






filebeat是一款轻量级的日志收集工具,可以在非JAVA环境下运行。
因此,filebeat常被用在非JAVAf的服务器上用于替代Logstash,收集日志信息。
实际上,Filebeat几乎可以起到与Logstash相同的作用,
可以将数据转发到Logstash、Redis或者是Elasticsearch中进行直接处理。
为什么要用filebeat来收集日志?为什么不直接使用lohstash收集日志?
因为logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存
(这就是为什么logstash启动特别慢的原因)。
而filebeat只需要10M左右的内存资源。
常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat发送到logstash,
lostash根据配置文件进行过滤,然后将过滤之后的文件传输到elasticsearch中,最后通过kibana展示。
filebeat结合logstash带来的好处?
1、通过logstash,具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,
从而减轻Elasticsearch持续写入数据的压力。
2、从其它数据源(例如数据库,s3对象存储或消息传递队列)中提取
3、将数据发送到多个目的地,例如S3,HDFS(hadoop分部署文件系统)或写入文件
4、使用数据流逻辑组成更复杂的处理管道。
---------------------- Filebeat+ELK 部署 ----------------------
filebeat是一款轻量级的日志收集工具,可以在非JAVA环境下运行。
因此,filebeat常被用在非JAVAf的服务器上用于替代Logstash,收集日志信息。
实际上,Filebeat几乎可以起到与Logstash相同的作用,
可以将数据转发到Logstash、Redis或者是Elasticsearch中进行直接处理。
为什么要用filebeat来收集日志?为什么不直接使用lohstash收集日志?
因为logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存
(这就是为什么logstash启动特别慢的原因)。
而filebeat只需要10M左右的内存资源。
常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat发送到logstash,
lostash根据配置文件进行过滤,然后将过滤之后的文件传输到elasticsearch中,最后通过kibana展示。
filebeat结合logstash带来的好处?
1、通过logstash,具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,
从而减轻Elasticsearch持续写入数据的压力。
2、从其它数据源(例如数据库,s3对象存储或消息传递队列)中提取
3、将数据发送到多个目的地,例如S3,HDFS(hadoop分部署文件系统)或写入文件
4、使用数据流逻辑组成更复杂的处理管道。
Node1节点(2C/4G):node1/192.168.233.12 Elasticsearch
Node2节点(2C/4G):node2/192.168.233.13 Elasticsearch
Apache节点:apache/192.168.233.11 Logstash Kibana Apache
Filebeat节点:filebeat/192.168.233.12 Filebeat
//在 Node1 节点上操作
1.安装 Filebeat
#上传软件包 filebeat-6.7.2-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.7.2-linux-x86_64.tar.gz
mv filebeat-6.7.2-linux-x86_64/ /usr/local/filebeat
#时间同步
yum install ntpdate -y
ntpdate ntp.aliyun.com
2.设置 filebeat 的主配置文件
cd /usr/local/filebeat
vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
tags: ["nginx"]
fields:
service_name: 192.168.233.21_nginx
log_type: nginx
from: 192.168.233.21
- type: log
enabled: true
paths:
- /etc/httpd/logs/access_log
- /etc/httpd/logs/error_log
tags: ["httpd"]
fields:
service_name: 192.168.233.21_httpd
log_type: httpd
from: 192.168.233.21
- type: log
enabled: true
paths:
- /usr/local/mysql/data/mysql_general.log
tags: ["mysql"]
fields:
service_name: 192.168.233.21_mysqld
log_type: mysql
from: 192.168.233.21
--------------Elasticsearch output-------------------
(全部注释掉)
----------------Logstash output---------------------
output.logstash:
hosts: ["192.168.233.11:5044"] #指定 logstash 的 IP 和端口
#配置logsatsh
input {
beats { port => "5045" }
}
output {
if "nginx" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
if "httpd" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
if "mysql" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
stdout {
codec => rubydebug
}
}
#启动 filebeat
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
#-e:输出到标准输出,禁用syslog/文件输出
#-c:指定配置文件
#nohup:在系统后台不挂断地运行命令,退出终端不会影响程序的运行
logstash -f nginx1.conf --path.data /opt/test6 &
#多个实例同时收集:
[root@elk1 log]# vim nginx1.conf
input {
beats { port => "5045" }
}
output {
if "nginx" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
if "httpd" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index =>"%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
stdout {
codec => rubydebug
}
}
logstash -f nginx1.conf --path.data /opt/test6 &
在示例中我使用的 5045 只是一个示意的端口号,实际上你可以选择任何你系统中未被占用的端口号。
通常,使用大于 1024 且未被其他服务占用的端口是一个良好的选择。
Beats 输入插件默认使用的是 5044 端口,但你可以根据你的需求选择一个不同的端口号。
确保所选择的端口号不会与其他正在运行的服务或进程冲突,并且能够通过防火墙等机制访问。
简而言之,你可以自定义端口号,只要确保它是一个有效的、未被占用的端口号,
并且在 Logstash 配置文件和相应的 Filebeat 配置文件中正确匹配。
优化性能:
pipeline.workers 2
该参数用于设置 Logstash 处理事件的工作线程数量。默认值是核心数。
在一个拥有两个核心的系统上,可以设置为 2,以充分利用系统资源。
pipeline.batch.size 125
该参数定义了从输入中检索事件的批量大小,然后将这批事件发送到过滤器和工作线程。
默认值是 125。你可以根据你的需求和系统性能进行调整。
pipeline.batch.delay 50
该参数定义了在轮询下一个事件之前等待的时间,以确保形成一个适当大小的事件批量。
默认值是 50 毫秒。你可以根据实际情况进行调整。
先部署ELK集群
4台机器

####ELK1##
防火墙
改名

 更改工作目录
更改工作目录

#######同步操作:
安装时间工具
yum install ntpdate -y
ntpdate ntp.aliyun.com
任意一台机器输入data 查看时间是否有一致

####ELK1##################

![]()
![]()

为了方便识别 修改httpd 和NGINX的工作目录
这个NGINX是yum安装的 工作目录如下
编译安装是 /usr/local/nginx/



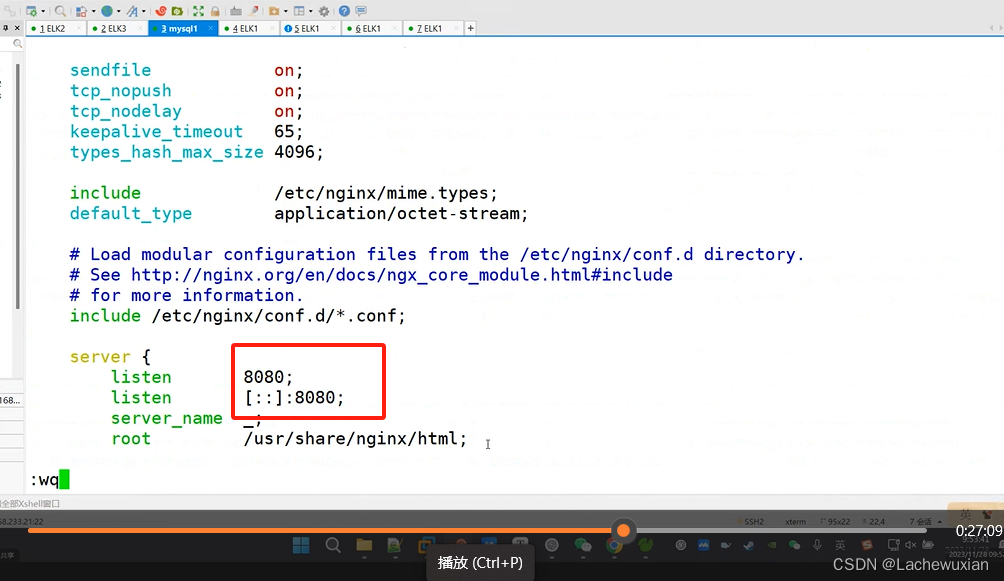
页面测试一下端口老师上课改过 nginx是8080(没记录改的过程)
本来nginx的默认端口是80
不输入端口默认是80


######如何来本地收集niginx的日志
设置 filebeat 的主配置文件
给nginx的日志赋权权限 能够读取日志内容

改配置之前 先备份filebeat的配置文件,防止失误


配置输出流
5044是filebeat的默认端口
把outputs的下面elastisearch全部注释掉 因为日志只能发送给一个 这里发送给logstash
打开logstash的注释 修改ip地址
eastiscearch注释掉

修改为
删除下面

查看nginx的日志格式

注意空格 和- 输入下面

注意格式对齐
标识为nginx
索引名字为 192168.233.11_nginx
l类型为nginx
日志来源192.168.233.11

####配置logsatsh

5044是filebeat的默认端口
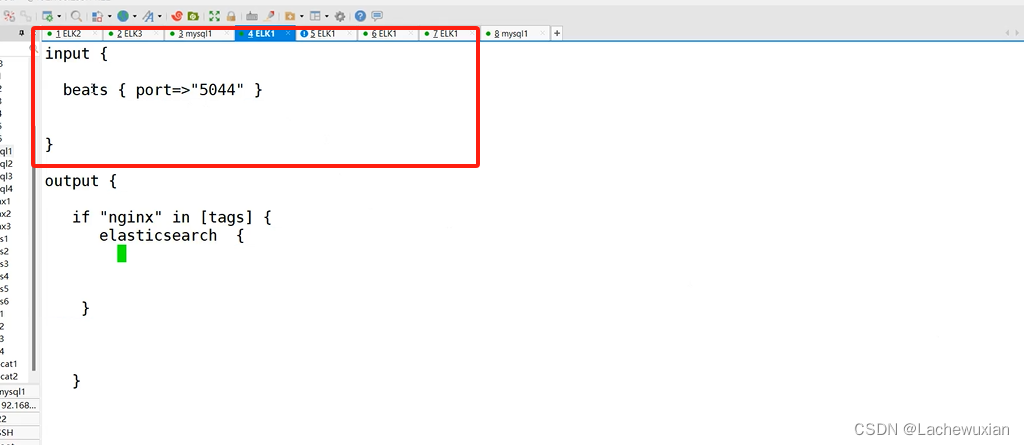
少了input 在后面截图
input {
beats { port => "5044" }
}
output {
if "nginx" in [tags] {
elasticsearch {
hosts => ["192.168.233.12:9200","192.168.233.13:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
}
stdout {
codec => rubydebug
}
}


#启动 filebeat
开启收集日志
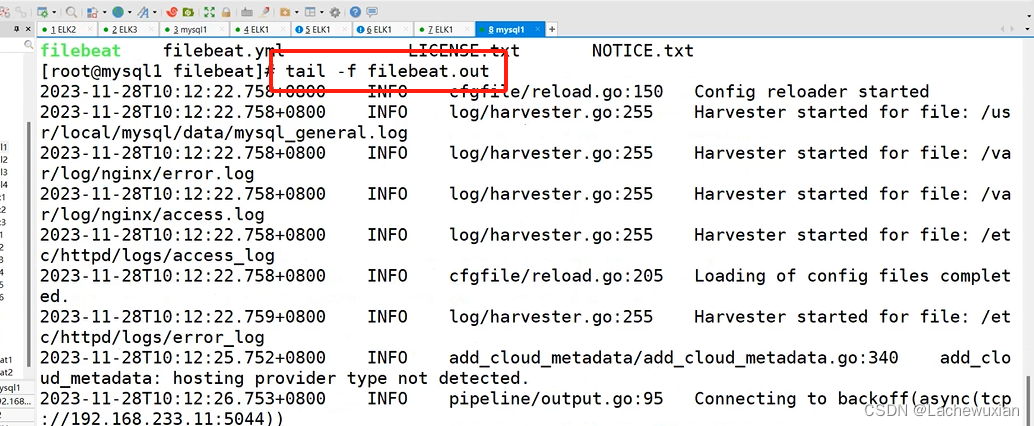
nohup ./filebeat -e -c filebeat.yml > filebeat.out &
nohup 表示在后台记录执行命令的过程
./filebeat 运行文件
-e 使用标准输出的同时进行syslog文件输出
·c 指定配置文件
执行过程输出到filebeat.out这个文件当中,& 后台运行

开一台elk1、查看输出日志的文件

查看日志发现报错

指定配置文件,再指定到数据工作目录
logstash -f file_nginx.conf --path.data /opt/test1 &
这个命令将启动logstash并使用file_nginx.conf作为配置文件,–path.data参数指定了logstash的数据目录为/opt/test1。&符号表示在后台运行logstash
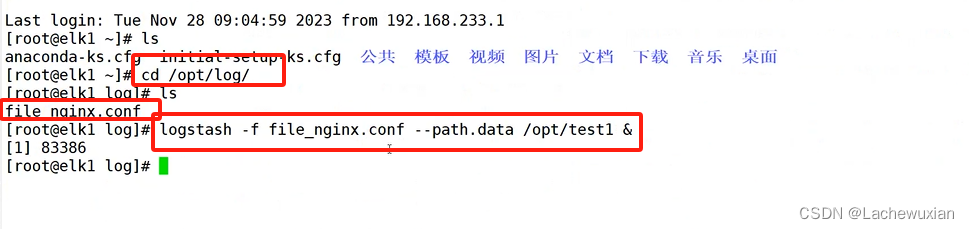
c测试下


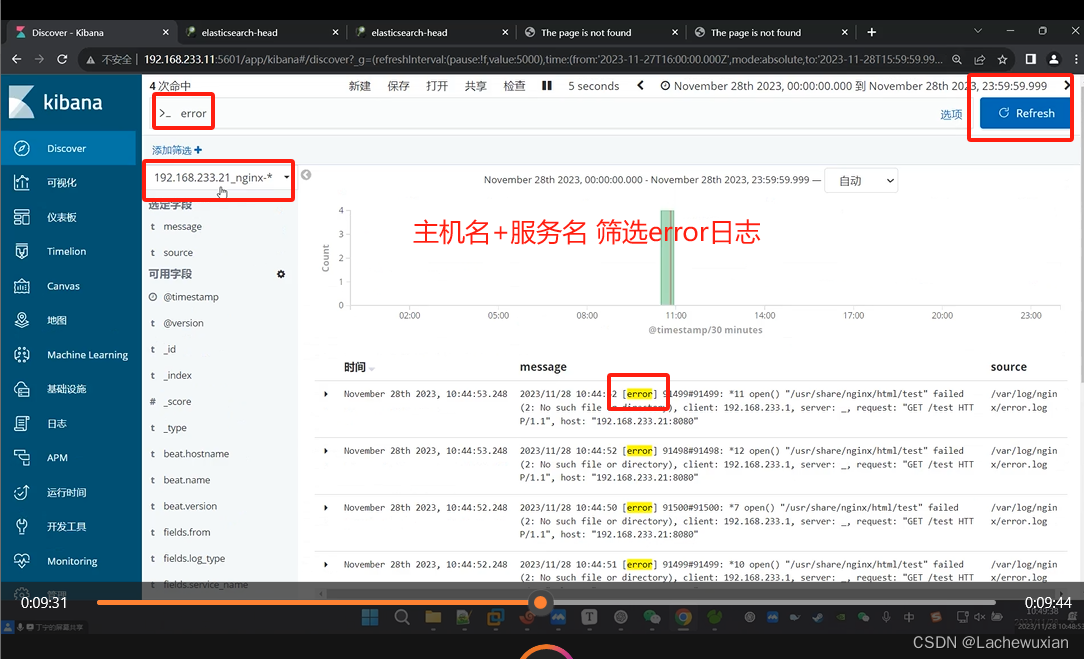
索引已经创建成功
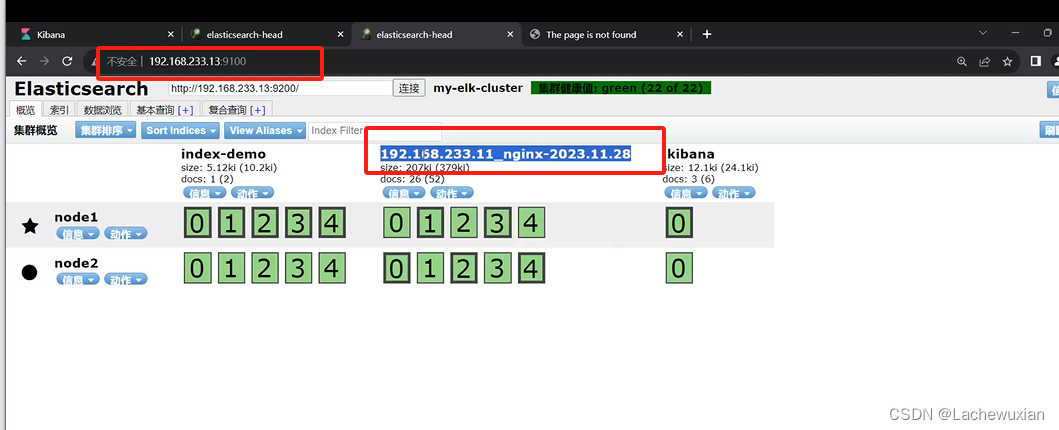
kabana也有索引




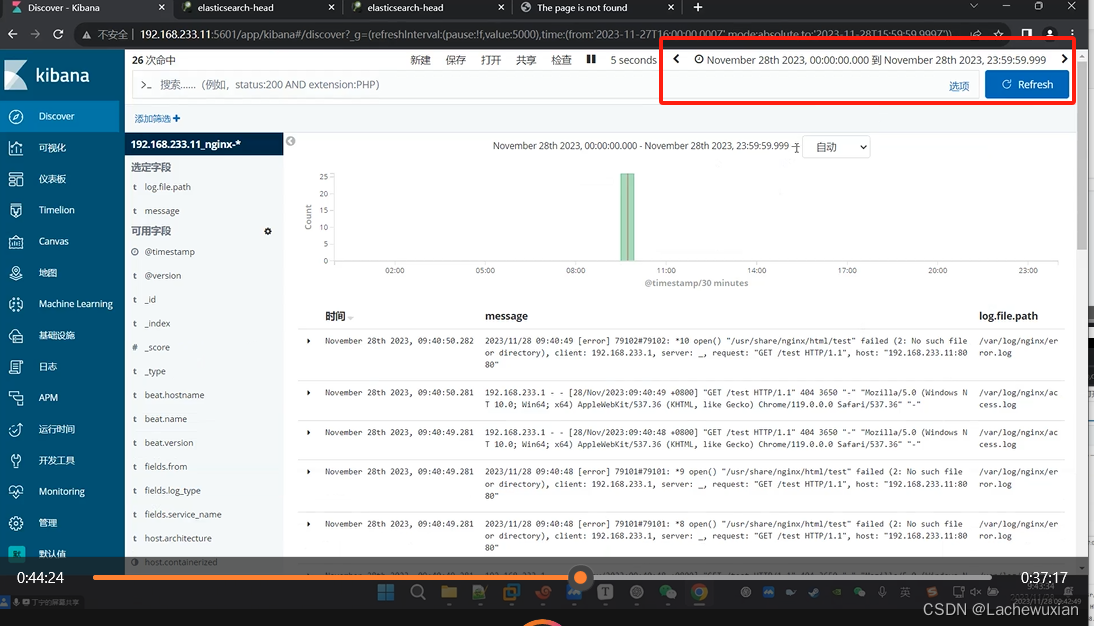
左边 选定字段

logstash通过filebeat远程收集多个日志
服务器装 mysql nginx httpd
在mysql 上192.168.233.21


日志目录一生成

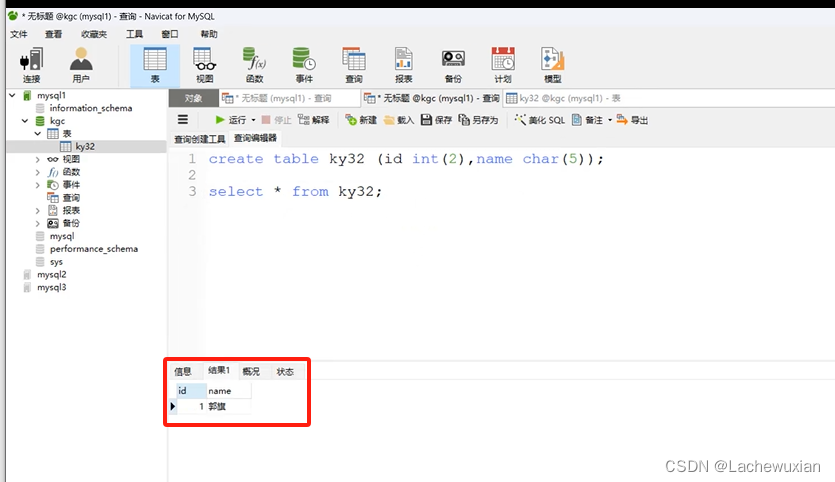
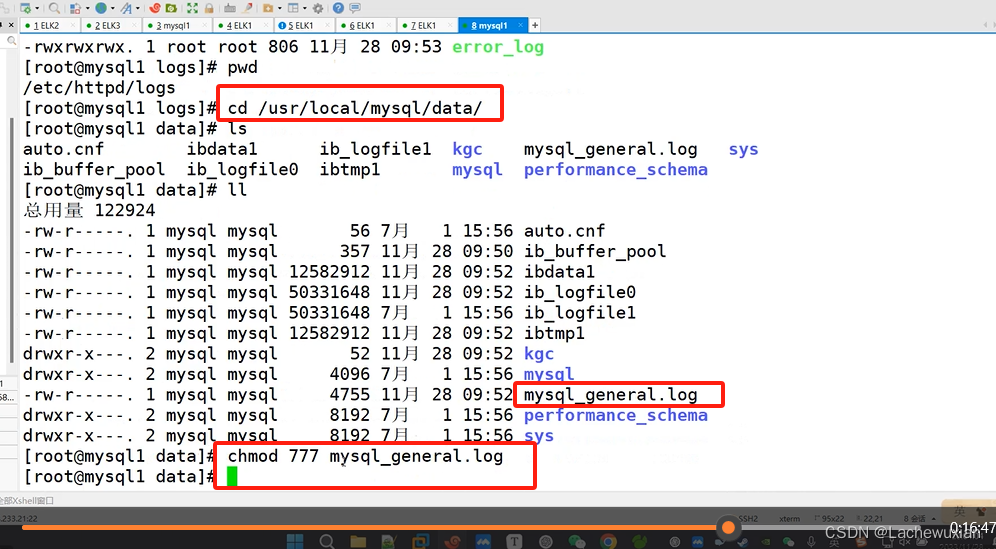
cat mysql_general.log
目录
创表数据日志已生产

装 nginx httpd


改下端口 防止端口冲突







拖入安装包filebeat
j解压
改名
备份


把这之间注释掉的信息 全部删除 留着没用

注释掉下一个output
 打开注释,输入Lostash的IP
打开注释,输入Lostash的IP

开一台mysql、
查看NGINX的日志目录路径格式 给NGINX日志目录授权

查看httpd目录路径格式 给httpd 日志目录授权


查看MySQL的日志目录路径格式,授权
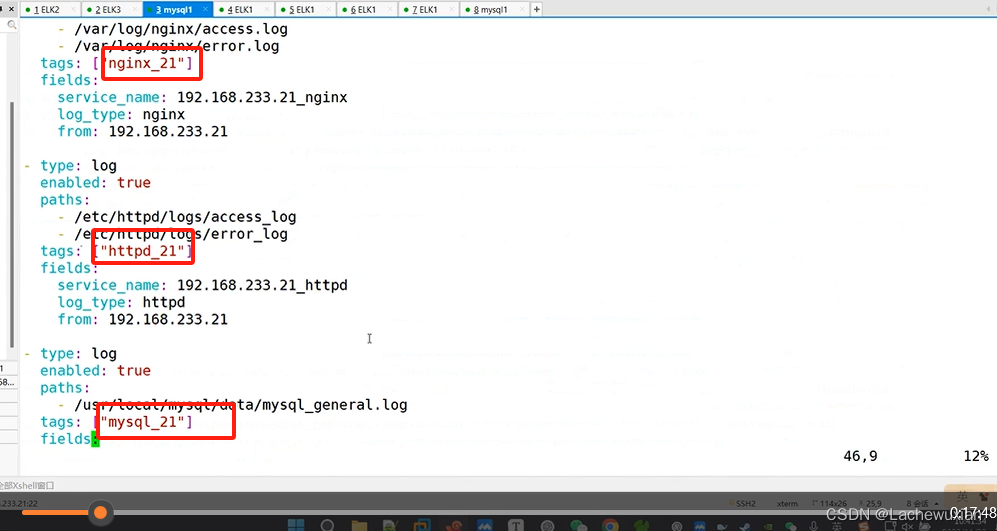
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- /var/log/nginx/error.log
tags: ["nginx"]
fields:
service_name: 192.168.233.21_nginx
log_type: nginx
from: 192.168.233.21
- type: log
enabled: true
paths:
- /etc/httpd/logs/access_log
- /etc/httpd/logs/error_log
tags: ["httpd"]
fields:
service_name: 192.168.233.21_httpd
log_type: httpd
from: 192.168.233.21
- type: log
enabled: true
paths:
- /usr/local/mysql/data/mysql_general.log
tags: ["mysql"]
fields:
service_name: 192.168.233.21_mysqld
log_type: mysql
from: 192.168.233.21
标识方便识别 再次修改下

 在ELK1 上192.168.233.11
在ELK1 上192.168.233.11
收日志到目录 /opt/log

接着上面 这里的标识也改下



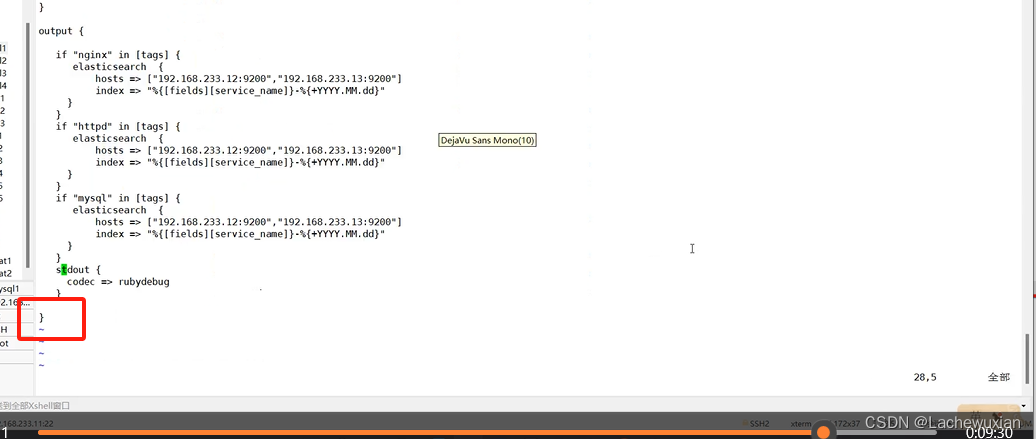
先到mysql上 启动felibeat文件往loastash上发

再到elk1上
指定配置文件,再指定到数据工作目录
这个命令将启动logstash并使用file_nginx.conf作为配置文件,–path.data参数指定了logstash的数据目录为/opt/test2。&符号表示在后台运行logstash





vim filebeat.yml
优化性能:
pipeline.workers 2
该参数用于设置 Logstash 处理事件的工作线程数量。默认值是核心数。
在一个拥有两个核心的系统上,可以设置为 2,以充分利用系统资源。
pipeline.batch.size 125
该参数定义了从输入中检索事件的批量大小,然后将这批事件发送到过滤器和工作线程。
默认值是 125。你可以根据你的需求和系统性能进行调整。
pipeline.batch.delay 50
该参数定义了在轮询下一个事件之前等待的时间,以确保形成一个适当大小的事件批量。
默认值是 50 毫秒。你可以根据实际情况进行调整。














 4324
4324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









