







时间序列分析(Time Series Analysis)
原理
时间序列分析是一种针对时间序列数据的统计和预测方法。时间序列数据是按照时间顺序排列的一组观测值,其分析方法主要包括识别数据模式(如趋势、季节性、周期性等)、构建预测模型和进行未来数据的预测。常用的时间序列模型有自回归移动平均模型(ARIMA)、季节性自回归综合移动平均模型(SARIMA)等。
公式
- 自回归模型(AR, Autoregressive Model):
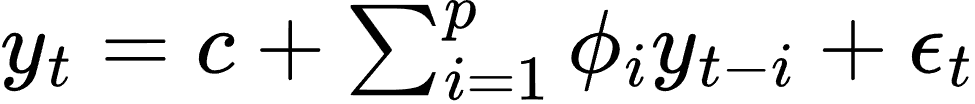
其中,yt 是时间 t 的观测值,c 是常数项,ϕi 是自回归系数,ϵt 是误差项。
- 移动平均模型(MA, Moving Average Model):
其中,μ 是均值,θi 是移动平均系数,ϵt 是误差项。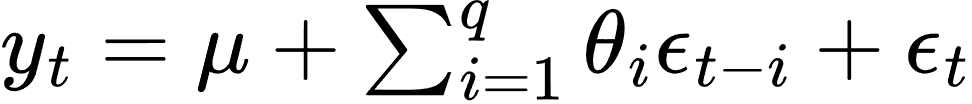
- 自回归移动平均模型(ARMA, Autoregressive Moving Average Model):
结合了AR和MA模型:
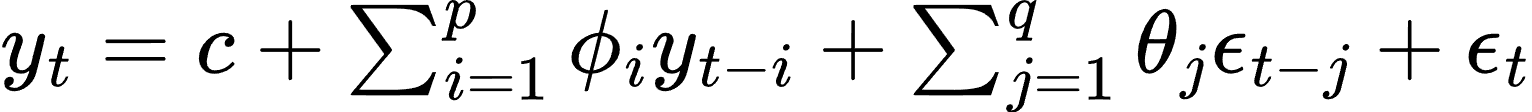
- 自回归综合移动平均模型(ARIMA, Autoregressive Integrated Moving Average Model):
ARIMA 模型在 ARMA 模型的基础上引入差分操作以处理非平稳时间序列:
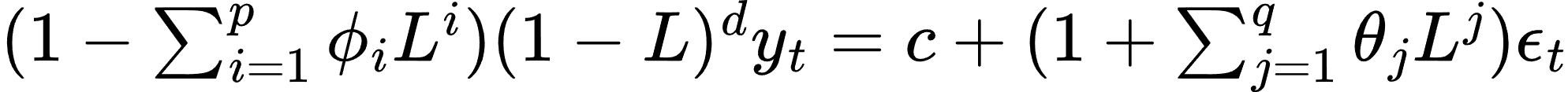
其中,L 是滞后算子,d 是差分阶数。
生活场景应用的案例
销售量预测:时间序列分析可以用于商店的销售量预测。假设我们有一个包含过去几年的销售数据的时间序列,我们可以使用时间序列模型来预测未来的销售量。这可以帮助商店优化库存管理,避免过多或过少的库存。
案例描述
假设我们有一个包含过去五年某商店每月销售量的数据集,我们希望通过这些历史数据来
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









