







1. 理解fork函数
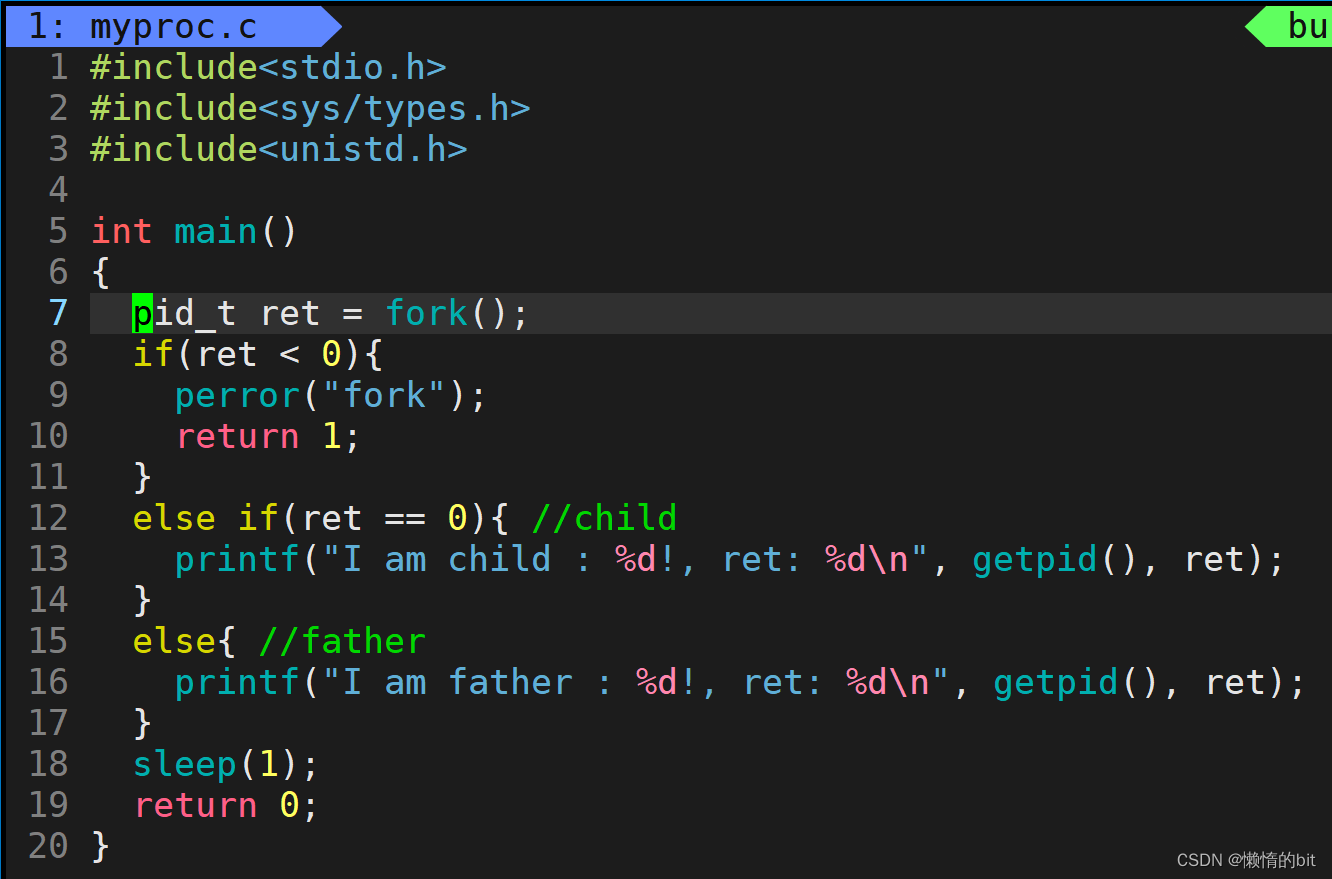

1.1 创建子进程
- 创建子进程,给子进程分配对应的内核结构,因为进程的独立性,子进程也要有自己的代码和数据
- 当我们没有加载程序,子进程没有自己的代码和数据,所以子进程只能使用父进程的代码和数据
- 代码:都是不可被写的,只能读取,所以父子共享,
- 数据:可能被修改,所以必须分离
1.2 写时拷贝
当子进程刚刚被创建时,子进程和父进程的数据和代码是共享的,即父子进程的代码和数据通过页表映射到物理内存的同一块空间。只有当父进程或子进程需要修改数据时,才将父进程的数据在内存当中拷贝一份,然后再进行修改

这种在需要进行数据修改时再进行拷贝的技术,称为写时拷贝技术
-
创建进程的时候,如果直接分离拷贝的话,可能根本用不到,即使用到了,也可能只是读取,所以编译器器编译程序的时候不会直接实现分离拷贝
-
在我们用的时候再分配,这是一种高效使用内存的一种表现,但是OS是无法在代码执行前预知那些空间会被访问
1、为什么数据要进行写时拷贝?
- 进程具有独立性。多进程运行,需要独享各种资源,多进程运行期间互不干扰,不能让子进程的修改影响到父进程
2、为什么不在创建子进程的时候就进行数据的拷贝?
- 子进程不一定会使用父进程的所有数据,并且在子进程不对数据进行写入的情况下,没有必要对数据进行拷贝,我们应该按需分配,在需要修改数据的时候再分配(延时分配),这样可以高效的使用内存空间。
3、代码会不会进行写时拷贝?
- 90%的情况下是不会的,但这并不代表代码不能进行写时拷贝,例如在进行进程替换的时候,则需要进行代码的写时拷贝
1.4 fork常规用法
- 一个进程希望复制自己,使子进程同时执行不同的代码段。例如父进程等待客户端请求,生成子进程来处理请求
- 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数
1.5 fork调用失败的原因
- 系统中有太多的进程,内存空间不足,子进程创建失败
- 实际用户的进程数超过了限制,子进程创建失败
1.5 代码共享

- CPU中有一个寄存器叫EIP,它是记录一个进程的上下文数据,方便重新加载时能从离开的位置运行
- 进程随时可能被中断(可能没有执行完),下次回来时,还必须从之前的位置继续运行(不是最开始的位置),
- 在fork进程创建上下文数据的时候,不用给子进程,它会认为自己的EIP起始值,就是fork之后的代码,所以结论是fork之后,父子进程的所有代码都是共享的
2. 进程终止->return/exit/_exit


- 进程终止时,操作系统会直接释放相关内核数据结构和对应的数据和代码
- 进程终止的常见方式
- 代码跑完,结果正确
- 代码跑完,结果不正确
- 代码没有跑完,程序崩溃了
- 如何终止一个进程
- 在mian函数内,用return语句终止进程,return 退出码
- 使用exit可以在代码任何地方调用,都表示直接终止进程
2.1 退出码->strerror

- 我们自己是可以使用这些退出码和含义,但是如果想自己定义,也可以自己设计一套退出方案
3. 进程等待->wait/waitpid
父进程通过进程等待的方式,回收子进程,获取子进程的退出信息

- wait可以验证并回收僵尸进程的问题,waitpid可以获取子进程退出结果的问题
- pid = -1,等待任意一个子进程,与wait等效,pid > 0,等待其进程ID与pid相等的子进程
- options:
默认为0表示阻塞等待,WNOHANG为非阻塞等待 - status:输出型参数
3.1 演示代码->阻塞等待


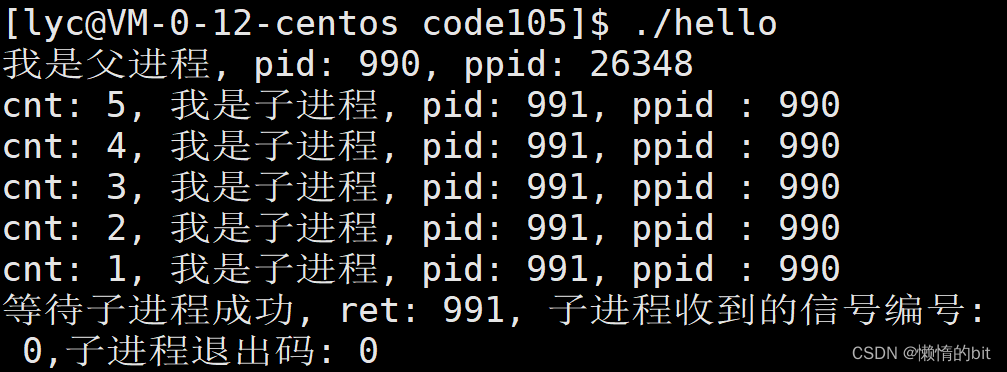
- 进程等待也可以用来回收僵尸进程
3.2 演示代码->非阻塞等待
#include <iostream>
#include <vector>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <unistd.h>
typedef void (*handler_t)(); //函数指针类型
std::vector<handler_t> handlers; //函数指针数组
void fun_one()
{
printf("这是一个临时任务1\n");
}
void fun_two()
{
printf("这是一个临时任务2\n");
}
// 在父进程以非阻塞方式等待时
// 只要向Load里面添加内容,就可以让父进程执行对应的方法喽!
void Load()
{
handlers.push_back(fun_one);
handlers.push_back(fun_two);
}
int main()
{
pid_t id = fork();
if(id == 0)
{
// 子进程
int cnt = 5;
while(cnt)
{
printf("我是子进程: %d\n", cnt--);
sleep(1);
}
exit(11); // 11 仅仅用来测试
}
else
{
int quit = 0;
while(!quit)
{
int status = 0;
pid_t res = waitpid(-1, &status, WNOHANG); //以非阻塞方式等待
if(res > 0)
{
// 等待成功 && 子进程退出
// WEXITSTATUS(status) 等价于 (status >> 8) & 0xFF
printf("等待子进程退出成功, 退出码: %d\n", WEXITSTATUS(status));
quit = 1;
}
else if( res == 0 )
{
// 等待成功 && 但子进程并未退出
printf("子进程还在运行中,暂时还没有退出,父进程将执行其他任务\n");
if (handlers.empty())
Load();// 加载任务
std::vector<handler_t>::iterator iter = handlers.begin();
while (iter != handlers.end())
{
(*iter)();
iter++;
}
//for(auto iter : handlers)
//{
// // 执行处理其他任务
// iter();
//}
}
else
{
//等待失败
printf("wait失败!\n");
quit = 1;
}
sleep(1);
}
}
}
3.3 阻塞等待 VS 非阻塞等待

- 进程阻塞本质:进程阻塞在系统函数的内部,
- 非阻塞等待:一般都是在内核中阻塞,等待被唤醒
- 阻塞等待:我们的父进程通过调用waitpid来进行等待,如果子进程没有退出,我们waitpid这个系统调用,立马返回
3.4 获取子进程status

- status并不是按照整数来整体使用的,而是按照比特位的方式,将32个比特位进行划分,只需要学习低16位
- 这也是上面为什么会写成status & 0x7F的原因
3.5 wait和waitpid的补充说明
1. 父进程通过wait/waitpid可以拿到子进程的退出结果,为什么要用wait/waitpid函数呢?直接使用全局变量不行吗?
- 进程具有独立性,直接使用全局变量是不行的,因为数据会发生写时拷贝,父进程无法拿到,而且还有信号
2. 既然进程是具有独立性的,进程退出码,不也是子进程的数据吗,父进程怎么拿到的呢?wait和waitpid究竟做了什么?

- 子进程的task_struct里面保留了任何进程退出时的退出信息,父进程就是在这里面拿到的
- wait/waitpid是操作系统的系统调用,而tast_struct是内核数据结构对象,自然wait/waitpid能拿到子进程的退出结果,和进程退出码
4. 进程替换->execl/execle等
fork()之后父子各自执行父进程代码的一部分,但如果子进程就想执行一个全新的程序呢,这时就可以通过进程的程序替换,来完成这个功能
- 程序替换,是通过特定的接口,
- 加载磁盘上的一个权限程序(代码和数据),
- 加载到调用进程的地址空间中,让子进程执行其他程序

- 将新的磁盘上的程序加载到内存,并和当前进程的页表,重新建立映射,
4.1 进程替换的原理
当进行进程程序替换时,有没有创建新的进程?
- 进程程序替换之后,该进程对应的PCB、进程地址空间以及页表等数据结构都没有发生改变,只是进程在物理内存当中的数据和代码发生了改变,所以并没有创建新的进程,而且进程程序替换前后该进程的pid并没有改变
子进程进行进程程序替换后,会影响父进程的代码和数据吗?
- 子进程刚被创建时,与父进程共享代码和数据,但当子进程需要进行进程程序替换时,也就意味着子进程需要对其数据和代码进行写入操作,这时便需要将父子进程共享的代码和数据进行写时拷贝,
- 此后父子进程的代码和数据也就分离了,因此子进程进行程序替换后不会影响父进程的代码和数据。
为什么要进程替换?
- 因为在一些特殊的场景下,我们有时候必须要让子进程执行新的程序
4.1 演示代码->进程替换(不创建子进程)


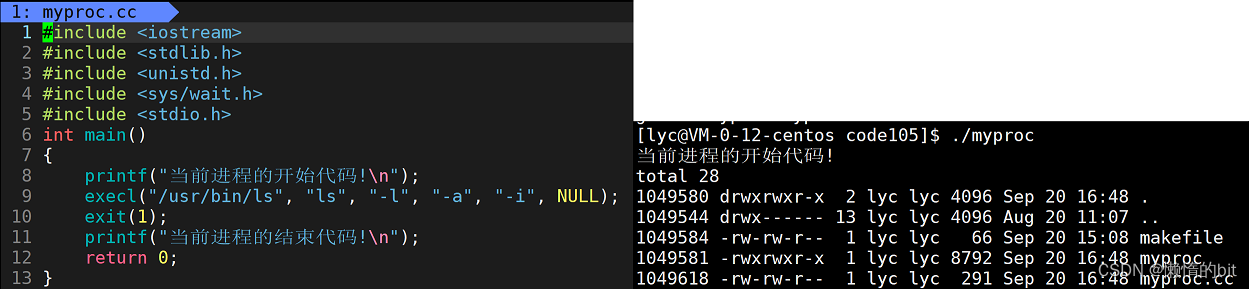

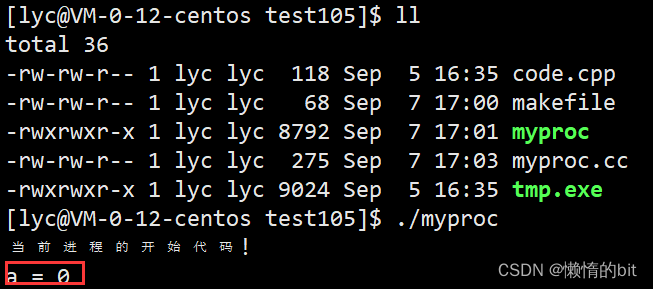
- execl根本不需要进行函数返回值判定,
- execl是程序替换,调用该函数成功之后,会将当前进程的所有的代码和数据都进行替换(包括已经执行的和没有执行的)
- execl一旦调用成功,后续所有代码,全都不会执行
4.2 演示代码->进程替换(创建子进程)
为什么我要创建子进程?
- 为了不影响父进程,我们想让父进程聚焦在读取数据,解析数据,指派进程执行代码的功能


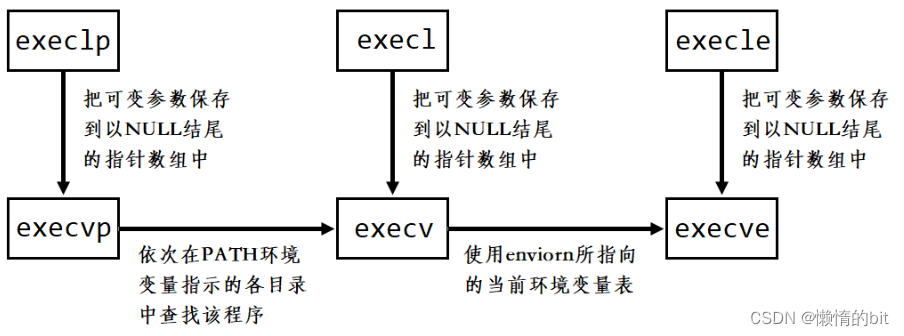
- 只有ececve才是函数调用接口
一个简单的shell
shell 运行原理:通过让子进程执行命令,父进程阻塞等待&&解析命令
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#define NUM 1024
#define SIZE 32
#define SEP " "
//保存完整的命令行字符串
char cmd_line[NUM];// "ls -a -l -i"
//保存打散之后的命令行字符串
char* g_argv[SIZE];// "ls" "-a" "-l" "-i"
//
int main()
{
//0. 命令行解释器,一定是一个常驻内存的进程,不退出
while (1)
{
//1. 打印出提示信息 [whb@localhost myshell]#
printf("[root@localhost myshell]# ");
fflush(stdout);
memset(cmd_line, '\0', sizeof cmd_line);
//2. 获取用户的键盘输入[输入的是各种指令和选项: "ls -a -l -i"]
if (fgets(cmd_line, sizeof cmd_line, stdin) == NULL)
{
continue;
}
cmd_line[strlen(cmd_line) - 1] = '\0';
//回车会触发\n "ls -a -l -i\n\0"
//3. 命令行字符串解析:"ls -a -l -i" -> "ls" "-a" "-i"
g_argv[0] = strtok(cmd_line, SEP); //第一次调用,要传入原始字符串
int index = 1;
if (strcmp(g_argv[0], "ls") == 0)
{
g_argv[index++] = "--color=auto";
}
if (strcmp(g_argv[0], "ll") == 0)
{
g_argv[0] = "ls";
g_argv[index++] = "-l";
g_argv[index++] = "--color=auto";
}
while (g_argv[index++] = strtok(NULL, SEP)); //第二次,如果还要解析原始字符串,传入NULL
//4. TODO,内置命令, 让父进程(shell)自己执行的命令,我们叫做内置命令,内建命令
//内建命令本质其实就是shell中的一个函数调用
if (strcmp(g_argv[0], "cd") == 0) //not child execute, father execute
{
if (g_argv[1] != NULL) {
chdir(g_argv[1]); //cd path, cd ..
}
continue;
}
//5. fork()创建父子进程
pid_t id = fork();
if (id == 0) //child
{
printf("下面功能让子进程进行的\n");
//cd cmd , current child path
execvp(g_argv[0], g_argv); // ls -a -l -i
exit(1);
}
//father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if (ret > 0) {
printf("exit code: %d\n", WEXITSTATUS(status));
}
}
}
- 获取命令行。
- 解析命令行。
- 创建子进程。
- 替换子进程。
- 等待子进程退出。

- 第四步中的内建命令本质其实就是shell中的一个函数调用,这里使用chdir进行调用














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









