







由于视频显著性检测的带有标签的视频数据集是比较困难的,因此本文提出了一种不需要标签数据的VSOD方法。
一、摘要
那么如何去实现无标签数据的视频显著性检测呢?
本文想到一个方法,即渐进式的,先定位显著对象后分割显著对象。
而定位显著对象我们可以在SOD上完成,但由于SOD中是缺乏动态的运动信息的,因此可以在SOD期间引入动态显著性,但保留相同的精细分割过程。
具体过程其实是一个生成时空位置标签的算法,该算法可以生成高显著性的位置标签并且跟踪相邻帧的显著对象。接着根据这些生成的标签,利用一个双流定位网络,引入一个光流分支去完成视频显著对象定位。
二、实现流程
由于以往的VSOD方法在处理场景丰富的大规模数据集时是比较困难的,因此本文为了克服这一点,使用场景丰富的SOD数据集去完成VSOD。
即,利用SOD数据集去实现VSOD,经过研究,发现同时具有静态信息和动态信息的位置有很大可能是显著区域。
2.1 如何利用SOD去实现VSOD?
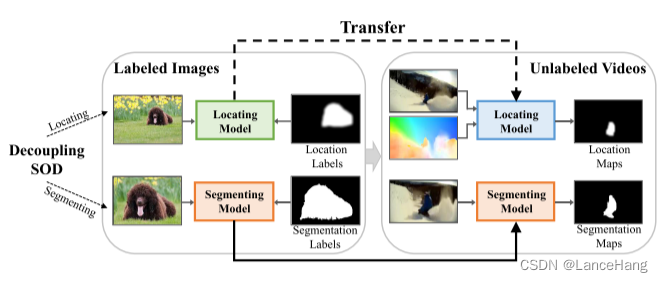
如图,我们分别使用的SOD数据和未标记的视频数据,将SOD解耦为谷底的定位和分割,利用SOD和VSOD之间的定位差异性和分割相似性来将知识从图像转移到视频。那么如何进行知识转移呢?
可以用粗定位和精细分割实现知识转移:
①利用在SOD数据集上训练的CLM,它可以分别从帧和光流图像中预测静态位置图和动态位置图。
②通过预测的静态位置图和动态位置图,设计一个生成时空位置标签的方法。
③提出一种光流跟踪方法去获取相邻帧中相同显著对象的时空位置图。(这些位置图也被认为是视频显著对象位置图)
④提出一个双流定位网络,利用这些帧和相应的时空位置图来定位视频显著对象。
⑤基于SOD和VSOD在显著对象分割上的相似性,可以直接用在SOD数据集上训练的精细分割模型来实现VSOD的精确分割。
2.2 知道了知识转移的大致流程,那么如何去实现呢?
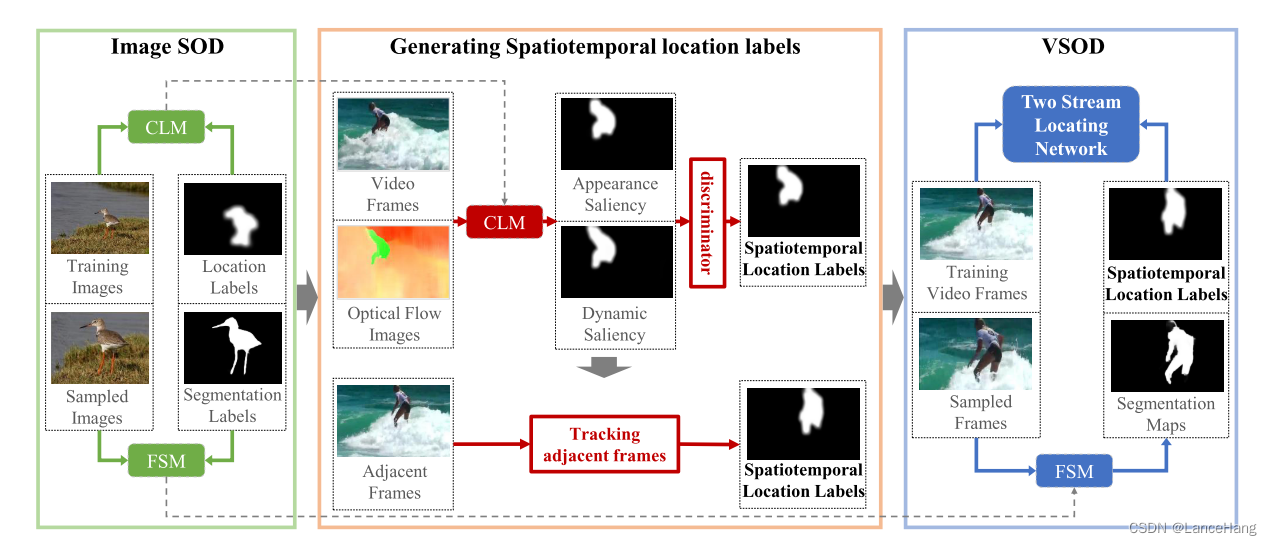
如图,即我们的算法框架,它包含了图像SOD、生成时空位置标签和VSOD。
其中图像SOD包含生成时空位置标签的CLM和用于最终视频显著对象分割的FSM。
时空位置标签通过训练的CLM生成,并且基于生成的时空位置标签,训练能定位所有帧的显著对象区域的双流定位网络。
最终VSOD通过训练好的双流定位网络和FSM实现。
2.3 那么他们具体如何工作呢?
- CLM和FSM由图像SOD数据集DUSTR训练,CLM是为了突出包含高显著性区域,它可以从视频帧中识别静态显著性区域,并从光流图像中识别动态显著性区域,而一个对象同时在静态显著性区域和动态显著性区域时,这个对象则可以被认为是视频显著对象。
- 并且基于静态显著性区域和动态显著性区域的相似性,就能识别高显著性帧,从而定位视频显著区域。
- 由于相邻帧视频之间的连续性,则可以利用相邻帧跟踪方法定位相邻帧中包含相同显著对象的显著区域。
- 用一个双流定位网络,通过使用高显著性帧及其相邻的光流图像作为输入、CLM作为时空位置标签预测的显著区域去学习视频显著对象的位置。
- 接着可以用FSM进行精细分割。
三、算法框架详细介绍
上面也说了,该算法由图像SOD、生成时空位置标签和VSOD组成。
3.1 图像SOD
图像SOD可分为两部分:CLM和FSM。而为了帮助VSOD充分利用在图像上学习的定位和分割知识,需要走三步:CLM、FSM和基于注意力的采样器。
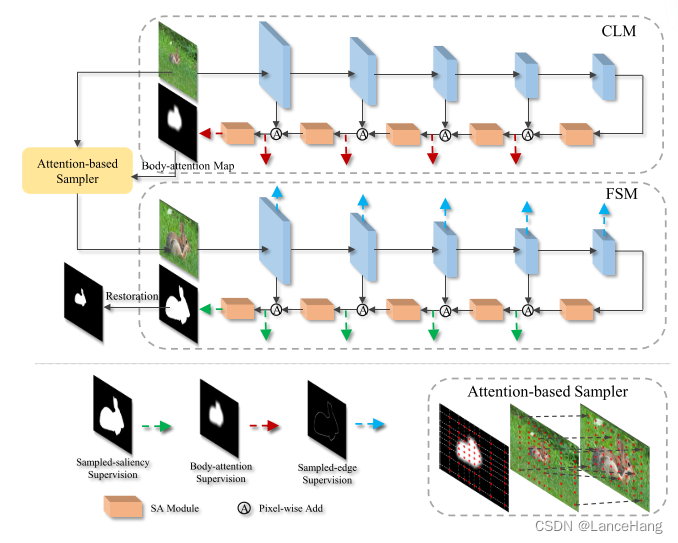
- 其中CLM是一种定位显著对象的网络,它基于特征金字塔(FPN)。身体注意力位置图被视为CLM的标签,以引导模型去聚焦于包含显著对象的粗糙区域(这些区域通过膨胀操作和高斯模糊操作生成)。
- CLM输出的身体注意力位置图被用来增加图像中与显著对象相关区域的分辨率,这样就能放大显著对象细节,接着把处理后的图像作为FSM的输入,使其更好的完成图像分割。
- 在细粒度分类任务中提出了基于注意力的采样器,去放大显著对象的细节。它主要是通过计算原始图像和采样图像的坐标之间的映射函数,对具有高关注度的基于注意力地图的区域进行更密集的采样。而恢复过程则是利用该映射函数将预测的采样分割结果恢复到原始形式。
3.2 生成时空位置标签
- 生成时空位置标签
时空显著对象:能在静态帧中吸引人类注意力,并在连续帧中保持明显的运动的对象。
高显著性帧:视频中每个对象都是时空显著对象。
时空位置标签的生成由外观显著性预测分支、动态显著性预测分支和高显著性帧判别器组成。
对于静态显著性分支:用图像数据集上训练的CLM来找到静态显著性区域。
对于动态分支:去估计视频帧的光流,并对其进行渲染。
高显著性帧判别器:经过渲染后能很容易利用CLM检测动态显著性区域,因此可以用高显著性帧判别器来确定静态显著性区域和动态显著性区域是否相似(可以利用IOU判别)。
由于动态显著性区域可能会因为显著对象的局部运动而没有包含完整的对象,但是静态显著性区域由训练好的CLM获得,他有很大的概率包含完整的对象,因此可以用这些高显著性帧和他们相应的显著对象位置图作为训练数据的一部分,用于后面的双流定位网络。
- 跟踪相邻帧
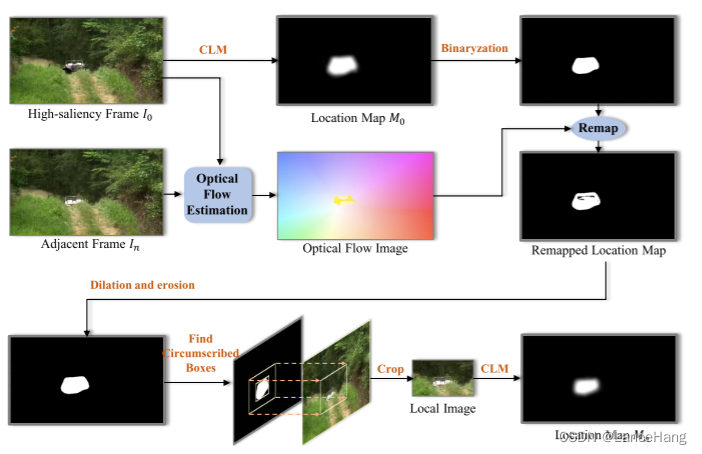
为什么要跟踪视频帧呢?
在获得带有显著对象位置图的高显著性帧之后,基于对应的光流信息可以生成相邻帧的显著对象位置图。但如果在双流定位网络输入时只有这种高显著性帧的话,那么训练模型就只在这种帧上表现良好但在其他没有高显著性对象的帧上表现不好。
那么如何实现跟踪效果呢?
由于视频帧有连续性,因此这些高显著性帧的相邻帧中视频显著对象很可能和高显著性帧的视频显著对象相同。因此可以将这些帧添加到训练数据中。如上图。
3.3 双流定位网络
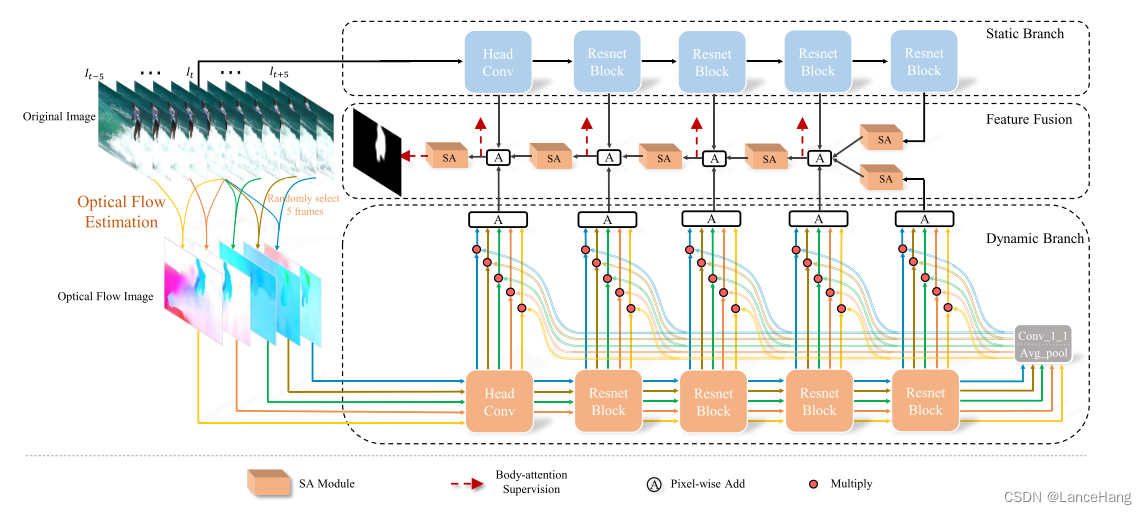
上图即为双流定位网络的详细说明,他可以有效的适用这种稀疏时空位置标签的数据结构,并且通过光流图像引入了运动信息。
他有三个模块组成:静态特征提取分支、动态特征提取分支和特征融合模块。
其中静态分支和动态分支是基于图像SOD数据集训练的CLM,输入分别是RGB图像和五个光流图像。
那么这如何获得光流图像呢?
从上图可以看出我们会从当前帧的前五帧和后五帧中随机选取五张图,与当前帧做对比计算当前帧的光流图像。
那么为什么要输入五个光流图呢?
因为只输入一个的话网络的结果很容易受到光流图像的质量的影响,但输入五张的话就会包含或多或少不同的运动信息,使结果变得更好。
特征融合模块的结构类似于FPN的解码器,不同的是在每层的特征融合之后引入了Side-out aggregation(SA)模块。
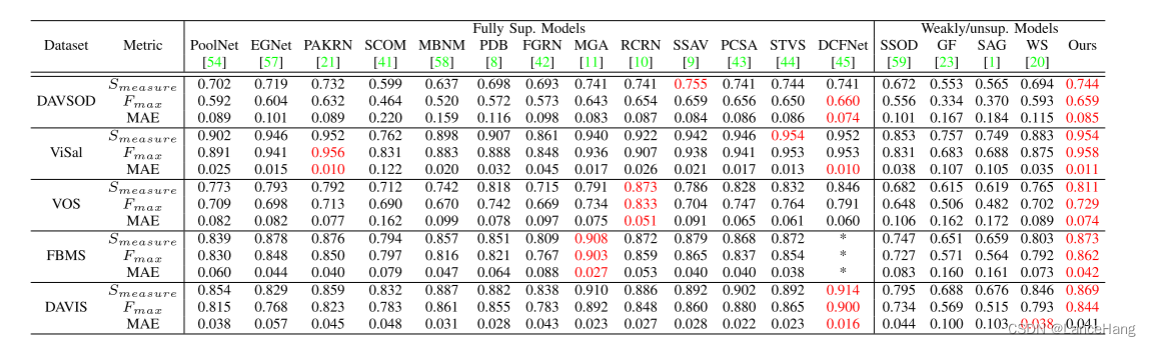
四、实验结果


















 1936
1936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









