







 本文探讨了编程中的交换操作,深入解析了swap函数中的指针传递原理,强调了类型安全的重要性。同时,文章介绍了泛型编程中的lsearch函数,讨论了函数指针和静态方法的区别,并提供了C语言实现栈的例子,强调了在释放栈资源时正确处理动态内存的重要性。此外,还涉及了CPU内部结构,如ALU和寄存器的工作原理,以及如何将高级语言转换为汇编代码。
本文探讨了编程中的交换操作,深入解析了swap函数中的指针传递原理,强调了类型安全的重要性。同时,文章介绍了泛型编程中的lsearch函数,讨论了函数指针和静态方法的区别,并提供了C语言实现栈的例子,强调了在释放栈资源时正确处理动态内存的重要性。此外,还涉及了CPU内部结构,如ALU和寄存器的工作原理,以及如何将高级语言转换为汇编代码。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
void swap(void *vp1,void *vp2,int size)
{
char *buffer=(char *)malloc(size*sizeof(char));
memcpy(buffer,vp1,size);
memcpy(vp1,vp2,size);
memcpy(vp2,buffer,size);
}
void main()
{
char *h=strdup("William");
char *w=strdup("Lily");
swap(&h,&w,sizeof(char *));
printf("%s\n",h);
}
开始对swap交换里面的&比较奇怪。但后来又想,如果我们交换一个int,那么穿进去的是int的地址,如果我们交换的是char *那么理所当然的传进去的是char* 的地址。
如果这里没有&,它的运行结果将是

很明显只交换了前面四个字符,因为这是对字符串直接进行操作。
当然,也可以这么传。swap(h,&w,sizeof(char *))一个是*一个是**,但是编译器还是不会报错。最可能的情况是将h的前四个字节解释成地址,而在栈中没有这个地址,导致程序崩溃。
int lsearch(int key,int array[],int size) //这是int型的线性搜索
{
for(int i=0;i<size;i++)
{
if(array[i]==key)
return i;
}
return -1;
}
void *lsearch(void *key,void *base,int n,int elemsize)
{
for(int i=0;i<n;i++)
{
void *elemAddr=(char *)base+i*elemsize;
if(memcpy(key,elemAddr,elemsize)==0)
return elemAddr;
}
return NULL;
}需要注意的是
void *elemAddr=(char *)base+i*elemsize;将base强制转换成char*是为了能进行算术运算。
不允许对void*解引用,因为你不知道它在内存中占几个字节
因为base是void*类型的,如果使用base+i的话,编译器不会隐式的将i*sizeof(类型),因为编译器不知道这个类型
而且使用memcpy(key,elemAddr,elemsize)==0为判定条件也是不好的,因为需要考虑函数指针(这里也不知道说的是什么意思)
实际上的函数原型是这样的
viod *lsearch(viod *key,void *base,int n,int elemSize,int (*cmpfn)(void*,void*))
int array[]={4,2,3,7,11,6};
int size=6;
int number=7;
int *fund=(int *)lsearch(&number,array,size,sizeof(int),intCmp);key指向number的首地址
base指向数组的首地址
它们都不知道所指向的地址会被解释成什么
n是数组长度
elemsize是显示传进去的数据类型长度,也因为它的存在使函数具备了泛型的基本功能
cmpfn是个函数指针,指向的是能比较两个地址表现的函数。
这里使用
int intCmp(void *elem1,void *elem2)
{
int *vp1=(int *)elem1;
int *vp2=(int *)elem2;
return *vp1-*vp2;
}作为比较函数原型
当是下面这个例子的时候,比较原型又会有很大的不同
char *notes[]={"Ab","F#","B","Gb","D"};
char *favouriteNote="Eb";
char **fund=lsearch(&favouriteNote,notes,5,sizeof(char*),StrCmp);int StrCmp(void *vp1,void *vp2)
{
char *s1=*(char **)vp1;
char *s2=*(char **)vp2;
return strcmp(s1,s2);
}因为notes是char**的形式,为了使比较双方等同,故传进去的是&favouriteNote,当然也可以不这么传,但是相应的下面就得做出一些修改
讲void *形式的&favouriteNote和notes强制转换成char**的形式再解引用就相当于指向字符串数组的指针
这时候在调用strcmp函数进行比较就很顺理成章了。
函数和方法的不同之处在于,它们看起来很相似,只是方法实际上将其相关对象的地址作为一个隐含参数,这个隐含参数叫做(this)指针
lsearch的第五个参数传入的要么是一个普通的非面向对象的函数,要么就是静态方法,因为静态方法没有this指针
stack的pure c实现
only for int
typedef struct {
int *elems;
int logicalLen;
int alloclength;
}Stack;
void StackNew(Stack *s);
void StackDispose(Stack *s);
void StackPush(Stack *s,int value);
int StackPop(Stack *s);
void StackNew(Stack *s)
{
s->logicalLen=0;
s->alloclength=4;
s->elems=malloc(4*sizeof(int));
assert(s->elems!=NULL); //这一句很重要,严谨性的体现
}
void StackDispose(Stack *s)
{
free(s->elems);
}
void StackPush(Stack *s,int value)
{
if(s->logicalLen==s->alloclength)
{
s->alloclength*=2;
s->elems=realloc(s->elems,s->alloclength*sizeof(int));
assert(s->elems!=NULL);
}
s->elems[s->logicalLen]=value;
s->logicalLen++;
}
int StackPop(Stack *s)
{
assert(s->logicalLen>0);
s->logicalLen--;
return s->elems[s->logicalLen];
}对于泛型
typedef struct{
void *elems;
int elemSize;
int loglength;
int alloclength;
;
}Stack;
void StackNew(Stack *s,int elemSize);
void StackDispose(Stack *s);
void StackPush(Stack *s,void *elemAddr);
void StackPop(Stack*s,void *elemAddr);
void StackNew(Stack *s,int elemSize)
{
s->elemSize=elemSize;
s->loglength=0;
s->alloclength=4;
s->elems=malloc(4*elemSize);
assert(s->elems!=NULL);
}
void StackDispose(Stack *s)
{
free(s->elems);
}
static void StackGrow(Stack *s)
{
s->alloclength*=2;
s->elems=realloc(s->elems,s->alloclength*s->elemSize);
}
void StackPush(Stack *s,void *elemAddr)
{
if(s->loglength==s->alloclength)
StackGrow(s);
void *target=(char *)s->elems+s->loglength*s->elemSize;
memcpy(target,elemAddr,s->elemSize);
s->loglength++;
}
void StackPop(Stack *s,void *elemAddr)
{
void *sourse=(char *)s->elems+(s->loglength-1)*s->elemSize;
memcpy(elemAddr,sourse,s->elemSize);
s->loglength--;
}用这个泛型实现对字符串进行操作
void main()
{
const char* friends[]={"AI","Bob","Carl"};
Stack stringStack;
StackNew(&stringStack,sizeof(char *));
for(int i=0;i<3;i++)
{
char *copy=strdup(friends[i]);
StackPush(&stringStack,©);
}
char *name;
for(int i=0;i<3;i++)
{
StackPop(&stringStack,&name);
printf("%s\n",name);
free(name);
}
StackDispose(&stringStack);
}
但是现在问题来了
for(int i=0;i<3;i++)
{
StackPop(&stringStack,&name);
printf("%s\n",name);
free(name);
}栈不应该强制的设为空,或者说用户并需要弹出所有元素才能释放栈空间
为了方便用户我们应该在释放栈空间之前将堆的内容释放掉,并将它们归还给堆空间,很多情况下我们没必要这么做,当存储的是内置类型的时候没必要手动清零,不过需要注意归还各类动态申请的资源,或者一些打开文件资源等
现在的stackDispose函数并不知道栈里的那些元素是指针,最多只知道他们占四个字节。那么怎么让free释放掉所有的资源呢
我们需要重写栈的定义,重写StackNew,重写StackDispose,写一个释放内存的函数freefn
void StackNew(Stack *s,int elemSize,void (*freefn)(void *))void StackDispose(Stack *s)
{
if(s->freefn!=NULL)
for(int i=0;i<s->loglength;i++)
{
s->freefn((char *)s->elems+i*s->elemSize);
}
free(s->elems);
}void stringFree(void *elem)
{
free(*(char **)elem);
}
内存分配的空间实际上比你需要的空间要大一些,因为前面的4个或8个字节需要记录分配空间的大小
当你得到返回的头指针时,实际上得到的不是整块内存的头指针,而是头指针之后4个或8个字节之后的指针
每一个寄存器在理论上都可以从RAM读取信息或将信息写入RAM中
ALU算数逻辑单元,它很容易在4个字节上进行加法减法移位等操作
ALU与寄存器堆相连
上述结构要求所有有意义的数学运算都需要通过寄存器来完成
另一种方式是让ALU与整个RAM相连,这样的话就会特别昂贵
大多数的运算都是将数据读入寄存器中,然后将计算结果读入另一个寄存器,最后再写入到属于它的内存中
LOAD STORE STRUCTURE
--------------------------------------------------------------------------------------------------------------------------------------------
发现整个文章的结构都很混乱,等全部弄完了再整理吧。CLASS 9 主要讲的是怎么将C C++的语句转换为汇编语句
int i;
int j;
i=10;
j=i+7;
j++;
/*----------------------------------------------*/
M[R1+4]=10; //大写的M代表整个RAM store operation
R2=M[R1+4]; //load operation
R3=R2+7; //ALU operation
M[R1]=R3; //store operation
/*----------------------------------------------*/
R2=M[R1];
R2=R2+1;
M[R1]=R2;
//ALU默认对四个字节进行处理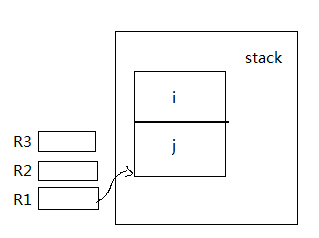
int i;
short s1;
short s2;
i=200; => M[R1+4]=200;
s1=i; => R2=M[R1+4]; M[R1+2]=.2 R2;
s2=s1+1;=> R2=.2M[R1+2]; R3=R2+1; M[R1]=.2 R3;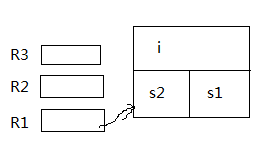
.2表示低位的两个字节
int array[4];
int i;
for(i=0;i<4;i++)
array[i]=0;
i--;
/*---------------------------------------------*/
M[R1]=0; //i=0
R2=M[R1];
BGE R2,4,PC+40
R3=M[R1];
R4=R3*4; //基地址
R5=R1+4; //偏移量
R6=R4+R5;
M[R6]=0;
R2=M[R2];
R2=R2+1;
M[R1]=R2;
JMP PC-40;
//所有的汇编指令都是四个字节宽
//汇编中共有59条指令
//所以前面的六位用来表示指令类型,然后再决定怎么解释后面的26位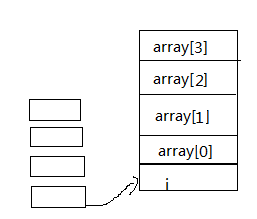
BGE B表示分支 GE表示大于或等于 PC+40表示下跳到10条指令之后
CLASS 10
void foo(int bar,int *baz)
{
char snack[4];
short *why;
}每次调用这个函数都会在栈中产生下面的结构
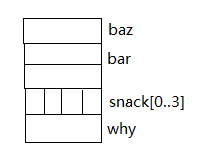
中间的结构保存function called 信息
void foo(int bar,int *baz)
{
char snack[4];
short *why;
why=(short *)(snack +2);
*why=50;
}
int main(int argc,char **argv)
{
int i=4;
foo(i,&i);
return 0;
}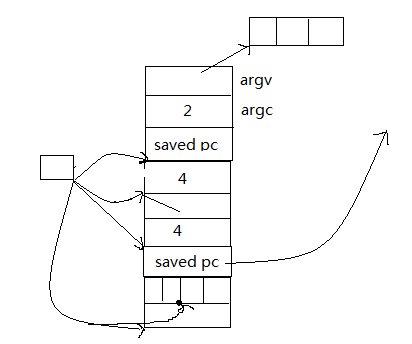
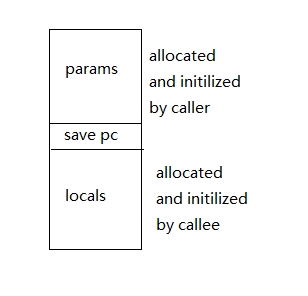
活动记录的上部分是由调用者设置的
对于下面的一半,调用者并不知道函数中到底有多少局部变量
/*----
SP=SP-4;
M[SP]=4;
SP=SP-8;
R1=M[MP+8];
R2=MP+8;
M[SP]=R1;
M[SP+4]=R2;
CALL <foo>
SP=SP+8;
FOO:
SP=SP-8;
R1=SP+6;
M[SP]=R1;
R1=M[SP];
M[R1]=.2 50;
SP=SP+8;
RET;
MAIN:
RV=0; //rv专门在调用和被调用函数间返回返回值















 2792
2792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









