







一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-
光照条件:我们无法对自然场景图像中的光照条件做出任何假设。可能接近黑暗,相机上的闪光灯可能打开,或者太阳可能很耀眼,使整个图像饱和。
-
分辨率:并非所有相机都是一样的——我们可能会处理分辨率低于标准的相机。
-
非纸质物体:大多数(但不是全部)纸张不具有反射性(至少在您尝试扫描的纸张环境中)。自然场景中的文本可能具有反射性,包括徽标、标志等。
-
非平面对象:考虑将文本环绕在瓶子周围时会发生什么 - 表面上的文本会扭曲变形。虽然人类可能仍然能够轻松“检测”和阅读文本,但我们的算法将面临困难。我们需要能够处理这样的用例。
-
未知布局:我们不能使用任何先验信息来为我们的算法提供有关文本所在位置的“线索”。
=========================================================================
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XXPKId7V-1637126841247)(https://pyimagesearch.com/wp-content/uploads/2018/08/opencv_text_detection_east.jpg)]
随着 OpenCV 3.4.2 和 OpenCV 4 的发布,我们现在可以使用名为 EAST 的基于深度学习的文本检测器,该检测器基于 Zhou 等人 2017 年的论文 EAST: An Efficient and Accurate Scene Text Detector。
我们称该算法为“EAST”,因为它是一个:高效且准确的场景文本检测管道。
这组作者说,EAST 管道能够预测 720p 图像上任意方向的单词和文本行,而且可以以 13 FPS 的速度运行。 也许最重要的是,由于深度学习模型是端到端的,因此可以避开其他文本检测器通常应用的计算成本高的子算法,包括候选聚合和单词分区。
为了构建和训练这样一个深度学习模型,EAST 方法利用了新颖、精心设计的损失函数。 有关 EAST 的更多详细信息,包括架构设计和训练方法,请务必参阅作者的出版物。
===============================================================
$ tree --dirsfirst
.
├── images
│ ├── car_wash.png
│ ├── lebron_james.jpg
│ └── sign.jpg
├── frozen_east_text_detection.pb
├── text_detection.py
└── text_detection_video.py
请注意,我在 images/ 目录中提供了三张示例图片。 您可能希望添加自己的智能手机收集的图像或您在网上找到的图像。 我们今天将审查两个 .py 文件:
-
text_detection.py :检测静态图像中的文本。
-
text_detection_video.py :通过网络摄像头或输入视频文件检测文本。
===============================================================
我今天包含的文本检测实现基于 OpenCV 的官方 C++ 示例;但是,我必须承认,将其转换为 Python 时遇到了一些麻烦。
首先,Python 中没有 Point2f 和 RotatedRect 函数,因此,我无法 100% 模仿 C++ 实现。 C++ 实现可以生成旋转的边界框,但不幸的是,我今天与您分享的那个不能。
其次,NMSBoxes 函数不返回 Python 绑定的任何值(至少对于我的 OpenCV 4 预发布安装),最终导致 OpenCV 抛出错误。 NMSBoxes 函数可以在 OpenCV 3.4.2 中工作,但我无法对其进行详尽的测试。
我在 imutils 中使用我自己的非最大值抑制实现解决了这个问题,但同样,我不相信这两个是 100% 可互换的,因为看起来 NMSBoxes 接受额外的参数。
鉴于所有这些,我已尽最大努力为您提供最好的 OpenCV 文本检测实现,使用我拥有的工作功能和资源。如果您对该方法有任何改进,请随时在下面的评论中分享。
===============================================================================
在开始之前,我想指出您的系统上至少需要安装 OpenCV 3.4.2(或 OpenCV 4)才能使用 OpenCV 的 EAST 文本检测器,接下来,确保您的系统上也安装/升级了 imutils:
pip install --upgrade imutils
此时您的系统已经配置完毕,因此打开 text_detection.py 并插入以下代码:
import the necessary packages
from imutils.object_detection import non_max_suppression
import numpy as np
import argparse
import time
import cv2
construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument(“-i”, “–image”, type=str,
help=“path to input image”)
ap.add_argument(“-east”, “–east”, type=str,
help=“path to input EAST text detector”)
ap.add_argument(“-c”, “–min-confidence”, type=float, default=0.5,
help=“minimum probability required to inspect a region”)
ap.add_argument(“-w”, “–width”, type=int, default=320,
help=“resized image width (should be multiple of 32)”)
ap.add_argument(“-e”, “–height”, type=int, default=320,
help=“resized image height (should be multiple of 32)”)
args = vars(ap.parse_args())
首先,导入所需的包和模块。 值得注意的是,我们从 imutils.object_detection 导入了 NumPy、OpenCV 和我对 non_max_suppression 的实现。 然后我们继续解析五个命令行参数:
–image :我们输入图像的路径。
–east : EAST 场景文本检测器模型文件路径。
–min-confidence :确定文本的概率阈值。 可选, default=0.5 。
–width :调整后的图像宽度 - 必须是 32 的倍数。默认值为 320 时可选。
–height :调整后的图像高度 - 必须是 32 的倍数。默认值为 320 时可选。
重要提示:EAST 文本要求您的输入图像尺寸是 32 的倍数,因此如果您选择调整 --width 和 --height 值,请确保它们是 32 的倍数! 从那里,让我们加载我们的图像并调整它的大小:
load the input image and grab the image dimensions
image = cv2.imread(args[“image”])
orig = image.copy()
(H, W) = image.shape[:2]
set the new width and height and then determine the ratio in change
for both the width and height
(newW, newH) = (args[“width”], args[“height”])
rW = W / float(newW)
rH = H / float(newH)
resize the image and grab the new image dimensions
image = cv2.resize(image, (newW, newH))
(H, W) = image.shape[:2]
我们加载并复制我们的输入图像。 确定原始图像尺寸与新图像尺寸的比率(基于为 --width 和 --height 提供的命令行参数)。 然后我们调整图像大小,忽略纵横比。 为了使用 OpenCV 和 EAST 深度学习模型进行文本检测,我们需要提取两层的输出特征图:
define the two output layer names for the EAST detector model that
we are interested – the first is the output probabilities and the
second can be used to derive the bounding box coordinates of text
layerNames = [
“feature_fusion/Conv_7/Sigmoid”,
“feature_fusion/concat_3”]
我们构建了一个 layerNames 列表:
第一层是我们的输出 sigmoid 激活,它为我们提供了一个区域是否包含文本的概率。
第二层是输出特征图,表示图像的“几何”——我们将能够使用这个几何来推导出输入图像中文本的边界框坐标
让我们加载 OpenCV 的 EAST 文本检测器:
load the pre-trained EAST text detector
print(“[INFO] loading EAST text detector…”)
net = cv2.dnn.readNet(args[“east”])
construct a blob from the image and then perform a forward pass of
the model to obtain the two output layer sets
blob = cv2.dnn.blobFromImage(image, 1.0, (W, H),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
start = time.time()
net.setInput(blob)
(scores, geometry) = net.forward(layerNames)
end = time.time()
show timing information on text prediction
print(“[INFO] text detection took {:.6f} seconds”.format(end - start))
我们使用 cv2.dnn.readNet 将神经网络加载到内存中,方法是将路径传递给 EAST 检测器。
然后,我们通过将其转换为 blob 来准备我们的图像。要阅读有关此步骤的更多信息,请参阅深度学习:OpenCV 的 blobFromImage 工作原理。 为了预测文本,我们可以简单地将 blob 设置为输入并调用 net.forward。 这些行被抓取时间戳包围,以便我们可以打印经过的时间。 通过将 layerNames 作为参数提供给 net.forward,我们指示 OpenCV 返回我们感兴趣的两个特征图:
-
用于导出输入图像中文本的边界框坐标的输出几何图
-
同样,分数图,包含给定区域包含文本的概率
我们需要一个一个地循环这些值中的每一个:
grab the number of rows and columns from the scores volume, then
initialize our set of bounding box rectangles and corresponding
confidence scores
(numRows, numCols) = scores.shape[2:4]
rects = []
confidences = []
loop over the number of rows
for y in range(0, numRows):
extract the scores (probabilities), followed by the geometrical
data used to derive potential bounding box coordinates that
surround text
scoresData = scores[0, 0, y]
xData0 = geometry[0, 0, y]
xData1 = geometry[0, 1, y]
xData2 = geometry[0, 2, y]
xData3 = geometry[0, 3, y]
anglesData = geometry[0, 4, y]
我们首先获取分数卷的维度(,然后初始化两个列表:
-
rects :存储文本区域的边界框 (x, y) 坐标
-
置信度:将与每个边界框关联的概率存储在 rects 中
我们稍后将对这些区域应用非极大值抑制。 循环遍历行。提取当前行 y 的分数和几何数据。 接下来,我们遍历当前选定行的每个列索引:
loop over the number of columns
for x in range(0, numCols):
if our score does not have sufficient probability, ignore it
if scoresData[x] < args[“min_confidence”]:
continue
compute the offset factor as our resulting feature maps will
be 4x smaller than the input image
(offsetX, offsetY) = (x * 4.0, y * 4.0)
extract the rotation angle for the prediction and then
compute the sin and cosine
angle = anglesData[x]
cos = np.cos(angle)
sin = np.sin(angle)
use the geometry volume to derive the width and height of
the bounding box
h = xData0[x] + xData2[x]
w = xData1[x] + xData3[x]
compute both the starting and ending (x, y)-coordinates for
the text prediction bounding box
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
add the bounding box coordinates and probability score to
our respective lists
rects.append((startX, startY, endX, endY))
confidences.append(scoresData[x])
对于每一行,我们开始遍历列。 我们需要通过忽略概率不够高的区域来过滤掉弱文本检测。
当图像通过网络时,EAST 文本检测器自然会减小体积大小——我们的体积大小实际上比我们的输入图像小 4 倍,因此我们乘以 4 以将坐标带回原始图像。
提取角度数据。 然后我们分别更新我们的矩形和置信度列表。 我们快完成了! 最后一步是对我们的边界框应用非极大值抑制来抑制弱重叠边界框,然后显示结果文本预测:
apply non-maxima suppression to suppress weak, overlapping bounding
boxes
boxes = non_max_suppression(np.array(rects), probs=confidences)
loop over the bounding boxes
for (startX, startY, endX, endY) in boxes:
scale the bounding box coordinates based on the respective
ratios
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)
draw the bounding box on the image
cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 255, 0), 2)
show the output image
cv2.imshow(“Text Detection”, orig)
cv2.waitKey(0)
正如我在上一节中提到的,我无法在我的 OpenCV 4 安装 (cv2.dnn.NMSBoxes) 中使用非最大值抑制,因为 Python 绑定没有返回值,最终导致 OpenCV 出错。我无法完全在 OpenCV 3.4.2 中进行测试,因此它可以在 v3.4.2 中运行。
相反,我使用了 imutils 包(第 114 行)中提供的非最大值抑制实现。结果看起来还是不错的;但是,我无法将我的输出与 NMSBoxes 函数进行比较以查看它们是否相同。 循环我们的边界框,将坐标缩放回原始图像尺寸,并将输出绘制到我们的原始图像。原始图像会一直显示,直到按下某个键。
作为最后的实现说明,我想提一下,我们用于循环分数和几何体的两个嵌套 for 循环将是一个很好的例子,说明您可以利用 Cython 显着加速您的管道。我已经使用 OpenCV 和 Python 在快速优化的“for”像素循环中展示了 Cython 的强大功能。
========================================================================
您准备好将文本检测应用于图像了吗?
下载frozen_east_text_detection,地址:
oyyd/frozen_east_text_detection.pb (github.com)
。 从那里,您可以在终端中执行以下命令(注意两个命令行参数):
$ python text_detection.py --image images/lebron_james.jpg \
–east frozen_east_text_detection.pb
您的结果应类似于下图:
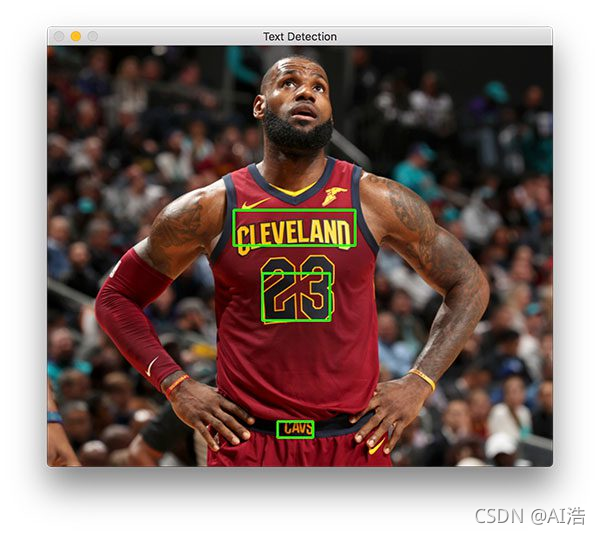
在勒布朗·詹姆斯身上标识了三个文本区域。 现在让我们尝试检测商业标志的文本:
$ python text_detection.py --image images/car_wash.png \
–east frozen_east_text_detection.pb
使用 OpenCV 检测视频中的文本
现在我们已经了解了如何检测图像中的文本,让我们继续使用 OpenCV 检测视频中的文本。 这个解释将非常简短; 请根据需要参阅上一节了解详细信息。 打开 text_detection_video.py 并插入以下代码:
import the necessary packages
from imutils.video import VideoStream
from imutils.video import FPS
from imutils.object_detection import non_max_suppression
import numpy as np
import argparse
import imutils
import time
import cv2
我们首先导入我们的包。 我们将使用 VideoStream 访问网络摄像头和 FPS 来对这个脚本的每秒帧数进行基准测试。 其他一切都与上一节相同。
为方便起见,让我们定义一个新函数来解码我们的预测函数——它将在每一帧中重复使用,并使我们的循环更清晰:
def decode_predictions(scores, geometry):
grab the number of rows and columns from the scores volume, then
initialize our set of bounding box rectangles and corresponding
confidence scores
(numRows, numCols) = scores.shape[2:4]
rects = []
confidences = []
loop over the number of rows
for y in range(0, numRows):
extract the scores (probabilities), followed by the
geometrical data used to derive potential bounding box
coordinates that surround text
scoresData = scores[0, 0, y]
xData0 = geometry[0, 0, y]
xData1 = geometry[0, 1, y]
xData2 = geometry[0, 2, y]
xData3 = geometry[0, 3, y]
anglesData = geometry[0, 4, y]
loop over the number of columns
for x in range(0, numCols):
if our score does not have sufficient probability,
ignore it
if scoresData[x] < args[“min_confidence”]:
continue
compute the offset factor as our resulting feature
maps will be 4x smaller than the input image
(offsetX, offsetY) = (x * 4.0, y * 4.0)
extract the rotation angle for the prediction and
then compute the sin and cosine
angle = anglesData[x]
cos = np.cos(angle)
sin = np.sin(angle)
use the geometry volume to derive the width and height
of the bounding box
h = xData0[x] + xData2[x]
w = xData1[x] + xData3[x]
compute both the starting and ending (x, y)-coordinates
for the text prediction bounding box
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
add the bounding box coordinates and probability score
to our respective lists
rects.append((startX, startY, endX, endY))
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









