






各位小伙伴们,父老乡亲们,你们好!!!
本篇是一个有关深度学习的非常非常非常基础的博客!!!所以可能对于一位刚入门或者还没有入门深度学习的小伙伴有些许作用,大佬可以绕过这篇Blog,嘿嘿。
本篇博客涉及到的内容如下:
1.从MNIST手写字体识别窥探pytorch的工作机制
2.个人的学习经验总结
好啦,废话就不多说了,直接上干货。
1.从LeNet手写字体识别窥探pytorch的工作机制
LeNet手写字体识别网络从现在的角度来看是一个非常简单的深度学习网络模型,该模型是由图灵奖获得者在1998年Yann LeCun提出的,并且应用到了具体的实践当中(泰库辣!!!)。LeNet模型的网络结构在CSDN上有许多讲解的文章,在这里就不再进行赘述。注意:如果看到这里,你不知道什么是LeNet网络结构,一定一定一定要去看一些其他博主的博客,然后记得再回到这篇博客。(因为这会使我的博客浏览量+1)
在我看来,任何一个网络模型都是由三部分组成,即数据的预处理(尺寸变化,归一化等等,如果你是基于私有数据集进行网络训练的话,还需要重写Class datasets(这部分的内容后面会提到(也许会是下一篇博客),请不要着急))、网络模型的搭建、模型训练过程的可视化。
接下来,咱们来看一下该如何搭建一个LeNet手写字体识别网络。
Part1.数据预处理部分:
1.实例化数据处理(Transform)操作
在这里,需要用到torchvision中的transforms package,一般就是使用如下代码来实现具体的数据处理操作(Resize,Crop,BN等等)
import torchvision.transforms as tf
transforms = tf.Compose([tf.Resize([32, 32]), #将图片的shape变成[32,32]
tf.ToTensor()]) #将图片转换为模型可以处理的张量数据Compose([])是将多个数据处理操作组合在一起,需要将多个数据处理操作(如归一化,BN等)组合成一个列表的形式,再传给Compose,列表中不同的数据处理操作需要用逗号分开。
2.从官网下载MNIST数据集,使用torchvision中的datasets package
(from torchvision import datasets)
datasets内置了多个数据集,可以使用
dir(datasets)语句来查看datasets内置了哪些数据集(如CIFAR10,CIFAR100,FashionMNIST等等)。(建议在Jupyter Notebook上运行一下该命令)
接下来就可以使用如下代码来下载所需的训练集和验证集:
from torchvision import datasets
data_path = "D:\pycharm-projects\handwriteidentity\minsit"
transforms = tf.Compose([tf.Resize([32, 32]),
tf.ToTensor()])
data_val = datasets.MNIST(data_path, train=False, download=True, transform=transforms)我们首先分析一下上述代码,第一行是导入需要的库,第二行是需要定义数据集的保存路径,第三行是实例化的预处理操作,第四行是下载MNIST数据集,可见,核心代码是第四行。我们先看下面的一张图片,可以看到其初始化函数中包含了5个参数,root是指数据集保存的路径(字符串数据类型),train是指当前下载的数据集用于模型训练还是模型验证,当train = True时,这代表当前下载的数据集是用于模型的训练的,反之则用于模型的验证。download = True 表示下载当前数据集到root指定的路径。最后,我们用一个变量来指向当前下载好的数据集,方便后续使用数据加载器访问该数据集。至此,我们谈明白了如何使用datasets。
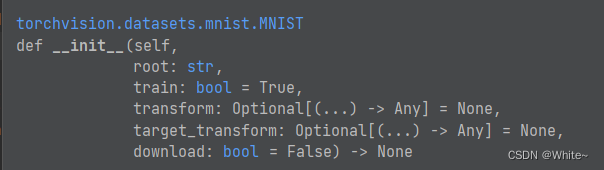
2.1 关于datasets,Dataset和Dataloader
pytorch中提供了一个名字为utils的库,可以使用如下代码来导入数据加载器以及Dataset
from torch.utils.data import DataLoader,Datasetdatasets来源于torchvision,包含了许多内置的数据集,但是Dataset并没有此功能;除此之外,当使用私有数据集进行模型的训练时,就需要自定义Dataset了(关于如何定义,请往下看)
2.2 关于Dataset与DataLoader,我的理解
当模型训练时,我们需要给模型传递数据,我理解的是有两种方法,第一种就是不管数据集有多少张图片,我需要编写大量的程序从数据集文件夹中一个一个取出图片和标签(这就让人很头大)去喂给模型;第二种就是首先将数据集转化成一个可迭代对象,然后再用一个变量指向这个可迭代的对象,之后再使用数据加载器(DataLoader)去按照Batch_size去从这个可迭代对象中取出图片和标签(相当于方法一中的许多工作就省去了),再把数据喂给模型。这就好比你用鱼竿钓鱼,别人用网捕鱼,当然是后者效率更高啦。
Part2.网络模型的搭建:
网络模型的搭建简单来讲分为两个部分,一是实例化模型,二是定义前向传播函数
首先,咱们看一下如何实例化一个模型
前提:pytorch框架指出,当你自定义一个模型的时候,都需要继承nn.module,这个是理解问题的关键。
为了能够更好的说明如何实例化对象(如用什么函数?),我推荐你看这篇博客
本文链接:(声明:我也是看了这篇博客之后收获颇多,Respect!!!)Python中__init__的用法和理解___init__在python中的用法_luzhan66的博客-CSDN博客
现在,你应该明白了该如何使用魔法函数即__init__()初始化函数来实例某一个对象,那么我直接附上我写的有关模型结构的代码:
import torch.nn as nn
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, kernel_size=5, stride=1)
self.pooling2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.pooling4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.linear1 = nn.Linear(in_features=400, out_features=120)
self.linear2 = nn.Linear(in_features=120, out_features=84)
self.linear3 = nn.Linear(in_features=84, out_features=10)
self.softmax = nn.Softmax(dim=1)
self.relu = nn.ReLU()
def forward(self, x):
out = self.conv1(x)
out = self.relu(out)
out = self.pooling2(out)
out = self.conv3(out)
out = self.relu(out)
out = self.pooling4(out)
out = out.view(-1, 400)
out = self.linear1(out)
out = self.linear2(out)
out = self.linear3(out)
out = self.softmax(out)
return out.float()可以看出,我们需要在初始化函数中定义模型的属性,即我们是否需要用到卷积层,池化层,全连接层,激活函数等等,然后实例化这些属性就是通过self来实现的,当我们完成该对象的属性之后,接下来就是该如何使用定义好的属性去实现一些操作,如先卷积再池化,或者先池化后卷积(这些就是在forwad()函数中来实现数据传播的顺序)。我们可以也可以在该类中的其它函数中使用定义好的类的属性。当然,你可能还会对super(LeNet5, self).__init__()有疑问,这个我们也是放到后面或者下一篇博客再去叙述吧!!!
Part3.模型训练结果的可视化
这部分我只关注了两个点,一个是模型训练的准确率,一个是模型的损失函数loss。使用了tqdm库来实现在终端展示模型的训练结果。
需要注意的是,模型输出的张量数据类型,在进行loss计算和准确率计算时,需要将张量数据转换为常量(想不出别的词来形容了)。其它倒没有需要强调的点了。
最后,下面是本文的全部代码。
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as tf
from torchvision import datasets
from model import LeNet5
from tqdm import tqdm #该库能够以终端进度条的可视化方法展示训练过程
# 定义数据集保存路径
data_path = "D:\pycharm-projects\handwriteidentity\minsit"
#使用cuda加速
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#定义数据集预处理方法
transforms = tf.Compose([tf.Resize([32, 32]),
tf.ToTensor()])
#使用torchvision中的dataset加载MNIST数据集,分为训练集和验证集
data_train = datasets.MNIST(data_path, train=True, download=True, transform=transforms)
data_val = datasets.MNIST(data_path, train=False, download=True, transform=transforms)
#使用dataloader数据加载器实现数据的批量化加载
train_data = DataLoader(dataset=data_train, batch_size=50, shuffle=True)
val_data = DataLoader(dataset=data_val, batch_size=50, shuffle=True)
#导入写好的LeNet5模型
model = LeNet5().to(device)
#定义超参数
epoches = 50
lr = 1e-2
#定义损失函数和优化器
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
#可以试着将optimizer改为SGD类型
#定义训练方法
for epoch in range(epoches):
pbar = tqdm(train_data)
# model.train(True)
for img, label in pbar:
img = img.to(device)
label = label.to(device)
optimizer.zero_grad()
model_out = model(img)
loss = loss_fn(model_out, label)
_, pred = torch.max(model_out, dim=1)
train_acc = (pred == label).sum() / label.shape[0]
loss.backward()
optimizer.step()
pbar.set_description("Processing [%d/%d] loss:%.4f, acc:%.4f" % (epoch, epoches, loss.item(), train_acc.item()))
with torch.no_grad():
if epoch % 10 == 0:
torch.save(model.state_dict(), f"model_epoch_{epoch}.pth")
print("model saved success")Tips:
1.在模型训练时,一定要注意optimizer.zero_grad(),loss.backward(),optimizer.step()三者之间的顺序,要保证每经历一次for循环都需要把上次的梯度进行清零。
2.loss.backward()会计算损失函数中权重的梯度,optimizer.step()是按照优化器设定的规则,根据计算好的当前梯度来进行梯度下降,使loss趋向于收敛。
3.其实还想写好多东西,但是由于时间原因(主要是高级的不会呀!!!),暂时写这么多吧。














 2302
2302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









