






创建本地文件
在桌面目录下创建文件wordfile.txt,其内容为"Hello World"和
“Hadoop MapReduce”(两行)
touch wordfile.txt
运行程序之前,需要启动Hadoop
切换到hadoop目录下,启动成功出现如下图所示
cd /usr/local/hadoop
./sbin/start-dfs.sh

在HDFS上创建输入文件夹
./bin/hdfs dfs -mkdir input1
./bin/hdfs dfs -mkdir input2
上传本地文件wordfile.txt到HDFS的input1目录下
./bin/hdfs dfs -put /home/hadoop/桌面/wordfile.txt input1

上传Hadoop安装目录中etc/hadoop下的所有xml文件上传至HDFS的input2文件夹中
./bin/hdfs dfs -put ./etc/hadoop/*.xml input2

运行Hadoop自带程序wordcount
首先在/usr/local/hadoop/share/hadoop/mapreduce目录下面找到自带包的版本

./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-examples-3.2.1.jar wordcount input1 output1
运行结束后词频统计结果已经被写入了HDFS的output1目录下,执行以下命令查看词频统计结果
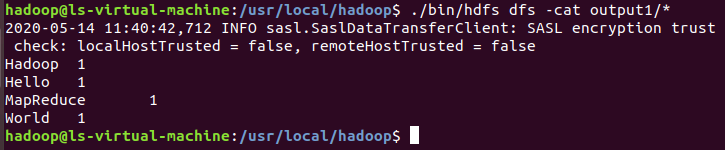
./bin/hdfs dfs -cat output1/*
运行Hadoop自带程序grep
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input2 output2 'dfs[a-z.]+'
运行结束后匹配统计结果已经被写入了HDFS的output2目录下,执行以下命令查看匹配统计结果
./bin/hdfs dfs -cat output2/*

运行Hadoop自带程序pi
两个参数含义:第一个是运行6次map任务,第二个是每个map任务投掷次数位为5000,所以总投掷次数是6×5000=30000
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-examples-3.2.1.jar pi 6 5000
为了结果更加准确,可以把这两个数值改大点。上面命令执行后,运行过程中会出现以下信息

最后出现的就是计算出的pi值
最后运行结束后,一定要记得:关闭Hadoop

好了,以上是本次操作的全部内容,有哪里不对的地方可以在评论区指出来哦















 3762
3762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









