






Introduction
在这个实验中,将为你的操作系统写内存管理代码。内存管理有两个部分。
第一个组件是内核的物理内存分配器,以便内核可以分配内存并在以后释放它。您的分配器将以 4096 字节为单位操作,称为页面。您的任务是维护记录哪些物理页面是空闲的、哪些已分配以及有多少个进程共享每个已分配页面的数据结构。您还将编写用于分配和释放内存页面的例程。
内存管理的第二个组件是虚拟内存,它将内核和用户软件使用的虚拟地址映射到物理内存中的地址。x86 硬件的内存管理单元(MMU)在指令使用内存时执行映射,查询一组页表。您将修改 JOS 以根据我们提供的规范设置 MMU 的页表。
Getting started
在这个实验和未来的实验中,您将逐步构建您的内核。我们还将提供一些额外的源代码。要获取该源代码,请使用 Git 提交您在上交实验 1 以来所做的更改(如果有的话),获取课程存储库的最新版本,然后基于我们的 lab2 分支 origin/lab2 创建一个名为 lab2 的本地分支:
athena%cd ~/6.828/lab
athena%add git
athena%git pull
Already up-to-date.
athena%git checkout -b lab2 origin/lab2
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
Switched to a new branch "lab2"
athena%
上面显示的 git checkout -b 命令实际上执行两个操作:首先,它创建一个名为 lab2 的本地分支,该分支基于课程工作人员提供的 origin/lab2 分支;其次,它更改您的实验目录的内容,以反映存储在 lab2 分支上的文件。Git 允许使用 git checkout branch-name 在现有分支之间进行切换,尽管在切换到另一个分支之前,应该提交任何未完成的更改
现在您需要将在 lab1 分支中所做的更改合并到 lab2 分支中,步骤如下:
athena%git merge lab1
Merge made by recursive.
kern/kdebug.c | 11 +++++++++--
kern/monitor.c | 19 +++++++++++++++++++
lib/printfmt.c | 7 +++----
3 files changed, 31 insertions(+), 6 deletions(-)
athena%
在某些情况下,Git 可能无法确定如何将您的更改与新的实验任务合并(例如,如果您修改了第二个实验任务中已更改的某些代码)。在这种情况下,git merge 命令会告诉您哪些文件存在冲突,您应首先解决冲突(通过编辑相关文件),然后使用 git commit -a 提交结果文件。
实验 2 包含以下新的源文件,您应该浏览一下:
- inc/memlayout.h
- kern/pmap.c
- kern/pmap.h
- kern/kclock.h
- kern/kclock.c
memlayout.h 描述了虚拟地址空间的布局,您需要通过修改 pmap.c 文件来实现该布局。memlayout.h 和 pmap.h 定义了 PageInfo 结构,您将使用它来跟踪哪些物理内存页面是空闲的。kclock.c 和 kclock.h 用于操作 PC 的备份电池时钟和 CMOS RAM 硬件,在其中 BIOS 记录了 PC 包含的物理内存量等信息。pmap.c 中的代码需要读取此设备硬件以确定物理内存的大小,但这部分代码已经为您完成,您无需了解 CMOS 硬件的工作原理的细节。
在本实验中,特别要注意 memlayout.h 和 pmap.h,因为它们包含了许多您需要使用和理解的定义。您可能还想复习一下 inc/mmu.h,因为它也包含了一些对本实验有用的定义。
在开始实验之前,不要忘记添加 -f 6.828 以获取 6.828 版本的 QEMU。
Lab Requirements
在本实验和随后的实验中,完成实验中描述的所有常规练习,并至少完成一个挑战问题。(当然,有些挑战问题比其他问题更具挑战性!)此外,对实验中提出的问题撰写简要答案,并简要描述您解决所选择的挑战问题的过程(例如,一两段文字)。如果您实现了多个挑战问题,您只需要在写作中描述其中一个,当然,您也可以描述更多。在提交实验前,将写作内容保存在名为 answers-lab2.txt 的文件中,放置在实验目录的顶层位置。
Part 1: Physical Page Management
操作系统必须跟踪物理 RAM 的哪些部分是空闲的,哪些是当前正在使用的。JOS 使用页面粒度(*page granularity)*来管理 PC 的物理内存,以便可以使用内存管理单元(MMU)来映射和保护每个已分配内存的部分。
现在您将编写物理页面分配器。它通过 struct PageInfo 对象的链表来跟踪哪些页面是空闲的(与 xv6 不同,这些对象并不嵌入在自由页面中),每个对象对应一个物理页面。在编写虚拟内存实现的其余部分之前,您需要先编写物理页面分配器,因为您的页表管理代码将需要分配物理内存来存储页表。
Exercise 1.
在文件 kern/pmap.c 中,您需要实现以下函数的代码(可能按照给定的顺序):
- boot_alloc()
- mem_init()(仅限于调用 check_page_free_list(1))
- page_init()
- page_alloc()
- page_free()
check_page_free_list() 和 check_page_alloc() 用于测试您的物理页面分配器。您应该启动 JOS 并查看 check_page_alloc() 是否报告成功。修改代码以使其通过测试。您可能会发现添加自己的 assert() 来验证您的假设是否正确是有帮助的。
size_t npages; // 物理内存总页数
static size_t npages_basemem; // 基本内存(base memory)的页数
// 这些变量在 mem_init() 函数中被设置
pde_t *kern_pgdir; // 内核的初始页目录
struct PageInfo *pages; // 物理页状态数组
static struct PageInfo *page_free_list; // 空闲物理页的链表
boot_alloc( )函数
static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // 下一个空闲内存字节的地址
char *result;
// 如果这是第一次,则初始化 nextfree。
// 'end' 是链接器自动生成的一个神奇符号,
// 它指向内核的 bss 段的末尾:
// 链接器未分配给任何内核代码或全局变量的第一个虚拟地址。
if (!nextfree) {//检查是否被初始化,如果尚未初始化(即为 NULL 或零值),则执行以下代码块
extern char end[];
nextfree = ROUNDUP((char *) end, PGSIZE);
}
// 分配一个足够大以容纳 'n' 字节的块,然后更新 nextfree。
// 确保 nextfree 保持对 PGSIZE 的倍数对齐。
//
// LAB 2: 在此处编写您的代码。
if (n == 0) {
return nextfree;
}
result = nextfree;
nextfree += ROUNDUP(n, PGSIZE);//用 PGSIZE 为大小的页面聚集 n 个byte
return result;
}
//PGSIZE是一个物理页面的大小 4KB=4096B
//如果分配的n不是0,那么就意味着有分配内容,就要 用 PGSIZE 为大小的页面聚集 n 个byte。那么下一个空闲页面(nextfree)就是 从当前开始算起加上 分配的页面之后的页面序号。
n是分配n个byte,意思就是现在要分配n个byte,占用n个byte
end是指向内核的 bss 段的末尾的一个指针
进入 $ROOT/obj/kern 目录,键入objdump -h kernel,查看文件结构可以发现,bss已经位于内核最终,所以,end是向内核的 bss 段的末尾的一个指针,也就是第一个未使用的虚拟内存地址。
-
内核空间
操作系统在运行时所使用的内存空间部分
-
示意图
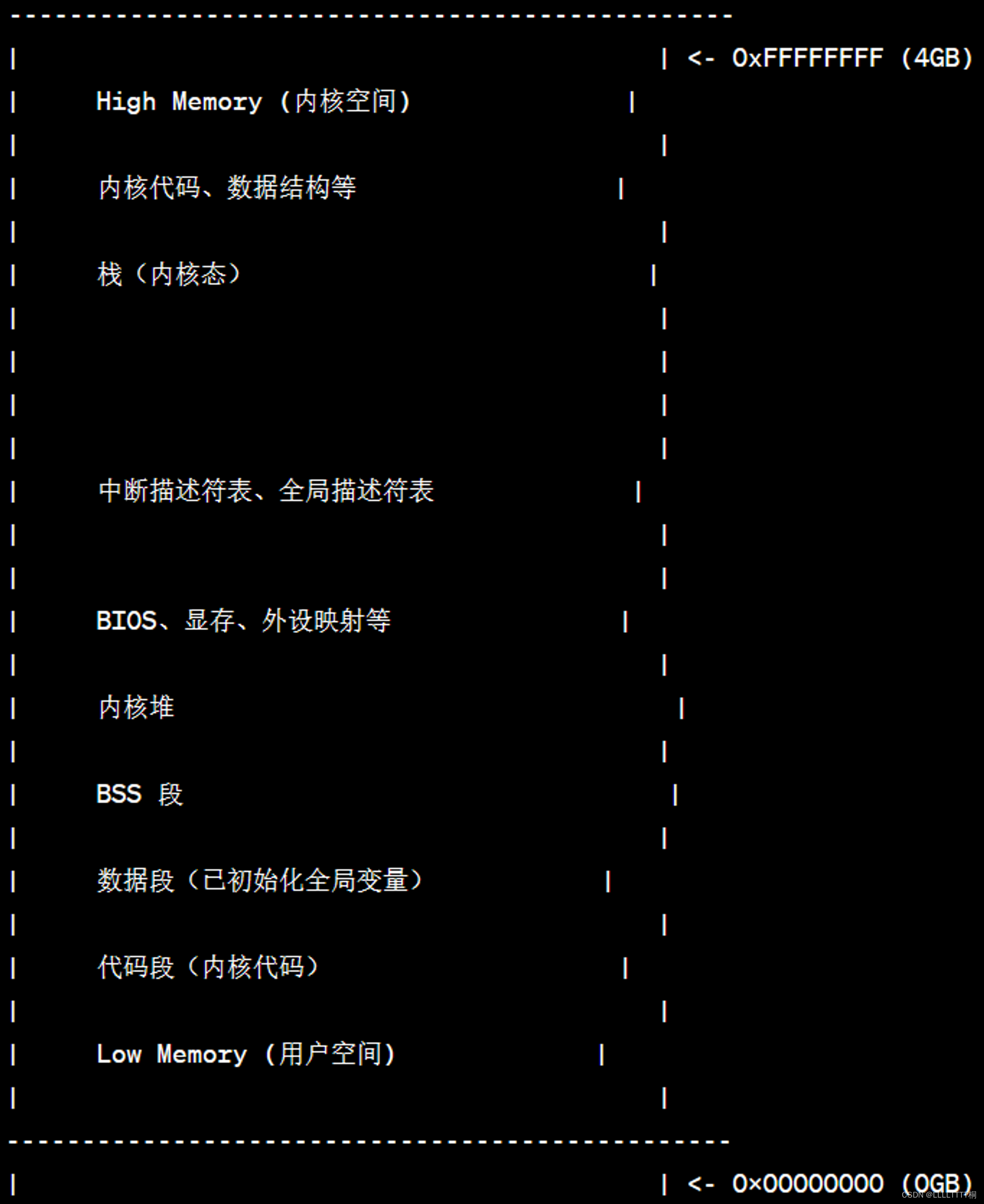
内核空间通常包含以下各部分,每个部分存放着不同类型的数据或功能:
- 代码段(Kernel Code Segment):
- 存放操作系统内核的实际代码。这些代码包括处理器架构相关的底层代码、系统调用处理程序、中断服务例程等。
- 数据段(Initialized Global Variables):
- 存放已经初始化的全局或静态变量,这些变量在编译时已经被初始化为特定的值。例如,全局的静态数据结构、常量等。
- BSS 段:
- 存放未初始化的全局或静态变量。这些变量在编译时并没有被初始化,但在程序启动时会被清零或设为默认值。这个段实际上不存储任何数据,只是为了表示一段需要在运行时清零的内存空间。
- 内核堆(Kernel Heap):
- 动态分配的内存空间,用于操作系统运行时动态管理的数据结构或对象。这包括进程控制块(PCB)、内存分配器所使用的数据结构等。
- BIOS、显存、外设映射等:
- 包含 BIOS、显存、外设映射区域等一些与硬件相关的内存区域。这些区域是操作系统与硬件进行通信和交互的重要部分。
- 中断描述符表、全局描述符表:
- 中断描述符表(Interrupt Descriptor Table)和全局描述符表(Global Descriptor Table)包含了操作系统在处理中断、异常和系统调用时所需的描述符和处理程序的信息。
- 栈(Kernel Stack):
- 内核态下的栈空间,用于存储操作系统执行过程中的函数调用、局部变量和参数等。每个内核态的执行上下文都有自己的栈空间。
以上这些部分共同构成了内核空间,提供了操作系统运行所需的代码、数据结构、堆内存管理、硬件交互等各种功能。
-
ROUNDUP宏。
进入 $ROOT/inc 目录下的 types.h 可以看到ROUNDUP的原定义。
// Round up to the nearest multiple of n
#define ROUNDUP(a, n) \\
({ \\
uint32_t __n = (uint32_t) (n); \\
(typeof(a)) (ROUNDDOWN((uint32_t) (a) + __n - 1, __n)); \\
})
定义为:用多个大小为PGSIZE的页面聚集最近的n个Byte。(Round up to the nearest multiple of n)
boot_alloc 函数的主要作用是分配物理内存,并确保分配的内存块是按页面对齐的
mem_init ( )函数
// 设置一个两级页表:
// kern_pgdir 是它的线性(虚拟)地址的根
//
// 此函数仅设置地址空间的内核部分
// (即地址 >= UTOP)。用户部分的地址空间
// 将稍后设置。
//
// 从 UTOP 到 ULIM,用户被允许读取但不允许写入。
// 超过 ULIM 的部分,用户既不能读取也不能写入。
void
mem_init(void)
{
uint32_t cr0;
size_t n;
// Find out how much memory the machine has (npages & npages_basemem).
//使用 i386_detect_memory() 函数检测系统的物理内存大小。
i386_detect_memory();
// Remove this line when you're ready to test this function.
panic("mem_init: This function is not finished\\n");
//
// create initial page directory.
//使用 boot_alloc(PGSIZE) 分配了一页大小(PGSIZE)的内存空间,用于存放页目录
//将分配的内存空间进行清零操作,即使用 memset 函数将这一页的内容全部设置为 0
kern_pgdir = (pde_t *) boot_alloc(PGSIZE);
memset(kern_pgdir, 0, PGSIZE);
//
// Recursively insert PD in itself as a page table, to form
// a virtual page table at virtual address UVPT.
// (For now, you don't have understand the greater purpose of the
// following line.)
// Permissions: kernel R, user R
kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;
//
// Allocate an array of npages 'struct PageInfo's and store it in 'pages'.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. 'npages' is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
// 分配一个包含 npages 个 'struct PageInfo' 结构体的数组,并将其存储在 'pages' 中。
// 内核使用这个数组来跟踪物理页面:对于每个物理页面,这个数组中都有一个对应的 struct PageInfo 结构体。
// 'npages' 是内存中物理页面的数量。使用 memset 来将每个 struct PageInfo 的所有字段初始化为 0。
// Your code goes here:
pages = (struct PageInfo *) boot_alloc(npages*sizeof(struct PageInfo));
memset(pages, 0, npages*sizeof(struct PageInfo));
//
// Now that we've allocated the initial kernel data structures, we set
// up the list of free physical pages. Once we've done so, all further
// memory management will go through the page_* functions. In
// particular, we can now map memory using boot_map_region
// or page_insert
// 现在我们已经分配了初始的内核数据结构,我们设置了空闲物理页面的列表。一旦完成这一步,所有后续的内存管理都将通过 page_* 函数进行。
//特别是,我们现在可以使用 boot_map_region 或 page_insert 来映射内存。
//page_init():初始化空闲页面列表。这个函数的目的是设置空闲页面列表,以便进行后续的内存管理。它可能会分配、标记或初始化空闲页面,以便内核可以使用它们来进行内存分配。
//check_page_free_list(1):进行空闲页面列表的检查。参数 1 可能指示该函数进行某种类型的检查,以确保空闲页面列表在初始化后是有效的。
//check_page_alloc() 和 check_page():这些函数可能会进行其他的内存页管理检查,以确保内存分配和页表管理等功能正常工作。
page_init();
check_page_free_list(1);
check_page_alloc();
check_page();
//
// Now we set up virtual memory
//
// Map 'pages' read-only by the user at linear address UPAGES
// Permissions:
// - the new image at UPAGES -- kernel R, user R
// (ie. perm = PTE_U | PTE_P)
// - pages itself -- kernel RW, user NONE
// Your code goes here:
//
// Use the physical memory that 'bootstack' refers to as the kernel
// stack. The kernel stack grows down from virtual address KSTACKTOP.
// We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP)
// to be the kernel stack, but break this into two pieces:
// * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory
// * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if
// the kernel overflows its stack, it will fault rather than
// overwrite memory. Known as a "guard page".
// Permissions: kernel RW, user NONE
// Your code goes here:
//
// Map all of physical memory at KERNBASE.
// Ie. the VA range [KERNBASE, 2^32) should map to
// the PA range [0, 2^32 - KERNBASE)
// We might not have 2^32 - KERNBASE bytes of physical memory, but
// we just set up the mapping anyway.
// Permissions: kernel RW, user NONE
// Your code goes here:
// Check that the initial page directory has been set up correctly.
check_kern_pgdir();
// Switch from the minimal entry page directory to the full kern_pgdir
// page table we just created. Our instruction pointer should be
// somewhere between KERNBASE and KERNBASE+4MB right now, which is
// mapped the same way by both page tables.
//
// If the machine reboots at this point, you've probably set up your
// kern_pgdir wrong.
lcr3(PADDR(kern_pgdir));
check_page_free_list(0);
// entry.S set the really important flags in cr0 (including enabling
// paging). Here we configure the rest of the flags that we care about.
cr0 = rcr0();
cr0 |= CR0_PE|CR0_PG|CR0_AM|CR0_WP|CR0_NE|CR0_MP;
cr0 &= ~(CR0_TS|CR0_EM);
lcr0(cr0);
// Some more checks, only possible after kern_pgdir is installed.
check_page_installed_pgdir();
}
PageInfo 结构
进入 $ROOT/inc/memlayout.h 中可以看到PageInfo的定义:
struct PageInfo {
// Next page on the free list.
struct PageInfo *pp_link;// pp_ref is the count of pointers (usually in page table entries)
// to this page, for pages allocated using page_alloc.
// Pages allocated at boot time using pmap.c's
// boot_alloc do not have valid reference count fields.
uint16_t pp_ref;
};
这个 PageInfo 中包括了两个变量:
pp_link:指向下一个空闲的页。
pp_ref:这是指向该页的指针数量。在启动时间时,Pages没有合法的指针,即指针为NULL。
初始化分配首页
// create initial page directory.
kern_pgdir = (pde_t *) boot_alloc(PGSIZE);
memset(kern_pgdir, 0, PGSIZE);
文段头部写到,kern_pgdir 是虚拟地址的首部,那么在 kern_pgdir 作为页表头部的指针进行首页的分配。
分配npages大小的数组
分配数组大小为 npages,数据单元是 PageInfo,那么所占用空间就是 : npages*sizeof(struct PageInfo)
将分配完的数据指针放入pages变量中,可以模仿1.2.2 中初始化分配首页的步骤来写下面的代码:
// Allocate an array of npages 'struct PageInfo's and store it in 'pages'.
// The kernel uses this array to keep track of physical pages: for
// each physical page, there is a corresponding struct PageInfo in this
// array. 'npages' is the number of physical pages in memory. Use memset
// to initialize all fields of each struct PageInfo to 0.
// 分配一个包含 npages 个 'struct PageInfo' 结构体的数组,并将其存储在 'pages' 中。
// 内核使用这个数组来跟踪物理页面:对于每个物理页面,这个数组中都有一个对应的 struct PageInfo 结构体。
// 'npages' 是内存中物理页面的数量。使用 memset 来将每个 struct PageInfo 的所有字段初始化为 0。
// Your code goes here:
pages = (struct PageInfo *) boot_alloc(npages*sizeof(struct PageInfo));
memset(pages, 0, npages*sizeof(struct PageInfo));
only up to the call to check_page_free_list(1),所以我就不往下分析了先。
page_init( )函数
// Initialize page structure and memory free list.
// After this is done, NEVER use boot_alloc again. ONLY use the page
// allocator functions below to allocate and deallocate physical
// memory via the page_free_list.
//
void
page_init(void)
{
size_t i;
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
pages[0].pp_ref = 1;
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
for (i = 1; i < npages_basemem; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
for (i = IOPHYSMEM/PGSIZE; i < EXTPHYSMEM/PGSIZE; i++) {
pages[i].pp_ref = 1;
}
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
//
size_t first_free_physical_address = PADDR(boot_alloc(0));
for (i = EXTPHYSMEM/PGSIZE; i < first_free_physical_address/PGSIZE; i++) {
pages[i].pp_ref = 1;
}
for (i = first_free_physical_address/PGSIZE; i < npages; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
初始化页表结构和空闲页的链表。
这个函数中已经写好的代码片段是假设所有的物理页面都为空的情况,当然这在实际中是不可能的。
所以要初始化空闲页的链表的话就要明确哪些内存是空闲的。
步骤如下:
1)给0页面标记为正在使用的状态。
2)剩下的基础内存是空闲的。
3)IO洞 不能被分配。
4)扩展内存有些被用,有些空闲 看完了这四句话整个人都不好了,第一句第二句还知道什么意思,剩下的是什么意思呢?
给初始页面标记为正在使用状态
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
pages[0].pp_ref = 1;
pp_ref:这是指向该页的指针数量。 刚开始的时候如果被占用的页面所拥有的指针数量是1,那么模仿下面已存在的代码可以得到以上的这段代码,将指针数量标记为1即可。
剩下的基础内存是空闲的
什么叫基础内存,大概意思就是在头上有一部分空着的吧。所以直接复制下面的那段代码稍作修改就可以了。
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
for (i = 1; i < npages_basemem; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
//npages_basemem 则是基本内存区域中页面的数量
//static struct PageInfo *page_free_list; // Free list of physical pages
//pages[i].pp_ref = 0;:将该页面的引用计数(pp_ref)设置为 0。引用计数是用于跟踪页面被引用的次数的计数器。
//pages[i].pp_link = page_free_list;:将当前页面的 pp_link 指针指向当前的 page_free_list,这样将该页面插入到空闲页面链表的头部。
//page_free_list = &pages[i];:更新 page_free_list 指向新插入的页面,使得该页面成为新的空闲页面链表的头部。
IO洞 不能被分配
IO洞是个什么意思?
注释中写道是从IOPHYSMEM到EXTPHYSMEM之间的空间就是IO hole。
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
for (i = IOPHYSMEM/PGSIZE; i < EXTPHYSMEM/PGSIZE; i++) {
pages[i].pp_ref = 1;
}
IO洞后有些被用,有些空闲
首先,如果需要物理地址转虚拟地址可以通过 KADDR(physical_address),反之用PADDR(virtual_address)。
其次,梳理一下上面的几条,页面中第一个页是被占用的,不可被使用的
从第二个页面到Base页结束是可被使用的,其后,IO洞里面的页不可被使用
再随后,也就是文中提到的扩展内存之后,有些可以被用,有些空闲,这就取决于被用和不可被用的临界点在哪里。
那么我们想到了可被使用的第一个页面的位置可以用 boot_alloc() 函数查询到,如果说想找到第一个页面的位置把参数写0就可以了。
在这种特殊情况下,如果您想要获取可用的第一个页面的位置,可以通过 boot_alloc(0) 来实现。这是因为 boot_alloc 函数在内部对于参数为 0 时有特殊处理。原理是这样的:
当 boot_alloc 函数的参数 n 为 0 时,它并不会执行实际的内存分配操作。相反,它仅仅返回当前可用的下一个空闲内存地址(或者也可以理解为指向下一个可用内存块的指针)。在函数内部,如果参数 n 为 0,它会返回 nextfree 这个指针,该指针指向了下一个可用内存块的虚拟地址。
这样,当您调用 boot_alloc(0) 时,实际上只是获取了下一个可用的内存块的虚拟地址,并没有分配实际的内存块。这个虚拟地址表示内存的起始位置,可以被用于标识某些特定内存区域的起点,比如第一个可用的页面。
所以,通过 boot_alloc(0) 可以获得下一个可用内存块的地址,如果将参数设置为 0,就能够获取可被使用的第一个页面的位置。
在这里boot_alloc()获取的是第一个可用的虚拟地址,那么需要把它转换为物理地址,用到了PADDR这个宏。
所以,意思就是从 EXTPHYSMEM 到 PADDR(boot_alloc(0)) 都不可使用,以后可以使用。
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
//
size_t first_free_physical_address = PADDR(boot_alloc(0));
for (i = EXTPHYSMEM/PGSIZE; i < first_free_physical_address/PGSIZE; i++) {
pages[i].pp_ref = 1;
}
for (i = first_free_physical_address/PGSIZE; i < npages; i++) {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
page_alloc( )函数
先看注释,该函数是分配物理页面。
1)这个函数有一个参数是 alloc_flags ,如果 alloc_flags & ALLOC_ZERO 则把所有返回的物理页面都填充 ‘ \0’。
2)page2kva 函数的作用就是通过物理页获取其内核虚拟地址,分配后的页面需要将 pp_link 指针设置为 NULL。
// Allocates a physical page. If (alloc_flags & ALLOC_ZERO), fills the entire
// returned physical page with '\\0' bytes. Does NOT increment the reference
// count of the page - the caller must do these if necessary (either explicitly
// or via page_insert).
//
// Be sure to set the pp_link field of the allocated page to NULL so
// page_free can check for double-free bugs.
//
// Returns NULL if out of free memory.
//
// Hint: use page2kva and memset
// 分配一个物理页面。如果(alloc_flags&ALLOC_ZERO),则用 '\\0' 字节填充返回的整个物理页面。不会增加页面的引用计数 - 调用者必须在必要时(显式或通过 page_insert)进行这些操作。
// 确保将分配的页面的 pp_link 字段设置为 NULL,以便 page_free 可以检查重复释放的错误。
// 如果内存不足,则返回 NULL。
// 提示:使用 page2kva 和 memset
struct PageInfo *
page_alloc(int alloc_flags)
{
// Fill this function in
if (page_free_list == NULL) {
return NULL;
}
struct PageInfo *allocated_page = page_free_list;
page_free_list = page_free_list->pp_link;
allocated_page->pp_link = NULL;
if (alloc_flags & ALLOC_ZERO)
memset(page2kva(allocated_page),'\\0', PGSIZE);
return allocated_page;
}
这段代码是用来实现页面分配的函数 page_alloc。下面是对这段代码的解释:
- 首先,函数检查
page_free_list是否为空。page_free_list是一个指向空闲页面链表的指针,如果它为空(即没有可用的空闲页面),函数就会返回NULL,表示没有可用内存页了。 - 如果有可用的空闲页面,函数会从空闲页面链表中取出第一个页面,并将其指针赋值给
allocated_page。这个页面将被分配给调用者使用。 - 接着,函数更新
page_free_list,将其指向空闲页面链表的下一个页面。这样,被取出的页面就不再属于空闲页面链表,而是被分配出去了。 allocated_page->pp_link = NULL;将被分配的页面的pp_link字段设置为NULL。这是为了在page_free函数中检查可能的双重释放(double-free)错误。确保被分配的页面不再指向其他空闲页面。- 最后,如果传入的
alloc_flags中包含ALLOC_ZERO标志,函数会使用memset将被分配的页面填充为零值。这将清空整个页面的内容,将所有字节设置为 '\0'。 - 最后返回
allocated_page,这个指针指向被成功分配的页面。
总之,这段代码的作用是从空闲页面链表中分配一个页面,并根据需要将其清零,然后返回被分配的页面的指针。
page_free( )函数
释放页面
如果pp->pp_ref不为0说明这个页面不是空的,如果pp->pp_link不为NULL说明接下来链表还有空页面,意思就是不能free,否则会出现问题。
如果排除以上条件,那么就可以free,free的步骤就是把pp_link从以前的NULL变成现在下一个可用页面,也就是page_free_list。
//
// Return a page to the free list.
// (This function should only be called when pp->pp_ref reaches 0.)
//
void
page_free(struct PageInfo *pp)
{
// Fill this function in
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
if (pp->pp_ref!=0 || pp->pp_link!=NULL){
panic("ARE YOU SERIOUS? Double check failed when dealloc page");
return;
}
pp->pp_link = page_free_list;
page_free_list = pp;
}
总结
在这个练习里面总共写了四个函数。boot_alloc( )函数,mem_init ( )函数,page_init()函数,page_alloc( )函数,page_free( )函数。
纵向分析一下这五个函数,但从名字来说可以分三类,boot,memory和page层面。
boot,启动层面,boot_alloc() 做了启动时先分配了N个byte空间的功能。这一步做完就有了一定的空间。
memory,内存层面,mem_init() 引入了数据结构Page_Info,做完这一步就将引入的空间在内存中划分成了页的层次。刚才分配了n个byte的空间,那么在这里就同样对应着npage*sizeof(Page_Info)个byte的页面,也就是npage个页面。
page,页面层面,page_init()是页面的初始化,初始化做的就是标记页表中哪些可以用,哪些不能用,把能用的链接起来。page_alloc( )就是分配这些能用的页面,page_free()就是释放掉页面。
所以,事实上,这个实验基本就完成了内存层面初始化页面以及页面的基本操作(包括删除和分配)。
退回$ROOT,现在应该make grade是20分,第一个练习完成。
这样第一部分就结束了,现在pages数组保存这所有物理页的信息,page_free_list链表记录这所有空闲的物理页。可以用page_alloc()和page_free()进行分配和回收。
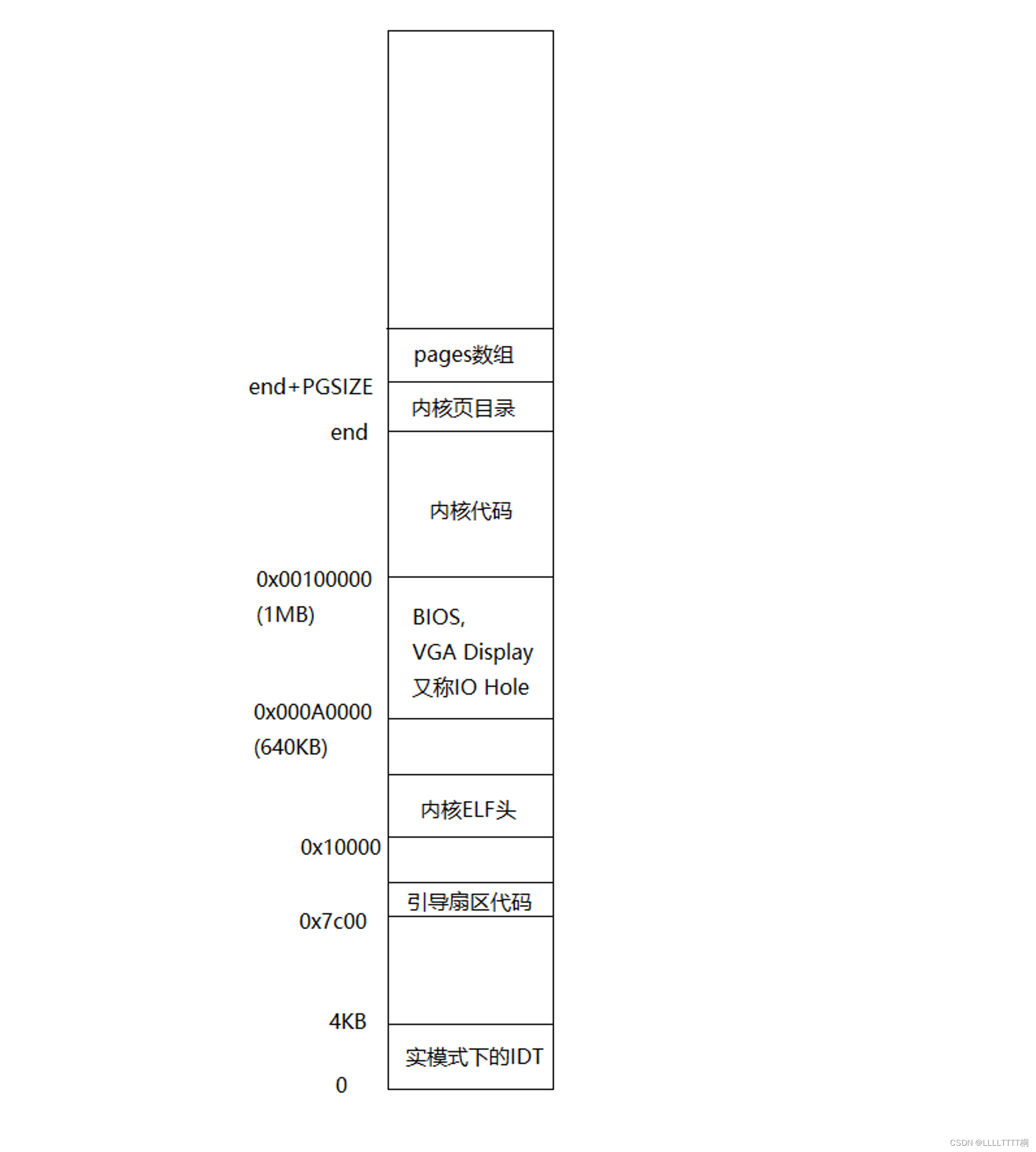
-
执行完mem_init()后的物理内存如下
Part 2: Virtual Memory
在开始其他任何操作之前,请先熟悉一下x86架构的保护模式内存管理架构,即分段和页面翻译。
Exercise 2.
如果您还没有这样做,请查阅 Intel 80386 参考手册的第 5 章和第 6 章。仔细阅读关于页面翻译和基于页面的保护的章节(5.2 和 6.4)。我们建议您也浏览一下关于分段的章节;尽管 JOS 使用页面硬件进行虚拟内存和保护,但在 x86 上无法禁用分段翻译和基于分段的保护,因此您需要对其有基本的了解。
Virtual, Linear, and Physical Addresses
在 x86 的术语中,一个虚拟地址由段选择器(segment selector)和段内偏移(offset within the segment)组成。线性地址是经过段翻译(segment translation)但尚未经过页翻译(page translation)的地址。物理地址是在经过段和页翻译后最终得到的地址,也是最终发送到硬件总线上到达 RAM 的地址。
-
示意图

C指针是虚拟地址的“偏移”组件。在 boot/boot.S 文件中,我们安装了一个全局描述符表(Global Descriptor Table,GDT),通过将所有段基址设置为0并将限制设置为0xffffffff,有效地禁用了段翻译。因此,“选择器”(selector)没有效果,线性地址总是等于虚拟地址的偏移量。在第三个实验中,我们需要更多地与分段进行交互,以设置特权级别,但对于内存转换,我们可以在整个 JOS 实验中忽略分段,只专注于页转换。
回顾一下实验一第三部分,在那里我们安装了一个简单的页表,使得内核可以以链接地址 0xf0100000 运行,尽管实际上它被加载到物理内存中,就在 ROM BIOS 的上方,地址是 0x00100000。这个页表只映射了 4MB 的内存。在本实验中,您要设置 JOS 的虚拟地址空间布局,我们将扩展这个页表,将物理内存的前 256MB 映射到虚拟地址 0xf0000000,并映射虚拟地址空间的其他区域。
Exercise 3.
虽然 GDB 只能通过虚拟地址访问 QEMU 的内存,但在设置虚拟内存时检查物理内存通常很有用。回顾一下实验工具指南中的 QEMU 监控命令,特别是 xp 命令,它允许您检查物理内存。要访问 QEMU 监控界面,在终端中按下 Ctrl-a c(同样的绑定可返回到串行控制台)。
使用 QEMU 监控中的 xp 命令和 GDB 中的 x 命令,检查对应的物理地址和虚拟地址的内存内容,确保您看到的数据是相同的。
我们修补过的 QEMU 版本提供了 info pg 命令,这可能也会很有用:它显示当前页表的紧凑但详细的表示,包括所有映射的内存范围、权限和标志。标准 QEMU 还提供了 info mem 命令,显示虚拟地址的哪些范围被映射,以及使用了什么权限。
从在 CPU 上执行的代码来看,一旦我们进入了保护模式(在 boot/boot.S 中首先执行的操作),就无法直接使用线性地址或物理地址。所有内存引用都被解释为虚拟地址,并由内存管理单元(MMU)进行转换,这意味着 C 中的所有指针都是虚拟地址。
JOS 内核经常需要将地址视为不透明值或整数进行操作,而无需对其进行解引用,例如在物理内存分配器中。有时这些是虚拟地址,有时是物理地址。为了帮助记录代码,JOS 源代码区分了这两种情况:类型 uintptr_t 表示不透明的虚拟地址,physaddr_t 表示物理地址。这两种类型实际上只是 32 位整数(uint32_t)的同义词,所以编译器不会阻止您将一个类型赋值给另一个!由于它们是整数类型(而不是指针),如果尝试对它们进行解引用,编译器将会报错。
JOS 内核可以通过首先将 uintptr_t 强制转换为指针类型来对其进行解引用。相比之下,内核无法明智地对物理地址进行解引用,因为MMU将转换所有内存引用。如果将 physaddr_t 强制转换为指针并对其进行解引用,您可能能够加载和存储到结果地址(硬件会将其解释为虚拟地址),但您可能不会得到您期望的内存位置。
总结如下:
C 类型 地址类型 T* 虚拟地址 uintptr_t 虚拟地址 physaddr_t 物理地址
Question
假设以下 JOS 内核代码是正确的,变量 x 应该具有什么类型,
uintptr_t还是physaddr_t?mystery_t x; char* value = return_a_pointer(); *value = 10; x = (mystery_t) value;
这个应该是 uintptr_t ,因为内核中的数据操作数据都是以内核虚拟地址进行
JOS 内核有时需要读取或修改它仅知道物理地址的内存。例如,向页表添加映射可能需要分配物理内存来存储页目录,然后初始化该内存。然而,内核无法绕过虚拟地址转换,因此无法直接加载和存储到物理地址。JOS 重新映射了从物理地址0开始的所有物理内存,将其映射到虚拟地址0xf0000000,其中一个原因是帮助内核读取和写入仅知道物理地址的内存。为了将物理地址转换为内核实际可以读取和写入的虚拟地址,内核必须将0xf0000000添加到物理地址,以找到其在重新映射区域中相应的虚拟地址。您应该使用 KADDR(pa) 来执行这个加法运算。
JOS 内核有时也需要能够根据内核数据结构存储的内存的虚拟地址找到物理地址。内核全局变量和由 boot_alloc() 分配的内存位于内核加载的区域内,从0xf0000000开始,这正是我们映射了所有物理内存的区域。因此,要将这个区域内的虚拟地址转换为物理地址,内核只需减去0xf0000000。您应该使用 PADDR(va) 来执行这个减法运算。
-
物理内存和虚拟内存的转换
我们代码中的 C 指针就是虚拟地址(Virtual Address)中的 offset,通过描述符表和段选择子(Selector),通过分段机制转换为线性地址(虚拟地址),因为JOS中设置的段基址为0,所以线性地址就等于offset。在未开启分页之前,线性地址就是物理地址。而在我们开启分页之后,线性地址经过 CPU 的MMU部件的页式转换得到物理地址。
开启分页后,当处理器碰到一个线性地址后,它的MMU部件会把这个地址分成 3 部分,分别是页目录索引(Directory)、页表索引(Table)和页内偏移(Offset), 这 3 个部分把原本 32 位的线性地址分成了 10+10+12 的 3 个片段。每个页表的大小为4KB(因为页内偏移为12位)。
举例:现在要将线性地址 0xf011294c 转换成物理地址。首先取高 10 位(页目录项偏移)即960(0x3c0),中间 10 位(页表项偏移)为274(0x112),偏移地址为1942(0x796)。 首先,处理器通过 CR3 取得页目录,并取得其中的第 960 项页目 录项,取得该页目录项的高 20 位地址,从而得到对应的页表物理页的首地址,再次取得页表中的第274项页表项,并进而取得该页表项的首地址,加上线性地址的低12位偏移地址1942,从而得到物理地址。
由上面也可知道,每个页目录表有1024个页目录项,每个页目录项占用4字节,一个页目录表占4KB内存。而每个页目录项都指向一个有1024个页表项的页表,每个页表项也占用4字节,因此JOS中页目录和页表一共要占用 1025 * 4KB = 4100KB 约4MB的内存。而通常我们说每个用户进程虚拟地址空间为4GB,其实就是每个进程都有一个页目录表,进程运行时将页目录地址装载到CR3寄存器中,从而每个进程最大可以用4GB内存。在JOS中,为了简单起见,只用了一个页目录表,整个系统的线性地址空间4GB是被内核和所有其他的用户程序所共用的。
分页管理中,页目录以及页表都存放在内存中,而由于CPU 和内存速度的不匹配,这样地址翻译时势必会降低系统的效率。为了提高地址翻译的速度,x86处理器引入了地址翻译缓存TLB(旁路转换缓冲)来缓存最近翻译过的地址。当然缓存之后会引入缓存和内存中页表内容不一致的问题,可以通过重载CR3使整个TLB内容失效或者通过 invlpg 指令。
Reference counting
在将来的实验中,您将经常看到同一个物理页同时映射到多个虚拟地址(或多个环境的地址空间中)。在与物理页对应的 struct PageInfo 结构的 pp_ref 字段中,您将保留对每个物理页引用的数量计数。当这个计数归零时,表示该物理页可以被释放,因为它不再被使用。通常情况下,该计数应该等于该物理页在所有页表中 UTOP 以下出现的次数(在 UTOP 以上的映射大多由内核在引导时设置,不应该被释放,因此不需要对它们进行引用计数)。我们还将使用它来跟踪我们对页目录页的指针数量,并进而追踪页目录对页表页面的引用次数。
在使用 page_alloc 函数时需要小心。它返回的页面的引用计数始终为 0,因此在对返回的页面执行某些操作(比如将其插入到页表中)后,pp_ref 应该立即递增。有时其他函数会处理这个问题(例如,page_insert 函数),有时调用 page_alloc 函数的函数必须直接处理它。
-
可以在 inc/memlayout.h 找到虚拟内存的布局
/* * Virtual memory map: Permissions * kernel/user * * 4 Gig --------> +------------------------------+ * | | RW/-- * ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ * : . : * : . : * : . : * |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| RW/-- * | | RW/-- * | Remapped Physical Memory | RW/-- * | | RW/-- * KERNBASE, ----> +------------------------------+ 0xf0000000 --+ * KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE | * | - - - - - - - - - - - - - - -| | * | Invalid Memory (*) | --/-- KSTKGAP | * +------------------------------+ | * | CPU1's Kernel Stack | RW/-- KSTKSIZE | * | - - - - - - - - - - - - - - -| PTSIZE * | Invalid Memory (*) | --/-- KSTKGAP | * : . : | * : . : | * MMIOLIM ------> +------------------------------+ 0xefc00000 --+ * | Memory-mapped I/O | RW/-- PTSIZE * ULIM, MMIOBASE --> +------------------------------+ 0xef800000 * | Cur. Page Table (User R-) | R-/R- PTSIZE * UVPT ----> +------------------------------+ 0xef400000 * | RO PAGES | R-/R- PTSIZE * UPAGES ----> +------------------------------+ 0xef000000 * | RO ENVS | R-/R- PTSIZE * UTOP,UENVS ------> +------------------------------+ 0xeec00000 * UXSTACKTOP -/ | User Exception Stack | RW/RW PGSIZE * +------------------------------+ 0xeebff000 * | Empty Memory (*) | --/-- PGSIZE * USTACKTOP ---> +------------------------------+ 0xeebfe000 * | Normal User Stack | RW/RW PGSIZE * +------------------------------+ 0xeebfd000 * | | * | | * ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ * . . * . . * . . * |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| * | Program Data & Heap | * UTEXT --------> +------------------------------+ 0x00800000 * PFTEMP -------> | Empty Memory (*) | PTSIZE * | | * UTEMP --------> +------------------------------+ 0x00400000 --+ * | Empty Memory (*) | | * | - - - - - - - - - - - - - - -| | * | User STAB Data (optional) | PTSIZE * USTABDATA ----> +------------------------------+ 0x00200000 | * | Empty Memory (*) | | * 0 ------------> +------------------------------+ --+ * * (*) Note: The kernel ensures that "Invalid Memory" is *never* mapped. * "Empty Memory" is normally unmapped, but user programs may map pages * there if desired. JOS user programs map pages temporarily at UTEMP. */这个虚拟内存映射图显示了 JOS 操作系统内存布局的一个高级视图。让我们从底部开始,逐步解释各个部分:
0x00000000(0): 虚拟地址空间的开始。通常,低地址保留给用户模式进程的代码、数据、堆和栈。USTABDATA (0x00200000): 用户模式符号表数据的可选部分。这用于调试。UTEMP (0x00400000): 临时映射的用户空间,用户程序可能会暂时在这里映射页面。PFTEMP: 用于映射待复制的页面,为了实现写时复制。UTEXT (0x00800000): 用户程序的文本(代码)区域的开始。- 从
UTEXT到UTOP之间的空间用于用户程序的数据、堆和普通用户栈。 USTACKTOP: 用户栈的顶部。UXSTACKTOP: 用户模式异常栈的顶部。当用户模式程序接收到异常时,会使用这个栈。UENVS (0xeec00000): 用户环境结构体的只读区域。UPAGES (0xef000000): 描述物理页面信息的只读页面。UVPT (0xef400000): 当前页表的只读映射,允许用户模式代码检查页表。ULIM (0xef800000): 用户空间的结束。上面的地址被保留用于内核。MMIOBASE (0xef800000)到MMIOLIM (0xefc00000): 内存映射的 I/O 区域,用于与硬件设备进行通信。KSTACKTOP: CPU0 的内核栈顶部,每个处理器都有自己的内核栈。KERNBASE (0xf0000000): 内核的基地址,所有物理内存从这个地址开始被映射到虚拟内存中。
在这个内存布局中,权限分为内核(RW)和用户(--或R)。这意味着有些区域只有内核可以写入(RW/--),有些区域用户可以读取但不能写入(R-/R-),还有些区域用户和内核都不能访问(--/--)。这样的权限设置帮助保护操作系统的稳定性和安全性,防止用户程序意外或恶意地修改内核或其他程序的内存。
可以从这个页表结构找一下虚拟地址是如何对应上的物理地址:
首先,根据虚拟地址vaddr = UVPT[31:22] PDX|PTX|00 在虚拟内存空间里查询,根据二级页表翻译机制:
1)页目录。系统首先取出vaddr的前10位,即UVPT[31:22],去页目录里面查询,并取得其中的页目
2)页表项和偏移地址。再取出vaddr中间10位,即PDX,和vaddr的后面的偏移值,组合之后在页表找到最终的页面物理地址。
由文段可知,地址从 [0,ULIM)区间为分配给用户的,其余的为分配给操作系统的。
在 JOS 操作系统中,UTOP 是一个宏定义,代表用户地址空间的顶部。更具体地说,UTOP 表示用户空间的最高地址(Upper limit of the User space)。通常情况下,它表示用户可访问的最高虚拟地址。以上这个界限以下的地址范围是为用户程序保留的,用于用户空间的分配和操作。
在 JOS 操作系统中,ULIM 是一个宏定义,代表用户地址空间的限制(User space Limit)。ULIM 是一个界限,表示用户空间的上限,即用户可访问的最高虚拟地址。ULIM 以上的地址范围通常不是用户空间可访问的范围,因此 ULIM 可以被用作用户空间的上界
在 JOS 操作系统中,UVPT 是一个宏定义,代表虚拟页表(Virtual Page Table)。UVPT 是一个特殊的虚拟地址,用于将页目录(Page Directory)映射到虚拟地址空间中,形成一个虚拟页表。通常情况下,UVPT 定义了页目录的一个虚拟地址,使得可以通过该虚拟地址来访问页目录的内容。
在 JOS 中,通过将页目录本身映射到 UVPT 虚拟地址来创建虚拟页表。这样的做法使得内核能够轻松地通过虚拟地址来访问页目录,从而能够更方便地管理和操作页表和页面映射。
Page Table Management
Exercise 4.
In the file kern/pmap.c, you must implement code for the following functions.
pgdir_walk() boot_map_region() page_lookup() page_remove() page_insert()
check_page(), called frommem_init(), tests your page table management routines. You should make sure it reports success before proceeding.
现在要写的代码在 kern/pmap.c 中,都是关于虚拟地址和物理地址转换的代码。
每一个物理页面对应一个Page的结构体和一个物理页号PPN(Pysical Page Number)和物理首地址。
在 pmap.h 中有这样几个定义:
static inline physaddr_t
page2pa(struct PageInfo *pp)
{
return (pp - pages) << PGSHIFT;
}
static inline struct PageInfo*
pa2page(physaddr_t pa)
{
if (PGNUM(pa) >= npages)
panic("pa2page called with invalid pa");
return &pages[PGNUM(pa)];
}
static inline void*
page2kva(struct PageInfo *pp)
{
return KADDR(page2pa(pp));
}
这段代码包含了一些内联函数(inline functions),用于在物理页结构 PageInfo 和物理地址之间进行转换,并且将物理页映射到对应的虚拟地址上。
page2pa(struct PageInfo *pp)函数接收一个 PageInfo 结构的指针作为参数,然后返回该 PageInfo 对应的物理地址。它通过计算 PageInfo 结构在页数组pages中的偏移量,然后左移PGSHIFT位来得到对应的物理地址。pa2page(physaddr_t pa)函数执行相反的操作。它接收一个物理地址pa作为参数,并返回与该物理地址相关联的 PageInfo 结构的指针。该函数首先通过PGNUM(pa)函数检查物理地址是否有效(是否超出了可用页的数量),然后返回对应的 PageInfo 结构的指针。page2kva(struct PageInfo *pp)函数接收 PageInfo 结构的指针作为参数,并返回该 PageInfo 对应的虚拟地址。它首先调用page2pa(pp)函数将 PageInfo 转换为物理地址,然后通过KADDR宏将物理地址转换为对应的虚拟地址。
这些函数在操作系统内核中用于处理物理页和对应的虚拟地址之间的转换,使得操作系统能够方便地管理和操作页面和地址。
pgdir_walk( ) 函数
// Given 'pgdir', a pointer to a page directory, pgdir_walk returns
// a pointer to the page table entry (PTE) for linear address 'va'.
// This requires walking the two-level page table structure.
//
// The relevant page table page might not exist yet.
// If this is true, and create == false, then pgdir_walk returns NULL.
// Otherwise, pgdir_walk allocates a new page table page with page_alloc.
// - If the allocation fails, pgdir_walk returns NULL.
// - Otherwise, the new page's reference count is incremented,
// the page is cleared,
// and pgdir_walk returns a pointer into the new page table page.
//
// Hint 1: you can turn a PageInfo * into the physical address of the
// page it refers to with page2pa() from kern/pmap.h.
//
// Hint 2: the x86 MMU checks permission bits in both the page directory
// and the page table, so it's safe to leave permissions in the page
// directory more permissive than strictly necessary.
//
// Hint 3: look at inc/mmu.h for useful macros that manipulate page
// table and page directory entries.
// 给定'pgdir',一个指向页目录的指针,pgdir_walk返回线性地址'va'的页面表项(PTE)的指针。
// 这需要遍历两级页表结构。
// 相关的页表页可能尚不存在。
// 如果这是真的,并且create == false,则pgdir_walk返回NULL。
// 否则,pgdir_walk使用page_alloc分配一个新的页表页。
// - 如果分配失败,pgdir_walk返回NULL。
// - 否则,增加新页面的引用计数,
// 清除页面,
// 并且pgdir_walk返回指向新页表页的指针。
// 提示1:可以使用kern/pmap.h中的page2pa()将PageInfo*转换为其引用的页面的物理地址。
// 提示2:x86 MMU在页目录和页表中检查权限位,因此将页目录中的权限设置得比严格要求更宽松是安全的。
// 提示3:查看inc/mmu.h中用于操作页面的有用宏。
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
// Fill this function in
pde_t pde = pgdir[PDX(va)];
if (!(pde & PTE_P))
if (!create)
return NULL;
else {
struct PageInfo *pp = page_alloc(true);
if (!pp)
return NULL;
(pp->pp_ref)++;
pgdir[PDX(va)] = page2pa(pp) | PTE_U | PTE_P | PTE_W;
return (pte_t *) page2kva(pp) + PTX(va);
}
return (pte_t *) KADDR(PTE_ADDR(pde)) + PTX(va);
}
主要作用是根据给定的页目录 pgdir 和虚拟地址 va 来获取或创建对应的页表项(PTE,Page Table Entry)。
在提示3里面写道 inc/mmu.h 中有很多可以调用的宏,那么就可以先来看一下这个文件中的内容:
// A linear address 'la' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
// \\--- PDX(la) --/ \\--- PTX(la) --/ \\---- PGOFF(la) ----/
// \\---------- PGNUM(la) ----------/
这段注释注意如下几个宏的使用:
PDX:一个虚拟地址的页目录索引,也是地址的前10位。
PTX:一个虚拟地址的页表索引,也是地址的中间10位。
PGOFF:一个虚拟地址的页偏移,也是地址的后12位。
// Page table/directory entry flags.
#define PTE_P 0x001 // Present
#define PTE_W 0x002 // Writeable
#define PTE_U 0x004 // User
#define PTE_PWT 0x008 // Write-Through
#define PTE_PCD 0x010 // Cache-Disable
#define PTE_A 0x020 // Accessed
#define PTE_D 0x040 // Dirty
#define PTE_PS 0x080 // Page Size
#define PTE_G 0x100 // Global
这一段就是表示页目录以及页表索引的各种状态。(存在,可写,用户,不允许缓存,可达,脏读,页面大小,是否全局等)
按照注释中所写,整个程序的步骤如下:
当页目录索引内不存在 va 对应的表项时,即虚拟地址没有对应的物理地址,需要根据create判断是否要为其分配一个物理页面用作二级页表,这里需要设置权限,由于一级页表和二级页表都有权限控制,所以一般的做法是,放宽一级页表的权限,主要由二级页表来控制权限,在提示2中写道,要注意去掉页目录索引(PDX)和页表索引(PTX)的权限位以保证安全操作。
当页目录索引内存在 va 对应的表项时,即虚拟地址有对应的物理地址,该页面的指针数量应该加一,页面清空,并返回一个新页表页的指针。 三个输入
pgdir(pde_t *pgdir):这是一个指向页目录的指针。页目录是一个数组,存储着指向页表的物理地址或者一些标志位。va(const void *va):这是一个指向要查询或创建页表项的虚拟地址的指针。create(int create):这是一个表示是否允许创建新的页表项的标志。如果为非零值,表示允许创建新的页表项;如果为零值,表示不允许创建新的页表项。
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
// 取得虚拟地址的页目录项 PDX(va), 并得到物理地址中所对应的页目录,命名为 pde
pde_t pde = pgdir[PDX(va)];
// 如果该物理页面 pde 不存在
if (!(pde & PTE_P))
// pde 不存在且不允许创建
if (!create)
return NULL;
// pde 不存在且允许创建
else {
// 新建页面 pp
struct PageInfo *pp = page_alloc(true);
// 如果新建页面失败
if (!pp)
return NULL;
// 新建页面的指针数量增长1
(pp->pp_ref)++;
// 新建页面取消限制权限
pgdir[PDX(va)] = page2pa(pp) | PTE_U | PTE_P | PTE_W;
// 取得虚拟地址的页表项 PTX(va),并找到新建页面所对应的地址
return (pte_t *) page2kva(pp) + PTX(va);
}
// 如果该页目录的物理地址 pde存在,说明该地址已分配,则返回已分配过的地址
return (pte_t *) KADDR(PTE_ADDR(pde)) + PTX(va);
}
PTE_ADDR 是一个宏,用于从页表项(PTE,Page Table Entry)中提取物理地址部分。在 x86 架构中,页表项包含了对应虚拟地址的物理页框号码(即页表项中存储的物理地址)。
具体而言,PTE_ADDR 宏的作用是提取页表项中存储的物理页框号,并返回一个表示物理地址的数值。
例如,假设有一个页表项 pte,其中存储着某个虚拟地址对应的物理地址和相关的控制信息。通过应用 PTE_ADDR(pte) 这个宏,可以提取出页表项中存储的物理页框号码。
常见的用途是在页表管理或虚拟内存管理中,从页表项中提取出实际物理页框的地址,以便进行地址转换或其他操作。
PTE_ADD
-
pde不就是物理地址了吗,为什么还要用PTE_ADDR来转换
对于 x86 架构而言,页目录项(PDE,Page Directory Entry)的确存储了页表的物理地址部分,但在一些情况下,需要通过 PTE_ADDR 宏来进一步提取页表的物理地址。
在 x86 架构中,页目录项(PDE)的结构如下所示:
- 31-12 位:页表的物理地址
- 11-0 位:可能包含了一些标志位,如权限位等
通常情况下,要获得页表的物理地址,可以直接使用页目录项(PDE)中的物理地址部分。但有时可能需要清除页目录项中的标志位信息,只保留物理地址部分,这时就可以使用
PTE_ADDR宏。PTE_ADDR宏用于从给定的页表项中提取出页的基本物理地址部分,同时丢弃页表项中的其他位。虽然命名上看起来是 "Page Table Entry Address",但它在处理页目录项时也能正常工作,因为页目录项和页表项在结构上类似,只是其具体作用在于页目录项和页表项上的地址提取。所以,尽管页目录项(PDE)中存储了页表的物理地址部分,有时为了清除标志位或者提取出纯粹的物理地址,可以使用
PTE_ADDR宏来保留页表的物理地址部分。
boot_map_region( ) 函数
// Map [va, va+size) of virtual address space to physical [pa, pa+size)
// in the page table rooted at pgdir. Size is a multiple of PGSIZE, and
// va and pa are both page-aligned.
// Use permission bits perm|PTE_P for the entries.
//
// This function is only intended to set up the ``static'' mappings
// above UTOP. As such, it should *not* change the pp_ref field on the
// mapped pages.
//
// Hint: the TA solution uses pgdir_walk
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
size_t pgs = size / PGSIZE;
if (size % PGSIZE != 0) {
pgs++;
} //计算总共有多少页
for (int i = 0; i < pgs; i++) {
pte_t *pte = pgdir_walk(pgdir, (void *)va, 1);//获取va对应的PTE的地址
if (pte == NULL) {
panic("boot_map_region(): out of memory\\n");
}
*pte = pa | PTE_P | perm; //修改va对应的PTE的值
pa += PGSIZE; //更新pa和va,进行下一轮循环
va += PGSIZE;
}
}
参数:
- pgdir:页目录指针
- va:虚拟地址
- size:大小
- pa:物理地址
- perm:权限
作用:通过修改pgdir指向的树,将[va, va+size)对应的虚拟地址空间映射到物理地址空间[pa, pa+size)。va和pa都是页对齐的。
page_insert()函数
// Map the physical page 'pp' at virtual address 'va'.
// The permissions (the low 12 bits) of the page table entry
// should be set to 'perm|PTE_P'.
//
// Requirements
// - If there is already a page mapped at 'va', it should be page_remove()d.
// - If necessary, on demand, a page table should be allocated and inserted
// into 'pgdir'.
// - pp->pp_ref should be incremented if the insertion succeeds.
// - The TLB must be invalidated if a page was formerly present at 'va'.
//
// Corner-case hint: Make sure to consider what happens when the same
// pp is re-inserted at the same virtual address in the same pgdir.
// However, try not to distinguish this case in your code, as this
// frequently leads to subtle bugs; there's an elegant way to handle
// everything in one code path.
//
// RETURNS:
// 0 on success
// -E_NO_MEM, if page table couldn't be allocated
//
// Hint: The TA solution is implemented using pgdir_walk, page_remove,
// and page2pa.
//
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
// Fill this function in
pte_t *pte = pgdir_walk(pgdir, va, 1); //拿到va对应的PTE地址,如果va对应的页表还没有分配,则分配一个物理页作为页表
if (pte == NULL) {
return -E_NO_MEM;
}
pp->pp_ref++; //引用加1
if ((*pte) & PTE_P) { //当前虚拟地址va已经被映射过,需要先释放
page_remove(pgdir, va); //这个函数目前还没实现
}
physaddr_t pa = page2pa(pp); //将PageInfo结构转换为对应物理页的首地址
*pte = pa | perm | PTE_P; //修改PTE
pgdir[PDX(va)] |= perm;
return 0;
}
参数:
- pgdir:页目录指针
- pp:PageInfo结构指针,代表一个物理页
- va:线性地址
- perm:权限
返回值:0代表成功,-E_NO_MEM代表物理空间不足。
作用:修改pgdir对应的树结构,使va映射到pp对应的物理页处。
page_lookup()
// Return the page mapped at virtual address 'va'.
// If pte_store is not zero, then we store in it the address
// of the pte for this page. This is used by page_remove and
// can be used to verify page permissions for syscall arguments,
// but should not be used by most callers.
//
// Return NULL if there is no page mapped at va.
//
// Hint: the TA solution uses pgdir_walk and pa2page.
//
struct PageInfo *
page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
// Fill this function in
struct PageInfo *pp;
pte_t *pte = pgdir_walk(pgdir, va, 0); //如果对应的页表不存在,不进行创建
if (pte == NULL) {
return NULL;
}
if (!(*pte) & PTE_P) {
return NULL;
}
physaddr_t pa = PTE_ADDR(*pte); //va对应的物理
pp = pa2page(pa); //物理地址对应的PageInfo结构地址
if (pte_store != NULL) {
*pte_store = pte;
}
return pp;
}
参数:
- pgdir:页目录地址
- va:虚拟地址
- pte_store:一个指针类型,指向pte_t *类型的变量
返回值:PageInfo*
作用:通过查找pgdir指向的树结构,返回va对应的PTE所指向的物理地址对应的PageInfo结构地址。
在这段代码中,pte_store 参数是一个指向 pte_t 指针的指针。这个参数主要用于存储页面表项(PTE,Page Table Entry)的地址。
具体来说,page_lookup 函数的作用是根据给定的虚拟地址 va,在页表中查找对应的页面,并返回该页面的 PageInfo 结构体指针。如果找到了对应页面,同时 pte_store 不为 NULL,那么 page_lookup 函数会将找到的页表项的地址存储到 pte_store 指向的地址中。这样做的目的在于提供额外的信息,允许调用者在需要的情况下访问对应虚拟地址的页表项,例如用于检查页面的权限或者进行其他的验证。
因此,pte_store 参数的作用是允许调用者获取对应虚拟地址的页表项的地址,这样可以在必要时进行页表项的验证或其他操作。
page_remve()
// Unmaps the physical page at virtual address 'va'.
// If there is no physical page at that address, silently does nothing.
//
// Details:
// - The ref count on the physical page should decrement.
// - The physical page should be freed if the refcount reaches 0.
// - The pg table entry corresponding to 'va' should be set to 0.
// (if such a PTE exists)
// - The TLB must be invalidated if you remove an entry from
// the page table.
//
// Hint: The TA solution is implemented using page_lookup,
// tlb_invalidate, and page_decref.
//
void
page_remove(pde_t *pgdir, void *va)
{
// Fill this function in
pte_t *pte_store;
struct PageInfo *pp = page_lookup(pgdir, va, &pte_store); //获取va对应的PTE的地址以及pp结构
if (pp == NULL) { //va可能还没有映射,那就什么都不用做
return;
}
page_decref(pp); //将pp->pp_ref减1,如果pp->pp_ref为0,需要释放该PageInfo结构(将其放入page_free_list链表中)
*pte_store = 0; //将PTE清空
tlb_invalidate(pgdir, va); //失效化TLB缓存
}
参数:
- pgdir:页目录地址
- va:虚拟地址
作用:修改pgdir指向的树结构,解除va的映射关系。
Part 3: Kernel Address Space
JOS 将处理器的 32 位线性地址空间分为两部分。用户环境(进程),我们将在实验 3 中开始加载和运行,将有控制低部分的布局和内容,而内核始终完全控制上部分。划分线在 inc/memlayout.h 中由符号 ULIM 定义,略显 arbitrario,为内核保留了大约 256MB 的虚拟地址空间。这解释了为什么我们在实验 1 中需要给内核一个如此高的链接地址:否则在内核的虚拟地址空间中将没有足够的空间同时映射用户环境。
你会发现在 inc/memlayout.h 中 JOS 内存布局图对这部分和后续实验都很有帮助。
/*
* Virtual memory map: Permissions
* kernel/user
*
* 4 Gig --------> +------------------------------+
* | | RW/--
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* : . :
* : . :
* : . :
* |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| RW/--
* | | RW/--
* | Remapped Physical Memory | RW/--
* | | RW/--
* KERNBASE, ----> +------------------------------+ 0xf0000000 --+
* KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| |
* | Invalid Memory (*) | --/-- KSTKGAP |
* +------------------------------+ |
* | CPU1's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| PTSIZE
* | Invalid Memory (*) | --/-- KSTKGAP |
* : . : |
* : . : |
* MMIOLIM ------> +------------------------------+ 0xefc00000 --+
* | Memory-mapped I/O | RW/-- PTSIZE
* ULIM, MMIOBASE --> +------------------------------+ 0xef800000
* | Cur. Page Table (User R-) | R-/R- PTSIZE
* UVPT ----> +------------------------------+ 0xef400000
* | RO PAGES | R-/R- PTSIZE
* UPAGES ----> +------------------------------+ 0xef000000
* | RO ENVS | R-/R- PTSIZE
* UTOP,UENVS ------> +------------------------------+ 0xeec00000
* UXSTACKTOP -/ | User Exception Stack | RW/RW PGSIZE
* +------------------------------+ 0xeebff000
* | Empty Memory (*) | --/-- PGSIZE
* USTACKTOP ---> +------------------------------+ 0xeebfe000
* | Normal User Stack | RW/RW PGSIZE
* +------------------------------+ 0xeebfd000
* | |
* | |
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* . .
* . .
* . .
* |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
* | Program Data & Heap |
* UTEXT --------> +------------------------------+ 0x00800000
* PFTEMP -------> | Empty Memory (*) | PTSIZE
* | |
* UTEMP --------> +------------------------------+ 0x00400000 --+
* | Empty Memory (*) | |
* | - - - - - - - - - - - - - - -| |
* | User STAB Data (optional) | PTSIZE
* USTABDATA ----> +------------------------------+ 0x00200000 |
* | Empty Memory (*) | |
* 0 ------------> +------------------------------+ --+
*
* (*) Note: The kernel ensures that "Invalid Memory" is *never* mapped.
* "Empty Memory" is normally unmapped, but user programs may map pages
* there if desired. JOS user programs map pages temporarily at UTEMP.
*/
JOS将线性地址空间分为两部分,由定义在inc/memlayout.h中的ULIM分割。ULIM以上的部分用户没有权限访问,内核有读写权限。
Permissions and Fault Isolation
由于内核和用户内存都存在于每个环境的地址空间中,我们将不得不在我们的 x86 页表中使用权限位,以允许用户代码仅访问地址空间的用户部分。否则,用户代码中的错误可能会覆盖内核数据,导致崩溃或更隐匿的故障;用户代码也可能能够窃取其他环境的私有数据。请注意,可写权限位(PTE_W)会影响用户和内核代码!
用户环境将无权访问 ULIM 上方的任何内存,而内核将能够读取和写入此内存。对于地址范围 [UTOP, ULIM),内核和用户环境都具有相同的权限:它们可以读取但不能写入这个地址范围。这个地址范围用于对用户环境只读地暴露特定的内核数据结构。最后,UTOP 以下的地址空间供用户环境使用;用户环境将设置访问此内存的权限。
Initializing the Kernel Address Space
现在您将设置 UTOP 上方的地址空间:地址空间的内核部分。inc/memlayout.h 显示了您应该使用的布局。您将使用刚刚编写的函数来设置适当的线性到物理的映射关系。
Exercise 5.
在调用 check_page() 后填写 mem_init() 中缺失的代码。
您的代码现在应该通过 check_kern_pgdir() 和 check_page_installed_pgdir() 检查。
boot_map_region( ) 作用是将一段 连续的虚拟地址映射到 它所对应的物理地址中,比如,将 [va, va+size)映射到 [pa, pa+size);
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
来看一下他的参数,第一个是页面的目录,第二个是虚拟地址,第三是映射范围大小,第四是对应物理地址,第五是赋予的权限。
那么我们先来看一下要映射的第一部分:
这一部分的映射,起点是UPAGES,大小是PTSIZE,物理地址是 PADDR(pages) ,权限是 PTE_U|PTE_P ,这里不写PTE_P是因为函数内部已经自己默认赋予此权限了。
//
// Now we set up virtual memory
//
// Map 'pages' read-only by the user at linear address UPAGES
// Permissions:
// - the new image at UPAGES -- kernel R, user R
// (ie. perm = PTE_U | PTE_P)
// - pages itself -- kernel RW, user NONE
// Your code goes here:
boot_map_region(kern_pgdir, UPAGES, PTSIZE, PADDR(pages), PTE_U);
第二部分的映射如下:
这一部分的映射,起点是KSTACKTOP-KSTKSIZE,大小是KSTKSIZE,物理地址是 PADDR(bootstack) ,权限是 PTE_W ,这里不写PTE_P是因为函数内部已经自己默认赋予此权限了。
// Use the physical memory that 'bootstack' refers to as the kernel
// stack. The kernel stack grows down from virtual address KSTACKTOP.
// We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP)
// to be the kernel stack, but break this into two pieces:
// * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory
// * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if
// the kernel overflows its stack, it will fault rather than
// overwrite memory. Known as a "guard page".
// Permissions: kernel RW, user NONE
// Your code goes here:
boot_map_region(kern_pgdir, KSTACKTOP-KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W);
第三部分的映射如下:
这一部分的映射,起点是KERNBASE,大小是 2^32 - KERNBASE,物理地址是 0,权限是 PTE_W ,这里不写PTE_P是因为函数内部已经自己默认赋予此权限了。
//
// Map all of physical memory at KERNBASE.
// Ie. the VA range [KERNBASE, 2^32) should map to
// the PA range [0, 2^32 - KERNBASE)
// We might not have 2^32 - KERNBASE bytes of physical memory, but
// we just set up the mapping anyway.
// Permissions: kernel RW, user NONE
// Your code goes here:
boot_map_region(kern_pgdir, KERNBASE, -KERNBASE, 0, PTE_W);
-
执行完mem_init()后kern_pgdir指向的内核页目录代表的虚拟地址空间到物理地址空间映射可以用下图来表示:
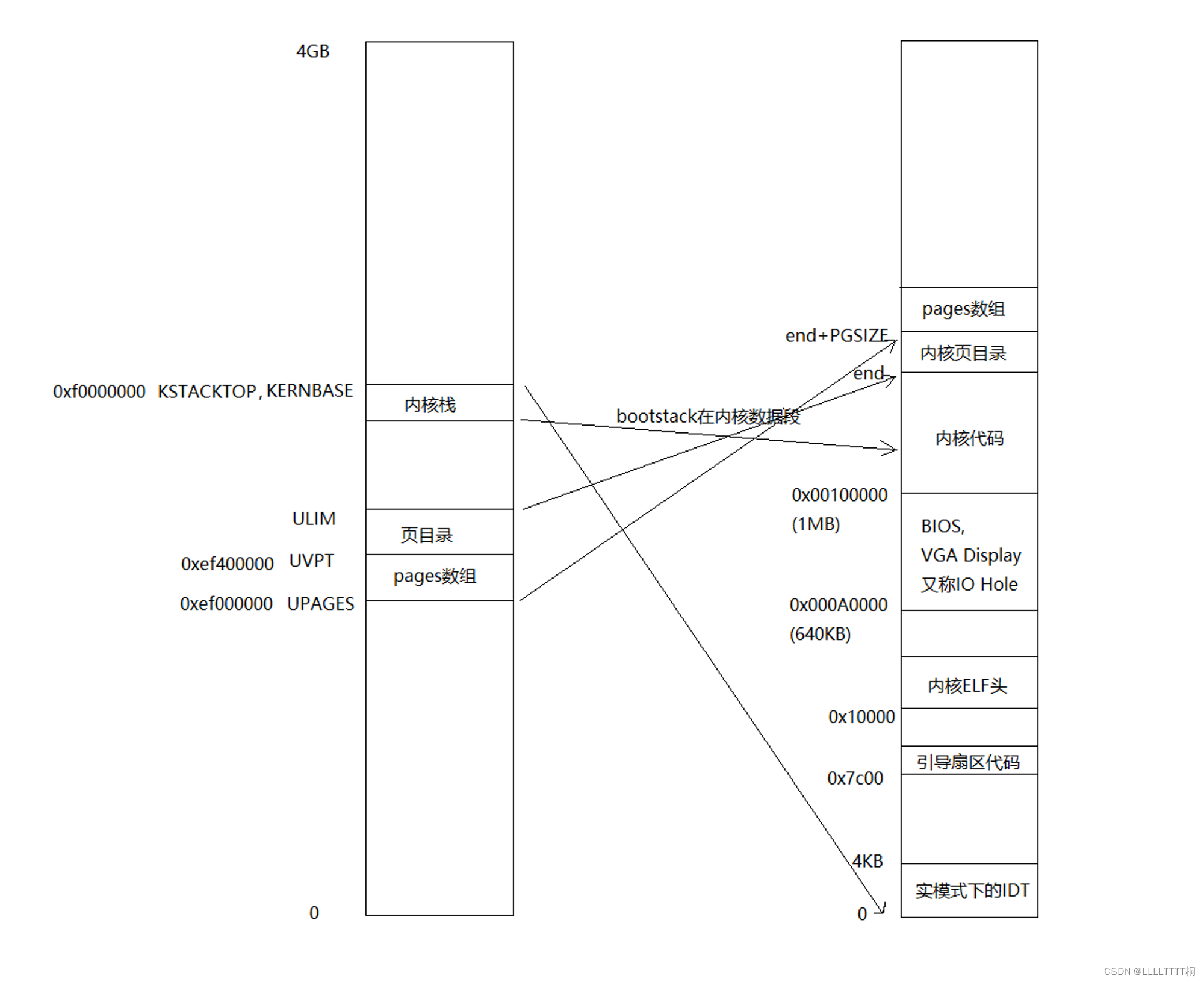
如何仔细看图和上面的代码,会觉得奇怪,UVPT开始的这一页是什么时候映射的?实际上早在mem_init()开始的时候就有这么一句kern_pgdir[PDX(UVPT)] = PADDR(kern_pgdir) | PTE_U | PTE_P;,页目录表的低PDX(UVPT)项指向页目录本身,也就是说虚拟地址UVPT开始处的0x400000字节映射到物理地址PADDR(kern_pgdir)处。
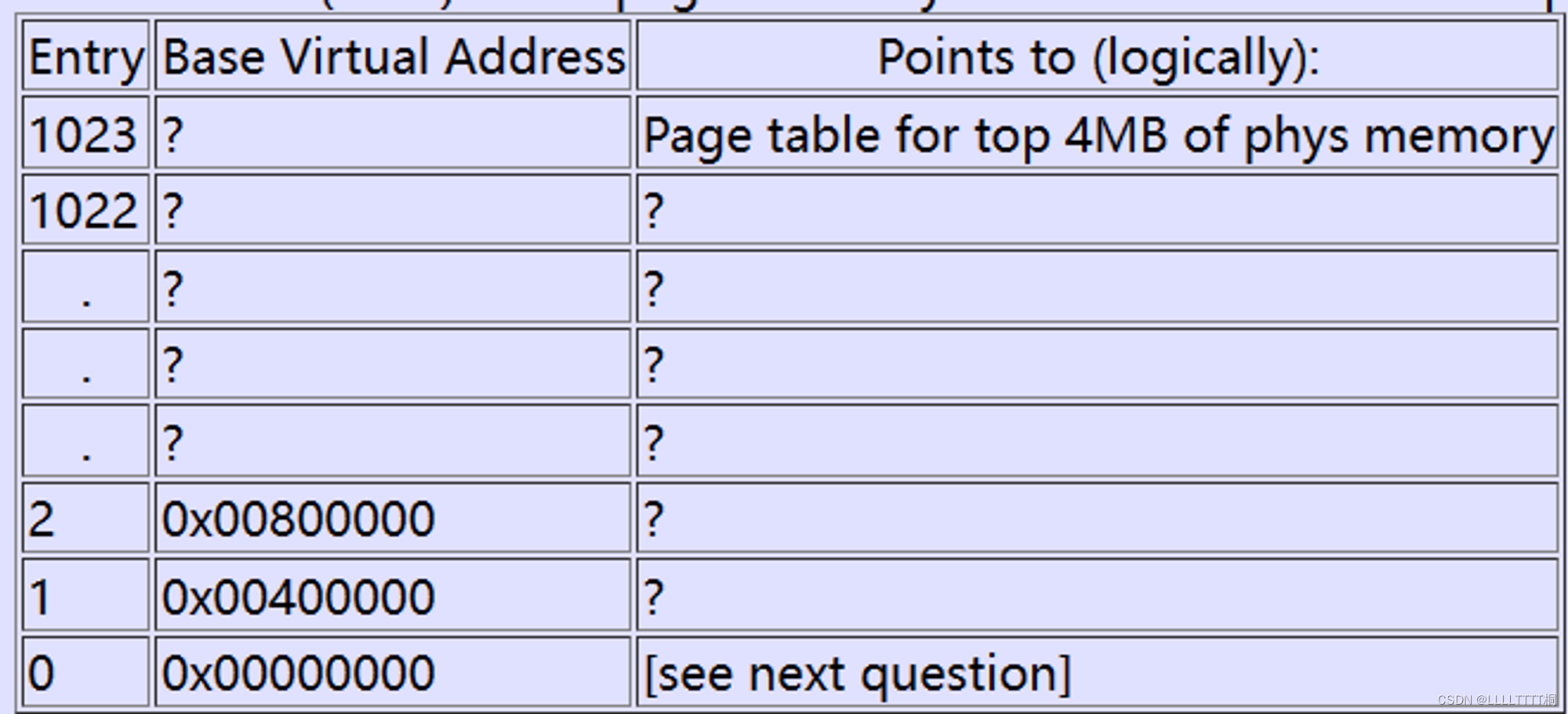
Question
在这一点上,页目录中已经填写了哪些条目(行)?它们映射到什么地址,指向哪里?换句话说,尽可能填写下面这个表格:
我们将内核和用户环境放置在相同的地址空间中。为什么用户程序不能读取或写入内核的内存?有什么特定的机制来保护内核内存?
这个操作系统能够支持的最大物理内存量是多少?为什么?
如果我们实际拥有最大物理内存量,管理内存的空间开销有多少?这个开销是如何分解的?
回顾一下在
kern/entry.S和kern/entrypgdir.c中的页表设置。在我们开启分页之后,EIP 仍然是一个较低的数字(略高于 1MB)。我们何时过渡到以高于 KERNBASE 的 EIP 运行?是什么让我们能够在开启分页和开始以高于 KERNBASE 的 EIP 运行之间继续以低 EIP 执行?为什么这个过渡是必要的?
-
回答
1)第一个问题就是在找页面对应的虚拟地址以及映射的物理地址范围的对应。那么就不得不再提一遍说过的刚才的虚拟地址的结构,前10位是页面,所以一共有1024个目录项,每一个目录项的大小是2^10 个页,最后每个页面有2^12个条目。一个页面能够映射4MB的物理内存(PTSIZE = 4MB)。
2)由于页表可以设置权限位,如果没有将 PTE_U 置 0 则用户无权限读写。
3)所有的空闲的物理页面一开始都储存在了pages这样一个数组中,这个数组存储的基本单元是PageInfo,那么一个PageInfo的大小是sizeof(struct PageInfo))=8 Byte,也就是说最多512K个页面,每个页面容量 2 ^ 12 = 4K。所以512K*4K=2GB。
4)刚才通过上一问,所有的 PageInfo 结构组成的数组的大小是 4MB,最多有 512 K 个页面,那么就有 0.5M 个页面,一条地址信息32位,也就是4B,那么就是页面信息要用4B*0.5M=2MB 记录,目录项本身4K,所以要6MB+4KB。
5)语句jmp *%eax即转到 eax 所存的地址执行,在这里完成了跳转。relocated 部分代码主要设置了栈指针以及调用 kern/init.c。由于在 kern/entrypgdir.c 中将 0~4MB 和 KERNBASE ~ KERNBASE + 4 MB 的虚拟地址都映射到了 0~4MB 的物理地址上,因此无论 EIP 在高位和低位都能执行。必需这么做是因为如果只映射高位地址,那么在开启分页机制的下一条语句就会crash。
***Challenge!***我们使用了许多物理页面来保存 KERNBASE 映射的页表。使用页目录项中的 PTE_PS("Page Size")位来做更省空间的优化工作。在原始的 80386 处理器上并不支持这一位,但是在更近期的 x86 处理器上支持。因此,你需要参考当前英特尔手册的第三卷。确保你设计的内核只在支持该功能的处理器上使用这种优化!
***Challenge!***扩展 JOS 内核监视器,添加以下命令:
以有用且易于阅读的格式显示当前活动地址空间中适用于特定虚拟/线性地址范围的所有物理页面映射(或缺失)。例如,您可以输入 'showmappings 0x3000 0x5000' 来显示适用于虚拟地址 0x3000、0x4000 和 0x5000 的物理页面映射及相应的权限位。 显式地设置、清除或更改当前地址空间中任何映射的权限。 在给定虚拟地址或物理地址范围的情况下,转储内存范围的内容。确保当范围跨越页面边界时,转储代码能够正确工作! 进行其他任何您认为以后用于调试内核可能有用的工作。(这很有可能会有用!)
-
回答
首先,形式是作为一个字符串输入的,我们需要先把它转换为数字形式的地址。
uint32_t xtoi(char* buf) { uint32_t res = 0; buf += 2; //0x... while (*buf) { if (*buf >= 'a') *buf = *buf-'a'+'0'+10;//aha res = res*16 + *buf - '0'; ++buf; } return res; }再写一个格式化输出的函数:
void pprint(pte_t *pte) { cprintf("PTE_P: %x, PTE_W: %x, PTE_U: %x\\n", *pte&PTE_P, *pte&PTE_W, *pte&PTE_U); }最后:
int showmappings(int argc, char **argv, struct Trapframe *tf) { if (argc == 1) { cprintf("Usage: showmappings 0xbegin_addr 0xend_addr\\n"); return 0; } uint32_t begin = xtoi(argv[1]), end = xtoi(argv[2]); cprintf("begin: %x, end: %x\\n", begin, end); for (; begin <= end; begin += PGSIZE) { pte_t *pte = pgdir_walk(kern_pgdir, (void *) begin, 1); //create if (!pte) panic("boot_map_region panic, out of memory"); if (*pte & PTE_P) { cprintf("page %x with ", begin); pprint(pte); } else cprintf("page not exist: %x\\n", begin); } return 0; } 运行 make qemuK> showmappings Usage: showmappings 0xbegin_addr 0xend_addr K> showmappings 0xf011a000 0xf012a000 begin: f011a000, end: f012a000 page f011a000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f011b000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f011c000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f011d000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f011e000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f011f000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0120000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0121000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0122000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0123000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0124000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0125000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0126000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0127000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0128000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f0129000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 page f012a000 with PTE_P: 1, PTE_W: 2, PTE_U: 0 K> showmappings 0xef000000 0xef010000 begin: ef000000, end: ef010000 page ef000000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef001000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef002000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef003000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef004000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef005000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef006000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef007000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef008000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef009000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef00a000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef00b000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef00c000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef00d000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef00e000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef00f000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 page ef010000 with PTE_P: 1, PTE_W: 0, PTE_U: 4 K>
Address Space Layout Alternatives
在 JOS 中我们使用的地址空间布局并不是唯一可能的。一个操作系统可以将内核映射到低线性地址,同时将线性地址空间的上部留给用户进程。然而,x86 内核通常不采用这种方法,因为 x86 的一个向后兼容模式称为虚拟 8086 模式,它在处理器中被“硬连接”以使用线性地址空间的底部部分,因此如果内核被映射到那里,则无法使用该模式。
甚至可能,尽管更加困难,设计内核以便不必为自身保留处理器线性或虚拟地址空间的任何固定部分,而是有效地允许用户级进程无限制地使用整个4GB的虚拟地址空间——同时完全保护内核免受这些进程的影响,并保护不同进程之间的隔离!
挑战!每个用户级环境都映射内核。更改 JOS 以使内核有自己的页表,并且用户级环境只映射了最少数量的内核页面。也就是说,每个用户级环境映射了足够数量的页面,以使用户级环境可以正确进入和离开内核。您还需要提出一个计划,让内核能够读/写系统调用的参数。
挑战!撰写一个概要,说明内核如何设计以允许用户环境无限制地使用完整的4GB虚拟和线性地址空间。提示:先完成上一个挑战练习,将内核减少到用户环境中的少数映射。提示:该技术有时称为“跟踪内核”。在您的设计中,请确保详细描述处理器在内核模式和用户模式之间进行转换时需要发生的具体情况,以及内核如何完成这些转换。还要描述内核在这种方案中如何访问物理内存和I/O设备,以及内核在系统调用等情况下如何访问用户环境的虚拟地址空间。最后,思考并描述这种方案在灵活性、性能、内核复杂性和其他方面的优缺点。
挑战!由于我们的 JOS 内核的内存管理系统只在页面粒度上分配和释放内存,我们没有类似于通用的 malloc/free 功能,在内核中无法使用。如果我们想要支持某些类型的I/O设备,这些设备需要比4KB大的物理连续缓冲区,或者如果我们希望用户级环境(不仅仅是内核)能够分配和映射4MB超级页以实现最大处理器效率,这可能会成为一个问题。(参见早期有关PTE_PS的挑战问题。) 将内核的内存分配系统泛化,以支持多种从4KB到某个合理最大值的二次幂分配单元大小的页面。确保您有某种方法,可以按需将较大的分配单元划分为较小的分配单元,并在可能时将多个小分配单元合并成较大单元。考虑可能在这样一个系统中出现的问题。
总结
该实验大体上做三件事:
-
提供管理物理内存的数据结构和函数,可总结为下图:
-
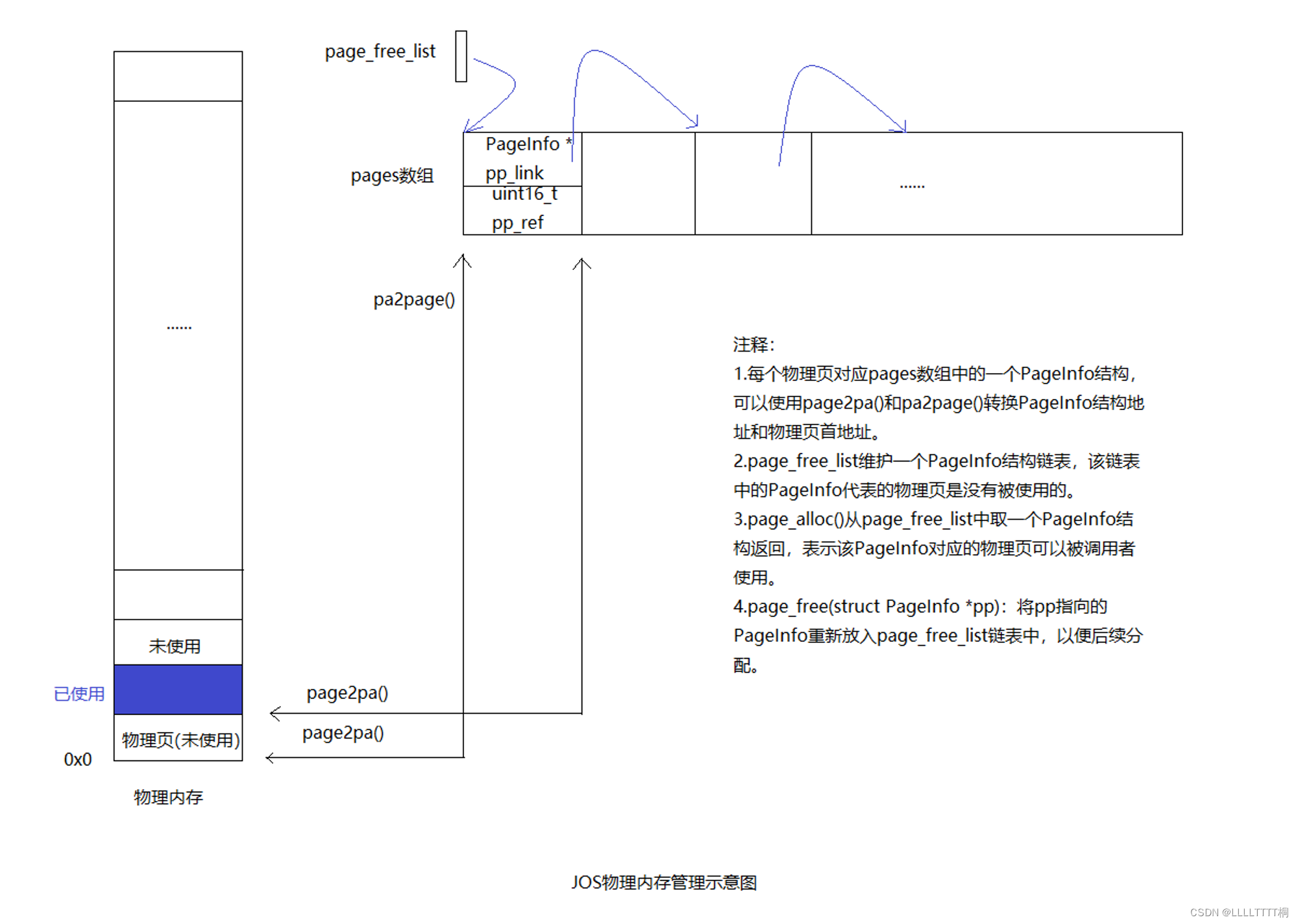
-
提供修改页目录和页表树结构的函数,从而达到虚拟页到物理页映射的目的。可总结为下图:
-
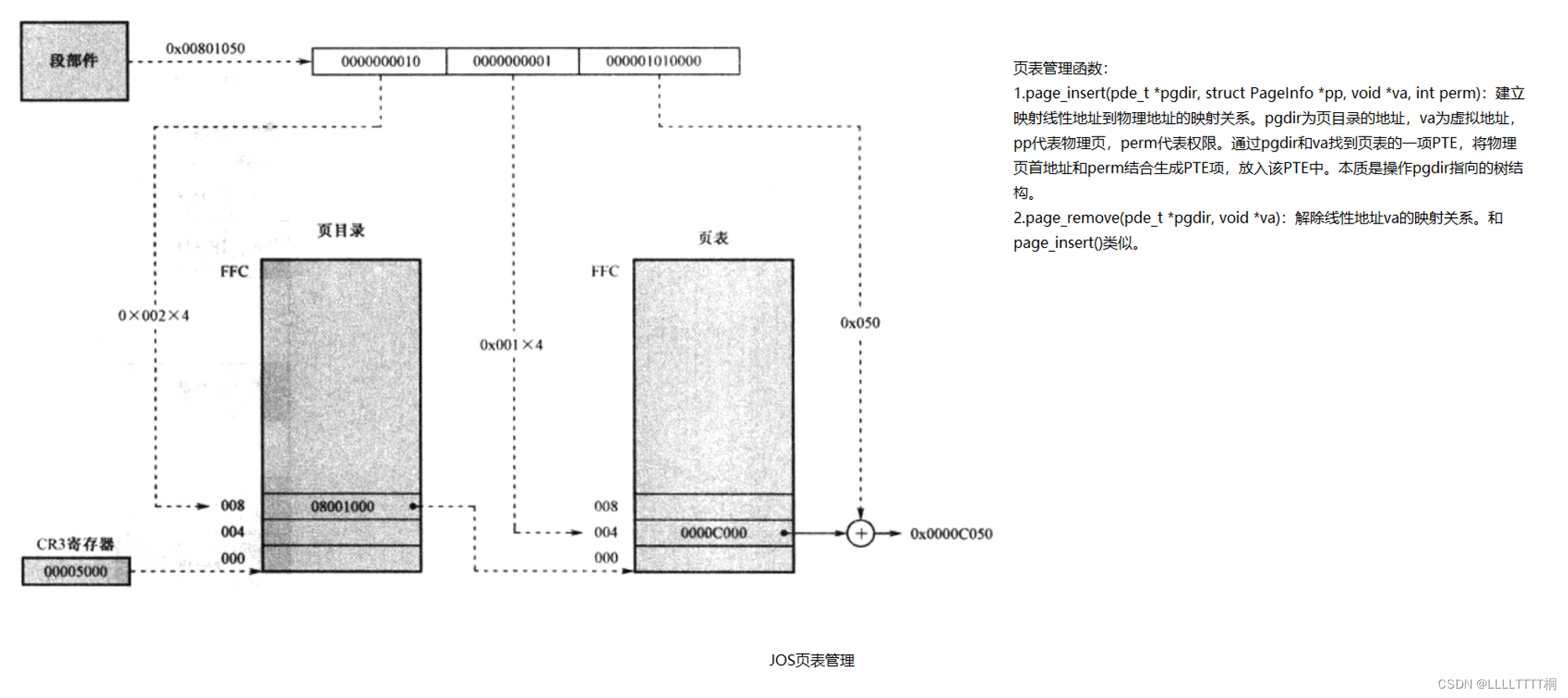
-
用前面两部分的函数建立内核的线性地址空间。内核的线性地址空间到物理内存的映射可总结为下图:现在我们可以直接使用UPAGES这个虚拟地址直接访问pages数组,使用UVPT访问内核页目录表,使用KSTACKTOP访问内核栈。
-
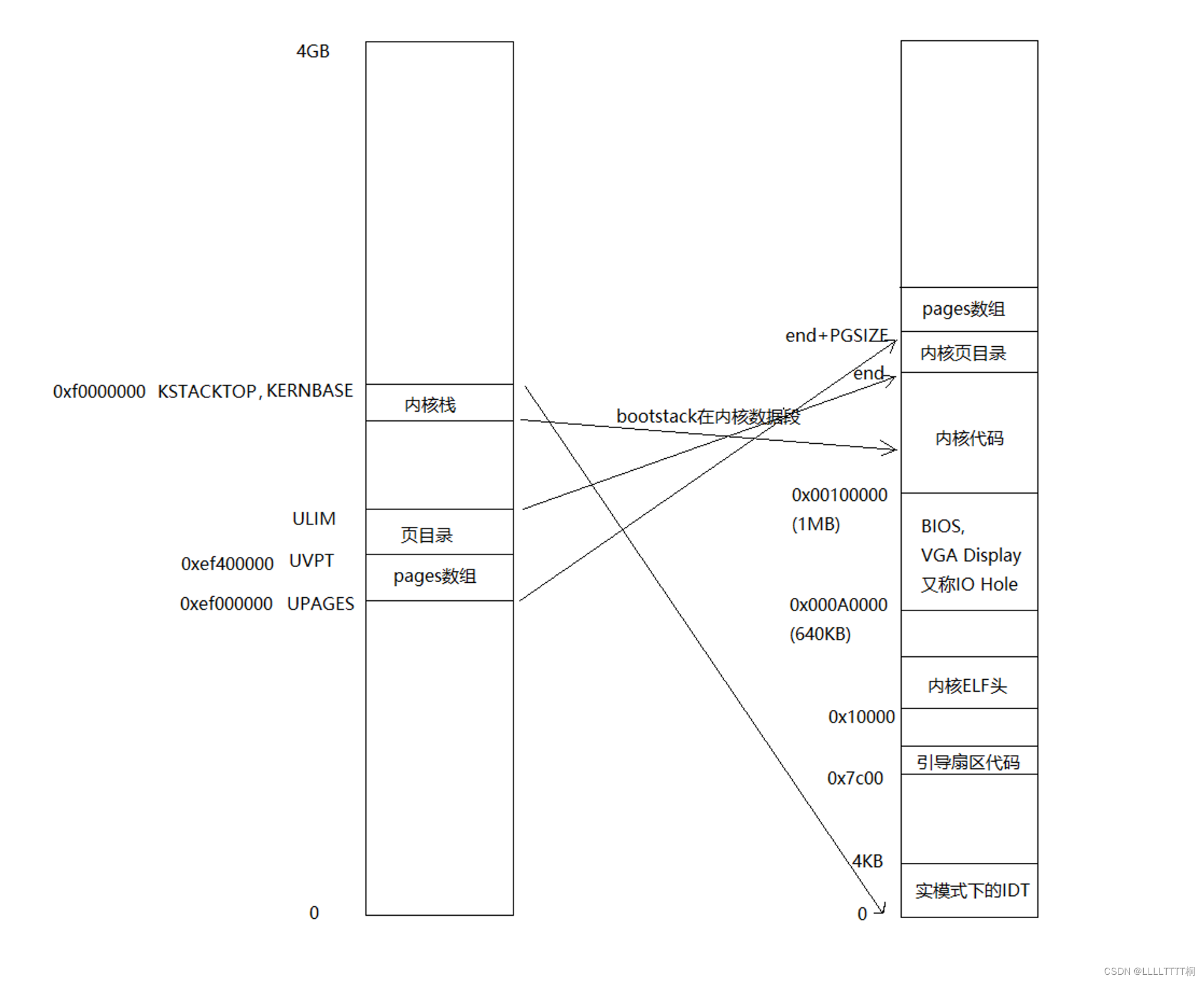

















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









