-
主要分片(primary shard)和复制分片(replica shard)
复制分片只是主分片的一个副本, 它可以防止硬件故障导致的数据丢失, 同时可以提供读请求, 比如搜索或者别的shard取回文档
PUT /blogs
{
"settings" : {
"number_of_shards" : 3, //设置主分片数量
"number_of_replicas" : 1 //设置副本分片数量
}
}
四、集群健康
集群健康有三种状态:
- green 所有主要分片和复制分片都可用
- yellow 所有主要分片可用, 但不是所有复制分片都可用
- red 不是所有的主要分片都可用
GET /_cluster/health
返回信息
{
"cluster_name": "elasticsearch",
"status": "yellow", <1>
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3 <2>
}
五、集群
单节点与分片

三个主分片都被分配到 Node 1 ,检查集群状态发现是"yellow",这是因为复制分片还没有节点分配,主要分片和复制分片不能存在同一Node上,因为如果这样分配,就不能进行数据冗余。
双节点与分片

第二个节点加入集群, 三个复制分片(replica shards)也已经被分配了——分别对应三个主分片, 这意味着在丢失任意一个节点的情况下依旧可以保证数据的完整性
cluster-health 现在的状态是 green , 这意味着所有的6个分片(三个主分片和三个复制分片) 都已可用
三节点与分片

从 Node 1 和 Node 2 来的分片已经被移动到新的 Node 3 上, 这样每个节点就有两个分片, 以代替之前的三个。 这意味着每个节点的硬件资源(CPU、 RAM、 I/O) 被较少的分片共享, 这样每个分片就会有更好的表现
分片本身就是一个完整成熟的搜索引擎, 它可以使用单一节点的所有资源。 使用这6个分片(3个主分片和三个复制分片) 我们可以扩展最多到6个节点, 每个节点上有一个分片, 这样就可以100%使用这个节点的资源了
更多扩展
我们可以让Node数量大于6吗?
主分片的数量在创建索引时已经给定 ,不可更改,这时我们可以增加复制分片的数量,让replica shard数量变为2
PUT /blogs/_settings
{
"number_of_replicas" : 2
}

blogs 索引现在有9个分片: 三个主分片和6个复制分片。 这意味着我们能够扩展到9个节点, 再次的变成每个节点一个分片。 这样使我们的搜索性能相比标准的三节点集群扩展三倍
注意:
- 集群扩容或者缩小,ElasticSerach会自动在节点间进行分片迁移,以使集群保持平衡
- 理论上主分片能存储的数据大小是没有限制的, 限制取决于你实际的使用情况。 分片的最大容量完全取决于你的使用状况: 硬件存储的大小、 文档的大小和复杂度、 如何索引和查询你的文档, 以及你期望的响应时间
- 更多的复制分片在同样数量的节点上并不能提高我们的性能, 因为每个分片都要访问更小比重的节点资源,需要增加硬件来提高吞吐量
六、集群容错
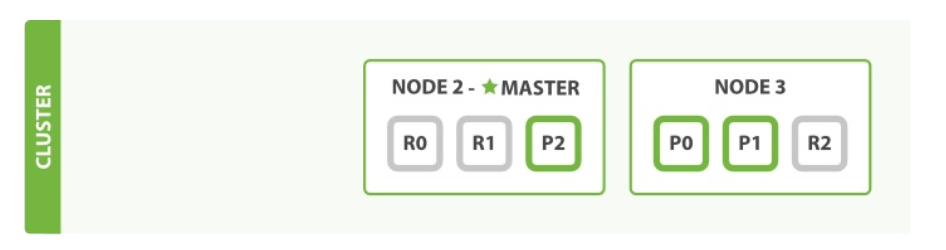
假设集群Node1宕机,必须有一个主节点来让集群的功能可用,就会在Node2和Node3中选举一个新的主节点,主分片P1,P2,R0分片丢失,但是其他另外两个节点依然保留完整数据,同时在剩下两个节点的复制分片中选举新的primary shard
整个过程瞬间完成,集群依然可以正常对外提供服务,此时集群还可以容忍一个节点宕机,也就是说3个primary shard,6个replica shard,3个Node,最多可以容忍两个节点的宕机。如果这里的repilca shard为3个,最多容忍1个节点宕机,可见副本数和节点的数量决定了集群容错的上限















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









