







前言
本文主在总结计算机网络中HTTP协议的发展史, 用于供大伙参考学习
本文会从HTTP1.0开始, 逐步介绍HTTP各个版本的功能特性, 优缺点等, 并引入下个版本来方便大家理解
HTTP1.0
最基本的HTTP协议, 协议整体使用请求头 + 请求体的形式来作为报文的边界用于解析读取, 这里介绍要花费太多的篇幅, 就不过多介绍, 这里就重点讲讲HTTP1.0的优缺点
优点
- 简单 : 只有头部和身体的组成, 并且头部信息是以key-value保存的, 易理解
- 灵活易扩展 : 各种请求和响应都可以随意扩展, 并且因为是工作在应用层, 可以随意更新下层协议
- 应用广
缺点
- 无状态传输, 在减轻服务器的负担的同时对于带身份的请求处理会麻烦很多
比如为了标识用户身份就使用了用户和服务器的交互 : cookie - 明文传输 : 所有信息明文发送没有加密, 很容易被窃取
- 不安全 : 上面两个特点带来的就是不安全, 在明文的完整性和身份验证上麻烦, 所以引入了HTTPS来保证安全
- 链接资源消耗大, 默认使用短链接的方式来进行请求响应, 需要耗费大量的资源用于建立链接
HTTP1.1
HTTP1.1的改进
- 使用长连接的方式改善了HTTP1.0短连接造成的性能开销
- 支持管道网络传输, 可以连续发送请求而不必等待请求响应后再发送请求
- 增加了更多的协议头, 让协议支持更多的协商内容, 比如浏览器和服务器沟通资源缓存相关的操作
HTTP1.1的性能瓶颈
- 请求 / 响应头没有压缩就发送, 首部信息越多延迟越大, 只能压缩body部分
- 发送的消息带有冗长的首部, 每次发送相同的首部浪费资源
- 服务器是按照请求的顺序响应的, 如果服务器第一个响应处理时间长, 会造成响应队头阻塞
- 没有请求优先级 ( 类似上面的问题 )
- 请求只能从客户端开始, 服务器只能被动响应
HTTP2.0
为了解决HTTP1.1依旧存在的问题, HTTP2.0横空出世
来看看HTTP2.0作出的优化
优化
- 头部压缩
- 采用二进制格式传输
- 数据流传输
- 使用了多路复用的方式支持并发传输
- 支持服务器主动推送
这里一个个解析给大家看看
HTTP2.0的改进
头部压缩
在HTTP1.1中, 报文存在的问题就是头部存在大量固定字段, 这些固定字段每次传输都要占用一定的网络资源, 并且这些字段使用ASCII编码, 字段的解析消息低
在HTTP2.0中, 使用了HPACK算法, 在服务器和客户端中同时维护了一张头部信息表, 所有的头部字段都在这个信息表中, 对于相同的字段就只发送索引号来提升传输的速度
HPACK算法
HPACK算法包含静态字典, 动态字典和Huffman编码, 支持动态维护新的头部字段, 并且头部字段都会经过Huffman编码压缩后发送, 提高了信息传输的效率
二进制格式传输
HTTP2.0统一采用二进制来传输数据, 这样在数据传输的时候无需再转化为二进制交给网络协议栈去解析, 增加了传输的效率
报文整体通过规定对应bit存储的数据来进行报文的解析

数据流传输
HTTP2.0将 单个请求响应称为一个数据流, 每个数据流都会有对应独一无二的编号, 不同数据流的帧是可以乱序发送的
- 这里将每个数据流响应数据称为帧
可以在一个返回的报文中发送多个请求的响应帧, 达到同时响应多个请求的效果, 接收端会通过对应数据流的编号将对应的响应报文拼接起来, 客户端还可以指定某个数据流的优先级, 让服务器优先响应高优先级的请求
使用了多路复用的方式支持并发传输
因为使用流式传输的方式, HTTP2.0可以同时响应多个报文, 所以是无需按客户端请求的顺序去响应请求
同时响应多个报文也提升了并发处理的请求数, 解决了HTTP1.1协议存在的队头阻塞问题
- 不过这里依旧存在一个队头阻塞问题, 后面讲HTTP3.0的时候再说
服务器主动推送
HTTP1.1比较笨拙, 服务器只能听从客户端的, 客户端想要什么就给什么, 而HTTP2.0长大了, 服务器会先想好客户端想要什么, 主动向客户端推送数据
- 比如要渲染一个页面需要HTML, CSS, JS等文件, 浏览器可能只是请求了个HTML文件, 服务器就将HTML, CSS, JS等文件都推送给浏览器, 减少了浏览器发送的请求数, 减少了消息来回提高了效率
- 之前HTTP1.1要做到这个要通过更换WebSocket协议来实现
HTTP2.0存在的问题
虽然使用流的方式提升了并发能力, 解决了应用层层面的队头阻塞问题, 但是在TCP层面依旧存在队头阻塞问题
TCP队头阻塞存在的问题就是TCP的可靠数据传输会等待整个数据都到达后才会传递给应用层, 如果请求的某个部分因为网络延迟没有到达, 那么后续的数据只能存放在内核缓冲区中等待前面报文到达才能提交给应用层
极端点出现丢包的情况的话, 还可能造成TCP重传, 一整个TCP链接中的所有HTTP请求都要等待这个丢失的包被重穿回来才能被应用层看到解析
HTTP3.0
为了解决现有的HTTP协议存在的问题, HTTP3.0进行了大刀阔斧的改造, 既然改变HTTP协议改变不了TCP队头阻塞的问题, 那就不用TCP来传输了, 使用UDP来传输HTTP3.0的报文, 整个HTTP3.0作出了以下的改变
- 运输层使用UDP传输
- 简化帧结构
- 升级新的压缩算法
下面一个个解析给大伙看看
HTTP3.0作出的改进
运输层使用UDP传输
HTTP3.0是使用UDP来进行数据传输, 防止因为复用一个TCP连接时出现丢包导致所有HTTP请求都阻塞
但是UDP是不可靠的数据传输, 为了保证可靠数据传输, HTTP3.0集成了QUIC协议, 在应用层协议方面实现了可靠数据传输
QUIC协议有下面的优点
- 无队头阻塞
- 更快的连接建立
- 连接迁移
后面再出个文章详细告诉大家QUIC协议, 这里大伙知道QUIC协议可以在保证数据可靠传输的基础上解决了TCP协议存在的问题即可
至于为什么不修改TCP协议, 而是引入QUIC协议配合UDP协议呢?
因为TCP协议是在操作系统内核层面组织的, 要更新TCP协议需要操作系统内核层面的代码改动, 成本太大很难普及, 所以选择改动相对较简单的应用层协议
帧结构简单
QUIC协议是包括了流操作的, 所以无需再在HTTP3.0的报文中包含对应的流协议定义, 所以帧结构也变得简单了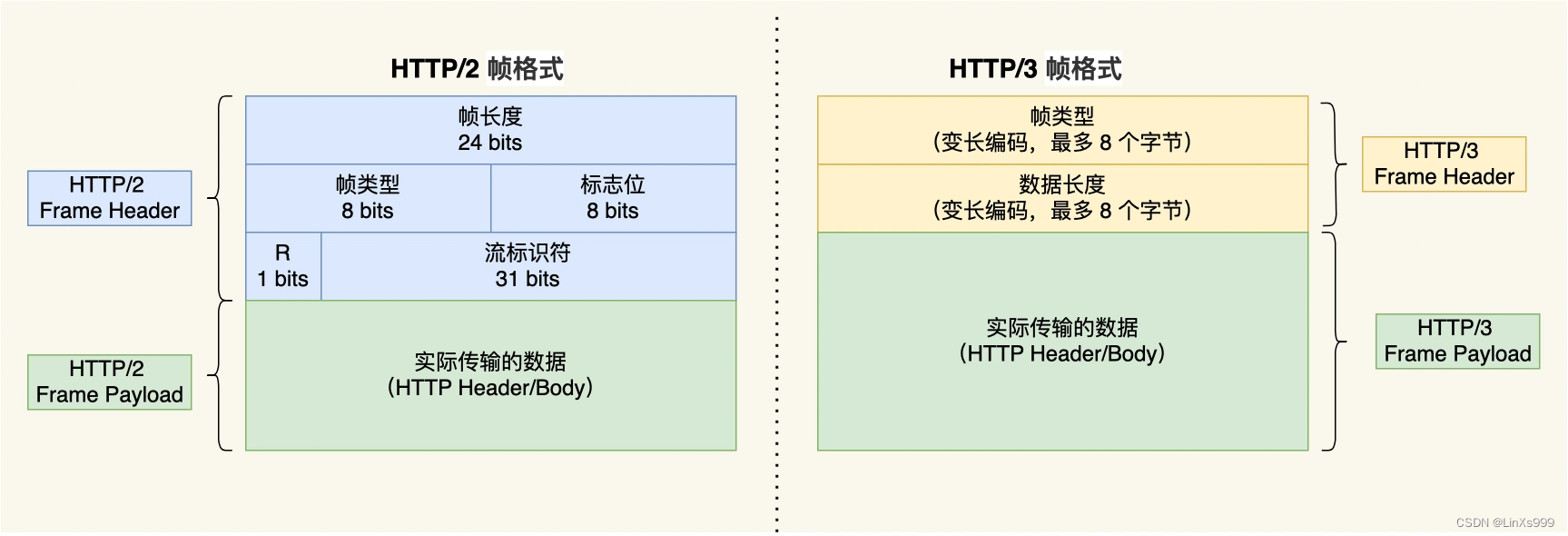
可以看到HTTP3.0无需再去定义额外的流标识符和对应的标志位, 整个帧结构简单不少
压缩算法采用QPACK
HTTP3.0的QPACK类似, 主要区别在于
- 对静态表进行了扩大, 增加了静态表项数
- 动态表编码更改
因为动态表具有时序性, 如果首次请求出现了丢包的话, 在后续的请求就无法正确解析出HPACK头部, 会导致后续的解码出现阻塞
而QPACK是增加了两个单向流, 每个节点都各自维护两个流, 一个用于传递动态字典, 一个用于确认字典
当有新的头部出现的时候, 服务器端通过一个流发送新头部给浏览器, 而浏览器就通过另一个流去告知服务器这个字典已经同步到了自己的本地动态表表中
总结几句
以上便是HTTP协议的一个发展变化史了, 整体来说HTTP协议就是一个不断修补改进的发展过程
从HTTP1.1开始, HTTP1.1存在头部冗余, 队头阻塞问题, HTTP2.0改用流的方式传输, 并且使用头部压缩和维护头部字典的方式改进了HTTP1.1协议存在的问题
而剩下的TCP协议存在的队头阻塞问题被HTTP3.0通过更换传输层协议为UDP并使用QUIC协议来实现可靠数据传输和数据流传输, 在解决了TCP的队头阻塞问题的基础上还保证了数据的可靠传输, 同时还在HTTP2.0头部压缩的基础上进一步升级优化, 更加提高了HTTP协议传输的效率
这篇文章是晚上无事总结的, 历时4天, 可能存在一些纰漏或是描述不对的, 希望大佬们看到可以指正















 1449
1449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









