








降维方法
1、主成分分析(PCA)
在PCA中,数据从原来的坐标系转换到新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们可以忽略余下的坐标轴,即对数据进行降维处理。
2、因子分析(Factor Analysis)。在因子分析中,我们假设在观察数据的生成中有一些观察不到的隐变量(latent variable)。假设观察数据是这些隐变量和某些噪声数据的线性组合。那么隐变量的数据可能比观察数据的数目少,也就是说通过找到隐变量就可以实现数据降维。
3、独立成分分析(ICA)
ICA假设数据从N个数据源生成的,和因子分析有些类似。假设数据为多个数据源的混合观察结果,这些数据源之间在统计上是相互独立的,而在PCA中只假设数据是不相关的。同因子分析一样,如果数据源的数目少于观察数据的数目,则可实现降维。
注:PCA应用最广泛,所以只介绍PCA。
线性判别分析(LDA)是一种经典的监督降维算法。主成分分析(PCA)是一种经典的无监督降维算法。
PCA降维的两个准则:
最近重构性:样本集中所有点,重构后的点距离原来的点的误差之和最小。
最大可分性:样本在低维空间的投影尽可能分开。
1、PCA
**scikit-learn中提供一个PCA类来实现PCA模型
decomposition.PCA( )**
注:decomposition.PCA不能应用于稀疏矩阵且无法适用于超大规模数据(因它要求所有的数据一次加载进内存)
参数
n_components:一个整数,指定降维后的维数
属性
explained_variance_ratio_:一个数组,元素是每个主成分explained variance的比例
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets,decomposition,manifold
def load_data():
iris=datasets.load_iris()
return iris.data,iris.target
def test_PCA(*data):
X,y=data
pca=decomposition.PCA(n_components=None)
pca.fit(X)
print('explained variance ratio : %s'%str(pca.explained_variance_ratio_))
X,y=load_data()
test_PCA(X,y)
def plot_PCA(*data):
X,y=data
pca=decomposition.PCA(n_components=2)
pca.fit(X)
X_r=pca.transform(X)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2))
for label,color in zip(np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target=%d"%label,color=color)
ax.set_xlabel("X[0]")
ax.set_ylabel("Y[0]")
ax.legend(loc="best")
ax.set_title("PCA")
plt.show()
plot_PCA(X,y)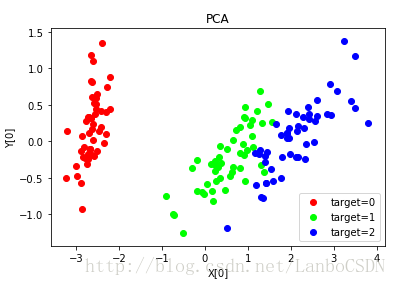
2、超大规模数据降维IncrementalPCA
可以将数据分批加载进内存。
3、KernelPCA
decomposition.KernelPCA( )
参数
n_components:一个整数,指定降维后的维数,如果为None,则维数不变。
kernel:一个字符串,指定核函数
–linear:线性核
–poly:多项式核
–rbf:高斯核函数
–sigmoid
alpha:一个整数,岭回归的超参数,用于计算逆转矩阵(当fit_inverse_transform=True时)。inverse:逆,transform:转。先逆后转。
属性
lambdas_:核化矩阵的特征值
alphas_:核化矩阵的特征向量
dual_coef_:逆转换矩阵
方法
fit(X[ , y]):训练模型
transform(X):执行降维
fit_transform(X[ , y]):训练模型并且降维
inverse_transform(X):执行升维,将数据从低维空间逆向转换到原始空间
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets,decomposition
def load_data():
'''
加载用于降维的数据
:return: 一个元组,依次为训练样本集和样本集的标记
'''
iris=datasets.load_iris()# 使用 scikit-learn 自带的 iris 数据集
return iris.data,iris.target
def test_KPCA(*data):
'''
测试 KernelPCA 的用法
:param data: 可变参数。它是一个元组,这里要求其元素依次为:训练样本集、训练样本的标记
:return: None
'''
X,y=data
kernels=['linear','poly','rbf','sigmoid']
for kernel in kernels:
kpca=decomposition.KernelPCA(n_components=None,kernel=kernel) # 依次测试四种核函数
kpca.fit(X)
print('kernel=%s --> lambdas: %s'% (kernel,kpca.lambdas_))
def plot_KPCA(*data):
'''
绘制经过 KernelPCA 降维到二维之后的样本点
:param data: 可变参数。它是一个元组,这里要求其元素依次为:训练样本集、训练样本的标记
:return: None
'''
X,y=data
kernels=['linear','poly','rbf','sigmoid']
fig=plt.figure()
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),
(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2),)# 颜色集合,不同标记的样本染不同的颜色
for i,kernel in enumerate(kernels):
kpca=decomposition.KernelPCA(n_components=2,kernel=kernel)
kpca.fit(X)
X_r=kpca.transform(X)# 原始数据集转换到二维
ax=fig.add_subplot(2,2,i+1) ## 两行两列,每个单元显示一种核函数的 KernelPCA 的效果图
for label ,color in zip( np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,
color=color)
ax.set_xlabel("X[0]")
ax.set_ylabel("X[1]")
ax.legend(loc="best")
ax.set_title("kernel=%s"%kernel)
plt.suptitle("KPCA")
plt.show()
def plot_KPCA_poly(*data):
'''
绘制经过 使用 poly 核的KernelPCA 降维到二维之后的样本点
:param data: 可变参数。它是一个元组,这里要求其元素依次为:训练样本集、训练样本的标记
:return: None
'''
X,y=data
fig=plt.figure()
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),
(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2),)# 颜色集合,不同标记的样本染不同的颜色
Params=[(3,1,1),(3,10,1),(3,1,10),(3,10,10),(10,1,1),(10,10,1),(10,1,10),(10,10,10)] # poly 核的参数组成的列表。
# 每个元素是个元组,代表一组参数(依次为:p 值, gamma 值, r 值)
# p 取值为:3,10
# gamma 取值为 :1,10
# r 取值为:1,10
# 排列组合一共 8 种组合
for i,(p,gamma,r) in enumerate(Params):
kpca=decomposition.KernelPCA(n_components=2,kernel='poly'
,gamma=gamma,degree=p,coef0=r) # poly 核,目标为2维
kpca.fit(X)
X_r=kpca.transform(X)# 原始数据集转换到二维
ax=fig.add_subplot(2,4,i+1)## 两行四列,每个单元显示核函数为 poly 的 KernelPCA 一组参数的效果图
for label ,color in zip( np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,
color=color)
ax.set_xlabel("X[0]")
ax.set_xticks([]) # 隐藏 x 轴刻度
ax.set_yticks([]) # 隐藏 y 轴刻度
ax.set_ylabel("X[1]")
ax.legend(loc="best")
ax.set_title(r"$ (%s (x \cdot z+1)+%s)^{%s}$"%(gamma,r,p))
plt.suptitle("KPCA-Poly")
plt.show()
def plot_KPCA_rbf(*data):
'''
绘制经过 使用 rbf 核的KernelPCA 降维到二维之后的样本点
:param data: 可变参数。它是一个元组,这里要求其元素依次为:训练样本集、训练样本的标记
:return: None
'''
X,y=data
fig=plt.figure()
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),
(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2),)# 颜色集合,不同标记的样本染不同的颜色
Gammas=[0.5,1,4,10]# rbf 核的参数组成的列表。每个参数就是 gamma值
for i,gamma in enumerate(Gammas):
kpca=decomposition.KernelPCA(n_components=2,kernel='rbf',gamma=gamma)
kpca.fit(X)
X_r=kpca.transform(X)# 原始数据集转换到二维
ax=fig.add_subplot(2,2,i+1)## 两行两列,每个单元显示核函数为 rbf 的 KernelPCA 一组参数的效果图
for label ,color in zip( np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,
color=color)
ax.set_xlabel("X[0]")
ax.set_xticks([]) # 隐藏 x 轴刻度
ax.set_yticks([]) # 隐藏 y 轴刻度
ax.set_ylabel("X[1]")
ax.legend(loc="best")
ax.set_title(r"$\exp(-%s||x-z||^2)$"%gamma)
plt.suptitle("KPCA-rbf")
plt.show()
def plot_KPCA_sigmoid(*data):
'''
绘制经过 使用 sigmoid 核的KernelPCA 降维到二维之后的样本点
:param data: 可变参数。它是一个元组,这里要求其元素依次为:训练样本集、训练样本的标记
:return: None
'''
X,y=data
fig=plt.figure()
colors=((1,0,0),(0,1,0),(0,0,1),(0.5,0.5,0),(0,0.5,0.5),(0.5,0,0.5),
(0.4,0.6,0),(0.6,0.4,0),(0,0.6,0.4),(0.5,0.3,0.2),)# 颜色集合,不同标记的样本染不同的颜色
Params=[(0.01,0.1),(0.01,0.2),(0.1,0.1),(0.1,0.2),(0.2,0.1),(0.2,0.2)]# sigmoid 核的参数组成的列表。
# 每个元素就是一种参数组合(依次为 gamma,coef0)
# gamma 取值为: 0.01,0.1,0.2
# coef0 取值为: 0.1,0.2
# 排列组合一共有 6 种组合
for i,(gamma,r) in enumerate(Params):
kpca=decomposition.KernelPCA(n_components=2,kernel='sigmoid',gamma=gamma,coef0=r)
kpca.fit(X)
X_r=kpca.transform(X)# 原始数据集转换到二维
ax=fig.add_subplot(3,2,i+1)## 三行两列,每个单元显示核函数为 sigmoid 的 KernelPCA 一组参数的效果图
for label ,color in zip( np.unique(y),colors):
position=y==label
ax.scatter(X_r[position,0],X_r[position,1],label="target= %d"%label,
color=color)
ax.set_xlabel("X[0]")
ax.set_xticks([]) # 隐藏 x 轴刻度
ax.set_yticks([]) # 隐藏 y 轴刻度
ax.set_ylabel("X[1]")
ax.legend(loc="best")
ax.set_title(r"$\tanh(%s(x\cdot z)+%s)$"%(gamma,r))
plt.suptitle("KPCA-sigmoid")
plt.show()
if __name__=='__main__':
X,y=load_data() # 产生用于降维的数据集
test_KPCA(X,y) # 调用 test_KPCA
#plot_KPCA(X,y) # 调用 plot_KPCA
#plot_KPCA_poly(X,y) # 调用 plot_KPCA_poly
#plot_KPCA_rbf(X,y) # 调用 plot_KPCA_rbf
#plot_KPCA_sigmoid(X,y) # 调用 plot_KPCA_sigmoid总结一下:实例就是把鸢尾花这个4维数据降维降到2维的。从plot_KPCA_poly函数可以看到,采用同样的多项式函数,如果参数不同,其降维后的数据分布是不同的。其他函数亦是如此。
将数据转换成前N个主成分的伪代码大致如下:
- 去除平均值
- 计算协方差矩阵
- 计算协方差矩阵的特征值和特征向量
- 将特征值从大到小排序
- 保留最上面的N个特征向量
将数据转换到上述N个特征向量构建的新空间中
PCA可以从数据中识别其主要特征,它是通过沿着数据最大方差方向旋转坐标轴来实现的。选择方差最大的方向作为第一条坐标轴,后续坐标轴与前面的坐标轴正交。协方差矩阵上的特征值分析可以用一系列的正交坐标轴来获取。















 1439
1439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









