







支持向量机(SVM, Support Vector Machine)
原理
支持向量机是一种监督学习模型,适用于分类和回归任务。SVM 的目标是找到一个能够最大化类别间间隔的超平面,以便更好地对数据进行分类。对于非线性数据,SVM 通过核技巧将数据映射到高维空间,使得在该空间中可以找到一个线性可分的超平面。
公式
SVM 的核心思想是找到一个超平面使得两类数据点之间的间隔最大化。给定训练数据集 (xi,yi),其中 xi 是特征向量,yi 是类别标签(+1 或 -1),SVM 通过求解以下优化问题来找到最优的超平面:
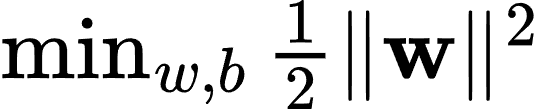
满足约束条件:
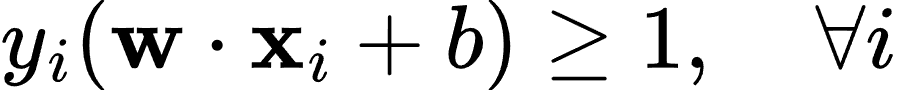
其中,w 是超平面的法向量,b 是偏置。
对于非线性数据,SVM 使用核函数 K(xi,xj) 将数据映射到高维空间。常用的核函数包括线性核、径向基核(RBF 核)和多项式核等。
生活场景应用的案例
邮件分类:SVM 可以用于电子邮件的垃圾邮件分类。假设我们有一个包含电子邮件内容的数据集,并使用特征如词频、长度等。我们可以使用 SVM 模型来预测某封邮件是否为垃圾邮件。
案例描述
假设我们有一个包含电子邮件内容和标签的数据集,包括以下特征:
- 词频(Term Frequency)
- 词汇量(Vocabulary Size)
- 邮件长度(Email Length)
- 特定关键词出现次数(Keyword Occurrence)
我们希望通过这些特征预测某封邮件是否为垃圾邮件。我们可以使用 SVM 模型进行训练和预测。训练完成后,我们可以使用模型来预测新邮件是否为垃圾邮件,并评估模型的性能。
代码解析
下面是一个使用 Python 实现上述垃圾邮件分类案例的示例,使用了 scikit-learn 库。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 创建示例数据
data = {
'term_frequency': [0.5, 0.1, 0.3, 0.8, 0.2, 0.4, 0.7, 0.6, 0.9, 0.3],
'vocabulary_size': [100, 150, 120, 200, 130, 140, 170, 180, 220, 110],
'email_length': [500, 600, 550, 700, 580, 620, 680, 650, 720, 590],
'keyword_occurrence': [2, 1, 3, 5, 1, 2, 4, 3, 6, 1],
'spam': [1, 0, 0, 1, 0, 0, 1, 0, 1, 0] # 1: Spam, 0: Not Spam
}
# 转换为 DataFrame
df = pd.DataFrame(data)
# 特征和目标变量
X = df[['term_frequency', 'vocabulary_size', 'email_length', 'keyword_occurrence']]
y = df['spam']
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建 SVM 模型并训练
model = SVC(kernel='linear', random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Confusion Matrix:")
print(cm)
print("Classification Report:")
print(report)在这个示例中:
- 我们创建了一个包含电子邮件信息的示例数据集,包括词频、词汇量、邮件长度和特定关键词出现次数等特征。
- 将数据集转换为 DataFrame 格式,并将特征和目标变量分开。
- 将数据集拆分为训练集和测试集。
- 使用训练集训练 SVM 分类模型。
- 通过测试集进行预测并评估模型的性能。
- 输出准确率(accuracy)、混淆矩阵(confusion matrix)和分类报告(classification report)。
这个案例展示了如何使用 SVM 模型来预测电子邮件是否为垃圾邮件,基于电子邮件的词频、词汇量、邮件长度和特定关键词出现次数等特征。模型训练完成后,可以用于预测新邮件是否为垃圾邮件,并帮助用户过滤垃圾邮件。
梯度提升决策树(GBDT, Gradient Boosting Decision Tree)
原理
梯度提升决策树(GBDT)是一种集成学习方法,通过迭代地训练多个决策树模型来逐步优化预测结果。每一棵新树都对之前树的预测误差进行拟合,从而减少整体的预测误差。GBDT 在回归和分类任务中都表现出色,尤其在处理非线性关系和复杂数据时具有优势。
GBDT 的核心思想是利用梯度下降算法来最小化损失函数。每一轮迭代中,GBDT 通过在负梯度方向上添加一个新模型来更新当前模型的预测。
公式
给定训练数据集 (xi,yi),GBDT 通过以下步骤构建模型:
- 初始化模型:
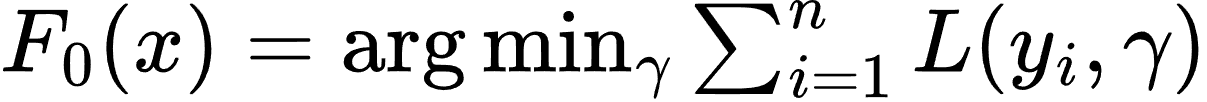
- 对于 m=1,2,...,Mm = 1, 2, ..., Mm=1,2,...,M:
- 计算当前模型的负梯度(残差):
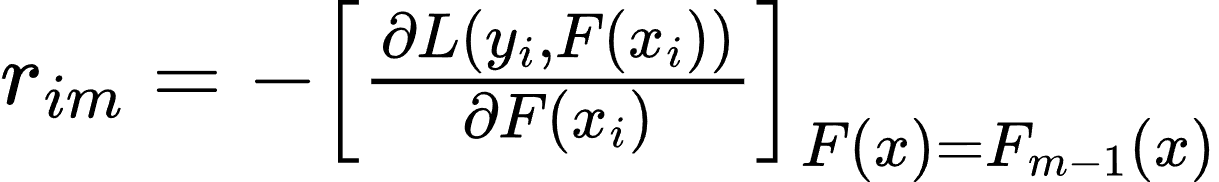
- 拟合一个新的决策树模型 hm(x)h_m(x)hm(x) 来对负梯度进行拟合:
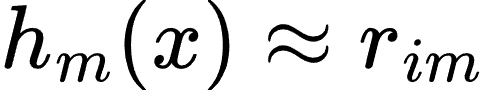
- 更新模型:
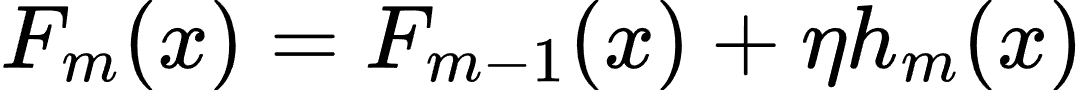
其中,η 是学习率,控制每棵树对最终模型的贡献。
生活场景应用的案例
房价预测:GBDT 可以用于房价预测。假设我们有一个包含房屋特征的数据集,如面积、房间数、位置等。我们可以使用 GBDT 模型来预测房价。
案例描述
假设我们有一个包含房屋特征的数据集,包括以下特征:
- 面积(Square Footage)
- 房间数(Number of Rooms)
- 房龄(Age of the House)
- 位置评分(Location Score)
我们希望通过这些特征预测房价。我们可以使用 GBDT 模型进行训练和预测。训练完成后,我们可以使用模型来预测新房屋的房价,并评估模型的性能。
代码解析
下面是一个使用 Python 实现上述房价预测案例的示例,使用了 scikit-learn 库。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
# 创建示例数据
data = {
'square_footage': [1500, 2500, 1800, 3000, 1200, 2000, 3500, 2800, 1600, 2200],
'number_of_rooms': [3, 4, 3, 5, 2, 4, 5, 4, 3, 4],
'age_of_house': [10, 5, 8, 2, 15, 7, 1, 4, 12, 6],
'location_score': [7, 8, 7, 9, 5, 7, 10, 8, 6, 7],
'price': [300000, 450000, 350000, 500000, 250000, 400000, 550000, 480000, 320000, 410000]
}
# 转换为 DataFrame
df = pd.DataFrame(data)
# 特征和目标变量
X = df[['square_footage', 'number_of_rooms', 'age_of_house', 'location_score']]
y = df['price']
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建 GBDT 模型并训练
model = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
print(f"R-squared: {r2}")
# 可视化特征重要性
feature_importance = model.feature_importances_
features = X.columns
indices = np.argsort(feature_importance)
plt.figure(figsize=(10, 6))
plt.title('Feature Importances')
plt.barh(range(len(indices)), feature_importance[indices], color='b', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()在这个示例中:
- 我们创建了一个包含房屋信息的示例数据集,包括面积、房间数、房龄和位置评分等特征。
- 将数据集转换为 DataFrame 格式,并将特征和目标变量分开。
- 将数据集拆分为训练集和测试集。
- 使用训练集训练 GBDT 回归模型。
- 通过测试集进行预测并评估模型的性能。
- 输出均方误差(Mean Squared Error, MSE)和决定系数(R-squared, R²)。
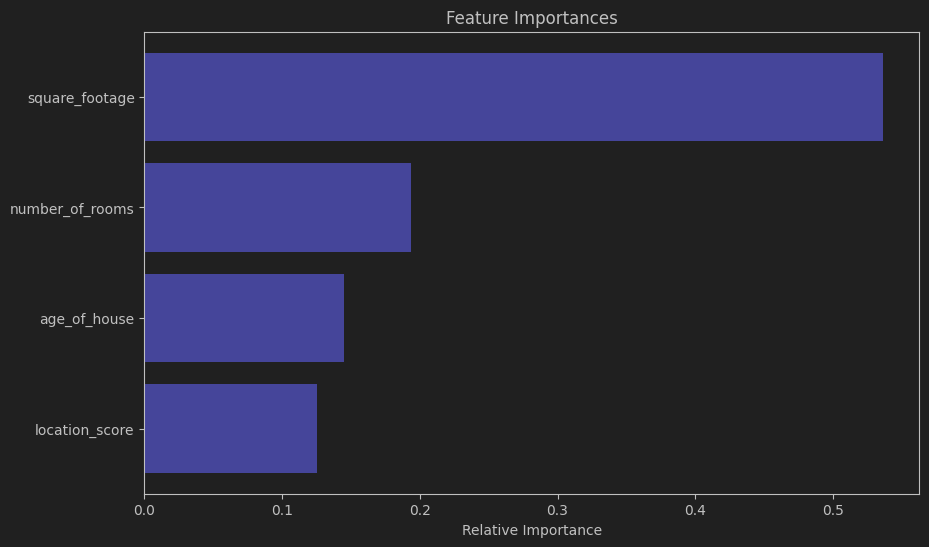
- 可视化特征的重要性,展示每个特征对预测结果的相对贡献。
这个案例展示了如何使用 GBDT 模型来预测房屋的价格,基于房屋的面积、房间数、房龄和位置评分等特征。模型训练完成后,可以用于预测新房屋的价格,并帮助用户在买房或卖房时做出更好的决策。















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









