






Introduction
这个实验是你可以自行完成的默认期末项目。
现在你已经有了一个文件系统,一个自尊的操作系统不应该没有网络堆栈。在这个实验中,你将编写一个网络接口卡的驱动程序。该网络接口卡将基于Intel 82540EM芯片,也被称为E1000。
Getting Started
使用Git来提交你的Lab 5源代码(如果还没有提交),获取课程存储库的最新版本,然后基于我们的lab6分支(origin/lab6)创建一个名为lab6的本地分支:
athena% cd ~/6.828/lab
athena% add git
athena% git commit -am '我对lab5的解决方案'
nothing to commit (working directory clean)
athena% git pull
Already up-to-date.
athena% git checkout -b lab6 origin/lab6
Branch lab6 set up to track remote branch refs/remotes/origin/lab6.
Switched to a new branch "lab6"
athena% git merge lab5
Merge made by recursive.
fs/fs.c | 42 +++++++++++++++++++
1 files changed, 42 insertions(+), 0 deletions(-)
athena%
然而,仅仅编写一个网络接口卡驱动程序是不足以让你的操作系统连接到互联网的。在新的lab6代码中,我们为你提供了一个网络堆栈和一个网络服务器。与以前的实验一样,使用Git获取这个实验的代码,合并你自己的代码,然后探索新的net/目录以及kern/目录中的新文件。
除了编写驱动程序,你还需要创建一个系统调用接口,以便让用户程序能够访问你的驱动程序。你将实现缺失的网络服务器代码,以在网络堆栈和你的驱动程序之间传输数据包。你还将通过完成一个Web服务器将所有内容整合在一起。使用新的Web服务器,你将能够从你的文件系统中提供文件。
你将不得不从头开始编写大部分内核设备驱动程序代码。这个实验提供的指导要比以前的实验少得多:没有骨架文件,没有被写死的系统调用接口,许多设计决策都由你来决定。因此,我们建议在开始任何个别的练习之前先阅读整个任务说明。许多学生认为这个实验比以前的实验更困难,所以请合理安排时间。
Lab Requirements
As before, you will need to do all of the regular exercises described in the lab and at least one challenge problem. Write up brief answers to the questions posed in the lab and a description of your challenge exercise in answers-lab6.txt.
QEMU's virtual network
我们将使用QEMU的用户模式网络堆栈,因为它不需要管理权限即可运行。QEMU的文档中有更多关于用户模式网络(user-net)的信息。我们已经更新了Makefile以启用QEMU的用户模式网络堆栈和虚拟E1000网络卡。
默认情况下,QEMU提供一个运行在IP地址10.0.2.2上的虚拟路由器,并将分配IP地址10.0.2.15给JOS。为了保持简单,我们在net/ns.h中硬编码了这些默认值,这是网络服务器的一部分。
虽然QEMU的虚拟网络允许JOS建立到互联网的任意连接,但JOS的10.0.2.15地址在QEMU内部的虚拟网络之外没有意义(也就是说,QEMU充当了NAT),所以我们无法直接从运行QEMU的主机连接到在JOS内运行的服务器。为了解决这个问题,我们配置QEMU在主机上的某个端口上运行一个服务器,该服务器只需连接到JOS中的某个端口,并在真实主机和虚拟网络之间传输数据。
你将在端口7(echo)和端口80(http)上运行JOS服务器。为了避免在共享的Athena机器上发生冲突,Makefile会根据你的用户ID生成这些端口的转发端口。要查找QEMU在开发主机上转发到哪些端口,请运行make which-ports。为了方便起见,Makefile还提供了make nc-7和make nc-80,允许你直接在终端上与运行在这些端口上的服务器交互。(这些目标只连接到正在运行的QEMU实例;你必须单独启动QEMU本身。)
Packet Inspection
Makefile还配置了QEMU的网络堆栈,以记录所有进出的数据包到你的实验目录中的qemu.pcap文件。
要获取捕获数据包的十六进制/ASCII转储,可以像这样使用tcpdump:
tcpdump -XXnr qemu.pcap
另外,你也可以使用Wireshark来以图形方式检查pcap文件。Wireshark还知道如何解码和检查数百种网络协议。如果你在Athena上,你将不得不使用Wireshark的前身ethereal,它位于sipbnet锁柜中。
Debugging the E1000
我们非常幸运能够使用模拟的硬件。由于E1000在软件中运行,模拟的E1000可以以用户可读的格式向我们报告其内部状态和遇到的任何问题。通常情况下,裸机驱动程序开发者不会享受到这样的便利。
E1000可以生成大量的调试输出,因此你需要启用特定的日志通道。一些你可能会发现有用的通道包括:
- tx:记录数据包传输操作
- txerr:记录传输环错误
- rx:记录RCTL的更改
- rxfilter:记录传入数据包的过滤
- rxerr:记录接收环错误
- unknown:记录未知寄存器的读取和写入
- eeprom:记录从EEPROM的读取
- interrupt:记录中断和中断寄存器的更改
要启用“tx”和“txerr”日志,例如,可以使用以下命令:
make E1000_DEBUG=tx,txerr ...
请注意:E1000_DEBUG标志仅适用于6.828版本的QEMU。
如果你遇到困难,不理解为什么E1000的响应不符合你的预期,你可以进一步深入研究QEMU中的E1000实现,它位于hw/net/e1000.c中。这可以帮助你更好地理解E1000的工作原理和可能的问题。
The Network Server
从头开始编写一个网络堆栈是一项艰巨的工作。因此,我们将使用lwIP,一个开源的轻量级TCP/IP协议套件,它包括一个网络堆栈等多个功能。你可以在这里找到更多关于lwIP的信息。在这个任务中,就我们而言,lwIP是一个黑盒子,它实现了BSD套接字接口,并具有数据包输入端口和数据包输出端口。
网络服务器实际上是四个环境的组合:
- 核心网络服务器环境(包括套接字调用分发器和lwIP)
- 输入环境
- 输出环境
- 计时器环境
以下图表显示了不同环境及其之间的关系。该图表显示了整个系统,包括设备驱动程序,设备驱动程序将在后面介绍。在这个实验中,你将实现图中绿色部分的功能。
-
网络服务器
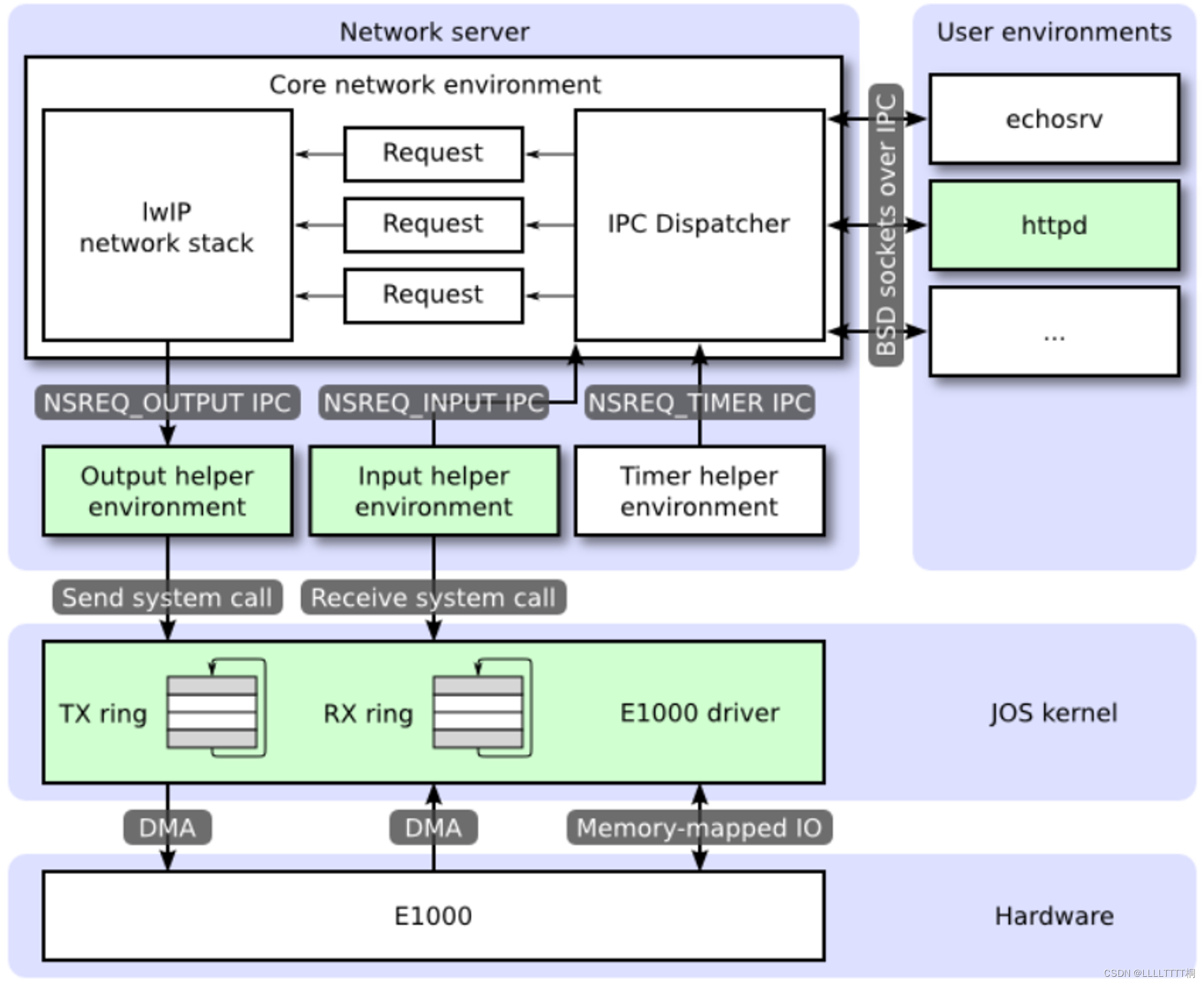
-
核心网络服务器环境 core network server environment (includes socket call dispatcher and lwIP) 核心网络服务器环境由套接字调用调度器和lwIP本身组成。套接字调用调度器的工作方式与文件服务器完全相同。用户环境使用存储在lib/nsipc.c中的存根(stubs)向核心网络环境发送IPC消息。如果查看lib/nsipc.c,你会发现我们查找核心网络服务器的方式与查找文件服务器相同:i386_init使用NS_TYPE_NS创建了NS环境,因此我们在envs中查找这种特殊的环境类型。对于每个用户环境的IPC,网络服务器中的调度器代表用户调用lwIP提供的适当的BSD套接字接口函数。
常规用户环境不直接使用nsipc_*调用。相反,它们使用lib/sockets.c中提供的基于文件描述符的套接字API的函数。因此,用户环境通过文件描述符引用套接字,就像它们引用磁盘上的文件一样。许多操作(如连接、接受等)是特定于套接字的,但读取、写入和关闭通过lib/fd.c中的正常文件描述符设备调度代码进行。与文件服务器一样,lwIP也为所有打开的套接字生成唯一的ID。在文件服务器和网络服务器中,我们使用存储在struct Fd中的信息将每个环境的文件描述符映射到这些唯一的ID空间。
尽管文件服务器和网络服务器的IPC调度器看起来表现一样,但有一个关键的区别。像accept和recv这样的BSD套接字调用可能会无限期地阻塞。如果调度程序允许lwIP执行这些阻塞调用中的一个,调度程序也将阻塞,整个系统一次只能有一个未完成的网络调用。由于这是不可接受的,网络服务器使用用户级线程来避免阻塞整个服务器环境。对于每个传入的IPC消息,调度程序会创建一个线程,并在新创建的线程中处理请求。如果线程阻塞,那么只有该线程被挂起,而其他线程继续运行。
除了核心网络环境外,还有三个辅助环境。除了接受来自用户应用程序的消息外,核心网络环境的调度器还接受来自输入和计时器环境的消息。
-
输出环境 input environment 在为用户环境提供套接字调用服务时,lwIP将生成要传输到网络卡的数据包。LwIP将使用NSREQ_OUTPUT IPC消息将每个要传输的数据包发送到输出辅助环境,其中数据包作为IPC消息的页参数附加在消息中。输出环境负责接受这些消息,并通过你即将创建的系统调用接口将数据包转发到设备驱动程序。
-
输入环境 output environment 由网络卡接收到的数据包需要被注入到lwIP中。对于设备驱动程序接收到的每个数据包,输入环境从内核空间中提取数据包(使用你将要实现的内核系统调用),并使用NSREQ_INPUT IPC消息将数据包发送到核心服务器环境。
数据包输入功能与核心网络环境分开,因为JOS使得同时接受IPC消息并轮询或等待设备驱动程序中的数据包变得困难。在JOS中,我们没有select系统调用,允许环境监视多个输入源以确定哪个输入准备好被处理。
如果查看net/input.c和net/output.c,你会发现两者都需要被实现。这主要是因为实现依赖于你的系统调用接口。在你实现驱动程序和系统调用接口之后,你将编写两个辅助环境的代码。
-
计时器环境 timer environment 计时器环境定期发送NSREQ_TIMER类型的消息给核心网络服务器,通知它计时器已经过期。这个线程的计时器消息由lwIP用于实现各种网络超时。
仔细看上图,绿颜色的部分是本lab需要实现的部分。分别是:
- E1000网卡驱动,并对外提供两个系统调用,分别用来接收和发送数据。
- 输入进程。
- 输出进程。
- 用户程序httpd的一部分。
Part A: Initialization and transmitting packets
你的内核目前没有时间的概念,所以我们需要添加它。当前,硬件每隔10毫秒生成一个时钟中断。在每次时钟中断时,我们可以增加一个变量来指示时间已经提前了10毫秒。这个功能已经在kern/time.c中实现,但还没有完全集成到你的内核中。
Exercise 1.
在kern/trap.c中的每次时钟中断中添加对time_tick的调用。在kern/syscall.c中实现sys_time_msec,并将其添加到syscall,以便用户空间可以访问时间
// 1
// LAB 4: Your code here.
case (IRQ_OFFSET + IRQ_TIMER):
// 回应8259A 接收中断。
lapic_eoi();
time_tick();
sched_yield();
break;
// 2
static int
sys_time_msec(void)
{
// LAB 6: Your code here.
return time_msec();
// panic("sys_time_msec not implemented");
}
// 3
case SYS_time_msec:
return sys_time_msec();
这段程序实现了处理定时器中断的功能以及用户态系统调用 sys_time_msec()。
- 第一个部分(标记为 "1")处理定时器中断。当定时器中断发生时,系统调用
time_tick()来更新系统时间,然后调用sched_yield()来触发调度器的重新调度,以确定是否需要切换到另一个进程执行。最后,使用lapic_eoi()来向 8259A 中断控制器发送 End of Interrupt(EOI)信号,以确认已经处理了中断。 - 第二个部分(标记为 "2")是内核中的一个系统调用
sys_time_msec()的实现。这个系统调用的功能是获取当前系统时间(以毫秒为单位)。在这个实现中,它调用了time_msec()函数,该函数返回当前系统的运行时间(以毫秒为单位)。 - 第三个部分(标记为 "3")是在系统调用处理程序中的一个分支,用于处理用户程序发起的
SYS_time_msec系统调用。当用户程序调用SYS_time_msec时,内核会调用sys_time_msec()函数来获取当前系统时间,并将结果返回给用户程序。
The Network Interface Card
编写驱动需要很深的硬件以及硬件接口知识,本lab会提供一些E1000比较表层的知识,你需要学会看E1000的开发者手册。
Exercise 2.
浏览Intel的E1000软件开发手册。该手册涵盖了几个密切相关的以太网控制器,而QEMU则模拟了82540EM。
你应该现在浏览一下第2章,以对这个设备有所了解。为了编写你的驱动程序,你需要熟悉第3章、第14章,以及第4.1章(虽然不需要4.1章的子章节)。你还需要将第13章作为参考。其他章节主要涵盖了E1000的各个组件,你的驱动程序不需要与这些组件进行交互。现在不必担心细节,只需要对文档的结构有所了解,以便以后查找信息。
在阅读手册时,请记住E1000是一个功能强大的设备,具有许多先进的功能。一个有效的E1000驱动程序只需要使用网卡提供的一小部分功能和接口。仔细考虑与该卡进行接口的最简单方式。我们强烈建议在利用高级功能之前,先让基本驱动程序正常工作。
PCI Interface
-
PCI设备
PCI (Peripheral Component Interconnect) 设备是计算机系统中的一种常见外部设备接口标准。它是一种用于连接各种硬件设备(如网卡、显卡、声卡、存储控制器等)到计算机主板上的总线标准。PCI总线标准最早由Intel公司引入,并在后来的发展中不断演化和改进。
PCI设备通常是通过PCI插槽或PCI扩展卡的形式安装在计算机主板上。这些设备通过PCI总线与主板上的CPU和内存进行通信,以实现各种输入/输出功能。PCI设备通常包括一个或多个设备功能,每个功能都有自己的唯一标识。
PCI设备具有许多优点,包括高性能、可扩展性、广泛的支持和热插拔功能。它们通常在现代计算机系统中被广泛使用,为计算机提供了与外部设备进行数据交换的能力。PCI标准已经演化为PCI Express (PCIe) 标准,它是一种更快速、更高带宽的总线标准,用于连接现代计算机的各种外部设备。
E1000是PCI设备,意味着E1000将插到主板上的PCI总线上。PCI总线有地址,数据,中断线允许CPU和PCI设备进行交互。PCI设备在被使用前需要被发现和初始化。发现的过程是遍历PCI总线寻找相应的设备。初始化的过程是分配I/O和内存空间,包括协商IRQ线。
我们已经在kern/pic.c中提供了PCI代码。为了在启动阶段初始化PCI,PCI代码遍历PCI总线寻找设备,当它找到一个设备,便会读取该设备的厂商ID和设备ID,然后使用这两个值作为键搜索pci_attach_vendor数组,该数组由struct pci_driver结构组成。struct pci_driver结构如下:
struct pci_driver {
uint32_t key1, key2;
int (*attachfn) (struct pci_func *pcif);
};
如果找到一个struct pci_driver结构,PCI代码将会执行struct pci_driver结构的attachfn函数指针指向的函数执行初始化。attachfn函数指针指向的函数传入一个struct pci_func结构指针。struct pci_func结构的结构如下:
struct pci_func {
struct pci_bus *bus;
uint32_t dev;
uint32_t func;
uint32_t dev_id;
uint32_t dev_class;
uint32_t reg_base[6];
uint32_t reg_size[6];
uint8_t irq_line;
};
其中reg_base数组保存了内存映射I/O的基地址, reg_size保存了以字节为单位的大小。 irq_line包含了IRQ线。
当attachfn函数指针指向的函数执行后,该设备就算被找到了,但还没有启用,attachfn函数指针指向的函数应该调用pci_func_enable(),该函数启动设备,协商资源,并且填充传入的struct pci_func结构。
上面的结构反映了开发手册第4.1节表4-1中的一些条目。struct pci_func的最后三个条目对我们非常重要,因为它们记录了设备的已协商的内存、I/O和中断资源。reg_base和reg_size数组包含了多达六个Base Address Registers(BARs)或基址寄存器的信息。reg_base存储了内存映射I/O区域的基本内存地址(或I/O端口资源的基本I/O端口),reg_size包含与reg_base相对应的基本值的字节数或I/O端口的数量,而irq_line包含了分配给设备的中断的IRQ线。E1000 BARs的具体含义在表4-2的下半部分给出。
当调用设备的attach函数时,设备已被找到但尚未启用。这意味着PCI代码尚未确定分配给设备的资源,如地址空间和IRQ线,因此struct pci_func结构的最后三个元素尚未填充。attach函数应该调用pci_func_enable,这将启用设备,协商这些资源,并填充struct pci_func。
Exercise 3.
实现一个附加函数来初始化E1000。在kern/pci.c中的pci_attach_vendor数组中添加一个条目,以触发你的函数,如果找到匹配的PCI设备(确保将它放在标记表结束的{0, 0, 0}条目之前)。你可以在第5.2节中找到QEMU模拟的82540EM的供应商ID和设备ID。当JOS在启动时扫描PCI总线时,你也应该看到它们列在其中。
目前,只需通过pci_func_enable来启用E1000设备。我们将在整个实验中添加更多的初始化。
我们已经为你提供了kern/e1000.c和kern/e1000.h文件,以便你不需要修改构建系统。它们目前是空白的;你需要在这个练习中填写它们。你可能还需要在内核的其他地方包含e1000.h文件。
当你启动你的内核时,你应该会看到它打印出E1000卡的PCI功能已启用。你的代码现在应该通过make grade的pci attach测试。
kern/e1000.c:
int
e1000_attachfn(struct pci_func *pcif)
{
pci_func_enable(pcif);
return 0;
}
kern/pci.c:
struct pci_driver pci_attach_vendor[] = {
{ E1000_VENDER_ID_82540EM, E1000_DEV_ID_82540EM, &e1000_attachfn },
{ 0, 0, 0 },
};
pci_func是在哪存储的
pci_func 通常是指在 Linux 内核中用于表示一个 PCI 设备功能的结构体。这个结构体是在内核源代码中定义的,通常位于与 PCI 相关的代码文件中,如 include/linux/pci.h。
在 Linux 内核中,pci_func 结构体用于描述 PCI 总线上的一个设备功能,包括设备的各种属性和状态信息。它通常与 PCI 设备驱动程序交互,用于管理和配置 PCI 设备。
如果你有具体的编程或实现问题,或者需要更多关于 pci_func 的细节,请提供更多的上下文或具体问题,这样我可以提供更准确的帮助。
过程总结
pci_driver pci_attach_vendor[]这个里面存储着,现在支持的东西
为了在启动阶段初始化PCI,PCI代码遍历PCI总线寻找设备,当它找到一个设备,便会读取该设备的厂商ID和设备ID,然后使用这两个值作为键搜索pci_attach_vendor数组。搜索到了就会,当attachfn函数指针指向的函数执行后,该设备就算被找到了,但还没有启用,attachfn函数指针指向的函数应该调用pci_func_enable(),该函数启动设备,协商资源,并且填充传入的struct pci_func结构。
Memory-mapped I/O
软件通过内存映射I/O(MMIO)与E1000通信。在JOS中,你之前已经见过两次这种情况:CGA控制台和LAPIC都是通过写入和读取“内存”来控制和查询的设备。但是这些读写操作并不是针对DRAM;它们直接与这些设备交互。
-
DRAM
DRAM(动态随机存取内存,Dynamic Random Access Memory)是一种常见的计算机内存类型,用于存储计算机处理器可以直接访问的数据和程序代码。DRAM 是大多数现代计算机和其他电子设备中使用的主要内存形式。它的特点包括:
- 动态存储:DRAM 存储数据在微小的电容中,这些电容会随着时间逐渐失去电荷。因此,为了保持数据的完整性,DRAM 需要定期刷新(重新充电)。
- 随机存取:DRAM 允许对任何存储单元的直接访问,这意味着存取时间大致相同,不管访问哪个地址。
- 易失性:DRAM 在断电后无法保持数据,这意味着一旦电源关闭,存储在其中的所有信息都会丢失。
- 高密度和低成本:与其他类型的内存相比,DRAM 提供了更高的存储密度和较低的成本,这使其成为大容量存储的理想选择。
DRAM 通常用于执行当前正在运行的程序和处理的数据,这使得计算机可以快速访问这些信息。然而,由于它的易失性和需要定期刷新的特性,DRAM 不适合长期数据存储,这通常由硬盘驱动器或固态驱动器(非易失性存储)来处理。
pci_func_enable 与E1000协商一个MMIO区域,并将其基址和大小存储在BAR 0中(即 reg_base[0] 和 reg_size[0])。这是分配给设备的一段物理内存地址范围,这意味着你需要做一些操作才能通过虚拟地址访问它。由于MMIO区域被分配了非常高的物理地址(通常在3GB以上),你不能使用KADDR来访问它,因为JOS的限制是256MB。因此,你需要创建一个新的内存映射。我们将使用位于MMIOBASE之上的区域(你在实验室4中的 mmio_map_region 会确保我们不会覆盖LAPIC使用的映射)。由于PCI设备初始化发生在JOS创建用户环境之前,你可以在 kern_pgdir 中创建映射,并且它将始终可用。
-
对上面那段话的解释
这段话描述的是在某些操作系统或计算机体系结构中,如何通过内存映射输入/输出(MMIO)与特定的硬件设备(在这个例子中是 E1000 网络接口卡)进行交互。这里的关键概念包括:
- 内存映射I/O(MMIO):这是一种机制,允许CPU通过常规的内存访问指令来控制硬件设备。在这种机制下,设备的控制寄存器被映射到进程的地址空间中的某个区域。程序可以通过读写这些地址来读写设备的控制寄存器,就像访问普通内存一样。
- E1000 交互:E1000 指的是一种网络接口卡(NIC),它支持通过 MMIO 进行通信。
- PCI 功能使能(pci_func_enable):这是一个函数,用于配置 PCI 设备(如 E1000)以使用 MMIO。这个函数将设备的 MMIO 区域地址和大小配置到 PCI 设备的基地址寄存器(BAR)中,特别是 BAR 0。这里的
reg_base[0]和reg_size[0]分别表示 MMIO 区域的基地址和大小。 - 物理地址与虚拟地址:物理地址是硬件设备实际使用的地址,而虚拟地址是操作系统为程序提供的地址。由于程序通常不能直接访问物理地址,因此需要在操作系统内核中创建一个内存映射,将这些物理地址映射到虚拟地址空间,以便程序可以通过虚拟地址来访问和控制硬件设备。
简而言之,这段话说明了如何在操作系统中设置和使用 MMIO 来与一个 PCI 设备(如 E1000)进行交互。这包括使用
pci_func_enable函数配置设备,以及在内核中设置内存映射,以便程序可以通过虚拟地址来控制设备。 -
LAPIC
LAPIC (Local Advanced Programmable Interrupt Controller) 是一种高级可编程中断控制器,它存在于现代多核处理器的每个核心中。LAPIC 的主要作用是管理和控制处理器上的中断请求(IRQs),它对提高计算机系统的中断处理能力和效率起着重要作用。具体来说,LAPIC 的功能包括:
- 中断分发:LAPIC 负责接收来自系统的中断请求,并根据预设的策略将这些中断分发给特定的处理器核心。
- 中断优先级管理:它可以根据中断的优先级来处理中断请求,确保高优先级的中断先得到处理。
- 处理器间通信:LAPIC 支持处理器间的信号发送,这对于多核处理器系统中的同步和协调操作非常重要。
在操作系统中,对 LAPIC 的编程和使用通常涉及到内存映射I/O(MMIO)。这意味着 LAPIC 的控制寄存器被映射到一段特定的内存地址区域中,操作系统通过读写这些内存地址来控制 LAPIC。例如,在实验室环境或学术研究中,通常需要编写特定的函数来支持这种映射,以便于对 LAPIC 进行有效的控制和管理。
Exercise 4.
在你的附加函数中,通过调用
mmio_map_region(你在实验室 4 中编写以支持映射 LAPIC 的函数)为 E1000 的基地址寄存器 0 (BAR 0) 创建一个虚拟内存映射。你需要记录这个映射的位置到一个变量中,以便之后可以访问你刚刚映射的寄存器。看看
kern/lapic.c中的lapic变量,这是一种记录这种映射的方法。如果你确实使用了指向设备寄存器映射的指针,请确保将其声明为volatile;否则,编译器被允许缓存值和重新排序对这块内存的访问。为了测试你的映射,尝试打印出设备状态寄存器(参见第 13.4.2 节)。这是一个从寄存器空间的第 8 个字节开始的 4 字节寄存器。你应该得到 0x80080783,这表示全双工链路以 1000 MB/s 的速度运行,以及其他信息。
volatile void *bar_va;
#define E1000REG(offset) (void *)(bar_va + offset)
int
e1000_attachfn(struct pci_func *pcif)
{
pci_func_enable(pcif);
bar_va = mmio_map_region(pcif->reg_base[0], pcif->reg_size[0]); //mmio_map_region()这个函数之前已经在kern/pmap.c中实现了。
//该函数从线性地址MMIOBASE开始映射物理地址pa开始的size大小的内存,并返回pa对应的线性地址。
uint32_t *status_reg = (uint32_t *)E1000REG(E1000_STATUS);
assert(*status_reg == 0x80080783);
return 0;
}
提示:你将需要很多常量,比如寄存器的位置和位掩码的值。试图从开发者手册中复制这些常量是容易出错的,而且错误可能导致痛苦的调试过程。我们建议使用 QEMU 的 e1000_hw.h 头文件作为指导。我们不建议逐字复制它,因为它定义了远远超过你实际需要的内容,而且可能没有以你需要的方式定义,但它是一个很好的起点。
DMA
什么是DMA?简单来说就是允许外部设备直接访问内存,而不需要CPU参与。
https://en.wikipedia.org/wiki/Direct_memory_access
我们可以通过读写E1000的寄存器来发送和接收数据包,但是这种方式非常慢。E1000使用DMA直接读写内存,不需要CPU参与。驱动负责分配内存作为发送和接受队列,设置DMA描述符,配置E1000这些队列的位置,之后的操作都是异步的。
发送一个数据包:驱动将该数据包拷贝到发送队列中的一个DMA描述符中,通知E1000,E1000从发送队列的DMA描述符中拿到数据发送出去。
接收数据包:E1000将数据拷贝到接收队列的一个DMA描述符中,驱动可以从该DMA描述符中读取数据包。
发送和接收队列非常相似,都由DMA描述符组成,DMA描述符的确切结构不是固定的,但是都包含一些标志和包数据的物理地址。发送和接收队列可以由环形数组实现,都有一个头指针和一个尾指针。
这些数组的指针和描述符中的包缓冲地址都应该是物理地址,因为硬件操作DMA读写物理内存不需要通过MMU。
Transmitting Packets
E1000 的传输和接收功能基本上是相互独立的,所以我们可以一次专注于一个。我们首先着手处理数据包的传输,因为在发送“我在这里!”数据包之前,我们无法测试接收功能。
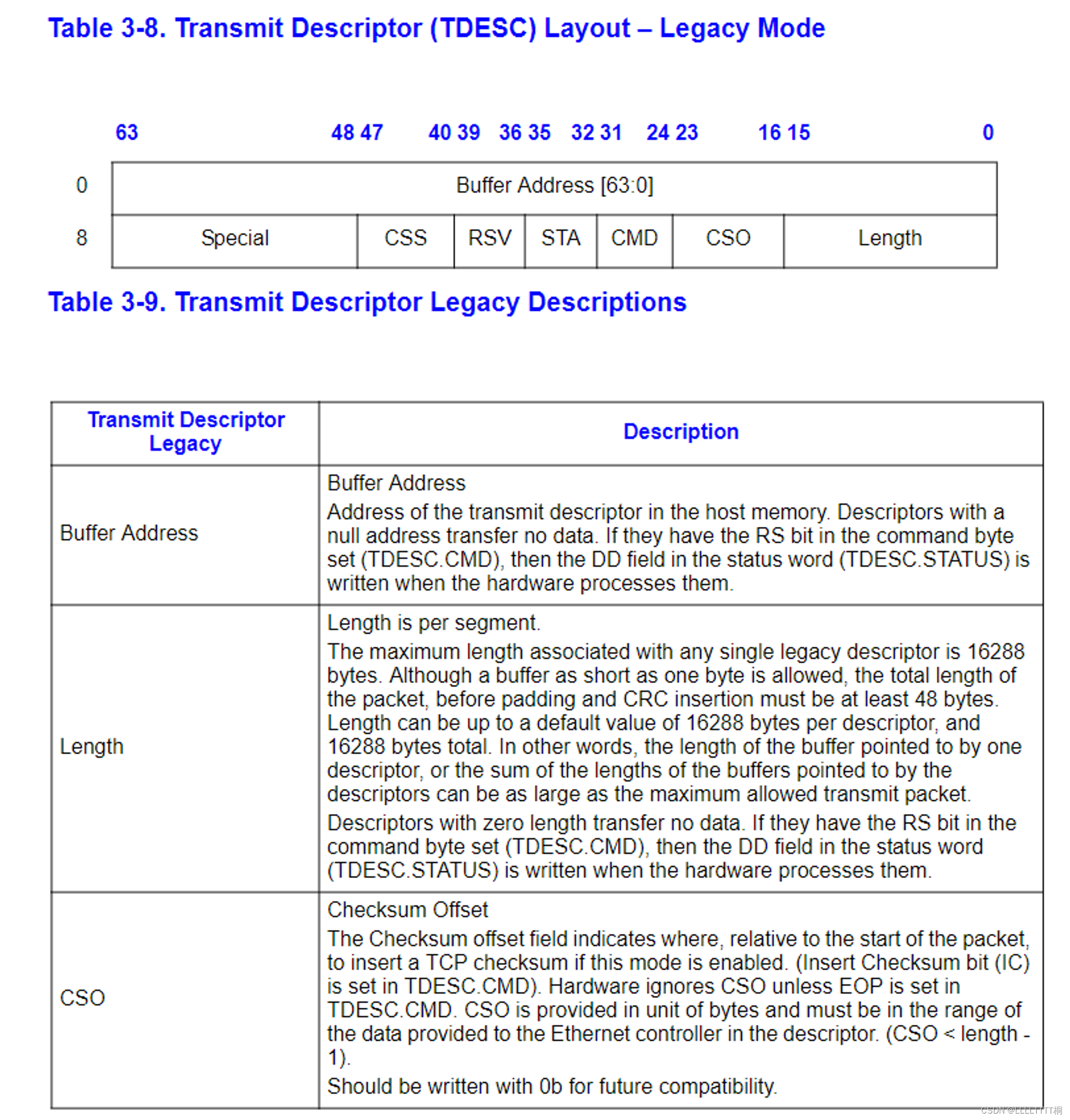
首先,你需要按照第 14.5 节描述的步骤初始化网卡以进行传输(不必担心小节中的细节)。传输初始化的第一步是设置传输队列。队列的具体结构在第 3.4 节描述,而描述符的结构在第 3.3.3 节描述。我们不会使用 E1000 的 TCP 卸载功能,所以你可以专注于“传统传输描述符格式”。你现在应该阅读这些部分,并熟悉这些结构。
第一步是建立发送队列,队列的具体结构在3.4节,描述符的结构在3.3.3节。驱动必须为发送描述符数组和数据缓冲区域分配内存。有多种方式分配数据缓冲区。最简单的是在驱动初始化的时候就为每个描述符分配一个对应的数据缓冲区。最大的包是1518字节。
-
发送队列和发送队列描述符

C Structures
你会发现使用 C 语言的结构体(structs)来描述 E1000 的结构是很方便的。就像你之前见过的像 struct Trapframe 这样的结构体一样,C 语言的结构体允许你在内存中精确地布局数据。虽然 C 语言可能在字段之间插入填充,但 E1000 的结构布局得很好,这通常不会成问题。如果你确实遇到了字段对齐问题,可以考虑使用 GCC 的“packed”属性。
作为一个例子,考虑手册中表 3-8 所给出的传统传输描述符,并在这里复制一下:
63 48 47 40 39 32 31 24 23 16 15 0
+---------------------------------------------------------------+
| Buffer address |
+---------------+-------+-------+-------+-------+---------------+
| Special | CSS | Status| Cmd | CSO | Length |
+---------------+-------+-------+-------+-------+---------------+
这个结构的第一个字节从右上角开始,因此要将其转换成 C 语言的结构体,需要从右向左、从上至下阅读。如果你仔细观察,你会发现所有的字段甚至都能很好地适应标准大小的类型:
struct tx_desc
{
uint64_t addr;
uint16_t length;
uint8_t cso;
uint8_t cmd;
uint8_t status;
uint8_t css;
uint16_t special;
};
你的驱动程序需要为传输描述符数组和传输描述符指向的数据包缓冲区预留内存。实现这一点有多种方法,从动态分配页面到简单地在全局变量中声明它们。无论你选择哪种方法,请记住,E1000 直接访问物理内存,这意味着它访问的任何缓冲区都必须在物理内存中是连续的。
处理数据包缓冲区也有多种方式。我们推荐从最简单的方式开始,即在驱动初始化期间为每个描述符预留一个数据包缓冲区,并简单地将数据包数据复制进出这些预分配的缓冲区。以太网数据包的最大大小为 1518 字节,这限定了这些缓冲区需要多大。更复杂的驱动程序可以动态分配数据包缓冲区(例如,当网络使用率低时减少内存开销),或者甚至直接传递由用户空间提供的缓冲区(一种称为“零拷贝”的技术),但从简单开始是好的。
Exercise 5.
执行第 14.5 节(但不包括其子节)中描述的初始化步骤。使用第 13 节作为初始化过程中涉及的寄存器的参考,以及第 3.3.3 节和第 3.4 节作为传输描述符和传输描述符数组的参考。
注意传输描述符数组的对齐要求和这个数组长度的限制。由于 TDLEN 必须是 128 字节对齐,而每个传输描述符为 16 字节,因此你的传输描述符数组将需要 8 的倍数的传输描述符。但是,不要使用超过 64 个描述符,否则我们的测试将无法测试传输环溢出。
对于 TCTL.COLD,你可以假设是全双工操作。对于 TIPG,参考第 13.4.34 节中表 13-77 所描述的 IEEE 802.3 标准 IPG 的默认值(不要使用第 14.5 节中的表格中的值)。
要进行的操作
- 分配一块内存用作发送描述符队列,起始地址要16字节对齐。用基地址填充(TDBAL/TDBAH) 寄存器。
- 设置(TDLEN)寄存器,该寄存器保存发送描述符队列长度,必须128字节对齐。
- 设置(TDH/TDT)寄存器,这两个寄存器都是发送描述符队列的下标。分别指向头部和尾部。应该初始化为0。
- 初始化TCTL寄存器。设置TCTL.EN位为1,设置TCTL.PSP位为1。设置TCTL.CT为10h。设置TCTL.COLD为40h。
- 设置TIPG寄存器。
struct e1000_tdh *tdh;
struct e1000_tdt *tdt;
struct e1000_tx_desc tx_desc_array[TXDESCS];
char tx_buffer_array[TXDESCS][TX_PKT_SIZE];
static void
e1000_transmit_init()
{
int i;
// 初始化传输描述符数组
for (i = 0; i < TXDESCS; i++) {
tx_desc_array[i].addr = PADDR(tx_buffer_array[i]); // 设置每个描述符的缓冲区地址 虚拟到物理
tx_desc_array[i].cmd = 0; // 初始化命令字段
tx_desc_array[i].status |= E1000_TXD_STAT_DD; // 设置状态字段
}
// 设置队列长度寄存器
struct e1000_tdlen *tdlen = (struct e1000_tdlen *)E1000REG(E1000_TDLEN);
tdlen->len = TXDESCS; // 设置传输描述符数组的长度
// 设置队列基址低32位
uint32_t *tdbal = (uint32_t *)E1000REG(E1000_TDBAL);
*tdbal = PADDR(tx_desc_array); // 设置传输描述符数组的物理基址的低32位
// 设置队列基址高32位
uint32_t *tdbah = (uint32_t *)E1000REG(E1000_TDBAH);
*tdbah = 0; // 设置传输描述符数组的物理基址的高32位
// 设置头指针寄存器
tdh = (struct e1000_tdh *)E1000REG(E1000_TDH);
tdh->tdh = 0; // 初始化传输描述符头指针
// 设置尾指针寄存器
tdt = (struct e1000_tdt *)E1000REG(E1000_TDT);
tdt->tdt = 0; // 初始化传输描述符尾指针
// 配置 TCTL 寄存器
struct e1000_tctl *tctl = (struct e1000_tctl *)E1000REG(E1000_TCTL);
tctl->en = 1; // 启用传输
tctl->psp = 1; // 启用填充保存
tctl->ct = 0x10; // 冲突阈值
tctl->cold = 0x40; // 全双工操作的冷启动阈值
// 配置 TIPG 寄存器
struct e1000_tipg *tipg = (struct e1000_tipg *)E1000REG(E1000_TIPG);
tipg->ipgt = 10; // IPG 传输延迟
tipg->ipgr1 = 4; // 第一个重传间隔
tipg->ipgr2 = 6; // 第二个重传间隔
}
是的,这些寄存器都是网卡的寄存器,更具体地说,是 E1000 网络接口卡(网卡)的寄存器。在这段代码中,通过配置这些寄存器来初始化和控制网卡的传输功能。每个寄存器都有特定的作用:
- TDLEN (Transmit Descriptor Length):这个寄存器定义了传输描述符数组的大小。
- TDBAL/TDBAH (Transmit Descriptor Base Address Low/High):这两个寄存器共同定义了传输描述符数组在物理内存中的位置。由于地址可能超过 32 位,因此通常需要两个寄存器来存储低位(TDBAL)和高位(TDBAH)。
- TDH (Transmit Descriptor Head):这个寄存器指向传输描述符数组中当前正在处理的描述符。
- TDT (Transmit Descriptor Tail):这个寄存器指向传输描述符数组中下一个要处理的描述符。
- TCTL (Transmit Control):这个寄存器用于控制传输操作的各种参数,如传输使能、填充策略、冲突阈值等。
- TIPG (Transmit Inter Packet Gap):这个寄存器控制数据包之间的间隔时间,用于符合以太网标准的发送间隔。
这些寄存器是网络卡硬件的一部分,通过编程这些寄存器,驱动程序能够控制网络卡的行为,如发送数据包等。在网络驱动开发中,了解并正确使用这些寄存器是非常重要的。
现在传输功能已经初始化,你需要编写代码来传输数据包,并通过系统调用使其对用户空间可用。要传输一个数据包,你需要将它添加到传输队列的尾部,这意味着将数据包数据复制到下一个数据包缓冲区,然后更新 TDT(传输描述符尾部)寄存器,通知网卡传输队列中有另一个数据包。(注意,TDT 是传输描述符数组的索引,而不是字节偏移量;文档在这点上说明得不是很清楚。)
然而,传输队列的大小是有限的。如果网卡传输数据包落后,导致传输队列满了怎么办?为了检测这种情况,你需要从 E1000 获取一些反馈。不幸的是,你不能仅仅使用 TDH(传输描述符头部)寄存器;文档明确指出,从软件读取这个寄存器是不可靠的。但是,如果你在传输描述符的命令字段中设置了 RS 位,那么当网卡传输了该描述符中的数据包时,网卡将在描述符的状态字段中设置 DD 位。如果一个描述符的 DD 位被设置,你就知道可以安全地回收该描述符,并用它来传输另一个数据包。
如果用户调用了你的传输系统调用,但下一个描述符的 DD 位没有被设置,表明传输队列已满,你该怎么办?在这种情况下,你需要决定如何处理。你可以简单地丢弃数据包。网络协议对此具有一定的韧性,但如果你丢弃了大量的数据包,协议可能无法恢复。你也可以告诉用户环境它需要重试,就像你在 sys_ipc_try_send 中所做的那样。这样做的好处是对生成数据的环境产生反压。
**Exercise 6.**编写一个函数来传输数据包,通过检查下一个描述符是否空闲,将数据包数据复制到下一个描述符中,并更新 TDT 寄存器。确保你处理了传输队列已满的情况。
int
e1000_transmit(void *data, size_t len)
{
uint32_t current = tdt->tdt; // 当前传输描述符尾部索引
// 检查当前描述符的 DD 位是否设置,以确认是否可用
if(!(tx_desc_array[current].status & E1000_TXD_STAT_DD)) {
return -E_TRANSMIT_RETRY; // 如果不可用,返回重试的信号
}
// 设置当前传输描述符的长度和命令
tx_desc_array[current].length = len; // 设置数据包长度
tx_desc_array[current].status &= ~E1000_TXD_STAT_DD; // 清除 DD 位,准备传输
tx_desc_array[current].cmd |= (E1000_TXD_CMD_EOP | E1000_TXD_CMD_RS); // 设置 EOP 和 RS 位
// 将数据包复制到相应的缓冲区
memcpy(tx_buffer_array[current], data, len); // 复制数据到缓冲区
// 更新 TDT 寄存器,将尾部索引移到下一个描述符
uint32_t next = (current + 1) % TXDESCS; // 计算下一个描述符的索引
tdt->tdt = next; // 更新 TDT 寄存器
return 0; // 传输成功
}
这个函数的主要作用是将一个待发送的数据包加入到 E1000 的传输队列中。它首先检查当前的传输描述符是否可用(通过检查 DD 位),然后设置描述符的长度和命令,将数据复制到对应的缓冲区,并更新传输描述符尾部寄存器 (TDT)。如果当前描述符不可用(即传输队列已满),函数返回一个重试的错误码。
-
示意图
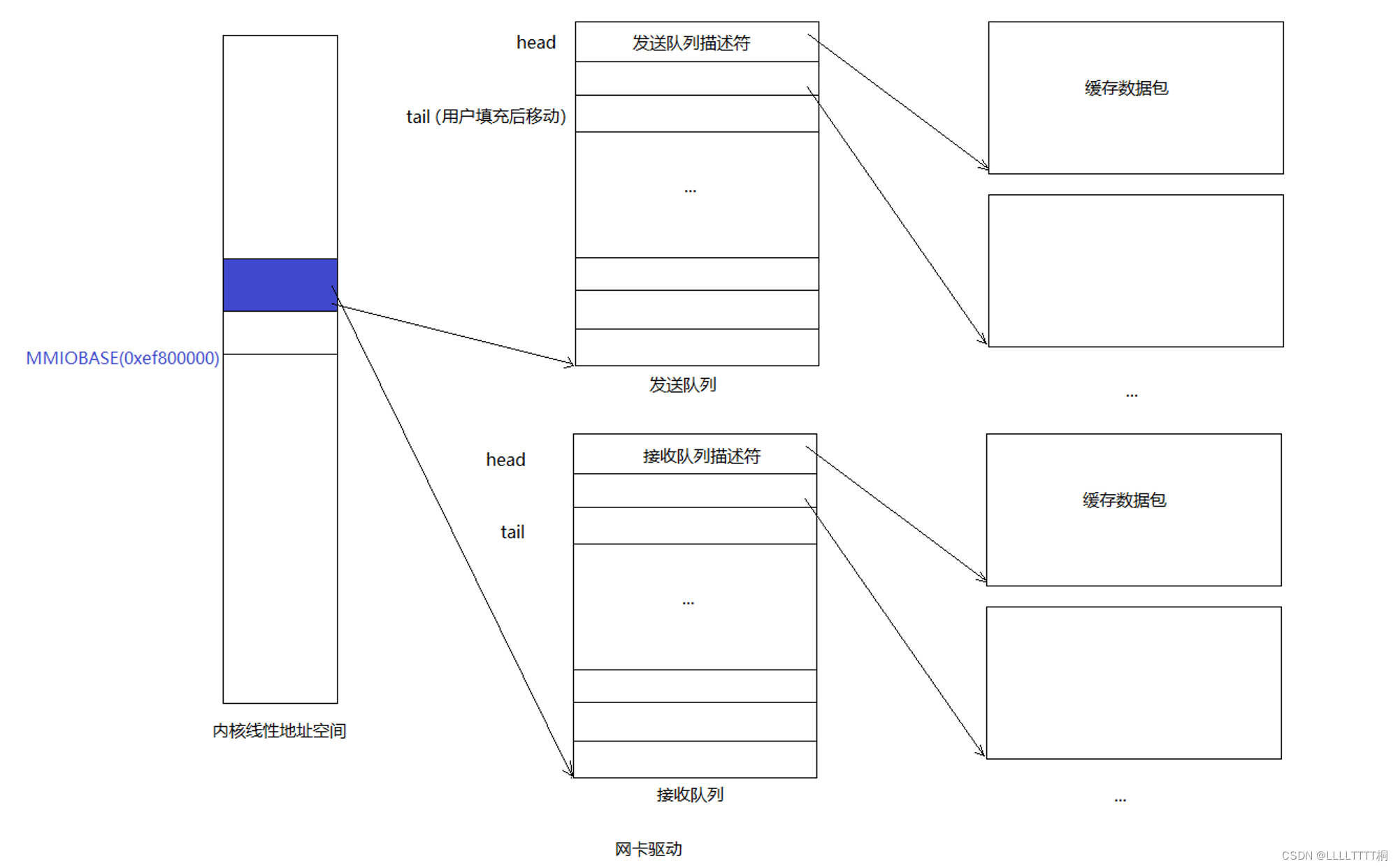
在您提供的图中,我们看到两个关键的数据结构:描述符队列和缓冲区队列。
- 描述符队列(在图中标为“发送队列描述符”和“接收队列描述符”):这些队列包含了多个描述符条目,每个描述符都对应一个数据包的发送或接收。在代码中,这个队列对应于
tx_desc_array[TXDESCS],其中TXDESCS是队列中描述符的数量。 - 缓冲区队列(在图中紧跟在每个描述符后面的大方框,标为“缓存数据包”):这些是实际存储网络数据包内容的内存区域。在代码中,这对应于
tx_buffer_array[TXDESCS][TX_PKT_SIZE],其中TXDESCS是缓冲区的数量,TX_PKT_SIZE是每个缓冲区可以存储的单个数据包的最大大小。
在图中,每个发送或接收描述符都与一个相应的缓冲区相关联。描述符包含了缓冲区物理地址的指针、状态位、命令位等信息,而缓冲区实际存储了网络数据包的内容。当网络接口卡(NIC)准备发送或接收数据包时,它会查看描述符队列来确定数据包的位置以及如何处理它们。
对于发送队列来说是一个典型的生产者-消费者模型:
- 生产者:用户进程。通过系统调用往tail指向的描述符的缓存区添加包数据,并且移动tail。
- 消费者:网卡。通过DMA的方式直接从head指向的描述符对应的缓冲区拿包数据发送出去,并移动head。接收队列也类似。
- 描述符队列(在图中标为“发送队列描述符”和“接收队列描述符”):这些队列包含了多个描述符条目,每个描述符都对应一个数据包的发送或接收。在代码中,这个队列对应于
Exercise 7. 添加一个系统调用,允许你从用户空间传输数据包。具体的接口由你决定。不要忘记检查任何从用户空间传递到内核的指针。
int
sys_pkt_try_send(void * buf, size_t len)
{
user_mem_assert(curenv, buf, len, PTE_U);
return e1000_transmit(buf, len);
}
case SYS_pkt_try_send:
return sys_pkt_try_send((void *) a1, (size_t) a2);
Transmitting Packets: Network Server
现在你已经为设备驱动程序的发送端添加了系统调用接口,是时候发送数据包了。输出辅助环境的目标是在一个循环中执行以下操作:接收来自核心网络服务器的 NSREQ_OUTPUT IPC 消息,并使用你上面添加的系统调用将这些 IPC 消息附带的数据包发送到网络设备驱动程序。NSREQ_OUTPUT IPC 由 net/lwip/jos/jif/jif.c 中的 low_level_output 函数发送,该函数将 lwIP 堆栈与 JOS 的网络系统连接起来。每个 IPC 将包括一个页面,其中包含一个 Nsipc 联合体,以及位于其 struct jif_pkt pkt 字段中的数据包(见 inc/ns.h)。struct jif_pkt 的结构如下:
struct jif_pkt {
int jp_len;
char jp_data[0];
};
jp_len 表示数据包的长度。IPC 页面上的所有后续字节都专用于数据包内容。在结构体末尾使用像 jp_data 这样的零长度数组是一种常见的 C 语言技巧(有些人可能认为这是一种怪异的用法),用于表示没有预先确定长度的缓冲区。只要确保在结构体后面有足够的未使用内存,你就可以将 jp_data 当作任意大小的数组来使用。
需要注意的是,当设备驱动程序的传输队列没有更多空间时,设备驱动程序、输出环境和核心网络服务器之间的交互。核心网络服务器使用 IPC 向输出环境发送数据包。如果输出环境因为发送数据包系统调用而被挂起(因为驱动程序没有更多的缓冲区空间用于新数据包),核心网络服务器将阻塞,等待输出服务器接受 IPC 调用。
Exercise 8. Implement net/output.c.
void
output(envid_t ns_envid)
{
binaryname = "ns_output";
// LAB 6: Your code here:
// - read a packet from the network server
// - send the packet to the device driver
uint32_t whom;
int perm;
int32_t req;
while (1) {
req = ipc_recv((envid_t *)&whom, &nsipcbuf, &perm); //接收核心网络进程发来的请求
if (req != NSREQ_OUTPUT) {
cprintf("not a nsreq output\\n");
continue;
}
struct jif_pkt *pkt = &(nsipcbuf.pkt);
while (sys_pkt_send(pkt->jp_data, pkt->jp_len) < 0) { //通过系统调用发送数据包
sys_yield();
}
}
}
NSREQ_OUTPUT 是网络服务器(Network Server)发来的请求类型之一。它表示网络服务器请求输出(Output),即请求将数据包发送到网络中。通常,网络服务器接收到需要输出的数据包后,会向输出进程发送 NSREQ_OUTPUT 请求,然后输出进程负责将这些数据包发送给实际的网络设备驱动程序,以便进行网络传输。
Question
How did you structure your transmit implementation? In particular, what do you do if the transmit ring is full?
在output中检测数据包是否发送成功,若未成功,则sched_yeild让出控制器sleep 一会儿。
发送一个数据包的流程
-
流程图
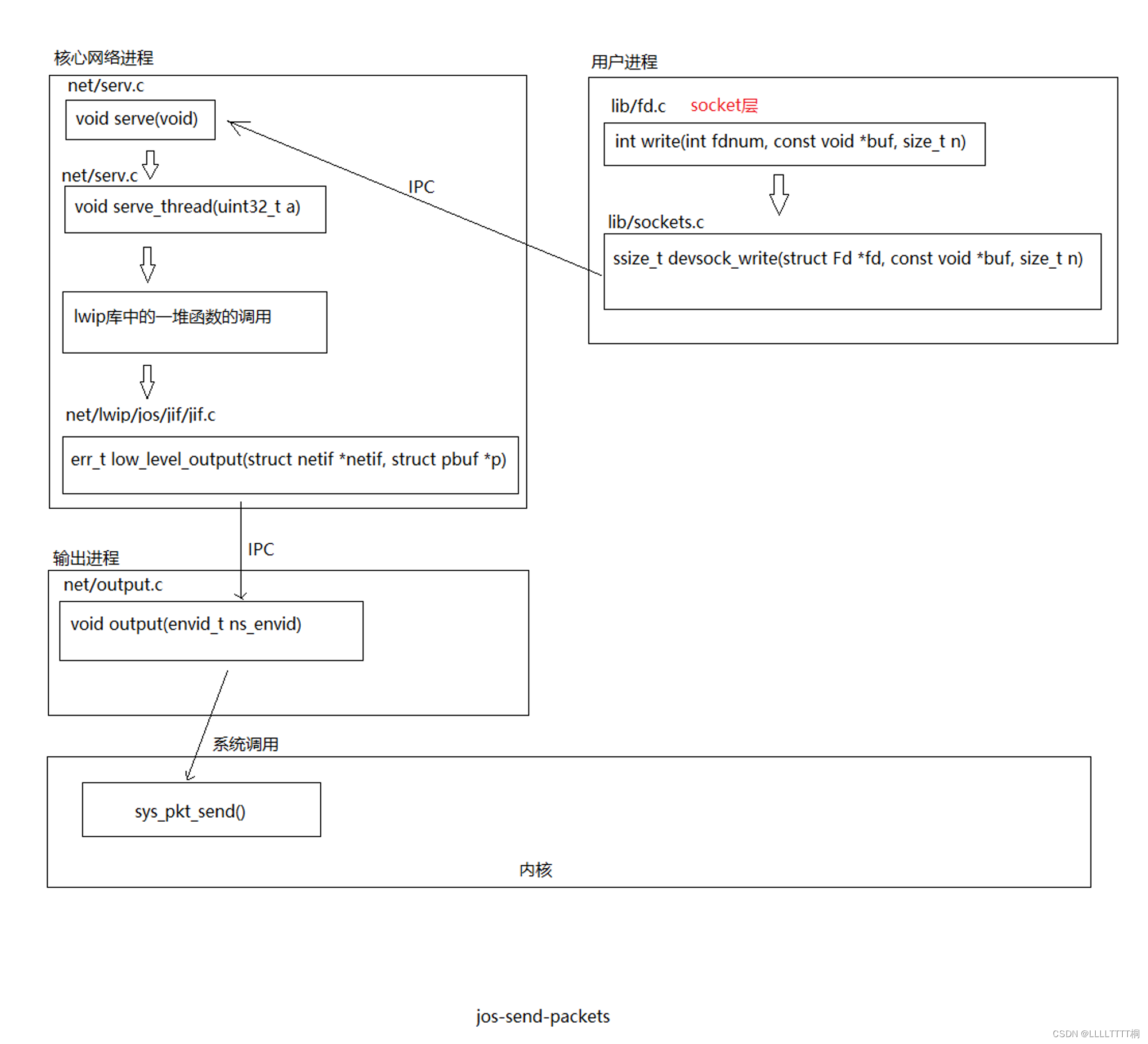
这张图描述了在 JOS 操作系统中发送一个网络包的流程,具体包括从应用层到网络驱动层的各个步骤。网络包的发送流程通常包括以下步骤:
- 应用层通过
lib/fd.c中的write函数发送数据。在这个例子中,数据可能来自于一个 socket 文件描述符。 write函数将调用转发到lib/sockets.c中的devsock_write函数,这是实现 BSD sockets API 的部分。devsock_write会通过 IPC 与网络服务器通信,请求发送数据包。- 网络服务器的
net/serv.c会通过serve和serve_thread函数处理这个请求。 - 处理函数将调用
net/lwip/jos/jif.c中的low_level_output函数,这是 lwIP 网络栈的一部分,用于将数据包准备好并放入发送队列。 - 最后,
net/output.c中的output函数通过 IPC 请求输出助手环境发送这个数据包。 - 输出助手环境调用
sys_pkt_send系统调用,这是实际与网络驱动交互的系统调用。 sys_pkt_send会将数据包放入网络接口卡(在这个例子中是 E1000)的发送缓冲区,这通常是通过 DMA (Direct Memory Access) 完成的。
整个流程结束时,网络包被发送到硬件级别的网络接口卡的发送(TX)环,等待由物理设备发送出去到网络上。所以,网络包最终被发送到了连接到服务器的网络中。
Part B: Receiving packets and the web server
Receiving Packets
就像你为发送数据包所做的那样,你也需要配置 E1000 来接收数据包,并提供一个接收描述符队列和接收描述符。第3.2节描述了数据包接收的工作原理,包括接收队列结构、接收描述符,以及初始化过程在第14.4节中有详细说明。
Exercise 9.
阅读第3.2节。你可以忽略有关中断和校验和卸载的任何内容(如果你决定以后使用这些功能,可以回到这些部分),你不需要关心阈值的细节以及网卡的内部缓存是如何工作的。
接收队列与发送队列非常相似,区别在于它由空的数据包缓冲区组成,等待着被传入的数据包填充。因此,当网络空闲时,发送队列是空的(因为所有数据包都已发送),但接收队列是满的(充满了空的数据包缓冲区)。
当 E1000 接收到一个数据包时,它首先检查数据包是否与网卡配置的过滤器相匹配(例如,查看该数据包是否发送到这个 E1000 的 MAC 地址),如果不匹配任何过滤器,它就忽略该数据包。否则,E1000 尝试从接收队列头部检索下一个接收描述符。如果头部(RDH)赶上了尾部(RDT),那么接收队列就没有空闲的描述符了,所以网卡会丢弃该数据包。如果有一个空闲的接收描述符,它会将数据包的数据复制到描述符指向的缓冲区中,设置描述符的 DD(描述符完成)和 EOP(数据包结束)状态位,并增加 RDH。
如果 E1000 接收到一个比单个接收描述符中的数据包缓冲区更大的数据包,它将从接收队列中检索所需数量的描述符以存储数据包的全部内容。为了表示这一点,它将在所有这些描述符上设置 DD 状态位,但只在最后一个描述符上设置 EOP 状态位。你可以在驱动程序中处理这种可能性,或者简单地配置网卡不接受“长数据包”(也称为巨帧),并确保你的接收缓冲区足够大,能够存储最大可能的标准以太网数据包(1518字节)。
Exercise 10.
按照第14.4节中的过程设置接收队列并配置 E1000。现在你不需要支持“长数据包”或多播。目前,不要配置网卡使用中断;如果你决定使用接收中断,以后可以改变。此外,配置 E1000 剥离以太网 CRC,因为评分脚本期望它被剥离。
默认情况下,网卡将过滤掉所有数据包。你必须使用网卡自己的 MAC 地址配置接收地址寄存器(RAL 和 RAH),以便接受发送到该网卡的数据包。你可以简单地硬编码 QEMU 默认的 MAC 地址 52:54:00:12:34:56(我们已经在 lwIP 中硬编码了这个,所以在这里做也不会使情况变得更糟)。要非常注意字节顺序;MAC 地址是从最低位字节到最高位字节编写的,所以 52:54:00:12 是 MAC 地址的低32位,34:56 是高16位。
E1000 只支持特定的接收缓冲区大小(在13.4.22节的 RCTL.BSIZE 描述中给出)。如果你使接收数据包缓冲区足够大并禁用长数据包,你就不必担心数据包跨越多个接收缓冲区。同样,记住,就像传输一样,接收队列和数据包缓冲区必须在物理内存中是连续的。
你应该至少使用128个接收描述符。
这部分与发送部分代码编写流程是类似的,查文档,为接收描述符、接收buffer 分配静态内存等,然后对接收描述符、E1000 RCTL等寄存器进行初始化。
uint32_t E1000_MAC[6] = {0x52, 0x54, 0x00, 0x12, 0x34, 0x56};
void
e1000_set_mac_addr(uint32_t mac[])
{
uint32_t low = 0, high = 0;
int i;
for (i = 0; i < 4; i++) {
low |= mac[i] << (8 * i);
}
for (i = 4; i < 6; i++) {
high |= mac[i] << (8 * i);
}
e1000[E1000_LOCATE(E1000_RA)] = low;
e1000[E1000_LOCATE(E1000_RA) + 1] = high | E1000_RAH_AV;
}
void
e1000_receive_init()
{
size_t i;
memset(rx_desc_list, 0 , sizeof(struct E1000RxDesc) * RX_DESC_SIZE);
for (i = 0; i < RX_DESC_SIZE; i++) {
rx_desc_list[i].buffer_addr = PADDR(rx_pbuf[i]);
}
// cprintf("mac addr %x:%x", e1000[E1000_LOCATE(E1000_RA)], e1000[E1000_LOCATE(E1000_RA) + 1] );
e1000[E1000_LOCATE(E1000_ICS)] = 0;
e1000[E1000_LOCATE(E1000_IMS)] = 0;
e1000[E1000_LOCATE(E1000_RDBAL)] = PADDR(rx_desc_list);
e1000[E1000_LOCATE(E1000_RDBAH)] = 0;
e1000[E1000_LOCATE(E1000_RDLEN)] = sizeof(struct E1000RxDesc) * RX_DESC_SIZE;
e1000[E1000_LOCATE(E1000_RDT)] = RX_DESC_SIZE - 1;
// 写了两遍 RDH,查了好久的BUG。
e1000[E1000_LOCATE(E1000_RDH)] = 0;
e1000[E1000_LOCATE(E1000_RCTL)] = E1000_RCTL_EN | E1000_RCTL_SECRC | E1000_RCTL_BAM | E1000_RCTL_SZ_2048;
e1000_set_mac_addr(E1000_MAC);
}
-
代码解释
这段程序是在一个网络驱动中,用于初始化 E1000 网络接口卡(NIC)的接收功能的代码。它主要由两个函数组成:
e1000_set_mac_addr和e1000_receive_init。E1000_LOCATE获得寄存器地址的函数
-
e1000_set_mac_addr(uint32_t mac[])函数负责设置 E1000 网卡的 MAC 地址。它接收一个包含 MAC 地址的数组mac,然后构造出该地址的低 32 位和高 16 位,分别设置到网络卡的接收地址寄存器(RAL 和 RAH)中。这样配置后,E1000 网卡就可以接收发送到这个 MAC 地址的数据包。 -
e1000_receive_init()函数负责初始化接收队列。它执行以下步骤:- 清零接收描述符列表
rx_desc_list,为其分配空间。 - 遍历接收描述符列表,并为每个描述符指定一个数据包缓冲区的物理地址
rx_pbuf[i]。 - 设置网络卡的中断掩码和中断设置寄存器(
E1000_IMS和E1000_ICS)为 0,这可能意味着暂时不使用中断机制。 - 设置接收描述符队列的基址(
E1000_RDBAL和E1000_RDBAH)到rx_desc_list的物理地址。 - 设置接收描述符队列的长度(
E1000_RDLEN)为描述符大小乘以描述符的数量。 - 设置接收描述符队列的尾部(
E1000_RDT)为描述符数量减一,这可能是为了初始化队列的尾部指针。 - 设置接收控制寄存器(
E1000_RCTL)以启用接收器(E1000_RCTL_EN),剥离以太网帧的 CRC(E1000_RCTL_SECRC),接收广播数据包(E1000_RCTL_BAM),并设置缓冲区大小为 2048 字节(E1000_RCTL_SZ_2048)。
最后,调用
e1000_set_mac_addr(E1000_MAC)以实际设置网卡的 MAC 地址。 - 清零接收描述符列表
简而言之,这段代码初始化 E1000 网卡以接收数据包,设置了接收描述符队列,并配置了网卡接收过滤器以接受特定的 MAC 地址。这是网络驱动开发中设置网卡接收路径的常见任务。
-
即使在没有编写接收数据包的代码之前,你现在也可以进行接收功能的基本测试。运行 make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-net_testinput。testinput 将传输一个 ARP(地址解析协议)公告数据包(使用你的数据包传输系统调用),QEMU 将自动回复。即使你的驱动程序还不能接收这个回复,你应该看到一条 "e1000: 单播匹配[0]: 52:54:00:12:34:56" 的消息,表明一个数据包被 E1000 接收并且匹配了配置的接收过滤器。如果你看到 "e1000: 单播不匹配: 52:54:00:12:34:56" 的消息,那么 E1000 过滤掉了数据包,这意味着你可能没有正确配置 RAL 和 RAH。确保你的字节顺序正确,并且没有忘记在 RAH 中设置 "地址有效" 位。如果你没有收到任何 "e1000" 消息,那么你可能没有正确启用接收。
现在你已经准备好实现接收数据包了。为了接收一个数据包,你的驱动程序将不得不跟踪预期包含下一个接收数据包的描述符(提示:根据你的设计,E1000 中可能已经有一个寄存器跟踪这个了)。类似于传输,文档说明 RDH 寄存器不能被软件可靠地读取,所以为了确定一个数据包是否已经被交付到这个描述符的数据包缓冲区,你将不得不读取描述符中的 DD 状态位。如果 DD 位被设置,你可以从该描述符的数据包缓冲区复制数据包数据,然后通过更新队列的尾部索引 RDT 告诉网卡该描述符是空闲的。
如果 DD 位没有被设置,那么没有数据包被接收。这是接收队列为空的等效情况,当传输队列满时,你可以做几件事情。你可以简单地返回一个 "再试一次" 错误,并要求调用者重试。虽然这种方法对于满的传输队列来说效果很好,因为那是一个暂时的条件,但对于空的接收队列来说就不太合理,因为接收队列可能会长时间保持空状态。第二种方法是挂起调用环境,直到接收队列中有数据包可以处理。这种策略与 sys_ipc_recv 非常相似。就像在 IPC 案例中一样,由于我们每个 CPU 只有一个内核栈,一旦我们离开内核,栈上的状态就会丢失。我们需要设置一个标志,表明一个环境已经因为接收队列下溢而被挂起,并记录系统调用参数。这种方法的缺点是复杂性:必须指示 E1000 生成接收中断,并且驱动程序必须处理它们,以便恢复因等待数据包而阻塞的环境。
Exercise 11.
编写一个函数从 E1000 接收数据包,并通过添加一个系统调用将其暴露给用户空间。确保你处理了接收队列为空的情况。
receive 的实现,最重要的一点是理解硬件接收数据包的过程:当硬件接收到数据包时,首先会进行一次过滤(对比MAC地址等),若符合接收标准,硬件会将数据包存储到我们分配的 buffer中,并同时设置描述符的DD位已经执行RDH加1操作。 所以当我们编写receive 函数时,可以选择定义一个 static 变量,用来指向第一个可接收的描述符。系统调用的实现不再详细给出,如有问题可以参看github上的源码,receive 具体实现如下.
int e1000_receive(void *buf, size_t *len)
{
static size_t next = 0; // 静态变量,用于跟踪下一个要检查的接收描述符的索引。
size_t tail = e1000[E1000_LOCATE(E1000_RDT)]; // 读取接收描述符队列尾部的当前位置。
// 检查当前描述符的状态位,看它是否包含一个已完成接收的数据包。
if ( !(rx_desc_list[next].status & E1000_RXD_STAT_DD) ) {
// 如果状态位不包含 E1000_RXD_STAT_DD(表示描述符完成),则没有数据包可接收。
return -1; // 返回 -1 表示没有数据包可供接收。
}
*len = rx_desc_list[next].length; // 从描述符中获取数据包的长度,并将其存储到提供的长度指针中。
memcpy(buf, rx_pbuf[next], *len); // 将数据包内容从接收缓冲区复制到用户提供的缓冲区中。
rx_desc_list[next].status &= ~E1000_RXD_STAT_DD; // 清除描述符的 DD 状态位,表示该描述符已处理完毕。
next = (next + 1) % RX_DESC_SIZE; // 更新下一个要检查的描述符的索引。
e1000[E1000_LOCATE(E1000_RDT)] = (tail + 1 ) % RX_DESC_SIZE; // 更新接收描述符队列的尾部指针。
cprintf("e1000_receive return 0\\n"); // 打印消息,表明函数成功执行并返回。
return 0; // 返回 0 表示成功接收数据包。
}
这个函数是网卡驱动程序中用于接收数据包的关键部分。它负责检查接收描述符队列,提取数据包,然后将其移动到用户空间的缓冲区中。通过更新描述符的状态,它还管理着接收队列的状态,确保队列能够正确地处理新的数据包。
Challenge!
如果发送队列已满或接收队列为空,环境和你的驱动程序可能会消耗大量 CPU 循环进行轮询,等待描述符。E1000 可以在完成一个传输或接收描述符后生成一个中断,避免了轮询的需要。修改你的驱动程序,使处理发送和接收队列变为基于中断驱动而不是轮询。
注意,一旦触发了中断,它会保持触发状态,直到驱动程序清除中断。在你的中断处理程序中,请确保在处理完中断后立即清除它。如果你不这样做,从中断处理程序返回后,CPU 将再次进入它。除了清除 E1000 网卡上的中断外,还需要在本地高级可编程中断控制器(LAPIC)上清除中断。使用 lapic_eoi 函数来实现这一点。
Receiving Packets: Network Server
在网络服务器输入环境中,你需要使用新的接收系统调用来接收数据包,并通过 NSREQ_INPUT IPC 消息将它们传递给核心网络服务器环境。这些 IPC 输入消息应该附带一个页面,其中包含一个填充了从网络接收到的数据包的 union Nsipc,及其 struct jif_pkt pkt 字段。
Exercise 12. Implement net/input.c.
void
sleep(int msec)
{
unsigned now = sys_time_msec();
unsigned end = now + msec;
if ((int)now < 0 && (int)now > -MAXERROR)
panic("sys_time_msec: %e", (int)now);
if (end < now)
panic("sleep: wrap");
while (sys_time_msec() < end)
sys_yield();
}
void
input(envid_t ns_envid)
{
binaryname = "ns_input";
size_t len;
char rev_buf[RX_PACKET_SIZE];
size_t i = 0;
while(1) {
// 阻塞式读
while ( sys_pkt_try_receive(rev_buf, &len) < 0) {
sys_yield();
}
memcpy(nsipcbuf.pkt.jp_data, rev_buf, len);
nsipcbuf.pkt.jp_len = len;
ipc_send(ns_envid, NSREQ_INPUT, &nsipcbuf, PTE_P|PTE_U);
sleep(50);
}
}
为了更彻底地测试我们的网络代码,源码已经提供了一个名为echosrv的守护进程,它设置一个在 port 7上运行的echo服务器,它将回显通过TCP连接发送的任何内容。我们在一个终端执行make E1000_DEBUG=TX,TXERR,RX,RXERR,RXFILTER run-echosrv 开启 echo 服务器, 在另一个终端执行 make nc-7 连接 echo 服务器。可以看到 nc 端的消息回显。
Question
你是如何构建接收实现的? 特别是,如果接收队列为空并且用户环境请求下一个传入数据包,你会怎么做?
用户请求接收时,若接受不成功(队列为空),则sched暂时让出控制权。接收成功,发送IPC,通知网络核心环境已经获得数据包,并简单sleep 50 ms,因为 网络核心环境需要时间对当前 shared 页的数据包进行处理。 当然,这样效率十分低下,我们可以考虑在Input环境中申请一定数量的页,轮流使用这个页向网络核心环境传递网络数据包。
Challenge! Read about the EEPROM in the developer's manual and write the code to load the E1000's MAC address out of the EEPROM. Currently, QEMU's default MAC address is hard-coded into both your receive initialization and lwIP. Fix your initialization to use the MAC address you read from the EEPROM, add a system call to pass the MAC address to lwIP, and modify lwIP to the MAC address read from the card. Test your change by configuring QEMU to use a different MAC address.
Challenge! Modify your E1000 driver to be "zero copy." Currently, packet data has to be copied from user-space buffers to transmit packet buffers and from receive packet buffers back to user-space buffers. A zero copy driver avoids this by having user space and the E1000 share packet buffer memory directly. There are many different approaches to this, including mapping the kernel-allocated structures into user space or passing user-provided buffers directly to the E1000. Regardless of your approach, be careful how you reuse buffers so that you don't introduce races between user-space code and the E1000.
Challenge! Take the zero copy concept all the way into lwIP.
A typical packet is composed of many headers. The user sends data to be transmitted to lwIP in one buffer. The TCP layer wants to add a TCP header, the IP layer an IP header and the MAC layer an Ethernet header. Even though there are many parts to a packet, right now the parts need to be joined together so that the device driver can send the final packet.
The E1000's transmit descriptor design is well-suited to collecting pieces of a packet scattered throughout memory, like the packet fragments created inside lwIP. If you enqueue multiple transmit descriptors, but only set the EOP command bit on the last one, then the E1000 will internally concatenate the packet buffers from these descriptors and only transmit the concatenated buffer when it reaches the EOP-marked descriptor. As a result, the individual packet pieces never need to be joined together in memory.
Change your driver to be able to send packets composed of many buffers without copying and modify lwIP to avoid merging the packet pieces as it does right now.
Challenge! Augment your system call interface to service more than one user environment. This will prove useful if there are multiple network stacks (and multiple network servers) each with their own IP address running in user mode. The receive system call will need to decide to which environment it needs to forward each incoming packet.
Note that the current interface cannot tell the difference between two packets and if multiple environments call the packet receive system call, each respective environment will get a subset of the incoming packets and that subset may include packets that are not destined to the calling environment.
Sections 2.2 and 3 in this Exokernel paper have an in-depth explanation of the problem and a method of addressing it in a kernel like JOS. Use the paper to help you get a grip on the problem, chances are you do not need a solution as complex as presented in the paper.
The Web Server
最简单形式的网络服务器会将文件的内容发送给请求的客户端。我们在 user/httpd.c 中提供了一个非常简单的网络服务器的框架代码。这个框架代码处理传入的连接并解析头部信息。
Exercise 13.
网络服务器缺少处理将文件内容发送回客户端的代码。通过实现 send_file 和 send_data 来完成网络服务器。
http_request 是一个比较重要的结构体。其包含了 socket, 也就是数据发送接收的接口。
struct http_request {
int sock;
char *url;
char *version;
};
如何判断打开的 fd 是一个目录, 要使用到fd.c中的fstat函数。其返回一个Stat 的结构体。
struct Stat {
char st_name[MAXNAMELEN];
off_t st_size;
int st_isdir;
struct Dev *st_dev;
};
-
首先编写
send_file,根据提示,在原有的代码前添加以下代码。// LAB 6: Your code here. // panic("send_file not implemented"); struct Stat st; if ( (r = open(req->url, O_RDONLY) )< 0 ) { return send_error(req, 404); } fd = r; // 怎么判断一个fd 是目录, 没有 num2fd if ( (r = fstat(fd, &st)) < 0) return send_error(req, 404); if (st.st_isdir) return send_error(req, 404); file_size = st.st_size; -
send_data函数编写。static int send_data(struct http_request *req, int fd) { // LAB 6: Your code here. // panic("send_data not implemented"); // 从fd 中读size大小数据,并发送 int r; size_t len; char buf[BUFFSIZE]; if ( (r = read(fd, buf, BUFFSIZE)) < 0 ) return -1; len = r; if ( write(req->sock, buf, len) != len) { die("Failed to send bytes to client"); } return 0; }
最后 run make run-httpd-nox,然后在虚拟机的浏览器中输入http://localhost:26002,浏览器会显示404, 然后输入http://localhost:26002/index.html,Web将会返回内容cheesy web page。
Question
What does the web page served by JOS's web server say?
用户级线程实现
用户级线程实现(User-level threading)是指在用户空间中实现的线程管理,而不是依赖于操作系统内核提供的线程管理功能。用户级线程库完全在用户空间执行,它提供了创建、销毁、调度和同步线程的能力,但不需要内核支持。
在用户级线程实现中,所有线程操作都是通过用户空间的库来管理的。这意味着,线程切换不需要内核模式切换,因此可以更快地进行,但这也有其局限性,例如一个线程的阻塞可能会阻塞整个进程,因为操作系统看不到用户级线程,它只管理进程级别的状态。
在您提供的代码片段中,描述了在 JOS 操作系统的网络库中如何实现用户级线程:
thread_init函数初始化一个全局的thread_queue,这个队列用于维护所有线程的上下文信息。thread_create函数创建一个新的线程,分配一个thread_context结构体来保存线程的状态,包括线程的栈、线程函数地址、参数等,并将其添加到线程队列中。thread_yield函数实现了线程的让步机制,它保存当前线程的状态(使用jos_setjmp),选择下一个线程运行(使用threadq_pop获取),并恢复那个线程的状态(使用jos_longjmp)以继续执行。
jos_setjmp 和 jos_longjmp 函数通常由汇编语言实现,因为它们需要直接操作 CPU 寄存器。jos_setjmp 保存当前的 CPU 寄存器状态到 jos_jmp_buf 结构中,而 jos_longjmp 则恢复这个状态,允许程序从保存点继续执行。
通过这种方式,用户级线程库提供了一种灵活的线程管理方法,允许程序设计者在不同的线程上下文之间快速切换,而不需要操作系统内核的直接干预。















 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









