







步骤1:编码概念
步骤2:常见编码
步骤3:UNICODE和UTF
步骤4:Java采用的是Unicode
步骤5:一个汉字使用不同编码方式的表现
步骤6:文件的编码方式-记事本
步骤7:文件的编码方式-eclipse
步骤8:用FileInputStream 字节流正确读取中文
步骤9:用FileReader 字符流正确读取中文
步骤10:练习-数字对应的中文
步骤11:答案-数字对应的中文
步骤12:练习-移除BOM
步骤13:答案-移除BOM
步骤 1 : 编码概念
计算机存放数据只能存放数字,所有的字符都会被转换为不同的数字。
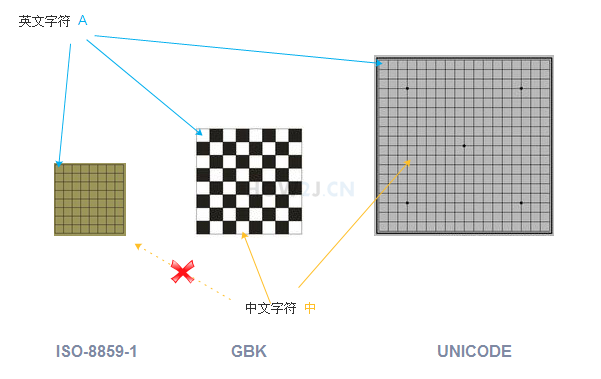
就像一个棋盘一样,不同的字,处于不同的位置,而不同的位置,有不同的数字编号。
有的棋盘很小,只能放数字和英文
有的大一点,还能放中文
有的“足够”大,能够放下世界人民所使用的所有文字和符号
如图所示,英文字符 A 能够放在所有的棋盘里,而且位置都差不多
中文字符, 中文字符 中 能够放在后两种棋盘里,并且位置不一样,而且在小的那个棋盘里,就放不下中文
步骤 2 : 常见编码
工作后经常接触的编码方式有如下几种:
ISO-8859-1 ASCII 数字和西欧字母
GBK GB2312 BIG5 中文
UNICODE (统一码,万国码)
其中
ISO-8859-1 包含 ASCII
GB2312 是简体中文,BIG5是繁体中文,GBK同时包含简体和繁体以及日文。
UNICODE 包括了所有的文字,无论中文,英文,藏文,法文,世界所有的文字都包含其中
步骤 3 : UNICODE和UTF
根据前面的学习,我们了解到不同的编码方式对应不同的棋盘,而UNICODE因为要存放所有的数据,那么它的棋盘是最大的。
不仅如此,棋盘里每个数字都是很长的(4个字节),因为不仅要表示字母,还要表示汉字等。
如果完全按照UNICODE的方式来存储数据,就会有很大的浪费。
比如在ISO-8859-1中,a 字符对应的数字是0x61
而UNICODE中对应的数字是 0x00000061,倘若一篇文章大部分都是英文字母,那么按照UNICODE的方式进行数据保存就会消耗很多空间
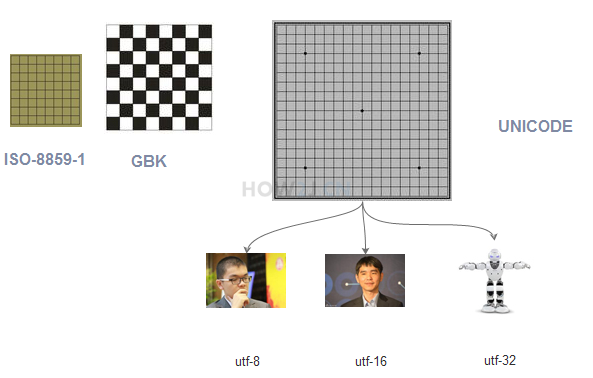
在这种情况下,就出现了UNICODE的各种减肥子编码, 比如UTF-8对数字和字母就使用一个字节,而对汉字就使用3个字节,从而达到了减肥还能保证健康的效果
UTF-8,UTF-16和UTF-32 针对不同类型的数据有不同的减肥效果,一般说来UTF-8是比较常用的方式
UTF-8,UTF-16和UTF-32 彼此的区别在此不作赘述,有兴趣的可以参考 unicode-百度百科
步骤 4 : Java采用的是Unicode
写在.java源代码中的汉字,在执行之后,都会变成JVM中的字符。
而这些中文字符采用的编码方式,都是使用UNICODE. "中"字对应的UNICODE是4E2D,所以在内存中,实际保存的数据就是十六进制的0x4E2D, 也就是十进制的20013。
|
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









