







scrapy爬虫的流程
英语词汇
genspider:生成爬虫 itcast:传智播客
itcast.cn:传智播客的网址 deploy:部署
pipeline:管道
1.安装scrapy
pip install scrapy
2.创建项目
scrapy startproject myspider1

3.查看新建项目的根目录
ls

cd myspider1 #切换到mysider1目录下
tree myspider1/ #查看mysider1目录下的所有子目录及文件

4.创建爬虫
scrapy genspider 爬虫名字 允许爬取的域名(url)
例子:
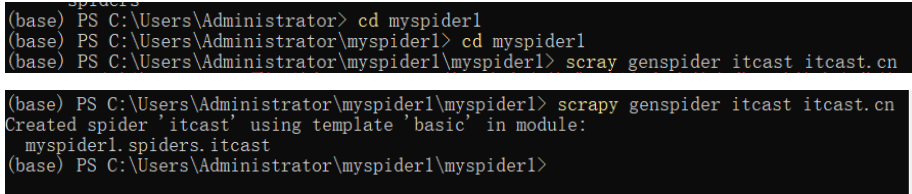
cd myspider1/ myspider1
scrapy genspider itcast itcast.cn
5.修改刚创建好的itcast文件中的源码

import scrapy
#定义爬虫类
class ItcastSpider(scrapy.Spider):
# 定义爬虫的名字
name = 'itcast'
# 域名进行链接
allowed_domains = ['itcast.cn']
# 爬虫起始的url,一般是自己修改
start_urls = ['http://itcast.cn/']
# 定义解析。从中获取网址的数据!!
# 定义对于网址的相关操作
def parse(self, response): # response所对应的start_urls
with open('itcase.html','wb') as f:
f.write(response.body)
6.运行 scrapy
命令:在项目目录下执行scrapy crawl 爬虫名字
生成日志文件: scrapy crawl itcast #crawl :爬取

7.ls命令查看生成的html文件

8.完成爬虫
itcast.py内部的源码:
修改起始的url
检查修改允许的域名
在parse方法中实现爬取逻辑
import scrapy
#定义爬虫类
class ItcastSpider(scrapy.Spider):
# 定义爬虫的名字
name = 'itcast'
#2.检查域名
allowed_domains = ['itcast.cn']
# 1.修改起始的url
start_urls = ['http://www.itcast.cn/channel/teacher.shtml#javaee']
#3.在parse方法中实现爬取逻辑
def parse(self, response): # response所对应的start_urls
#定义对于网站的相关操作
with open('itcase.html','wb') as f:
f.write(response.body)
1.1测试获取所有教师节点
在itcast文件中的parse方法内加入以下编码
# #爬取的网址:http://www.itcast.cn/channel/teacher.shtml#javaee
# 获取所有教师节点
# node_list = response.xpath('/html/body/div[10]/div/div[2]')
node_list = response.xpath('//div[@class="main_bot"]')
#遍历教师节点列表
print(len(node_list))
1.2在此项目的终端再次爬取此项目
scrapy crawl itcast
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8gBCxHIf-1619871487686)(pyProject1.assets/image-20210501163814176.png)]](https://img-blog.csdnimg.cn/20210501203324420.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0xhbnlLZXkxMQ==,size_16,color_FFFFFF,t_70)
1.3关闭日志文件
若找不到数字,就选中输入以下的命令,关闭日志文件
scrapy crawl itcast --nolog

2.1测试获取教师节点列表内的信息
#遍历教师节点列表
#print(len(node_list))
# 遍历每一个结点
for node in node_list:
# 创建一个字典
temp = {
}
# xpath方法返回的是选择器对象列 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1092
1092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









