







写在前面:本文只为了自己日后忘记时,温习巩固用,本人没有做出任何见解,纯属方便回顾阅读。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
原文标题:EAST: An Efficient and Accurate Scene Text Detector
这篇论文发表于2017年的CVPR,文章提出了一个高效精确的场景文字检测器。可以快速精确的产生文字追踪。该方法使用单个神经网络直接从整幅图片中预测任意方向的四边形文本行,消去了不必要的中间步骤(候选区域聚合和单词的分割)。该方法注重设计损失函数和神经网络体系结构。实验在包括ICDAR2015,COCO-Text和MSRA-TD500等经典数据集上,验证了提出的算法不管是在精度还是效率上都有着特别好的效果。在数据集ICDAR2015上,本文算法结果在13.2fps,720p分辨率下,F得分0.782。
场景文字检测流程

(a,b,c,d)都包含多个步骤,会需要经过多次优化,不彻底的优化导致误差放大,进而效果不好。
(e)该文章工作流程抛弃了不必要的中间步骤,实现了端到端的训练和优化。
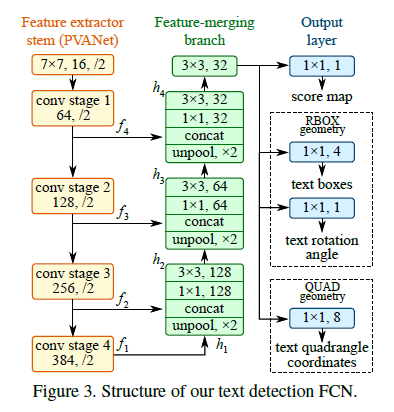
FCN网络结构
特征归并公式

输出几何形状设计

模型可以分解为三个部分:特征提取器、功能合并分支和输出层。
【特征提取器】最初可以利用一个卷积层和池化层交错的卷积神经网络进行预训练,可以得到四个级别的特征图fi,大小分别是原图的1/32,1/16,1/8和1/4。
【功能合并分支】在特征归并部分,逐步合并他们,在每一个归并阶段,从上一个阶段来的特征图最先进行unpooling,来增倍图的大小,然后与当前特征图级联(就是通道数串联)。然后,利用一个1*1的卷积层减少通道数并减少计算量,接着是一个3*3的卷积层将信息融合,最终产生本归并阶段的结果。在最后一个归并阶段之后,利用一个3*3卷积层产生最终的归并部分的特征图,并输入到输出层。
【输出层】对于RBOX,这个几何图形由4个通道的轴向包围盒(AABB)R和1个通道的旋转角度θ表示。R的公式和文献9中一样,其中4个通道分别表示4个距离(定位点到上右下左边界);对于QUAD Q,我们使用8个通道表示四边形四个顶点{pi | i<-{1,2,3,4}}到像素位置的坐标变换。由于每一个距离偏移都包含2个数字(δxi, δyi),那么几何输出包含了8个通道。
NMS设计思想
在假定邻近像素的几何关系趋于高度相关的假设下,逐行合并几何形状,同时合并同一行中的几何体,迭代合并当前遇到的最后一个几何体。在最好的情况下,运行速度提高到O(n),尽管其最坏情况与朴素的情况相同,只要局部假设成立,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8213
8213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









