







目录
集群规划
| 主机名 | IP地址 | 节点分布 |
|---|---|---|
| bigdata112 | 192.168.189.112 | NameNode / SecondaryNameNode / ResourceManager |
| bigdata113 | 192.168.189.113 | DataNode / NodeManager |
| bigdata114 | 192.168.189.114 | DataNode / NodeManager |
bigdata112作为master主节点,bigdata113和bigdata114作为slaves从节点,具体配置参见《Hadoop本地模式、伪分布式和全分布式集群安装与部署》。
集群启动 | 停止
单进程启动 | 停止
集群命令脚本在Hadoop的sbin目录下(例如:hadoop-2.7.3/sbin),如图:

在生产环境中,可以使用如下命令,启动当前节点的某个进程:
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
yarn-daemon.sh start|stop resourcemanager|nodemanager上面命令可以在集群的任何一个节点上运行。
(1)在112节点上执行上面的启动命令,可以在112上正常启动namenode / secondarynamenode / datanode进程,resourcemanager和nodemanager无法启动,会报如下错误:
Error: Could not find or load main class resourcemanager
Error: Could not find or load main class nodemanager
(2)在113或114上执行上面的启动命令,无法启动namenode和resourcemanager,其他可以正常启动,如图:
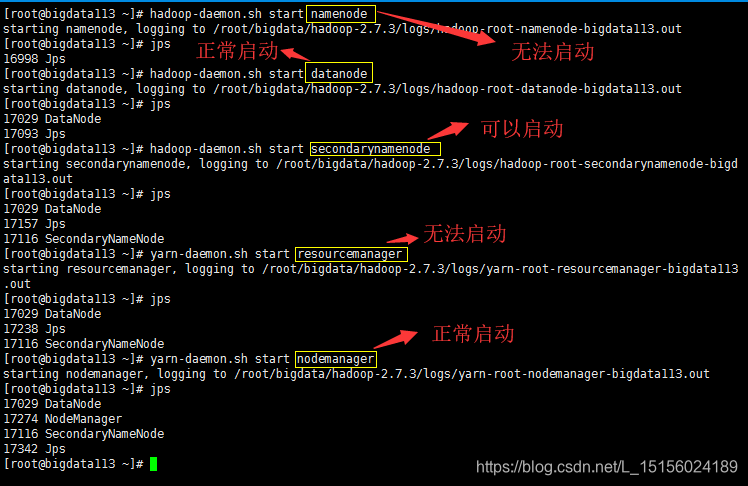
同一类型进程启动 | 停止
命令如下:
hadoop-daemons.sh start|stop namenode|datanode|secondarynamenode
yarn-daemons.sh start|stop resourcemanager|nodemanager请自行测试。
dfs和yarn分开启动 | 停止
启动 | 停止dfs
命令:start-dfs.sh | stop-dfs.sh
(1)无论在哪个节点执行start-dfs.sh,112都正常启动namenode进程,113和114正常启动datanode进程,而secondarynamenode进程会在执行命令的节点启动。
(2)无论在哪个节点执行stop-dfs.sh,112都正常关闭namenode进程,113和114正常关闭datanode进程,而要关闭secondarynamenode进程,必须在该进程所在节点执行stop-dfs.sh命令才可以,否则不能关闭。
启动 | 停止yarn
命令:start-yarn.sh | stop-yarn.sh
(1)如果在112上执行start-yarn.sh命令,112正常启动resourcemanager进程,113和114正常启动nodemanager进程;
(2)如果在113上执行start-yarn.sh命令,113和114正常启动nodemanager进程,resourcemanager无法启动。
(3)无论在哪个节点执行stop-yarn.sh,都能正常关闭nodemanager进程,关闭resourcemanager进程必须在该进程所在节点执行命令。
一起启动 | 停止yarn和dfs
命令:start-all.sh | stop-all.sh
该命令启动或停止整个集群,包括dfs和yarn。执行命令时,会提醒该命令已经过期,推荐使用分开启动 | 停止dfs和dfs。
推荐:
(1)在112上启动 | 停止yarn和dfs,无论是分开还是一起启动都可以。
(2)可以在单个节点执行单进程启动 | 停止命令,但必须是与该节点的进程相关的命令,比如在112上相关的进程应该是namenode、secondarynamenode和resourcemanager,在113或114上相关的进程应该是datanode和nodemanager。
NameNode
NameNode是Hadoop集群的主节点,主要职责:
- 接收客户端、命令行和程序等的请求,例如:创建目录,上传下载数据等。
- 管理和维护HDFS的操作日志edits文件和HDFS元数据镜像文件fsimage。
- 监控DataNode运行状态,发现DataNode死掉,将该DataNode移出集群,并重新备份上面的数据
在未启动集群,NameNode格式化后,各节点的tmp目录如下:
(1)112节点生成了fsimage文件,如图:

(2)113和114节点暂时没有tmp目录。
fsimage,顾名思义,是fs的image,也就是HDFS的快照,记录了HDFS的元数据(metadata),它是一个二进制文件,可以使用Hadoop提供的Image Viewer工具将fsimage转换成xml文件进行查看,转换命令如下:
hdfs oiv -i tmp/dfs/name/current/fsimage_0000000000000000000 -o ~/temp/fs-a.xml -p XMLfs-a.xml内容如下:
<?xml version="1.0"?>
<fsimage>
<NameSection>
<genstampV1>1000</genstampV1>
<genstampV2>1000</genstampV2>
<genstampV1Limit>0</genstampV1Limit>
<lastAllocatedBlockId>1073741824</lastAllocatedBlockId>
<txid>0</txid>
</NameSection>
<INodeSection>
<lastInodeId>16385</lastInodeId>
<inode>
<id>16385</id>
<type>DIRECTORY</type>
<name></name>
<mtime>0</mtime>
<permission>root:supergroup:rwxr-xr-x</permission>
<nsquota>9223372036854775807</nsquota>
<dsquota>-1</dsquota>
</inode>
</INodeSection>
<INodeReferenceSection></INodeReferenceSection>
<SnapshotSection>
<snapshotCounter>0</snapshotCounter>
</SnapshotSection>
<INodeDirectorySection></INodeDirectorySection>
<FileUnderConstructionSection></FileUnderConstructionSection>
<SnapshotDiffSection>
<diff>
<inodeid>16385</inodeid>
</diff>
</SnapshotDiffSection>
<SecretManagerSection>
<currentId>0</currentId>
<tokenSequenceNumber>0</tokenSequenceNumber>
</SecretManagerSection>
<CacheManagerSection>
<nextDirectiveId>1</nextDirectiveId>
</CacheManagerSection>
</fsimage>现在如果在112上执行dfs的启动命令start-dfs.sh,各节点tmp目录更新如下:
(1)112节点:
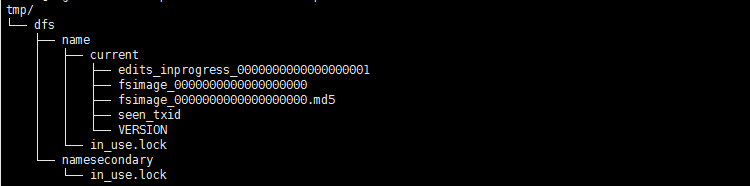
比之前多了一个edits开头的文件,dfs启动命令的日志就记录在该文件中,还多了namesecondary目录。过一段时间tmp变为如下情况:
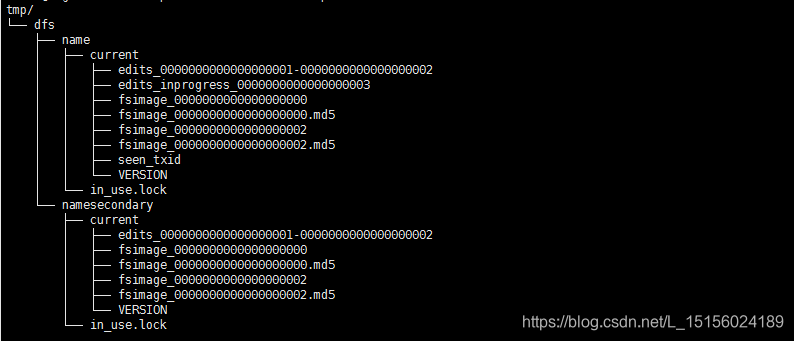
namesecondary目录几乎和name目录几乎相同。这是因为SecondaryNameNode节点从NameNode节点上拷贝了edits和fsimage文件,后面再解释。
(2)113和114节点tmp目录类似,如图:
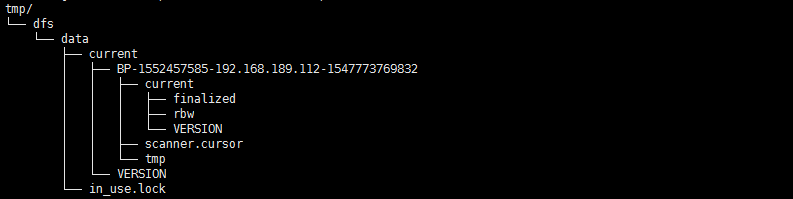
BP开头的字符串是Block Pool ID,下面暂时还没有数据。
以 edits开头的文件就是edits文件,它也是一个二进制文件,集群运行后,对HDFS的所有的操作日志都写进该文件中,使用Hadoop提供的Edits Viewer工具将其转换成xml文件进行查看,转换命令如下:
hdfs oev -i tmp/dfs/name/current/edits_inprogress_0000000000000000001 -o ~/temp/a.xml
a.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>3</TXID>
</DATA>
</RECORD>
</EDITS>下面接着在HDFS中创建一个/input目录,看看edits文件如何变化,创建目录命令如下:
hdfs dfs -mkdir /input创建成功后,如图:
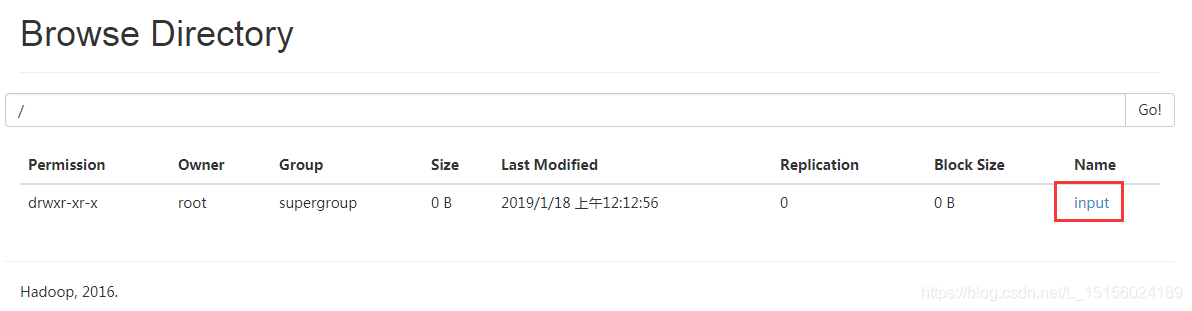
此时edits文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>3</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_MKDIR</OPCODE>
<DATA>
<TXID>4</TXID>
<LENGTH>0</LENGTH>
<INODEID>16386</INODEID>
<PATH>/input</PATH>
<TIMESTAMP>1547741576073</TIMESTAMP>
<PERMISSION_STATUS>
<USERNAME>root</USERNAME>
<GROUPNAME>supergroup</GROUPNAME>
<MODE>493</MODE>
</PERMISSION_STATUS>
</DATA>
</RECORD>
</EDITS>
EDITS标签中多了一个RECORDE标签,这个RECORED标签记录的就是创建目录的日志。上面能看到,edits文件有两个,一个以edits开头,一个以edits_inprogress,其中edits记录的是旧日志,edits_inprogress记录的是最新日志。
DataNode
先上传data.txt文件到HDFS的/input目录,上传命令如下:
hdfs dfs -put ~/input/data.txt /input上传成功如图:
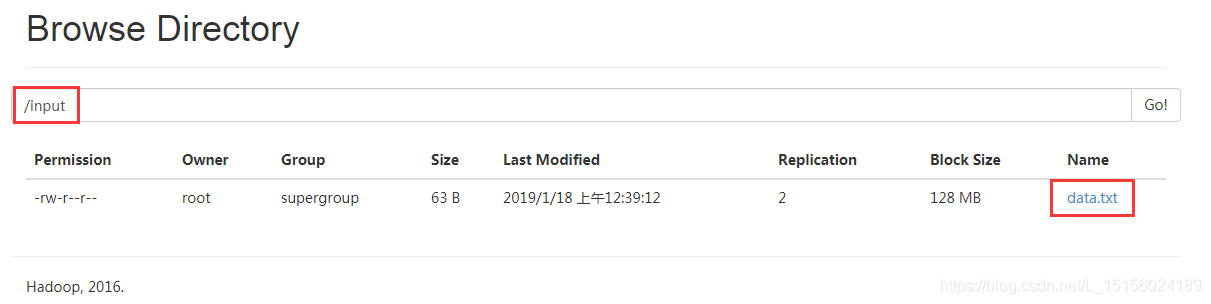
可以看到data.txt的实际大小只有63B,而数据块大小时128M。
113和114节点的tmp目录变化如图:
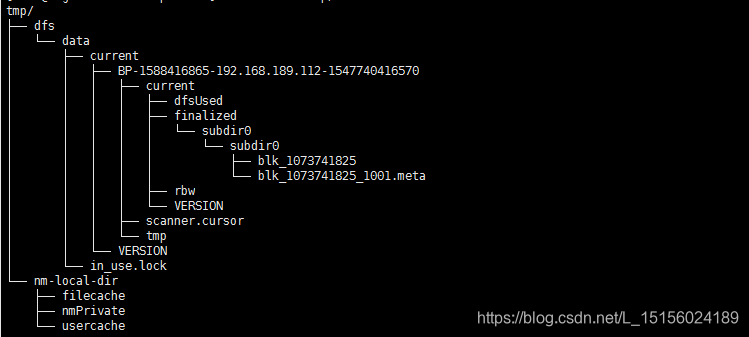
DataNode保存了data.txt的数据块blk_1073741825,在bigdata113和bigdata114上各存一份。
SecondaryNameNode
在集群搭建好,格式化NameNode时,会在控制台打印出格式化日志,如图:
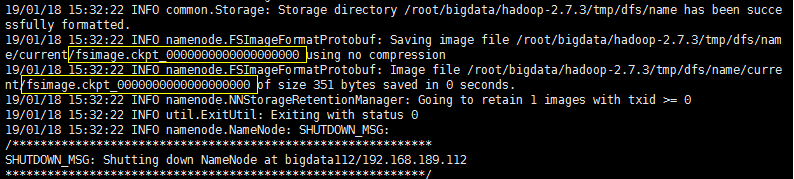
从打印的日志中看到,NameNode节点在tmp的name目录下生成了一个fsimage文件,如图:
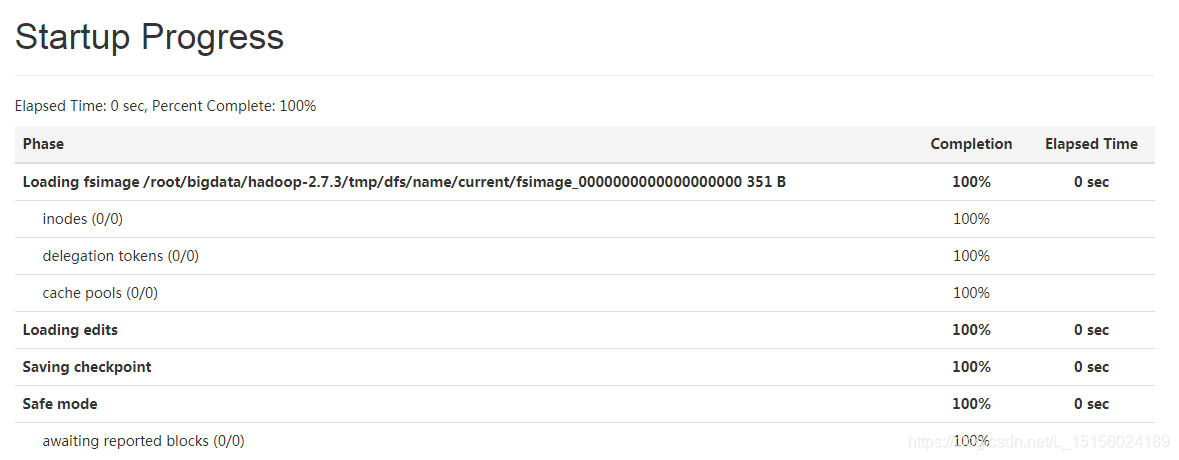
此时fsimage文件保存的还只是HDFS初始状态的元数据信息。接下来,启动dfs,NameNode启动首先将该fsimage文件加载到内存,接着加载edits文件,因为是首次启动,还没有edits文件。详细启动阶段如图:
dfs启动后,在DataNode节点的tmp目录下生成用于保存数据块的data目录,在NameNode的name目录下生成用于保存HDFS操作日志的以eidts_inprogress开头的edits文件,在SecondaryNameNode的tmp目录下生成namesecondary目录(仅有in_use.lock文件)。稍等几秒,NameNode会将edits_progress文件重命名后保存为edits文件,并生成一个新的edits_inprogress文件,此时SecondaryNameNode就发挥功力了,它通过HTTP Get方式从NameNode节点上将edits和fsimage文件下载下来,并加载到内存中(本集群两个节点在同一服务器上,所以目录就是上面这样的情况),然后对它们进行合并,合并后生成fsimage.chpt文件,再以HTTP POST方式上传至NameNode节点上。这是首次合并,只需要几秒。下次合并需要达到配置要求(检查点时间或者文件大小),默认检查点配置在Hadoop安装目录下的share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml中,如图:
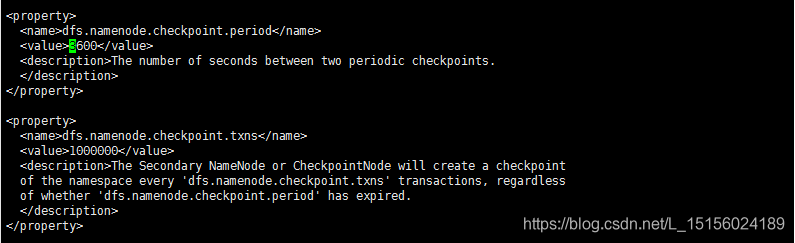
可以在hdfs-site.xml文件中配置,具体如下:
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
</property>
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>60</value>
</property>当关闭dfs时,会将edits_inprocess保存为edits文件,生成新的edits_process文件,这样再次启动dfs时,通过加载最新的fsimage和edits文件就能得到HDF完整的镜像。
总之,SecondaryNameNode主要用于合并edits和fsimage文件,那为什么要这么做呢?我们可以假设下,如果不合并,那么随着对HDFS的操作增多,edits日志不断增大,每次启动dfs,都要加载edits日志,速度会非常之慢。
整个流程可以归纳为:
(1)NameNode将edits_inprogress文件保存为edits文件(保存时机有很多,比如关闭dfs,达到检查点时间,文件大小等),生成新的edits_inprogress文件;
(2)SecondaryNameNode通过HTTP Get方式从NameNode下载edits和fsimage文件;
(3)SecondaryNameNode加载edits和fsimage文件到内存后合并,生成新的fsimage.ckpt文件;
(4)SecondaryNameNode将fsimage.ckpt文件以HTTP Post方式传回NameNode。


















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











