







数据清洗(Data Cleaning)
数据清洗是指处理缺失值和异常值,以提高数据质量和模型性能。它是数据预处理过程中至关重要的一步,有助于确保模型训练的准确性和可靠性。
原理
缺失值处理
处理缺失值的方法包括删除含有缺失值的样本或特征,或者使用插值、均值、中位数、众数等方法填补缺失值。
异常值处理
处理异常值的方法包括使用统计方法(如Z-Score)或基于模型的方法(如IQR)。
核心公式
处理缺失值
均值填补
对于一个有缺失值的特征列 X,其均值 Xˉ 计算为:

用这个均值填补缺失值。
处理异常值
Z-Score
标准化后的值 Z 计算公式为:
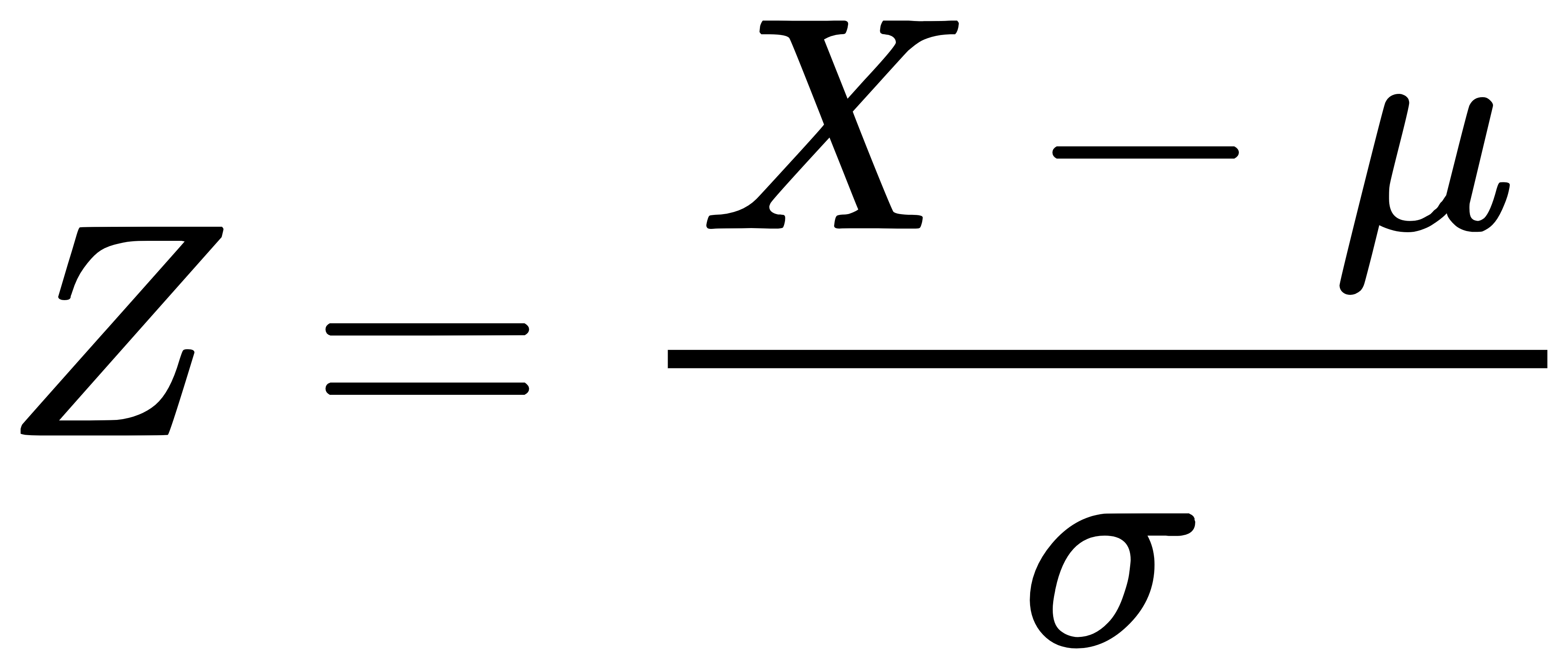
其中,μ 是均值,σ 是标准差。通常,∣Z∣>3 被认为是异常值。
案例
假设我们有一个关于房屋市场的数据集,其中包含房屋价格、房屋面积和用户评分等信息。数据集中可能存在缺失值和异常值,我们需要对其进行清洗,以便后续的分析和建模。
数据集描述
House_ID: 房屋的唯一标识符Price: 房屋价格(单位:千元)Size: 房屋面积(单位:平方米)Rating: 用户评分(1到5分)
代码实现
import pandas as pd
import numpy as np
# 创建虚构数据集
np.random.seed(42)
data = {
'House_ID': range(1, 101),
'Price': np.random.normal(loc=300, scale=50, size=100), # 房屋价格&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









