







一:背景
在探究哈夫曼前,先来看一个生活实例:将学生的百分制成绩转为等级制,即
[90 , 100]为A;
[80 , 90)为B;
[70 , 80)为C;
[60 , 70)为D;
[0 , 60)为E。
代码实现为:
if (a < 60)
{
b = 'E';
}
else if (a < 70)
{
b = 'D';
}
else if (a < 80)
{
b = 'C';
}
else if (a < 90)
{
b = 'B';
}
else
{
b = 'A';
}我们把代码表现的更形象点,绘出它对应的判别树:
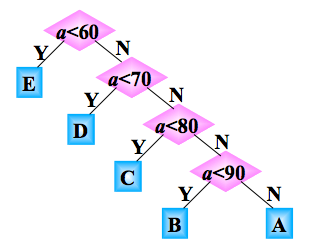
因为在实际生活中,学生的成绩在这5哥等级上的分布是不均匀的,假设其分布规律如下:
| 分数 | 0-59 | 60-69 | 70-79 | 80-89 | 90-100 |
| 比例 | 0.05 | 0.15 | 0.40 | 0.30 | 0.1 |
如果学生的总成绩数据有10000条,则5%的数据需 1 次比较,15%的数据需 2 次比较,40%的数据需 3 次比较,40%的数据需 4 次比较,因此 10000 个数据比较的
次数为: 10000 (5%+2×15%+3×40%+4×40%)=31500次
但是如果我们把判别树稍微修改下,也就是对等级的判断顺序改变下,又如何呢?
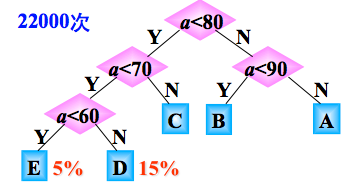
此种形状的二叉树,需要的比较次数是:10000 (3×20%+2×80%)=22000次,显然:两种判别树的效率是不一样的。
问题是能不能找到一种效率最高的判别树呢?
那就是接下来要讲的哈夫曼树。
二:哈夫曼树
哈夫曼树(Huffman),又叫最优树,是一类带权路径长度最短的树。
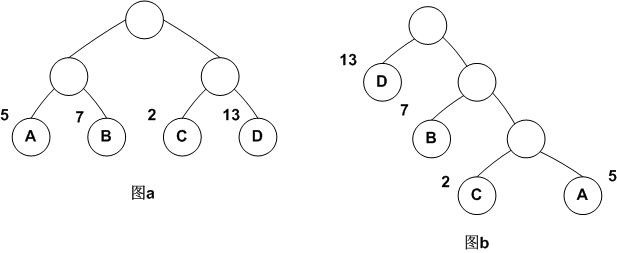
它们的带权路径长度分别为:
图a: WPL=5*2+7*2+2*2+13*2=54
图b: WPL=5*3+2*3+7*2+13*1=48
可见,图b的带权路径长度较小,我们可以证明图b就是哈夫曼树(也称为最优二叉树)。
那么我们如何构造哈夫曼树?
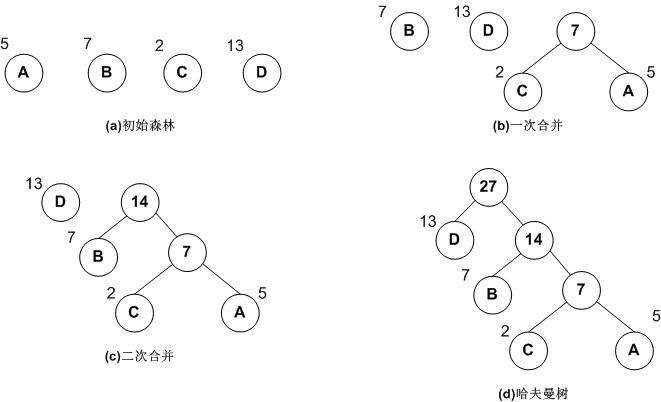
一般可以按下面步骤构建:
1:将所有左,右子树都为空的作为根节点。
2:在森林中选出两棵根节点的权值最小的树作为一棵新树的左,右子树,且置新树的附加根节点的权值为其左,右子树上根节点的权值之和。注意,左子树的权值应小于右子 树的权值。
3:从森林中删除这两棵树,同时把新树加入到森林中。
4:重复2,3步骤,直到森林中只有一棵树为止,此树便是哈夫曼树。
下面是构建哈夫曼树的图解过程:
三:哈夫曼编码
目前。进行快速远距离通信的主要手段是电报,即将需传送的文字转换长由二进制的字符组成的字符串。例如,假设需传送的电文为"ABACCDA",它只有4种字符,只需两个字符的串便可分辨。假设A,B,C,D的编码分别是00,01,10和11,则上述7个字符的电文便是“00010010101100”,总长14位,对方接收时,可按两位一分进行译码。
当然,在传送电文时希望电文长度尽可能的短。如果对每个字符设计长度不等的编码,且让电文中出现次数较多的字符采用尽可能短的编码,则传送的电文总长度便可减少。
如果设计A,B,C,D的编码是0,00,1,01,则上述7个字符可转化为长度为9的字符串“000011010”。但是,这样的电文无法翻译,例如传送过去的字符串中前4个字符的字串“0000”就有多种译法,或是“AAAA”,或是“ABA”,或是“BB”等等。因此,若要设计长短不等的编码,则必须满足:任意一个字符编码不是另一个字符编码的前缀,这种编码称前缀编码。
可以用二叉树来设计二进制的前缀编码,如此得到必是二进制前缀编码,读者可以自己证明;同时,我们可以利用设计一棵哈夫曼树的思想来使电文长度最短。
树中从根到每个叶子节点都有一条路径,对路径上的各分支约定指向左子树的分支表示”0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为各个叶子节点对应的字符编码。
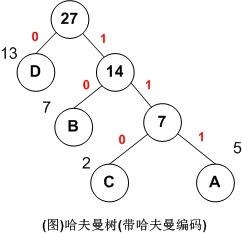
就拿上图例子来说:
A,B,C,D对应的哈夫曼编码分别为:111,10,110,0
用图说明如下:
四:哈夫曼编码实现
由于哈夫曼树中没有度为1的结点,则一棵有n个叶子的哈夫曼树共有2n-1个结点,可以用一个大小为2n-1 的一维数组存放哈夫曼树的各个结点。 由于每个结点同时还包含其双亲信息和孩子结点的信息,所以构成一个静态三叉链表。
#define _CRT_SECURE_NO_DEPRECATE
#define _CRT_SECURE_CPP_OVERLOAD_STANDARD_NAMES 1
#include<iostream>
#include<string>//use string
#include<string.h>//use strcpy
using namespace std;
typedef struct
{
char ch;
int weight;
int parent, lChild, rChild;
}HTNode, *HuffmanTree;//哈夫曼树
typedef char** HuffmanCode;//哈夫曼编码表
void Select(HuffmanTree & HT, int end, int & s1, int & s2);
void HuffmanCoding(HuffmanTree & HT, HuffmanCode & HC, int * w, char *ch, int n);
void HuffmanDecoding(HuffmanTree &HT, string text, int n);
int main()
{
//1.预期数据输入
int n;//字符集大小
int *w;//字符对应的权值
char *code;//n个字符
cout << "请输入字符集大小: ";
cin >> n;
w = new int[n];//申请内存
code = new char[n + 1];
cout << "请输入" << n << "个字符: ";
getchar();//注意这里
for (int i = 0; i < n; i++)
cin.get(code[i]);//可以读取空格
code[n] = '\0';
cout << "请输入字符对应的" << n << "个权值: ";
for (int i = 0; i < n; i++)
cin >> w[i];
//2.哈夫曼编码和译码
HuffmanTree myTree;
HuffmanCode myCode;
HuffmanCoding(myTree, myCode, w, code, n);
cout << "\n\n-----------------------------------------------------------------------\n";
cout << "编码为: \n";
for (int i = 0; i < n; i++)
cout << code[i] << "-----" << myCode[i] << endl;
cout << "\n\n-----------------------------------------------------------------------\n";
cout << "请输入编码进行解密译码: ";
string text;
cin >> text;
cout << "译码后明文是: ";
HuffmanDecoding(myTree, text, n);
cout << endl;
return 0;
}
/*
在HT[0...end]选择parent为0且weight最小的两个节点,其序号分别为是s1,s2(s1是最小weight节点的序号)
说白了,就是求出一个数组的最小的两个值的下标
*/
void Select(HuffmanTree & HT, int end, int & s1, int & s2)
{
int min1 = 99999999;
int min2 = 99999999;
for (int i = 0; i <= end; i++)
{
if (HT[i].parent == -1)
{
if (HT[i].weight < min1)
{
min1 = HT[i].weight;
s1 = i;
}
}
}
for (int i = 0; i <= end; i++)
{
if (HT[i].parent == -1)
{
if (s1!=i&&HT[i].weight < min2)//注意此处,应该是判断坐标而不是weight与min1判断,因为数组里可能有与min1相等的值
{
min2 = HT[i].weight;
s2 = i;
}
}
}
cout << s1 << " " << s2 << endl;
}
/* w存放n个字符的权值(均大于0),构造哈夫曼树HT,并求出n个字符的哈夫曼编码HC,ch数组存放n个字符 */
void HuffmanCoding(HuffmanTree & HT, HuffmanCode & HC, int * w, char * ch, int n)
{
if (n <= 1)
return;
int m = 2 * n - 1;
HT = new HTNode[m];
HuffmanTree p;
int i;
for (p = HT, i = 0; i < n; i++, p++, w++, ch++)//权值依次对应放入哈夫曼树
*p = { *ch,*w,-1,-1,-1 };
for (; i < m; i++, p++)
*p = { 0,-1,-1,-1,-1 };
int s1, s2;
for (i = n; i < m; i++)
{
Select(HT, i - 1, s1, s2);
HT[s1].parent = i;
HT[s2].parent = i;
HT[i].lChild = s1;
HT[i].rChild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
//从叶子到根逆向求每个字符的哈夫曼编码
int start;
HC = new char*[n];
char * cd = new char[n];
cd[n - 1] = '\0';
for (int i = 0; i < n; i++)
{
start = n - 1;
for (int c = i, f = HT[i].parent; f != -1; c = f, f = HT[f].parent)
{
if (HT[f].lChild == c)
cd[--start] = '0';
else
cd[--start] = '1';
}
HC[i] = new char[n - start];
strcpy(HC[i], &cd[start]);
}
delete[]cd;
}
/* 根据编译出的哈夫曼编码,译成字符明文 */
void HuffmanDecoding(HuffmanTree &HT, string text, int n)
{
int len = text.length();
int j = 2 * n - 2;
for (int i = 0; i < len; i++)
{
if (text[i] == '0')
j = HT[j].lChild;//走向左孩子
else
j = HT[j].rChild;//走向右孩子
if (HT[j].lChild == -1)//如果是叶节点
{
cout << HT[j].ch;
j = 2 * n - 2;//回到根节点
}
}
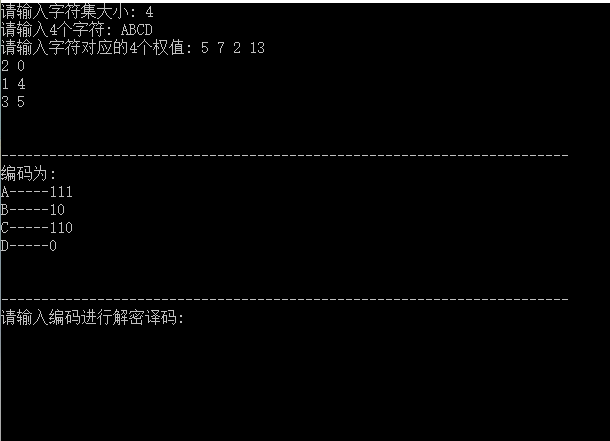
}运行截图:
图片资源,参考来自:http://www.cnblogs.com/mcgrady/p/3329825.html,http://www.cnblogs.com/kubixuesheng/p/4397798.html
返回目录---->数据结构与算法目录















 2957
2957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









