







存储过程
定义:存储过程有时候也称为sproc,它是真正的脚本——或者更准确的说,它是批处理——它存储与数据库中而不是单独的文件中。存储过程中有输入参数,输出参数以及返回值等。
创建存储过程:基本语法
语法:CREATE PROCEDURE|PROC<sproc name>........
案例:
USE AdventureWorks2012;
GO
CREATE PROC spEmployee
AS
SELECT * FROM HumanResources.Employee;
GO
CREATE PROC spEmployee
AS
SELECT * FROM HumanResources.Employee;
注意:为什么要在CREATE语法之前加上GO关键字(如果只是简单的SELECT语句,就不需要用它),这是因为大多数非表的CREATE语句不能与其他代码共享批处理。
使用ALTER 修改存储过程
定义:使用ALTER是在完全替换现有的存储过程。使用ALTER PROC 和 CREATE PROC 语句的唯一区别包含以下几点:
ALTER PROC:期望找到一个已有的存储过程,而CREATE则不是。
ALTER PROC:保留了存储过程上已经建立的任何权限。
ALTER PROC:在可能调用被修改的存储过程中的其他对象上保留了任何依赖信息。
删除存储过程
语法:DROP PROC|PROCEDURE <sproc name>[;]
参数化存储过程
声明参数
案例:
CREATE PROC spEmployeeByName
@LastName nvarchar(50)
AS
SELECT
p.LastName,p.FirstName,e.JobTitle,e.HireDate
FROM Person.Person p LEFT JOIN HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
WHERE p.LastName LIKE @LastName+'%';
@LastName nvarchar(50)
AS
SELECT
p.LastName,p.FirstName,e.JobTitle,e.HireDate
FROM Person.Person p LEFT JOIN HumanResources.Employee e ON p.BusinessEntityID = e.BusinessEntityID
WHERE p.LastName LIKE @LastName+'%';
EXEC spEmployeeByName 'Dobney';
提供默认值
定义:为了是参数可选的,必须提供默认值。看起来类似于初始化变量:在数据类型后和逗号之前添加“=”符号作为默认值。
案例:
--创建存储过程并给默认值
create proc spEmployeeByName
@LastName nvarchar(50) = null--设置参数并给默认值
as
if @LastName is not null--判断参数是否为空
begin
select
p.LastName,p.FirstName,e.JobTitle,e.HireDate
from Person.Person p LEFT JOIN HumanResources.Employee e on p.BusinessEntityID = e.BusinessEntityID
where p.LastName LIKE @LastName+'%';
end
else
begin
select
p.LastName,p.FirstName,e.JobTitle,e.HireDate
from Person.Person p LEFT JOIN HumanResources.Employee e on p.BusinessEntityID = e.BusinessEntityID;
end
exec spEmployeeByName;--使用默认值
exec spEmployeeByName 'Dobney';--使用参数
create proc spEmployeeByName
@LastName nvarchar(50) = null--设置参数并给默认值
as
if @LastName is not null--判断参数是否为空
begin
select
p.LastName,p.FirstName,e.JobTitle,e.HireDate
from Person.Person p LEFT JOIN HumanResources.Employee e on p.BusinessEntityID = e.BusinessEntityID
where p.LastName LIKE @LastName+'%';
end
else
begin
select
p.LastName,p.FirstName,e.JobTitle,e.HireDate
from Person.Person p LEFT JOIN HumanResources.Employee e on p.BusinessEntityID = e.BusinessEntityID;
end
exec spEmployeeByName;--使用默认值
exec spEmployeeByName 'Dobney';--使用参数
创建输出参数
定义:给调用存储过程的对象传递非记录集的信息。
案例1:
create proc dbo.uspLogErrors--创建带架构的存储过程
@ErrorLogID int = 0 output--声明输出参数
as
begin
set nocount on;--作用:阻止在结果集中返回显示受T-SQL语句或则usp影响的行计数信息。当SET ONCOUNT ON时候,不返回计数,当SET NOCOUNT OFF时候,返回计数;
set @ErrorLogID = 0;--设置值
--处理错误信息--
begin try
if ERROR_NUMBER() is null--判断错误行号
return;
if XACT_STATE()=-1-- XACT_STATE 指示请求是否有活动的用户事务,以及是否能够提交该事务
begin
print 'Cannot log error since the current transaction is in an uncommittable state.'
+'Rollback the transaction before executing uspLogError in order to successfully log error information.';
return;
end
--插入信息--
insert into dbo.ErrorLog
(
[UserName],
[ErrorNumber],
[ErrorSeverity],
[ErrorState],
[ErrorProcedure],
[ErrorLine],
[ErrorMessage]
)
values(
CONVERT(sysname,CURRENT_USER),
ERROR_NUMBER(),
ERROR_SEVERITY(),
ERROR_STATE(),
ERROR_PROCEDURE(),
ERROR_LINE(),
ERROR_MESSAGE()
)
set @ErrorLogID = @@IDENTITY;--获取插入标识
end try
begin catch
print 'An error occurred in stored procedure uspLogError:';
execute dbo.uspLogErrors;
return -1;
end catch
end
@ErrorLogID int = 0 output--声明输出参数
as
begin
set nocount on;--作用:阻止在结果集中返回显示受T-SQL语句或则usp影响的行计数信息。当SET ONCOUNT ON时候,不返回计数,当SET NOCOUNT OFF时候,返回计数;
set @ErrorLogID = 0;--设置值
--处理错误信息--
begin try
if ERROR_NUMBER() is null--判断错误行号
return;
if XACT_STATE()=-1-- XACT_STATE 指示请求是否有活动的用户事务,以及是否能够提交该事务
begin
print 'Cannot log error since the current transaction is in an uncommittable state.'
+'Rollback the transaction before executing uspLogError in order to successfully log error information.';
return;
end
--插入信息--
insert into dbo.ErrorLog
(
[UserName],
[ErrorNumber],
[ErrorSeverity],
[ErrorState],
[ErrorProcedure],
[ErrorLine],
[ErrorMessage]
)
values(
CONVERT(sysname,CURRENT_USER),
ERROR_NUMBER(),
ERROR_SEVERITY(),
ERROR_STATE(),
ERROR_PROCEDURE(),
ERROR_LINE(),
ERROR_MESSAGE()
)
set @ErrorLogID = @@IDENTITY;--获取插入标识
end try
begin catch
print 'An error occurred in stored procedure uspLogError:';
execute dbo.uspLogErrors;
return -1;
end catch
end
--执行语句--
exec dbo.uspLogErrors 10;
案例2:
begin try
create table OurIFTest(
Col1 int primary key
);
end try
begin catch
declare @MyOutputParameter int;
if error_number() = 2714
begin
print 'WARNING:Skipping CREATE as table already exists';
exec dbo.uspLogError @ErrorLogID = @MyOutputParameter output;
print 'An error was logged.The Log ID for your error was'+ cast(@MyOutputParameter as varchar);
end
else
raiserror('something not good happened this time around',16,1);
end catch
create table OurIFTest(
Col1 int primary key
);
end try
begin catch
declare @MyOutputParameter int;
if error_number() = 2714
begin
print 'WARNING:Skipping CREATE as table already exists';
exec dbo.uspLogError @ErrorLogID = @MyOutputParameter output;
print 'An error was logged.The Log ID for your error was'+ cast(@MyOutputParameter as varchar);
end
else
raiserror('something not good happened this time around',16,1);
end catch
注意:
● 对于存储过程声明中的输出参数,需要使用OUTPUT关键字。
● 和声明存储过程一样,调用存储过程时必须使用OUTPUT关键字。
● 赋给输出结果的变量不需要和存储过程中的内部参数有用相同的名称。
● EXEC(或者EXECUTE) 关键字是必须的,因为对存储过程的调用并不是批处理要做的第一件事。
通过返回值确认成功或失败
定义:返回值就是实际地返回数据,例如标识值或者是存储过程影响行数。而其实际作用是返回值可用来确定存储过程的执行状态。返回值指示了存储过程的成功或者失败,甚至是成功或失败的程度或属性。
如何使用RETURN
定义:事实上,不管是否提供返回值,程序都会收到一个返回值。SQLServer默认会在完成存储过程时自动返回一个0值。
语法:RETURN [<integer value to return >]
注意:返回的必须是整数。是无条件地从存储过程中退出的。这是指五路运行到存储过程的那个位置,在调用RETURN 语句之后将不会执行任何一行代码。这里说的无条件并不是说无论执行到代码的何处都将执行RETURN语句。相反,可以存储过程中有多个RETURN语句,只有当代码的标准条件结构发出命令时,才会执行这些RETURN语句,一旦这种情况发生,就不能再返回。
案例:
create proc spTestReturns
as
declare @MyMessage varchar(50);
declare @MyOtherMessage varchar(50);
select @MyMessage = 'Hi,it ''s that line before the RETURN';
print @MyMessage;
return 100;
select @MyOtherMessage = 'Sorry,but you won''t get this far';
print @MyOtherMessage;
return;
--测试代码----
declare @Return int;
exec @Return = spTestReturns;
select @Return;
--删除spTestReturns
drop proc spTestReturns;
注意:返回值一定是整数
错误处理
SQLServer中常见的错误类型:
● 产生运行时错误并终止代码继续执行的错误。
● SQL Server 知道、但不产生使代码停止运行的运行时错误的错误。这类错误也称为内联错误。
● 更具有逻辑性但是SQL Server 中不太引起注意的错误。
处理内联错误
定义:内联错误是指:那些能让SQL Server 继续运行,但是因为某些原因而不能成功完成指定任务的错误。
案例:insert into Person.BusinessEntityContact(BusinessEntityID,PersonID,ContactTypeID) values(0,0,1);出现547错误,即是插入错误。
利用@@ERROR
定义:@@ERROR 包含了最后执行的T-SQL语句的错误号。如果该值为0,则没有发生任何错误。与ERROR_NUMBER()函数有些类似,ERROR_NUMBER()函数只在CATCH块中有效(并且不管在CATCH块中的哪个位置都有效),而@@ERROR根据执行的每一条语句接收一个新值。
注意:有关@@ERROR的警告是每条新语句都会使之重置。想要保存它的某个位置的状态值必须保存到一个局部变量中。
案例:
declare @Error int;
insert into Person.BusinessEntityContact(BusinessEntityID,PersonID,ContactTypeID)values(0,0,1);
select @Error = @@ERROR;--获取上一条语句的错误状态,并赋值给一个局部变量,因为每一条语句都会是之重置。
print '';
print 'The Value of @Error is '+convert(varchar,@Error);
print 'The Value of @@ERROR is'+convert(varchar,@@ERROR);
insert into Person.BusinessEntityContact(BusinessEntityID,PersonID,ContactTypeID)values(0,0,1);
select @Error = @@ERROR;--获取上一条语句的错误状态,并赋值给一个局部变量,因为每一条语句都会是之重置。
print '';
print 'The Value of @Error is '+convert(varchar,@Error);
print 'The Value of @@ERROR is'+convert(varchar,@@ERROR);
在存储过程中使用@@ERROR
定义:如果需要向后兼容或更早的版本,那么TRY/CATCH就不适用。
注意:TRY/CATCH将处理之前的版本中终止脚本执行的各种错误。
案例:
--创建存储过程spInsertValidateBusinessEntityContact
create proc spInsertValidateBusinessEntityContact
@BusinessEntityID int,
@PersonID int,
@ContactTypeID int
as
begin
declare @Error int;
insert into Person.BusinessEntityContact(BusinessEntityID,PersonID,ContactTypeID)
values(@BusinessEntityID,@PersonID,@ContactTypeID)
set @Error = @@ERROR;--将@@ERROR赋给局部变量进行保存
if @Error = 0
print N'新记录被插入';
else
begin
if @Error = 547
print 'At least one provided parameter was not found.Correct and retry';
else
print 'UnKnown error occurred.Please contact your system admin';
end
end
create proc spInsertValidateBusinessEntityContact
@BusinessEntityID int,
@PersonID int,
@ContactTypeID int
as
begin
declare @Error int;
insert into Person.BusinessEntityContact(BusinessEntityID,PersonID,ContactTypeID)
values(@BusinessEntityID,@PersonID,@ContactTypeID)
set @Error = @@ERROR;--将@@ERROR赋给局部变量进行保存
if @Error = 0
print N'新记录被插入';
else
begin
if @Error = 547
print 'At least one provided parameter was not found.Correct and retry';
else
print 'UnKnown error occurred.Please contact your system admin';
end
end
--执行存储过程
exec spInsertValidateBusinessEntityContact 1,1,11;
exec spInsertValidateBusinessEntityContact 1,1,11;
在错误发生之前处理错误
定义:在错误发生之前处理错误。
案例:
create proc HumanResources.uspUpdateEmployeeHireInfo2
@BusinessEntityID int,
@JobTitle nvarchar(50),
@HireDate datetime,
@RateChangeDate datetime,
@Rate money,
@PayFrequency tinyint,
@CurrentFlag dbo.Flag
with exec as caller--指定在模块调用方的上下文中执行该模块中的语句。
as
begin
set nocount on;--作用:阻止在结果集中返回显示受T-SQL语句或则usp影响的行计数信息。当SET ONCOUNT ON时候,不返回计数,当SET NOCOUNT OFF时候,返回计数;
declare @BUSINESS_ENTITY_ID_NOT_FOUND int = -1000,--声明常量
@DUPLICATE_RATE_CHANGE int = -2000;--声明常量
begin try
begin transaction;--表示开启一个事务
update HumanResources.Employee
set
JobTitle = @JobTitle,
HireDate = @HireDate,
CurrentFlag = @CurrentFlag
where BusinessEntityID = @BusinessEntityID;
insert into HumanResources.EmployeePayHistory
(
BusinessEntityID,
RateChangeDate,
Rate,
PayFrequency
)
values(
@BusinessEntityID,
@RateChangeDate,
@Rate,
@PayFrequency
);
commit transaction;--提交一个事务
end try
begin catch
if @@TRANCOUNT>0--返回在当前连接上执行的 BEGIN TRANSACTION 语句的数目
begin
--rollback transaction;--将显式事务或隐性事务回滚到事务的起点或事务内的某个保存点
insert into HumanResources.EmployeePayHistory
(BusinessEntityID,RateChangeDate,Rate,PayFrequency)
values
(@BusinessEntityID,@RateChangeDate,@Rate,@PayFrequency);
end
else
begin
print 'BusinessEntityID not Found';
rollback transaction;
return @BUSINESS_ENTITY_ID_NOT_FOUND;
end
end catch
end
手动引发错误
定义:有时候会出现SQL Server 不能识别的错误,但是你希望SQL Server 能识别这样的错误。用RAISERROR命令。
语法:RAISERROR(<message ID|message string|variable>,<sererity>,<state>[,<argument>[,<...n>]])[WITH option[,...n]]
消息ID/消息字符串
定义:消息ID或消息字符串决定了向客户端发送的消息。
语法:
select * from master.sys.messages;--查询所有可能的系统消息
raiserror(N'引发了消息',1,1);
raiserror(N'引发了消息',1,1);
严重性
定义:信息性的错误(1-18),系统级错误(19-25),灾难级的错误(20-25)。如果引发的严重错误是19或者更高(系统级的),那么必须指定WITH LOG 选项。20以及更高级别的错误严重性会自动终止用户的连接。


状态
定义:状态是一个特殊的值。它会在识别的代码中的多个地方发生的相同错误。这样就可以发送位置标记表名发生错误的地方。状态值是1-127之间。
错误参数
定义:一些预定义的错误会接受参数。这就可能通过改变错误特性来史错误更具有动态性。也可以格式化错误消息来接受参数。
动态信息格式符号


最后一点很总要,可以设定参数的宽度,精度和数据类型的长/短。
宽度:通过提供整数值来设定想要为参数值所保留的空间。也可以指定“*”,在这种情况下,SQL Server会自动根据设定的精度值来决定宽度。
精度:确定了数值类型数据输出的最大数据位数。
长/段:当参数为整型、八进制数或十六进制数时,使用h(short)或l(long)来设定。
案例:raiserror('This is a sample parameterized %s,along with a zero pading and a sign%+010d',1,1,'string',12121);
WITH<option>
目前,在引发错误时混合搭配一下3个选项:
●LOG:这告诉SQL Server在SQL Server 错误日志和Windows应用程序日志中的记录错误。对于严重性级别大于或等于19的错误,这个选项是必须的。
●SETERROR:默认情况下,RAISERROR命令不会将@@ERROR设置为所生成的错误值。@@ERROR反映了实际的RAISERROR命令是成功或失败的。SETERROR重写了这个值并把@@ERROR的值设置为特定的错误ID。
●NOWAIT:这将立即向客户端通知错误。
重新抛出错误
定义:开发人员使用的不限于T-SQL领域的经验法则是只捕获可以处理的错误,您不知道如何处理的任何错误都应该直接传递给调用者,调用者可能知道(也可能不知道)如何处理错误,但是至少不需要你来处理。如果您没有准备好处理一个错误,则可以向下抛出(THROW)该错误。THROW在某些方面非常类似与RAISERROR,但是有一些重要的区别。
语法:THROW[error_number,message,state][;]
和raiserror的区别:THROW的参数非常类似与RAISERROR的参数,但是没有严重级别的参数。这是因为在使用指定的参数值调用THROW时,始终使用严重级别16。注意,16表示默认情况下不懈人Windows日志。但是当前的代码将停止执行。
●使用THROW时,error_number参数不需要已经存在于sys,messages中。但是,应该确保在某个位置定义您的错误。
●RAISERROR消息字符串使用prinf样式的语法进行动态消息传递,而THROW不这样做,如果您想要自定义抛出的消息,则必须预先连接它。
●THROW之前的语句必须以分号(;)终止。
案例:
begin try
insert OurIFTest(Col1) values(1);
end try
begin catch
print 'Arrived in the CATCH block.';
declare @ErrorNo int,
@Severity tinyint,
@State smallint,
@LineNo int,
@Message nvarchar(4000);
select
@ErrorNo = ERROR_NUMBER(),
@Severity = ERROR_SEVERITY(),
@State = ERROR_STATE(),
@LineNo = ERROR_LINE(),
@Message = ERROR_MESSAGE();
if @ErrorNO = 2714
print 'WARNING:object already exists';
else
throw;
end catch
insert OurIFTest(Col1) values(1);
end try
begin catch
print 'Arrived in the CATCH block.';
declare @ErrorNo int,
@Severity tinyint,
@State smallint,
@LineNo int,
@Message nvarchar(4000);
select
@ErrorNo = ERROR_NUMBER(),
@Severity = ERROR_SEVERITY(),
@State = ERROR_STATE(),
@LineNo = ERROR_LINE(),
@Message = ERROR_MESSAGE();
if @ErrorNO = 2714
print 'WARNING:object already exists';
else
throw;
end catch
添加自定义的错误消息
定义:可以利用特殊的系统存储过程向系统添加自己的消息。这个存储过程称为sp_addmessage
语法:
sp_addmessage [@msgnum=]<msg id>,
[@severity=]<severity>,
[@msgtext=] <'msg'>
[,[@lang=]<'language'>]
[,[@with_log=][TRUE|FALSE]]
[,[@replace=]'replace']
除了其他的语言和替换参数,以及WITH LOG选项的一点区别外,该存储过程中所有参数的含义于raiserror中的是相似的。
1.@lang:指定了消息应用的语言。在该参数中可以为syslanguages中支持的任何余元指定消息的一个单独版本。
2.@with_log:其工作方式与raiserror中的一样,如果设为TRUE,当取出错误的时候,会向SQL Server错误日志和NT应用日志自动记录错误消息(只有运行在NT环境下才会实现后一个操作),这里唯一特别之处就是通过把该参数设置为true而不是使用with log 选项来把消息写入日志。
3.@replace:如果是编辑现有的消息而非创建一个新消息,那么必须把@replace参数设置为REPLACE。倘若不这样做,那么如果消息已经存在,就会得到一个错误。
使用sp_addmessage
案例:
sp_addmessage
@msgnum = 60000,
@lang ='us_english',
@severity=10,
@msgtext = '%s is not a valid Order date.Order date must be within 7 days of current date.'
@msgnum = 60000,
@lang ='us_english',
@severity=10,
@msgtext = '%s is not a valid Order date.Order date must be within 7 days of current date.'
删除已有的自定义消息
语法:sp_dropmessage<message number>
存储过程的优点
1.创建可调用的进程
2.安全性
存储过程的性能
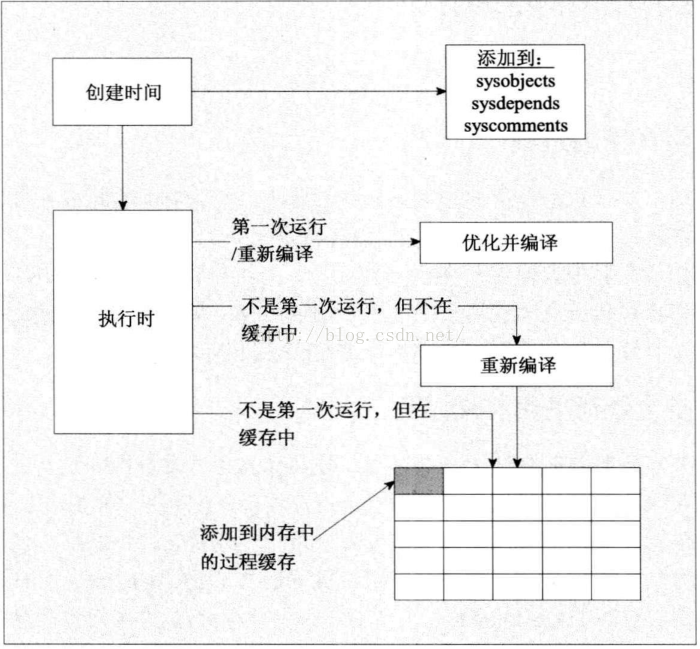
存储过程的缺点
1.对于存储过程不利之处要认识到的最重要的一点是,除非收到的干预(使用WITH RECOMPILE),否则只会在第一次运行存储过程时,或者当查询所涉及的表更新了统计信息时,擦会对存储过程进行优化。
2.使用WITH RECOMPILE选项
可以回避未使用正确的查询计划问题,因为可以确保为特定的某次运行创建新的计划。方法就是用WITH RECOMPILE选项。可以在运行时包含WITH RECOMPILE。只要在执行脚本中包含WITH RECOMPILE:
案例:EXEC spMySproc '1/1/2012' WITH RECOMPILE ;这告诉SQL Server 抛弃已有的执行计划并且创建一个新的计划——但是只有一次。也就是说,只有这次使用WITH RECOMPILE选项来执行存储过程,如果没有进一步的操作,SQLServer 一直继续新的计划。
也可以通过在存储过程中包含WITH RECOMPILE选项来时之变得更持久。如果使用这种方式,则在CREATE PROC 或 ALTER PROC 语句中的AS 语句前添加WITH RECOMPILE选项即可。如果通过该选项创建存储过程,那么无论在运行时选择了其他什么选项,每次存储过程时都会重新编译它。
存储过程实现递归
--递归--
create proc spFactorial
@ValueIn int,--输入参数
@ValueOut int OUTPUT--输出参数
as
declare @InWorking int;--输入值替换
declare @OutWorking int;--输出值替换
if @ValueIn>=1--判断输入值是否大于1
begin
select @InWorking = @ValueIn-1;
exec spFactorial @InWorking,@OutWorking OUTPUT;
select @ValueOut = @ValueIn* @OutWorking;
end
else
begin
select @ValueOut =1;
end
return;
go
create proc spFactorial
@ValueIn int,--输入参数
@ValueOut int OUTPUT--输出参数
as
declare @InWorking int;--输入值替换
declare @OutWorking int;--输出值替换
if @ValueIn>=1--判断输入值是否大于1
begin
select @InWorking = @ValueIn-1;
exec spFactorial @InWorking,@OutWorking OUTPUT;
select @ValueOut = @ValueIn* @OutWorking;
end
else
begin
select @ValueOut =1;
end
return;
go
--执行脚本
declare @WorkingOut int;
declare @WorkingInt int;
select @WorkingInt = 5;
exec spFactorial @WorkingInt,@WorkingOut OUTPUT;
print cast(@WorkingInt as varchar) + 'factorial is'+cast(@WorkingOut as varchar);
理解.NET程序集
定义:.net程序集可以和系统关联起来,并用来帮助实现真正复杂的操作。例如:可以在一个用户自定义函数中使用.net程序集,以从外部数据源提供数据(可能需要动态调用的数据源,如新闻源或股票报价)。
语法:CREATE ASSEMBLY <assembly name> AUTHORIZATION <owner name> FROM <path to assembly> WITH PERMISSION_SET =[SAFE|EXTERNAL_ACCESS|UNSAFE]
这里的CREATE ASSEMBLY和所有CREATE语句的作用一样——它指定了创建的对象类型和对象名称。
AUTHORIZATION用于设置运行该程序集的上下文。如果它有需要访问的表,那么在AUTHORIZATION中如何设置用户或角色名称将决定是否可以访问这些表。
在这之后是FROM子句。FROM子句指定了改程序集的路径以及该程序集的清单。
最后是WITH PERMISSION_SET 它有以下3个选项:
●SAFE:这个选项指的是安全。它现在程序集访问SQL Server的外部内容。像文件或网络就不能被程序集访问。
●EXTERNAL_ACCESS:允许外部访问,如网络文件或网络,但是要求程序集仍旧以托管代码形式运行。
●UNSAFE:此项是不安全的。它不仅允许程序集访问外部系统对象,也运行非托管代码。
使用存储过程的时机
优点:
●通常更佳的性能。
●可以用作安全隔离层(控制数据库的访问和更新方式)。
●可重用的代码。
●划分代码(可以封装业务逻辑)
●根据在运行时建立的动态而可以灵活执行。
缺点:
●不能跨平台移植。
●有些情况下可能因为错误的执行计划而被锁定。















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









