







决策树(Decision Tree)
原理
决策树是一种树形结构的模型,用于分类和回归任务。每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,每个叶节点代表一个类别或回归值。决策树通过递归地将数据集划分成较小的子集,构建一棵树来做出预测。
决策树的构建过程通常使用某种分裂准则,如信息增益、基尼指数或均方误差,来选择最佳的属性进行数据划分。
公式
常用的决策树分裂准则包括:
- 信息增益(Information Gain):
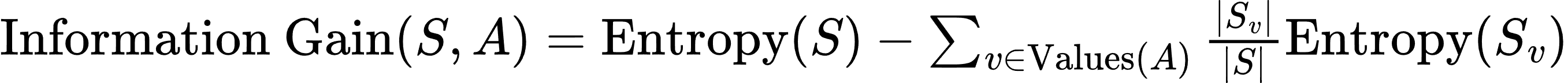
其中:
- S 是当前数据集。
- A 是待分裂的属性。
- Sv 是在属性 A 上取值为 v 的数据子集。
- 基尼指数(Gini Index):
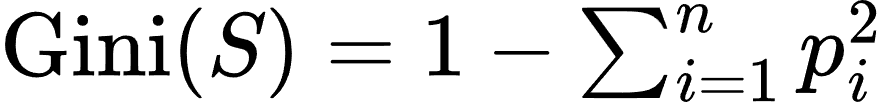
其中 pi 是第 i 类的样本比例。
生活场景应用的案例
信用评分:决策树可以用于银行的信用评分系统。假设我们有一个包含客户信息的数据集,如年龄、收入、信用历史等特征。我们可以使用决策树模型来预测客户是否有信用风险。
案例描述
假设我们有一个包含客户信息的数据集,包括以下特征:
- 年龄
- 年收入
- 信用历史(如是否有逾期还款记录)
- 已贷款数量
我们希望通过这些特征预测客户是否有信用风险。我们可以使用决策树模型进行训练和预测。训练完成后,我们可以使用模型来预测新客户的信用风险,并评估模型的性能。
代码解析
下面是一个使用Python实现上述信用评分案例的示例,使用了scikit-learn库。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 创建示例数据
data = {
'age': [25, 45, 35, 50, 23, 40, 60, 48, 33, 55],
'income': [50000, 100000, 70000, 120000, 48000, 75000, 130000, 115000, 68000, 105000],
'credit_history': [1, 0, 1, 0, 1, 1, 0, 0, 1, 0], # 1: No default, 0: Defaulted
'loan_amount': [20000, 50000, 30000, 60000, 18000, 32000, 70000, 45000, 28000, 52000],
'credit_risk': [1, 0, 1, 0, 1, 1, 0, 0, 1, 0] # 1: Low risk, 0: High risk
}
# 转换为DataFrame
df = pd.DataFrame(data)
# 特征和目标变量
X = df[['age', 'income', 'credit_history', 'loan_amount']]
y = df['credit_risk']
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型并训练
model = DecisionTreeClassifier(random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Confusion Matrix:")
print(cm)
print("Classification Report:")
print(report)
# 可视化决策树
plt.figure(figsize=(20, 10))
plot_tree(model, filled=True, feature_names=X.columns, class_names=['High Risk', 'Low Risk'], rounded=True)
plt.show()在这个示例中:
- 我们创建了一个包含客户信息的示例数据集,包括年龄、年收入、信用历史和贷款金额等特征。
- 将数据集转换为DataFrame格式,并将特征和目标变量分开。
- 将数据集拆分为训练集和测试集。
- 使用训练集训练决策树分类模型。
- 通过测试集进行预测并评估模型的性能。
- 输出准确率(accuracy)、混淆矩阵(confusion matrix)和分类报告(classification report)。
- 通过绘制决策树来可视化模型。

这个案例展示了如何使用决策树模型来预测客户的信用风险,基于客户的年龄、年收入、信用历史和贷款金额等特征。模型训练完成后,可以用于预测新客户的信用风险,并帮助银行在贷款审批过程中做出更好的决策。
随机森林(Random Forest)
原理
随机森林是一种集成学习方法,通过构建多个决策树并结合其预测结果来提高模型的准确性和稳定性。每棵树在训练时都使用了不同的子集数据,并且每个节点的分裂只使用了随机选择的特征子集。最终的预测结果是所有决策树预测结果的平均或投票结果。
公式
随机森林的关键思想是通过多次训练和结合多个决策树来减少过拟合并提高泛化能力。公式上没有特定的表示方法,但其核心思想可以通过以下步骤概括:
- Bootstrap Sampling:从原始训练数据集中有放回地随机抽取多个子集。
- Feature Subset Selection:在构建每棵决策树时,在每个节点上随机选择一个特征子集来进行分裂。
- Aggregation:通过投票或平均的方法结合所有树的预测结果。
生活场景应用的案例
信用评分:随机森林可以用于银行的信用评分系统。假设我们有一个包含客户信息的数据集,如年龄、收入、信用历史等特征。我们可以使用随机森林模型来预测客户是否有信用风险,相对于单棵决策树,随机森林通常能提供更高的准确性和稳定性。
案例描述
假设我们有一个包含客户信息的数据集,包括以下特征:
- 年龄
- 年收入
- 信用历史(如是否有逾期还款记录)
- 已贷款数量
我们希望通过这些特征预测客户是否有信用风险。我们可以使用随机森林模型进行训练和预测。训练完成后,我们可以使用模型来预测新客户的信用风险,并评估模型的性能。
代码解析
下面是一个使用Python实现上述信用评分案例的示例,使用了scikit-learn库。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# 创建示例数据
data = {
'age': [25, 45, 35, 50, 23, 40, 60, 48, 33, 55],
'income': [50000, 100000, 70000, 120000, 48000, 75000, 130000, 115000, 68000, 105000],
'credit_history': [1, 0, 1, 0, 1, 1, 0, 0, 1, 0], # 1: No default, 0: Defaulted
'loan_amount': [20000, 50000, 30000, 60000, 18000, 32000, 70000, 45000, 28000, 52000],
'credit_risk': [1, 0, 1, 0, 1, 1, 0, 0, 1, 0] # 1: Low risk, 0: High risk
}
# 转换为DataFrame
df = pd.DataFrame(data)
# 特征和目标变量
X = df[['age', 'income', 'credit_history', 'loan_amount']]
y = df['credit_risk']
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林模型并训练
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Confusion Matrix:")
print(cm)
print("Classification Report:")
print(report)
# 可视化一棵决策树
plt.figure(figsize=(20, 10))
plot_tree(model.estimators_[0], filled=True, feature_names=X.columns, class_names=['High Risk', 'Low Risk'], rounded=True)
plt.show()在这个示例中:
- 我们创建了一个包含客户信息的示例数据集,包括年龄、年收入、信用历史和贷款金额等特征。
- 将数据集转换为DataFrame格式,并将特征和目标变量分开。
- 将数据集拆分为训练集和测试集。
- 使用训练集训练随机森林分类模型。
- 通过测试集进行预测并评估模型的性能。
- 输出准确率(accuracy)、混淆矩阵(confusion matrix)和分类报告(classification report)。
- 通过绘制其中一棵决策树来可视化模型。

这个案例展示了如何使用随机森林模型来预测客户的信用风险,基于客户的年龄、年收入、信用历史和贷款金额等特征。模型训练完成后,可以用于预测新客户的信用风险,并帮助银行在贷款审批过程中做出更好的决策。















 1111
1111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









