







第一步 配置新得broker
- 将现有的集群上任一个服务器上的kafka目录拷贝到新的服务器上
- 修改config/server.properties中的broker.id、log.dirs、listeners
- 创建logs.dirs指定的目录,并设定读写权限(chomd -R 777 XXX)
broker.id=3
log.dirs=kafka-logs
listeners=PLAINTEXT://172.16.49.174:9092第二步 启动新的broker
bin/kafka-server-start.sh config/server.properties & 第三步 迁移指定topic的数据到新的broker
虽然经过上面两个步骤后已经完成了集群的扩容;但是集群上原有的topic的数据不会自动迁移到新的broker上。可以在新的broker所在的服务器上通过
ls /home/lxh/kafka_2.11-0.10.0.0/kafka-logs查看到并没有一原有的topic名称的文件目录(因为创建topic后会在config/server.properties中的配置的log.dirs 目录中生产以topic名称+分区编号的文件目录);那么就需要手动的区迁移数据
(一)、生成迁移分配规则json文件
创建编辑要迁移的topic的 json文件
vi topic-to-move.json 比如要将topic名称为test和paritioer_test的数据重新平衡到集群中,就可以新增以下内容
{"topics": [{"topic": "test"},
{"topic": "paritioer_test"}],
"version":1
}生成迁移分配规则json文件
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file topic-to-move.json --broker-list "0,1,2" --generate
得到的结果为
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test","partition":4,"replicas":[0,1]},{"topic":"test","partition":1,"replicas":[1,0]},{"topic":"paritioer_test","partition":0,"replicas":[0]},{"topic":"test","partition":2,"replicas":[0,1]},{"topic":"test","partition":0,"replicas":[0,1]},{"topic":"test","partition":3,"replicas":[1,0]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"test","partition":4,"replicas":[1,0]},{"topic":"test","partition":1,"replicas":[1,2]},{"topic":"test","partition":2,"replicas":[2,0]},{"topic":"paritioer_test","partition":0,"replicas":[0]},{"topic":"test","partition":0,"replicas":[0,1]},{"topic":"test","partition":3,"replicas":[0,2]}]}
其中的Current partition replica assignment指的是迁移前的partition replica;Proposed partition reassignment configuration 指的就是迁移分配规则json。需要将该json文件保存到json文件中(如expand-cluster-reassignment.json)
(二)、执行迁移分配
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --execute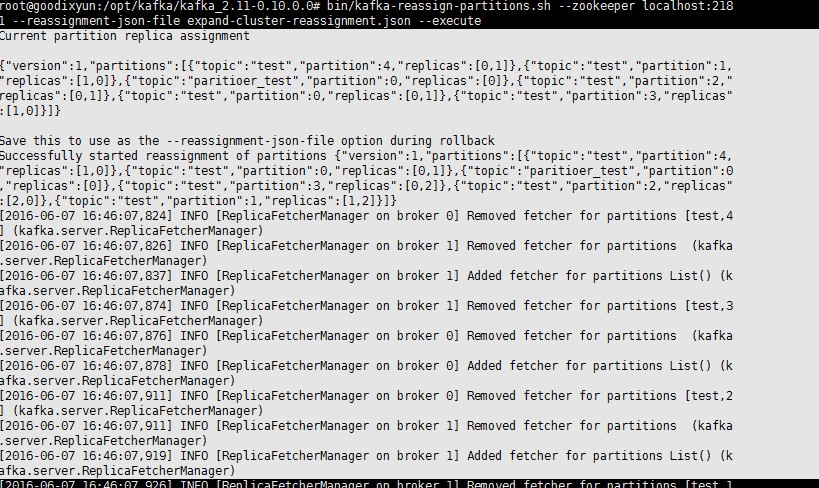
注意:在迁移过程中不能人为的结束或停止kafka服务,不然会有数据不一致的问题
(三)、验证分配
在执行的过程中,可以新开一个终端执行以下命令来查看执行是否正确完成
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --verify输出
Status of partition reassignment:
Reassignment of partition [test,4] completed successfully
Reassignment of partition [test,0] completed successfully
Reassignment of partition [paritioer_test,0] completed successfully
Reassignment of partition [test,3] completed successfully
Reassignment of partition [test,2] completed successfully
Reassignment of partition [test,1] completed successfully在迁移完成过程后,可以使用以下命令看下topic的每个partitions的分布情况
bin/kafka-topics.sh --zookeeper 172.16.49.173:2181 --describe --topic testTopic:test PartitionCount:5 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: test Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test Partition: 2 Leader: 2 Replicas: 2,0 Isr: 0,2
Topic: test Partition: 3 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: test Partition: 4 Leader: 0 Replicas: 1,0 Isr: 0,1
可以看到名为test的topic的有的数据以及存在于编号为2的新broker上了















 989
989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









