







关于如何使用selenium解决requests.get(url)获取不到页面全部内容的记录
今天在尝试使用requests库进行PWA封禁信息爬取时出现了提取到的字符数组为空的情况,详细信息如下:
问题描述
这里展示部分项目源码与页面源码:
如图所示,id = “root”对应的div中包含有我们想要获取的信息
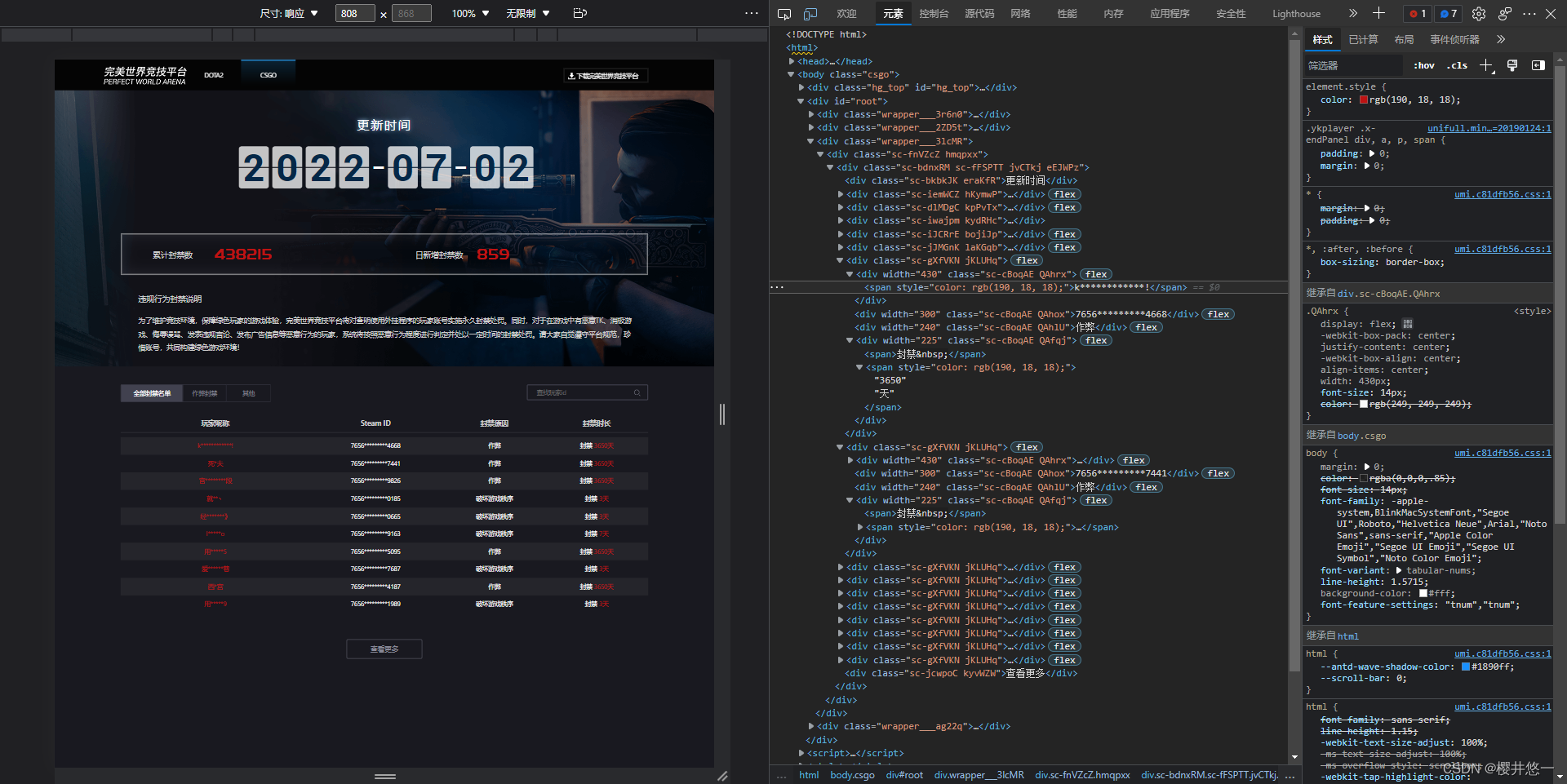
项目源码
获取到的结果
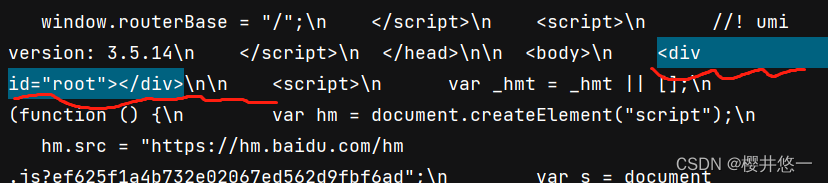
可以看到id = "root"对应的div中并没有信息,也就是说通过这种方法获取到的页面源码是不完整的
解决方案:
通过尝试,发现使用selenium库通过模拟当前浏览器可以完整地获取页面源码。
selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。
Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
具体实现:
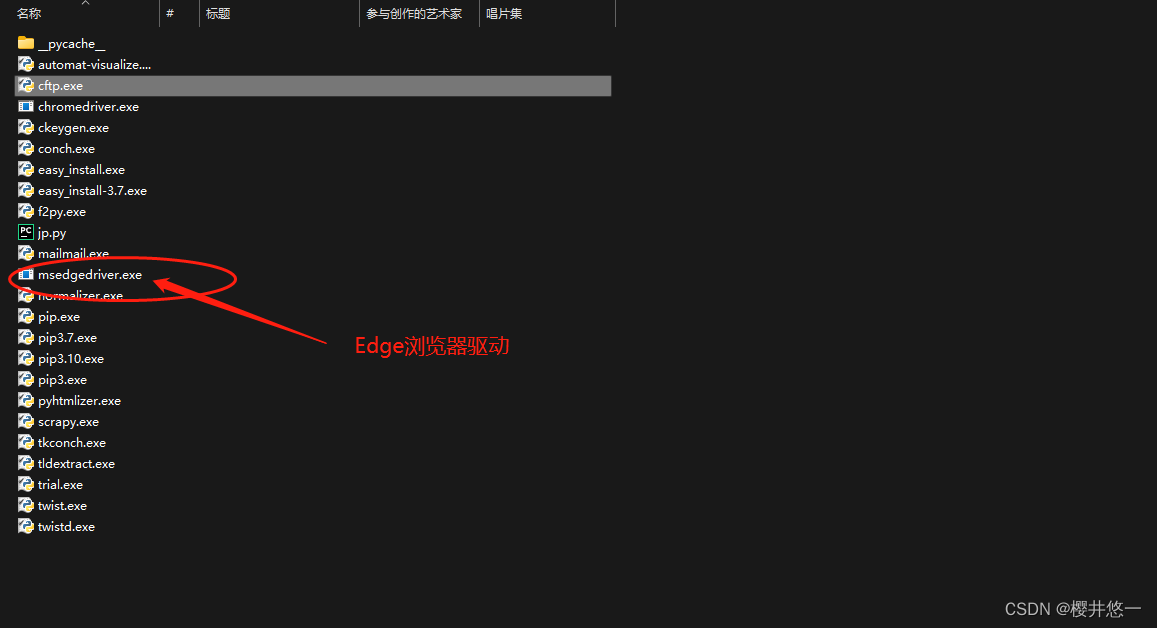
1.首先在设置中查看浏览器版本号,去浏览器官网下载对应版本的浏览器驱动。本次项目使用的是Edge浏览器,即去微软官网下载Edge浏览器驱动,并将驱动放在Python安装目录/Scripts下。
2.修改后的项目代码如下:
from lxml import etree
from selenium import webdriver
browser = webdriver.Edge()
url = "https://pvp.wanmei.com/csgo/ban"
browser.get(url)
browser.encoding = "utf-8"
browser.page_source
使用Jupyter服务器可以方便的查看每一个步骤的运行结果:
 、
、
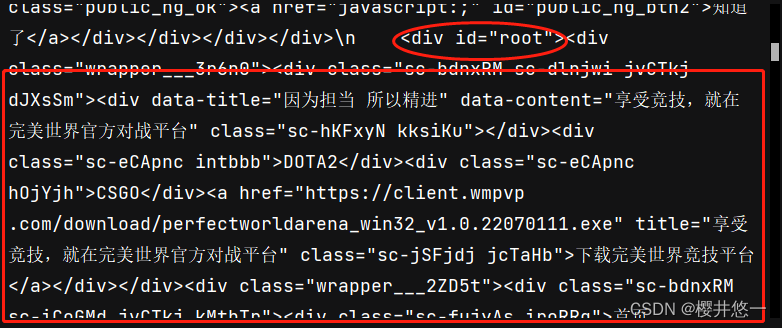
3.可以看到:此时id = "root"对应的div下是有内容的,接下来的任务即通过Xpath定位获取目标文本
举例如下,进一步实现:
from lxml import etree
from selenium import webdriver
browser = webdriver.Edge()
url = "https://pvp.wanmei.com/csgo/ban"
browser.get(url)
browser.encoding = "utf-8"
browser.page_source
html = etree.HTML(browser.page_source)
html
con = html.xpath("/html/body/div[2]/div[3]/div/div/div[7]/div[3]/text()")
con = str(con)
con
begin = con.index("'")
# begin
end = con.index("']")
con = con[begin + 1 : end]
con
再次查看当前运行效果:

我们成功获取了一名用户的封禁信息
需要注意的是,在使用Xpath时,需要添加 /text() 来获取文本信息。
4.在模拟浏览器中操作完成后,关闭浏览器:
browser.close()
还需注意的是,可能出现的报错:
1>在未下载浏览器驱动时提示需要将驱动添加至path,在将驱动添加到Scripts目录下后报错消失。
2>如未下载对应浏览器的驱动,可能报错:未找到目录。例如,在未拥有Chrome的情况下使用ChromeDriver驱动可能会报此错 误。
还需要继续学习!

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









