






编译原理-中科大(华保健)
词法分析:
词法分析的功能和主要接口是什么—》涉及的数据结构和算法。
1.词法分析的主要作用:字符流到记号流的转换
字符流:和被编译的语言密切相关(ASCII【c】,Unicode【java】,or…)
记号流:编译器内部定义的数据结构token,编码所识别出的词法单元
2.词法分析实现方式:手工,自动生成器
编译器的结构图/阶段划分:
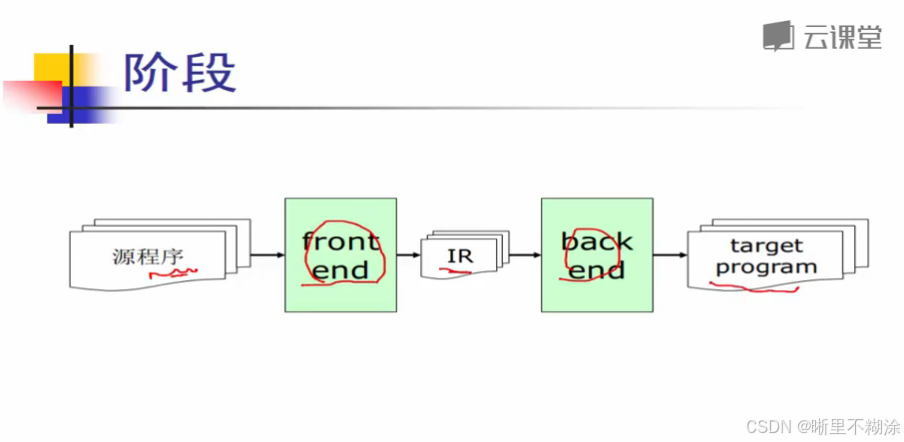
解释:
前端:接受源程序产生中间表示。处理源与源程序相关的属性。
后端:接受中间表示生成目标程序。处理具体的体系结构和目标基相关的属性。
前端的阶段划分:
词法分析器分析一个字符流,对字符流切分得到记号流。记号流进一步做传递输入给语法分析器。语法分析器读入记号流产生抽象语法树。抽象语法树作为一个数据结构进一步传递给语义分析器/类型检查器,检查语法树的正确性,进一步输出中间表示/中间代码。
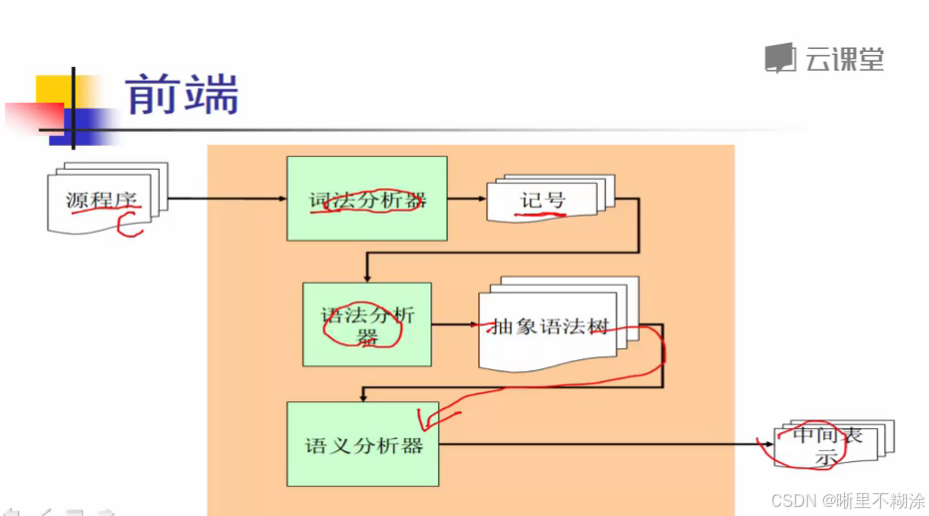
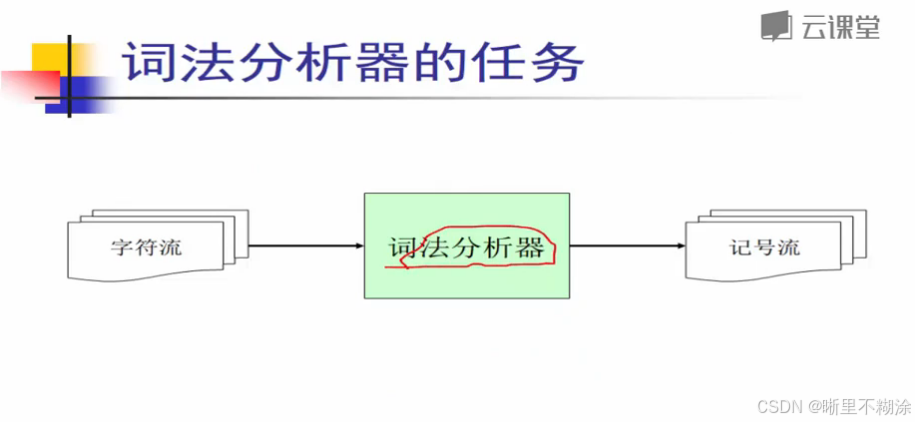
词法分析器的任务:
描述任何一个软件系统,首先最重要的可能都是要看清楚他的I/O接口。
输入字符流,词法分析器进行切分,输出记号流。
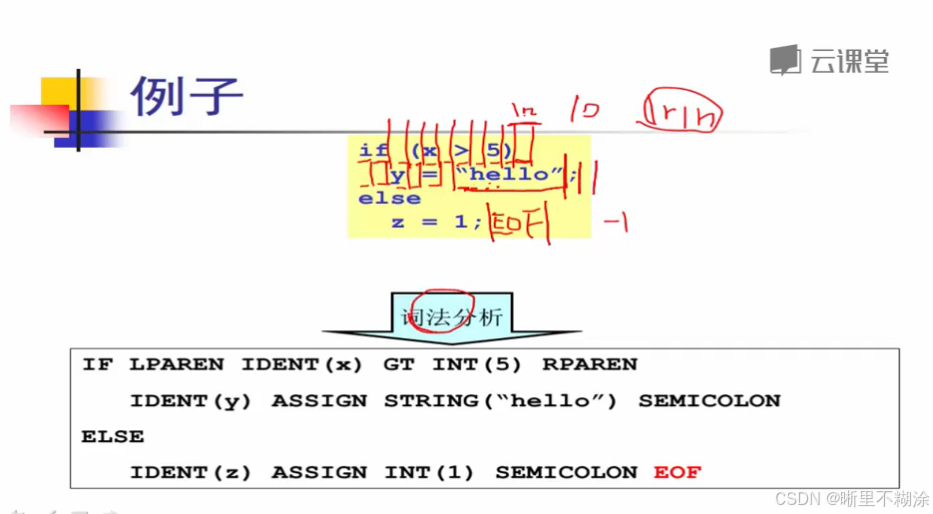
字符流是什么?记号流是什么?
字符流:源程序
单词流/记号流:是一个数据结构,用来记录词法单元。token<类型,值>
IF(关键字) IDENT(x)(标识符+具体的元素是什么) EOF(文件描述符)…
实现流程:数据结构的定义+算法的实现
(记号的数据结构—》字符流到记号流的算法)
记号的数据结构定义:
枚举类型 { 词法分析器所能识别的所有的记号的分类 }
结构体定义{ 枚举类型; 具体的单词的值;}
具体的单词值为0,表示实际上没有赋任何的值

词法分析器的实现的两个方法
- 手工编码实现法:纯手工编写程序代码实现词法分析的I/O接口功能
- 相对复杂,容易出错,但很主流
- eg.GCC,LLVM …
- 词法分析器的生成器:仅需要词法分析的声明
- 可快速原型,代码量少,较难控制细节
转移图:
用来记录词法分析的过程。
双圆圈:接受/识别状态—》一个单词的识别已经结束了—》返回所识别出来的token数据结构。
星号other的情况:多读的字符 新回滚被分析的程序/缓存中去,返回单独的一个<。
<> 是 !=
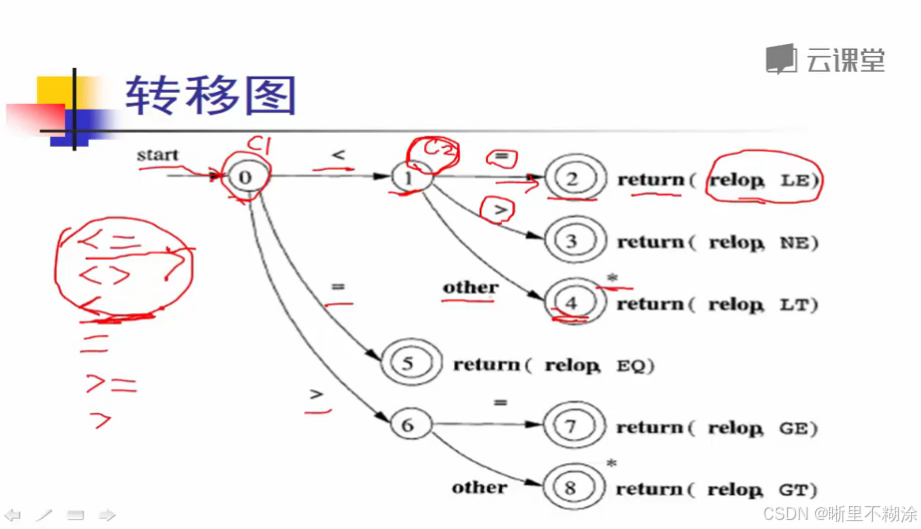
转移图算法:
返回token数据结构 命名nextToken()

标识符的转移图:
标识符以小或大写字母/下划线开头,中间循环读取字母下划线和数字,当读到其他的就表示结束了,*星号回滚最后一个读入的字符C,双圈返回所识别的ID。
是一个不断递归识别的过程。

标识符和关键字
关键字是标识符的一部分。eg.关键字:if,while,else…;标识符:字符串。

如何识别关键字呢?
- 在原来节点上扩展新的节点和边
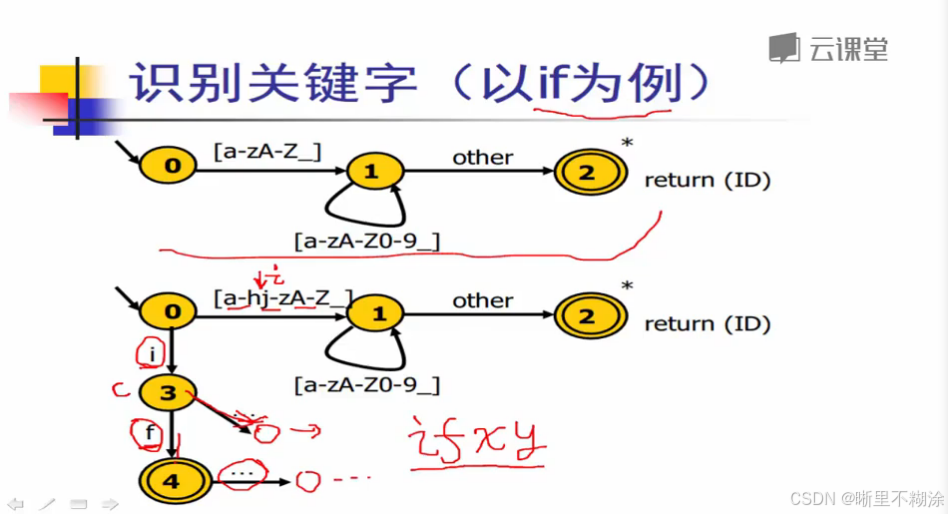
- 关键字表
- 构建关键字哈希表H【对任何语言,关键字都是确定的有限集合】
- 不在状态图上区分标识符和关键字,统一按标识符的转移图识别
- 查看H表查看是否是关键字
- 合理的构造哈希表H(完美哈希),可以在O(1)时间内完成。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









