






基础篇
ArrayList扩容规则
如果调用无参arrayList构造方法,则初始长度为0;如果构造带参的构造方法,则初始容量为指定长度。
1.调用add()方法
1.第一次扩容为10(从0到9)。
2.后续扩容都是前一次的1.5倍(创建一个新数组(0-14),将旧数组的元素拷贝到新数组中去,用新数组代替旧数组,旧数组没有被引用,作为垃圾被回收)。
1.5倍:先用右移(>>)除2,再加上原来的数组长度。
[0,10,15,22,33,49,73,109,163,244]
2.调用addAll()方法
若填加元素数量小于10,则直接扩容成10;若大于10则直接扩容成添加的元素数量。
若原本的数组容量已满,则选择下次扩容量与想添加的数组数间的较大值,进行扩容。
例:数组容量为10,已满。若再addAll()三个元素,则扩容为15;若再添加6个元素,则扩容为16.
Iterator_FailFast_FailSafe
1.failFast
(ArrayList)
一旦发现遍历的同时其他人来修改,则立即抛异常。
当执行一个遍历时,另一个线程修改了遍历的数据,则会立即抛出ConcurrentModificationException(并发修改异常)。
实现原理:记录了循环开始时的次数,如果在循环的过程中修改次数被改,则会尽快失败,抛出异常,阻止循环继续。
2.failSafe
(CopyWriteArrayList)
发现遍历的同时其他人来修改,应当能有应对策略,例如牺牲一致性来让整个遍历运行完成。
第一次遍历打印出来的依然是旧的循环,第二次遍历才会更新。
实现原理:读写分离。遍历时使用旧数组,在元素增加时创建一个新数组,长度是旧数组长度+1,然后将旧数组的元素copy到新数组中。添加是一个数组,遍历是另一个数组,互不干扰。遍历结束后回收旧数组,替换成新数组,于是在下次遍历的时候就遍历新的(添加后的)数组。
LinkedList与ArrayList比较
ArrayList:
1.基于数组,需要连续内存
2.随机访问快(根据下标访问)
3.尾部插入、删除性能好,其他部分插入、删除都会移动数据,因此性能低。
4.可以利用cpu缓存,一定程度上提升读写性能。
(局部性原理:读到一个元素后,会将一部分相邻的数据全部存入缓存中。)
LinkedList:
1.基于双向链表,无须连续内存
2.随机访问慢(要沿着链表遍历)
3.头尾插入删除性能高
4.占用内存多
HashMap
哈希表
应用场景:快速查找
通过计算元素的哈希码,得到元素的桶下标,计算元素位置。接下来只需要进行少量的比较即可找到元素。
当链表长度过长时,可以通过扩容减少链表长度。但如果元素的原始哈希码都一样时,即使扩容也无法改变链表长度,只能进行红黑树的树化。
底层数据结构,1.7与1.8有何不同?
1.7 数组+链表
1.8 数组+(链表|红黑树)
为什么要用红黑树?
红黑树:父节点左边都是比它小的元素;父节点右边都是比它大的元素。
数组链表过长会影响HashMap的性能。引入红黑树后链表过长也不会影响性能。
何时会树化?
1.链表长度大于8.
2.数组容量大于等于64.如果不够大会首先尝试扩容。
为何一上来不树化?
链表短时性能比红黑树好。树化会占用更多内存,没必要进行树化。
树化阈值为何是8?
正常情况下链表不会超过8.遭受到恶意攻击后链表长度才会过长。
1.红黑树用来避免Dos攻击,防止链表过长时性能下降,是偶然现象。hash表时间复杂度为O(1),且Node占用空间小;而红黑树时间复杂度为O(log₂n),且TreeNode占用空间较大。非必要时尽量使用链表。
2.hash值完全随机时,在hash表内按泊松分布。在负载因子为0.75的情况下,长度超过8的链表出现的概率为亿分之6.选择8使树化的几率足够小。
何时会退化为链表?
1.扩容时拆分树,树元素<=6时退化链表。
2.remove树节点,若root(根节点)、root.left(左孩子)、root.right(右孩子)、root.left.left(左孙子)有一个为null,也会退化链表。
索引如何计算?
key——>哈希——>二次哈希——>二次哈希%数组长度 / 二次哈希 &(按位与) (数组长度-1) 得到桶下标。
HashCode都有了,为何还要提供Hash()方法?
二次哈希可以降低哈希碰撞的概率,使哈希分布更为均匀。
数组容量为何是2的n次幂?
计算索引时,2的n次幂是使用按位与【 二次哈希&(数组长度-1) 】运算代替取模运算,效率更高。
put方法流程:
1.hashMap是懒惰创建数组,首次使用才创建数组。
2.计算索引(桶下标)。
3.如果桶下标还没人占用,创建Node占位返回。
4.如果桶下标已经有人占用:
如果已经是TreeNode走红黑树的添加或更新逻辑;
如果是普通Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑。
5.返回前检测容量是否超过阈值,一旦超过就进行扩容。
1.7和1.8的put流程有何不同?
1.8链表插入节点时采用尾插法,新的元素插入到原来链表的尾部。1.7采用头插法。
1.7是大于等于阈值且没有空位时才扩容,而1.8是大于阈值就扩容。
1.8在扩容计算Node索引时,会优化。
加载因子为何是0.75f
在空间占用和查询时间之间取得较好的平衡。
大于这个值,空间节省了,但链表就会比较长,影响性能。
小于这个值,冲突减少了,但扩容就会更频繁,空间占用多。
多线程下操作HashMap会有什么问题?
线程不安全,会造成数据错乱。先执行的数据可能被后面的数据覆盖掉,造成并发丢失现象。
1.7:扩容并发死链(线程2扩容后,由于头插法,链表顺序颠倒,但是线程1的变量e和next还引用了这两个节点[a引用b,b引用a,造成死链]),数据错乱
1.8:数据错乱
key能否为null?作为key的对象有什么要求?
HashMap的key可以为null。但其他Map(HashTable,TreeMap等)都不能为null,否则会出现空指针异常。
作为key的对象,必须重写HashCode和equals方法,并且key的内容不能修改(不可变)。
String对象的HashCode是怎样设计的?为何每次乘的都是31?
目的是达到较为均匀的散列效果,使每个字符串的hashCode足够独特。
1.字符串中的每个字符都能表现为一个数字,称为Si,其中i的范围是0~n-1.
2.散列公式为S_0∗31^{(n-1)}+ S_1∗31^{(n-2)}+ … S_i ∗ 31^{(n-1- i)}+ …S_{(n-1)}∗31^0
3.31 代入公式有较好的散列特性,并且 31 * h 可以被优化为
o 即 32 ∗h -h
o 即 2^5 ∗h -h
o 即 h≪5 -h
单例模式
单例模式的五种实现方式
1.饿汉式
类一初始化,实例就会提前创建出来。
破坏单例的场景:
1.反射破坏单例
通过调用无参构造方法,将私有的构造方法设为true,使它也可以被使用,然后再创建它的实例。导致它不再是单例。
预防:
在构造方法里加一个判断:如果instance不等于null,则抛出一个异常:单例对象不能重复创建。
2.反序列化破坏单例
把单例对象传给序列化方法,把对象变成字节流,再把字节流还原成一个对象,在反序列化时会构造一个新的对象。
预防:
写一个特殊的方法:readResolve()。里边返回instance。如果发现重写了这个方法,则将这个方法的返回值作为结果返回。
3.Unsafe破坏单例
调用unsafe方法破坏单例,目前没有找到预防方法。
2.枚举类(饿汉式)
可以很方便地控制对象的个数。
好处:
1.不怕反射(没有无参构造,不能反射创建枚举构造)、反序列化破坏单例。
2.Unsafe可以破坏枚举单例。
3.懒汉式
第一次调用getInstance时才会生成实例。
一开始的Instance变量不赋值,在调用时判断Instance是否为null,如果是则创建。不是则直接返回Instance。
线程安全问题:
线程不安全,线程1创建对象后还没来得及赋值,线程2就判断Instance为null,再次创建对象。
解决方法:
在方法上加一个synchronized,相当于在方法上加了一把锁,线程1进入方法后得到一把锁,线程2进入方法时发现锁对象被别人占用,则不执行,挂起。当线程1退出这个方法时会把锁解开,线程2继续执行时线程1的赋值已经完成,所以线程2可以直接使用线程1创建好的instance。(对性能有一定影响。只有首次创建对象时才需要锁,但是创建好对象后只能进一个线程,影响性能。)
首次创建对象时加入线程安全保护:
4.DCL懒汉式(双检锁)
在加锁之前先判断instance是否已创建好,如果已创建则直接返回instance,不会进入锁块。如果没有创建才进入锁,解决instance的竞争问题。当线程2拿到锁时,线程1挂起,线程2创建好对象并解锁,线程1经过第二个if判断发现已创建好对象,拿到直接返回的instance。
双检索的方法外面必须加volatile修饰。
解决共享变量的可见性和有序性问题。双检索变量是为了解决有序性问题。
线程1调用对象和给对象赋值的顺序有可能颠倒,可能先给对象赋值再调用对象(里边可能还有很多成员变量没有初始化);此时线程2在线程1给对象赋值后,就判断instance不等于null,然后返回了instance,此时线程1才调用对象。此时线程2拿到的就是不完整的对象。
加上volatile修饰后,volatile会在赋值语句之后加上一个内存屏障,阻止之前的赋值操作越过屏障跑到屏障下边,阻止指令的重排序。构造方法不可能越过屏障跑到赋值下边。
这样的话,即使线程2在线程1完成前进入方法,也无法在赋值完成之前拿到instance,会在锁中等待解锁后才拿到返回值。
5.内部类懒汉式
给静态变量赋值,代码一定会放入静态代码块执行。由静态代码块执行的代码,线程安全问题由jvm保证。
在类的内部创建一个内部类,内部类可以访问外部的私有变量和私有构造。在内部类里创建单例对象,赋值给内部静态变量。创建过程是线程安全的,而且没有用到这个内部类的时候不会初始化instance,所以是懒汉式。
jdk中有哪些地方体现了单例模式
-
Runtime() 体现了饿汉式单例
-
System中的Console方法体现了双检锁懒汉式单例
-
Collections 中的 EmptyNavigableSet 内部类懒汉式单例
-
ReverseComparator.REVERSE_ORDER 内部类懒汉式单例
-
Comparators.NaturalOrderComparator.INSTANCE 枚举饿汉式单例
并发篇
并发-线程状态
java中的线程状态
Java线程状态之间的转换
线程状态_五种状态vs六种状态
五种状态:操作系统层面
分到CPU时间的:运行
可以分到CPU时间的:就绪
分不到CPU时间的:阻塞
并发-线程池核心参数
1.核心线程数:最多保留的线程数(可以为0)
2.最大线程数:核心线程+救急线程
3.workQuene:阻塞队列,对任务起到缓冲作用。还未进行的线程不会直接成为救急线程,而是先存在任务队列中,等核心线程空闲下来后,会被获取执行。(上限控制)
4.救急队列:当核心线程都在运行,任务队列也都放满了,再添加新任务则会添加救急线程。不会保留在线程池中,而是有一定的生存时间。
5.生存时间keepAliveTime;时间单位unit。如果在这个时间范围内没有线程需要执行,则会从线程池把它去掉
6.拒绝策略:核心线程和任务队列满了,救急线程也超过了最大线程数上限,如果还有新任务创建,则采用handler拒绝策略。
7.线程工厂:为线程对象起个好名字。
拒绝策略:
任务队列:先进先出
任务进入后,如果有核心线程则进入核心线程执行;
如果核心线程满了则进入任务队列等待;
如果任务队列满了则创建救急线程(插队执行),执行完毕后救急线程再从任务队列里取靠前的任务执行,执行完所有任务队列后直接从线程池移除救急队列;
当救急线程也忙时,触发拒绝策略:
1.抛异常 AbortPolicy() (默认):线程池资源耗尽时直接抛异常,无法执行新任务。
2.调用者执行 CallerRunsPolicy():由调用者执行超出的任务。
3.丢弃新 DiscardPolicy():丢弃新任务,不报异常和错误。
4.丢弃老 DiscardOldestPolicy():把最早加入队列的任务丢弃掉,再把新任务加入任务队列中。
wait与sleep的比较
共同点:
wait(),wait(long),sleep(long)的效果都是让当前线程暂时放弃CPU的使用权,进入阻塞状态。
不同点:
方法归属不同
sleep(long)是Thread的静态方法。
wait,wait(long)都是Object的成员方法,每个对象都有。
醒来时机不同
sleep(long)和wait(long)的线程都会在等待响应的毫秒数后醒来。
wait()和wait(long)还可以被notify()唤醒,wait()如果不唤醒就会一直等下去。他们都可以被打断唤醒。
锁特性不同
wait方法的调用必须先获取wait对象的锁,而sleep无此限制。
wait方法执行后会释放对象锁,允许其他线程获得该对象锁(我放弃,但你们还可以用)
sleep如果在synchronized代码块中执行,不会释放对象锁(我放弃,但你们也用不了)
Lock与synchronized比较
语法层面
synchronized是关键字,源码在jvm中,用c++语言实现。
Lock是接口,源码由jdk提供,用Java语言实现。
使用synchronized时,退出同步代码块,锁会自动释放。
使用Lock时,需要手动调用unlock方法释放锁。
功能层面
二者均属于悲观锁,都具备互斥(一个线程成功,其他线程阻塞),同步(一个线程运行时发现需要其他线程的结果,则等待其他线程返回结果后才继续),锁重入(持锁的线程可以对对象重复加锁)功能。
Lock提供了许多synchronized不具备的功能,如获取等待状态、公平锁(不允许插队,先来先得)、可打断、可超时、多条件变量。
Lock有适合不同场景的实现,如ReentrantLock(基本的带有重入功能的锁),ReentrantReadWriteLock(更适合读多写少的场景)。
性能层面
没有竞争时,synchronized做了很多优化,如偏向锁,轻量级锁,性能好。
竞争激烈时,Lock的实现通常会提供更好的性能。
volatitle
volatitle能否保证线程安全?
线程安全要考虑三个方面:可见性,有序性,原子性。
1.可见性:一个线程对共享变量修改,另一个线程能看到最新结果。
2.有序性:一个线程内代码按照编写顺序执行。
3.原子性:一个线程内多行代码以一个整体运行,期间不能有其他线程代码插队。
volatile能够保证共享变量的可见性和有序性,不能保证原子性。
原子性:
一个线程执行时,可能进行了变量操作,但并未保存,此时另一个线程插队又对此变量进行操作,导致最后变量结果出问题。
可见性:
当CPU多次从内存中拿到同一个值时,JIT对代码进行优化:直接将拿到值后的代码缓存,提高性能。此时线程2再对内存中的变量进行操作,原先的线程就陷入死循环。而后续的线程3则可读到改变后的代码。
解决办法:使用volatile。JIT发现变量使用volatile修饰,则不对这个变量进行优化。
有序性:
指令重排序。可以通过volatile禁止。
原理:volatile使用内存屏障指定排序。对写操作,volatile会添加一个向上屏障,阻止上面的代码跑到下面去;而对于读操作,volatile会添加一个向下屏障,阻止下边的代码被先读到。所以在使用volatile时需要注意读写的顺序和volatile指定对象的位置。写的时候volatile要在最后位置,而读的时候要让volatile先读。
悲观锁和乐观锁
1.悲观锁的代表是synchronized和Lock锁。
1.核心思想:线程只有占有了锁,才能去操作共享变量,每次只有一个线程占锁成功,获取锁失败的线程都得停下来等待。
2.线程从运行到阻塞、再从阻塞到唤醒,涉及线程上下文切换,如果频繁会影响性能。
3.实际上,线程在获取synchronized和Lock锁时,如果锁已经被占用,都会做几次重试操作,减少阻塞机会。
2.乐观锁的代表是AtomicInteger,使用cas(compareAndSetInt对比并赋值)来保证原子性。
1.核心思想:无须加锁,每次只有一个线程能够成功修改共享变量,其他失败的线程不需要停止,不断重试直至成功。
2.由于线程一直运行,不需要阻塞,因此不涉及线程上下文切换。
3.它需要多核CPU支持,且线程数不应超过CPU核数。
HashTable与ConcurrentHashMap比较
1.HashTable与ConcurrentHashMap都是线程安全的Map集合。
2.HashTable与ConcurrentHashMap的键和值都不能为空。
3.HashTable并发度低,整个HashTable对应一把锁,同一时刻,只能有一个线程操作它。并发度很低。
4._1.8之前ConcurrentHashMap使用了Segment+数组+链表的结构,每个Segment对应一把锁,如果多个线程访问不同的Segment,则不会冲突。
5._1.8开始ConcurrentHashMap将数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突。
扩容
HashTable初始容量为11,每次扩容都是上次的容量*2+1;
1.7 初始化:饿汉式。
ConcurrentHashMap是一个Segment数组,Segment数组每个元素中都会套一个小数组,如果小数组中有索引冲突,则会构成一个链表。Segment数组(并发度)不能扩容。
Segment索引计算:线程key——>原始hash——>二次hash——>找二次hash值的二进制的高n位(n为数组容量的指数),转换成十进制,得到Segment下标。——>桶下标:小数组位置(找二次哈希值的二进制最低n位,n为小数组长度的指数)
小数组扩容:元素个数超过容量的3/4,容量翻倍。插入元素使用头插法,但是因为加了锁,所以不会造成死链。
1.8 初始化:懒汉式。
尾插法。只要满3/4就会扩容。
ConcurrentHashMap容量 * 3/4 > 元素个数。
只要操作的不是同一个链表头,就可以并发执行,提高性能。
扩容:到达扩容阈值后,创建出新数组,容量翻倍,将旧数组每个链表的数据迁移到新链表(从后往前),形成新的链表。旧的链表头部变成ForwardingNode,显示此链表已被处理过。旧数组的所有链表头部全都变成ForwardingNode后,表示数组全部处理完成,替换为新的数组。
扩容时的并发问题:
get:当链表还未替换完成时,新的线程要读取链表数据?通过链表头是否为ForwardingNode判断链表内容是否被替换。如果链表还未被替换,则直接get到旧的链表数据;如果要get的数据已经迁移到新的table,查询线程去get替换过的新的链表数据。扩容线程在进行链表迁移时,next指向发生变化,需要重新创建节点对象。
put:当要put的对象还未被替换且节点不需要变化,put可以并发执行;当要put的对象节点需要变化,会被链表头加锁阻塞;当要put的节点已经完成了变化,不能去新的表中去put,而是会帮忙迁移未替换完的数据。
对ThreadLocal(线程隔离)的理解
ThreadLocal作用:
1.线程隔离。线程间:ThreadLocal可实现资源对象的线程隔离,让每个线程各用各的资源对象,避免争用引发的线程安全问题。
2.资源共享。线程内:ThreadLocal同时实现了线程内的资源共享。
ThreadLocal原理:关联资源
每个线程中都有一个独立的ThreadLocalMap类型的成员变量,用来存储资源对象。
1.调用set方法,就以ThreadLocal自己作为key,资源对象当作value,放入当前线程的ThreadLocalMap集合中。
2.调用get方法,就是以ThreadLocal自己作为key,到当前线程中查找关联的资源值。
3.调用remove方法,就是以ThreadLocal自己作为key,移除当前线程中关联的资源值。
ThreadLocalMap:懒汉式,使用时才创建。
当每创建一个新的ThreadLocal对象,它就会为ThreadLocal分配一个hash值,一开始hash值是0,索引也是0;再创建一个ThreadLocal对象,它的hash值是0+一个大值,计算桶下标,放在对应位置。
扩容:元素个数超过容量的2/3时会扩容。容量翻倍,所有key重新计算索引。
索引冲突:线性探测法。从冲突位置开始找下一个空闲位置。
ThreadLocal_key内存释放时机
为什么ThreadLocalMap中的key(即ThreadLocal)要设计为弱引用?
一旦别的地方不再占用内存中的key,弱引用对象占用的内存就可以直接释放掉。
1.Thread可能需要长时间运行(如线程池中的线程),如果key不再继续使用,需要在内存不足时释放其占用的内存。
2.但GC仅仅能让key释放,后续还要根据key是否为null来进一步释放值的内存。释放时机:
1.获取key发现null key
2.set key时会使用启发式扫描,清除临近的null key,启发次数与元素个数、是否发现null key有关。
3.remove(推荐)。因为一般使用ThreadLocal时都把它作为静态变量,因此GC无法回收。
虚拟机
虚拟机-jvm内存结构
方法区:存放类加载时的方法
堆:存放new出来的对象
虚拟机栈:记录方法内的局部变量和方法参数等信息。
程序计数器:记录main线程执行中执行其他线程,回到主线程时从哪里开始执行。
本地方法栈:调用本地方法接口实现由操作系统实现的功能(本地库)
GC:内存不足时将不再使用的地方进行垃圾回收。
解释器:将字节码转换成CPU可以理解的机器码。
即时编译器(JIT):将频繁调用的热点代码翻译成机器代码并缓存起来,提高执行效率。
线程私有:程序计数器、虚拟机栈
线程共享:堆、方法区
哪些区域会有内存溢出
程序计数器不会有内存溢出,别的区域都有可能出现内存溢出情况。
出现OutOfMemoryError情况
1.堆内存耗尽:对象越来越多,并且一直在使用,不能被垃圾回收。
2.方法区内存耗尽:加载的类越来越多,很多框架都会在运行期间产生新的类。
3.虚拟机栈累积:每个线程最多占用1M内存,线程个数越来越多,又长时间运行不销毁时。
出现StackOverflowError情况
1.虚拟机栈内部:方法调用次数过多。
方法区、永久代、元空间的关系
方法区:JVM规范中定义的一块内存区域,用来存储类元数据,方法字节码,即时编译器需要的信息等。
永久代:Hotspot虚拟机对JVM规范的实现(1.8前)。
元空间:Hotspot虚拟机对JVM规范的实现(1.8后),使用本地内存作为这些信息的存储空间。
JVM内存参数
对于JVM内存配置参数:-Xmx10240m -Xms10240m -Xmn5120m -XX:SurvivorRatio=3 其最小内存值和Survivor区总大小分别是?
-Xmx10240m
Xmx:Java虚拟机最大内存10G
m:单位,兆字节
-Xms10240m
Xms:Java虚拟机的最小内存数10G
m:单位,兆字节
-Xmn5120m:5G
Xmn:虚拟机中新生代的内存数为5G,则剩下的老年代内存数为5G
-XX:SurvivorRatio=3
JVM垃圾回收算法
标记:找到不能被作为垃圾回收的对象并标记。标记的对象保留,未被标记的对象作为垃圾释放。
标记清除法
标记:将一定不能被回收的根对象作为GC Root对象,从根对象出发,沿着它的引用链找当前对象有没有被根对象引用到。若是则不能被回收,加标记。若否,则不加标记,GC时释放掉。
清除:有标记则保留,没有标记则释放。
缺点:
释放后的内存不连续,造成内存碎片问题。需要连续内存时碎片内存不够用。
标记整理法
标记清除的基础上多了整理阶段。
整理:移动未被清除的对象朝一端靠拢,避免了内存碎片的问题。
缺点:
多了整理步骤,要重新计算内存的引用地址,内存复制等,效率会变低。
标记复制法
把内存分成两部分,一部分用来存对象,一部分作为空闲区域。将标记的需要存活的对象复制到空闲区域,复制完成后将原来那部分所有内容清空。此时空区域再作为空闲区域,复制后的区域作为存对象区域。整个过程不会有内存对象产生。且效率比标记整理高。
缺点:
占用了一份额外的内存。
JVM垃圾回收
GC和分代回收算法
GC的目的:
实现无用对象内存自动释放,减少内存碎片,加快分配速度。
GC要点:
1.回收区域是堆内存,不包括虚拟机栈,在方法调用结束会自动释放方法占用的内存。
2.判断无用对象,使用可达性分析算法,三色表记法标记存活对象,回收未标记对象。
3.GC具体的实现称为垃圾回收器。
4.GC大都采用分代回收思想,理论依据是大部分对象朝生夕死,用完就立刻可以回收,另有少部分对象会长时间存活,每次很难回收,根据这两类对象的特性将回收区域分为新生代和老年代,不同区域应用不同回收策略。
5.根据GC的规模可分成Minor GC(小范围垃圾回收,新生代),Mixed GC(混合收集,新生代和部分老年代被回收),Full GC(全面回收,新生代与老年代内存全部不足,停顿明显)。
分代回收
1.伊甸园eden,最初对象诞生在这里。与幸存区合称新生代。
2.幸存区survivor,当伊甸园内存不足,回收的幸存对象到这里,分成from和to,采用标记复制法。
3.老年代old,当幸存区对象熬过几次回收(最多15次),晋升到老年代(幸存区内存不足或大对象会导致提前晋升)。
GC规模
1.Minor GC(小范围垃圾回收):发生在新生代的垃圾回收,暂停时间短。
2.Mixed GC(混合收集):新生代+老年代部分区域的垃圾回收,G1收集器特有。
3.Full GC(全面回收):新生代+老年代完整垃圾回收,暂停时间长,应尽力避免。
三色标记问题
用三种颜色记录对象的标记状态。
黑:已标记 灰:标记中 白:还未标记
并发漏标问题
漏标问题-----记录标记过程中变化
1.Incremental Update 增量更新
1.只要赋值发生,被赋值的对象就会被记录。
2.Snapshot At The Beginning,SATB 原始快照
1.新加对象会被记录
2.被删除引用关系的对象也被记录
垃圾回收器
Parallel GC 并行GC
1.新生代eden内存不足发生Minor GC,标记复制算法STW
2.老年代old内存不足发生Full GC,时间长,标记整理算法STW
3.使用场景:注重吞吐量的应用程序(不注重响应时间)
ConcurrentMarkSweep GC 并发标记GC
1.老年代标记阶段并发标记,重新标记时需要暂停STW,并发清除。(标记+清除算法,有内存碎片)
2.Failback Full GC。并发失败的时候会触发Full GC。
3.使用场景:注重响应时间
垃圾回收器G1
1.响应时间与吞吐量兼顾
2.将整个堆内存划分为多个区域,每个区域都可以充当伊甸园区、幸存区,老年代,专门用来存储大对象的空间。
工作流程:
1.新生代回收:伊甸园区空间不足,标记复制
2.并发标记:老年代并发标记,重新标记时需要STW。
3.混合收集:并发标记完成,开始混合收集,参与复制的有伊甸园、幸存区、老年区,其中老年区会根据暂停时间目标,选择部分回收价值高的区域,复制时STW
4.Failback Full GC。
内存溢出
项目中什么情况下会内存溢出,怎么解决的
1.误用固定大小线程池
当前线程任务超时后,其余任务将被加入任务队列中,任务对象所耗费的内存会导致整个堆内存耗尽,导致内存溢出异常。
解决方法:
不要用工具类提供的线程池来创建线程池。而是使用线程池时自己使用线程池的构造方法,根据实际情况设置一个有大小限制的任务队列。超过任务队列大小时会报错,但是不会导致内存溢出。
2.误用带缓冲线程池
线程数没有上限,线程数耗尽了内存资源导致资源溢出。解决方法同1.
解决方法:
不要用工具类提供的线程池来创建线程池。而是使用线程池时自己使用线程池的构造方法,根据实际情况设置一个有大小限制的任务队列。超过任务队列大小时会报错,但是不会导致内存溢出。
3.查询数据量太大导致内存溢出
如果直接查询的话商品量过多,占用内存过大,而且可能很多人同一时间查。
解决方法:
使用分页查询,一次查几十条。
4.动态生成类导致的内存溢出
循环动态生成类,运行一千多次的时候元空间出现内存溢出。一直调用类导致对象不能回收,类加载器也不能回收,元空间的内存不能释放。耗尽后就会出现异常。
解决方法:
把静态变量对象变成局部变量,使用后就可以回收掉,类加载器以及动态生成的类都可以回收,释放元空间。
类加载
类加载过程
1.加载
①将类的字节码载入方法区,并创建.class对象。
②如果此类的父类没有加载,先加载父类。
③加载是懒惰执行。
2.链接
①验证-验证类是否符合字节码规范,合法性、安全性检测。
②准备-为static变量分配空间,设置默认值。
③解析-将常量池的符号引用解析为直接引用。
3.初始化
①执行静态代码块与非final静态变量赋值。
②初始化是懒惰执行。
双亲委派
双亲委派:优先委派上级类加载器进行加载,
如果上级类加载器
①能找到这个类,则由上级加载,加载后该类也对下级加载器可见。
②找不到这个类,则下级类加载器才有资格执行加载。
| 名称 | 加载哪的类 | 说明 |
|---|---|---|
| Bootstrap ClassLoader 启动类加载器 | JAVA_HOME/jre/lib | 无法直接访问 |
| Extension ClassLoader 扩展类加载器 | JAVA_HOME/jre/lib/ext | 上级为Bootstrap,显示为null |
| Application ClassLoader 应用程序类加载器 | classpath | 上级为Extension |
| 自定义类加载器 | 自定义 | 上级为Application |
可以自己写一个java.lang.System吗
不行。
1.假设你自己的类用双亲委派,那么优先由启动器加载真正的System。
2.假设不用双亲委派,那么类加载器加载假冒的System时会先加载父类java.lang.Object,没有用委派的话找不到Object,会失败。
3.实际操作中类加载器加载java打头的类,会抛安全异常。
4.jdk9以上版本对特殊包名与模块绑定,编译不通过。
双亲委派的目的
1.让上级类加载器中的类对下级共享(反之不行),即能让你的类依赖到jdk提供的核心类。
2.让类的加载有优先次序,保证核心类优先加载。
对象引用类型
1.强引用
内存空间不足时不会被GC回收。当没有任何引用指向它或者指向它的对象为null的时候会被GC垃圾回收。
2.软引用
适用于缓存。第一次回收时不会被回收,而后当内存满,进行GC回收时会被回收。防止内存溢出。当空间充足时不会被回收。
3.弱引用
垃圾回收时直接被回收。
4.虚引用
必须配合引用队列使用。对象被回收时虚引用入队,释放关联的外部资源。
finalize
当重写了finalize方法的对象,在构造方法调用时,jvm会将其包装成一个finalizer对象,并加入unfinalized队列中(双向链表)。当进行垃圾回收时,将这些对象对应的finalizer对象加入一个空的队列ReferenceQueue(单向链表)。
真正的回收时机:即时对象无人引用,由于finalizer还在引用它,所以无法被回收。finalizerThread线程从ReferenceQueue中逐一取出每个finalizer对象,把他们从链表中断开,这样没人引用它,下次gc被回收。
为什么finalize方法非常不好,非常影响性能?
1.finalizeThred是守护线程,代码可能还没执行完,线程就结束了,导致资源未正确释放。
2.finalize执行中不会报异常,判断不了释放资源时的错误。
影响性能:
1.第一次被gc时不能及时释放内存。
2.gc本就是因内存不足引起,finalize调用又很慢,对象不及时释放会进入老年代,老年代内存不足会引起full gc,full gc后如果内存还跟不上创建新对象速度,就会导致内存溢出。
Spring refresh 流程
Spring refresh 概述
refresh 是 AbstractApplicationContext 中的一个方法,负责初始化 ApplicationContext 容器,容器必须调用 refresh 才能正常工作。它的内部主要会调用 12 个方法,我们把它们称为 refresh 的 12 个步骤:
准备工作
1.prepareRefresh 准备工作。创建和准备环境对象,管理各种键值信息。
创建beanFactory
2.obtainFreshBeanFactory 创建beanFactory(如果有的话获取,没有的话创建),bean的创建、依赖注入、初始化。BeanDefinition来源:xml、配置类、组件扫描。
3.prepareBeanFactory 准备beanFactory,初始化成员变量。
beanExpressionResolver 用来解析 SpEL(#{});
propertyEditorRegistrars 注册类型转换器(${});registerResolvableDependency 来注册 beanFactory 以及 ApplicationContext,让它们也能用于依赖注入;
beanPostProcessors用于bean的功能扩展。
4.postProcessBeanFactory 空实现,留给子类扩展beanFactory
5.invokeBeanFactoryPostProcessors 后处理器扩展beanFactory。通过后处理器扩展bean功能。
6.registerBeanPostProcessors 准备bean后处理器。从beanFactory中找到bean的后处理器,添加至集合。
准备ApplicationContext
7.initMessageSource 国际化功能
8.initApplicationEventMulticaster 添加事件广播器成员,事件发布器
9.onRefresh 空实现,留给子类扩展
10.registerListeners 注册事件监听器对象,用来收事件
11.finishBeanFactoryInitialization 初始化单例bean对象,将 beanFactory 的成员补充完毕,解析 @Value 中的 ${ },单例池缓存所有单例对象
12.finishRefresh 添加生命周期处理器
1.处理名称,检查缓存
一级缓存:放单例成品对象;二级缓存:放单例工厂的产品;三级缓存:放单例工厂。
2.检查父工厂
如果父子容器名称重复,优先子容器bean。
3.检查DependsOn
有依赖关系的bean创建次序有保障。无依赖关系时,A dependsOn B,则B先创建。
4.按Scope创建Bean
创建单例,去单例池获取bean,有则返回,无则进入创建流程。
创建多例,进入创建流程。从不缓存bean,直接创建新的。
创建自定义scope,例如request,到request域获取bean,有则返回,无则进入创建流程。
5.创建Bean
创建Bean实例 1.加@Autowired注入bean实例 2.有唯一的带参构造 3.默认构造(暴力反射把私有设为true)
依赖注入 注解匹配、根据名字/类型匹配、精确指定(优先级:精确>名字/类型>注解匹配)
初始化 方式:Aware接口、@PostConstruct、接口回调、@Bean、创建aop代理。
登记可销毁bean 实现AutoCloseable接口/自定义destroyMethod/提供close方法/@PreDestroy,即可记录下来,存储在bean工厂的成员变量中。多例scope不会存储。
6.类型转换
7.销毁bean
销毁时机:
单例bean:close时会逐一销毁。
多例bean:手动调用destroyBean销毁
自定义bean:作用域对象生命周期结束时。
事务失效的几种场景
1.抛出检查异常导致事务无法正确回滚。
-
原因:Spring 默认只会回滚非检查异常
-
解法:配置 rollbackFor 属性
-
@Transactional(rollbackFor = Exception.class)
-
2. 业务方法内自己 try-catch 异常导致事务不能正确回滚(只try-catch,没抛出去异常(return))
-
原因:事务通知只有捉到了目标抛出的异常,才能进行后续的回滚处理,如果目标自己处理掉异常,事务通知无法知悉
-
解法1:异常原样抛出
-
在 catch 块添加
throw new RuntimeException(e);
-
-
解法2:手动设置 TransactionStatus.setRollbackOnly()
-
在 catch 块添加
TransactionInterceptor.currentTransactionStatus().setRollbackOnly();
-
3. aop 切面顺序导致导致事务不能正确回滚(内层捉住异常,抛给外层后外层捉住异常但没抛出)
-
原因:事务切面优先级最低,但如果自定义的切面优先级和他一样,则还是自定义切面在内层,这时若自定义切面没有正确抛出异常…
-
解法1、2:同情况2 中的解法:1、2
-
解法3:配置类调整切面顺序,在 MyAspect 上添加
@Order(Ordered.LOWEST_PRECEDENCE - 1)(不推荐)
4. 非 public 方法导致的事务失效
-
原因:Spring 为方法创建代理、添加事务通知、前提条件都是该方法是 public 的
-
解法1:改为 public 方法
5. 父子容器导致的事务失效
父子容器,WebConfig 对应子容器,AppConfig 对应父容器,发现事务依然失效
-
原因:子容器扫描范围过大,把未加事务配置的 service 扫描进来
-
解法1:各扫描各的,不要图简便
-
解法2:不要用父子容器,所有 bean 放在同一容器
6. 调用本类方法导致传播行为失效
-
原因:本类方法调用不经过代理,因此无法增强
-
解法1:依赖注入自己(代理)来调用
-
解法2:通过 AopContext 拿到代理对象,来调用
-
解法3:通过 CTW,LTW 实现功能增强
7. @Transactional 没有保证原子行为(指令交错)
上面的代码实际上是有 bug 的,假设 from 余额为 1000,两个线程都来转账 1000,可能会出现扣减为负数的情况
-
原因:事务的原子性仅涵盖 insert、update、delete、select … for update 语句,select 方法并不阻塞
8. @Transactional 方法导致的 synchronized 失效
针对上面的问题,能否在方法上加 synchronized 锁来解决呢?
答案是不行,原因如下:
-
synchronized 保证的仅是目标方法的原子性,环绕目标方法的还有 commit 等操作,它们并未处于 sync 块内
-
可以参考下图发现,蓝色线程的查询只要在红色线程提交之前执行,那么依然会查询到有 1000 足够余额来转账
-
解法1:synchronized 范围应扩大至代理方法调用
-
解法2:使用 select … for update 替换 select
springMVC执行流程
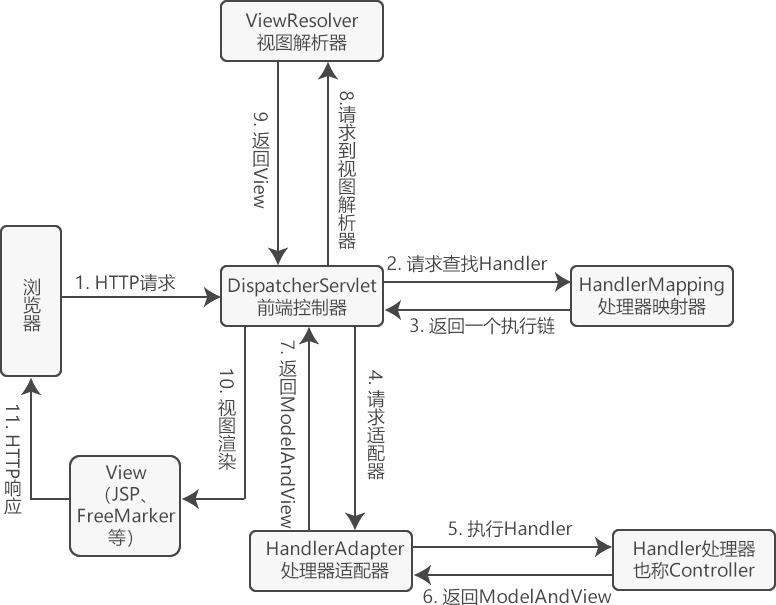
初始化阶段
-
在 Web 容器第一次用到 DispatcherServlet 的时候,会创建其对象并执行 init 方法
-
init 方法内会创建 Spring Web 容器,并调用容器 refresh 方法
-
refresh 过程中会创建并初始化 SpringMVC 中的重要组件, 例如 MultipartResolver,HandlerMapping,HandlerAdapter,HandlerExceptionResolver、ViewResolver 等
-
容器初始化后,会将上一步初始化好的重要组件,赋值给 DispatcherServlet 的成员变量,留待后用
匹配阶段
-
用户发送的请求统一到达前端控制器 DispatcherServlet
-
DispatcherServlet 遍历所有 HandlerMapping ,找到与路径匹配的处理器
① HandlerMapping 有多个,每个 HandlerMapping 会返回不同的处理器对象,谁先匹配,返回谁的处理器。其中能识别 @RequestMapping 的优先级最高
② 对应 @RequestMapping 的处理器是 HandlerMethod,它包含了控制器对象和控制器方法信息
③















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









