







爬虫第一步:获取整个网页的HTML信息。
源代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'https://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
req.encoding = "gbk"
print(req.text)出现问题:爬取下来的页面HTML与从页面审查的HTML不完全一致,缺少了页面上的正问内容部分HTML
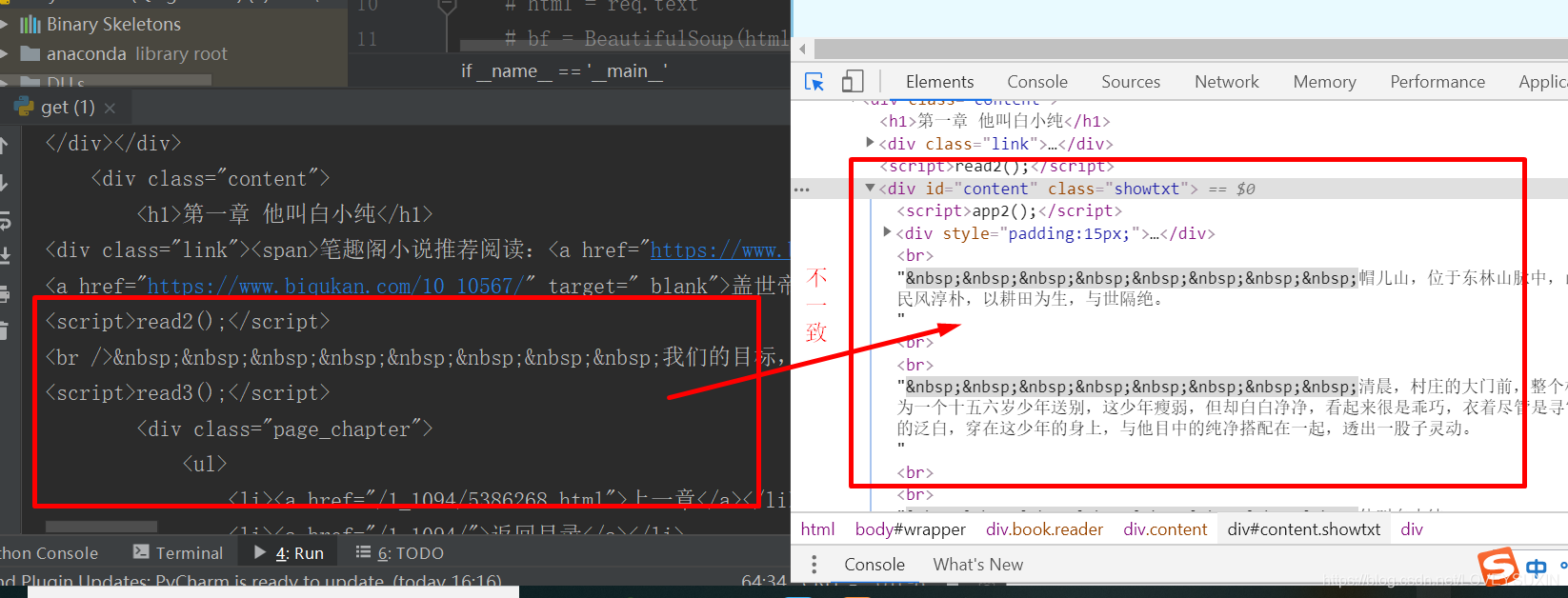
百度查询给出一个解释是:pycharm工具认为返回的数据太多给省略了,使用python自带的IDEA工具运行代码就没有问题。
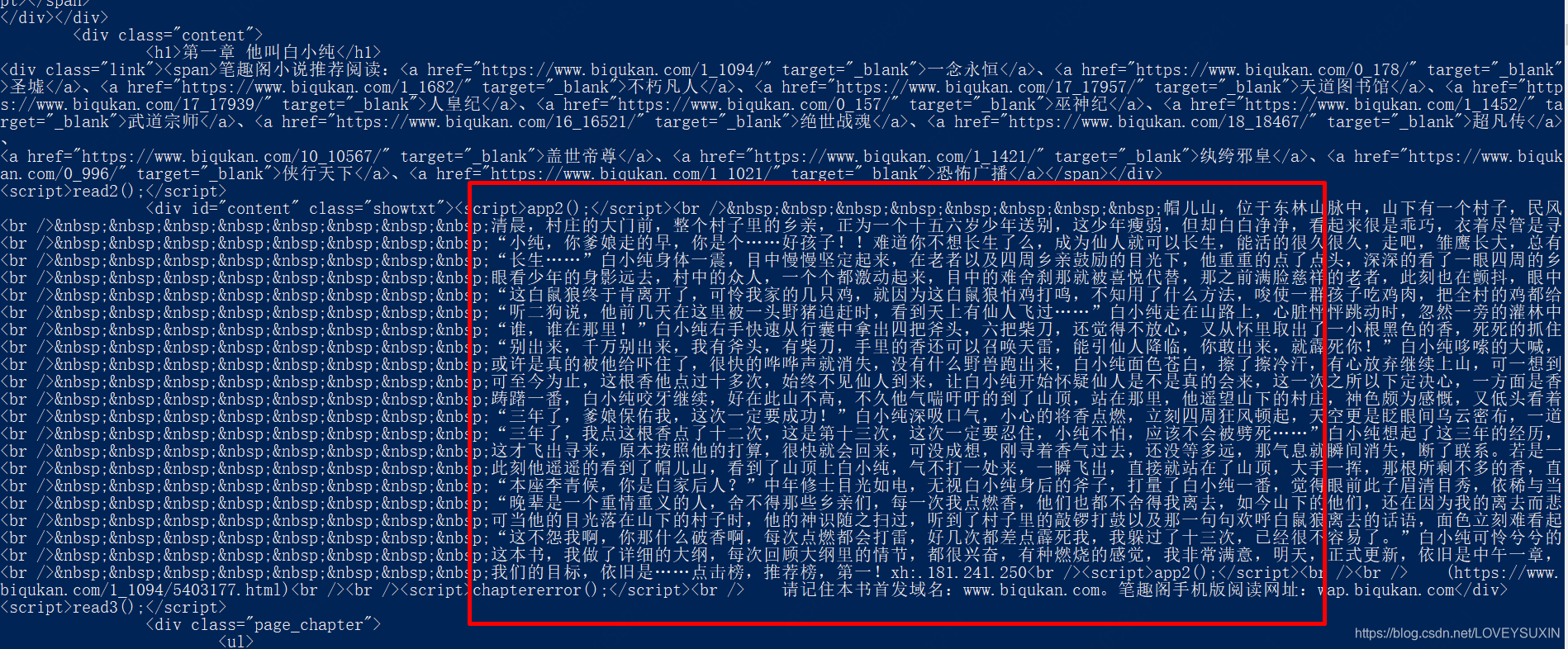
因此,在命令行又运行了一下代码,果真出现了正文,如下图:
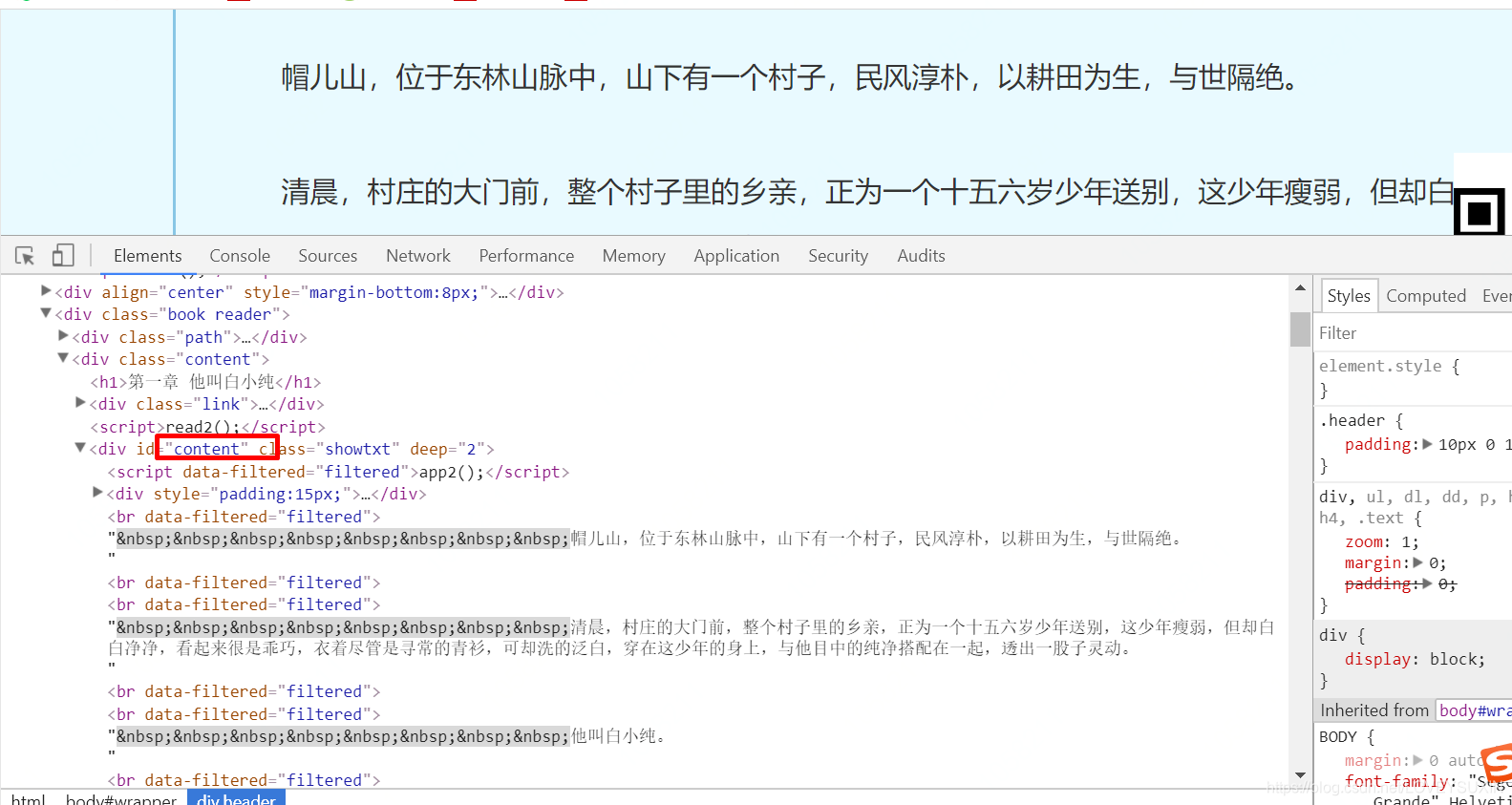
若必须在pycharm中运行,可进行如下修改: 写一个正则,只显示正文内容。
import requests
import re
if __name__ == '__main__':
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
p = r'id="content"(.*)' #正则只获取正文
req.encoding = "gbk"
texts = re.findall(p, req.text)
print(texts)再次,运行,结果如下:


















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









