







为什么需要RedLock?
这一点很好理解,因为普通的分布式锁算法在加锁时它的KEY只会存在于某一个Redis Master实例以及它的slave上(假如有slave的话, 即使cluster集群模式,也是一样的。因为一个KEY只会属于一个slot,一个slot只会属于一个Redis节点),如下图所示(图中虚线表示cluster中gossip协议交互路径):
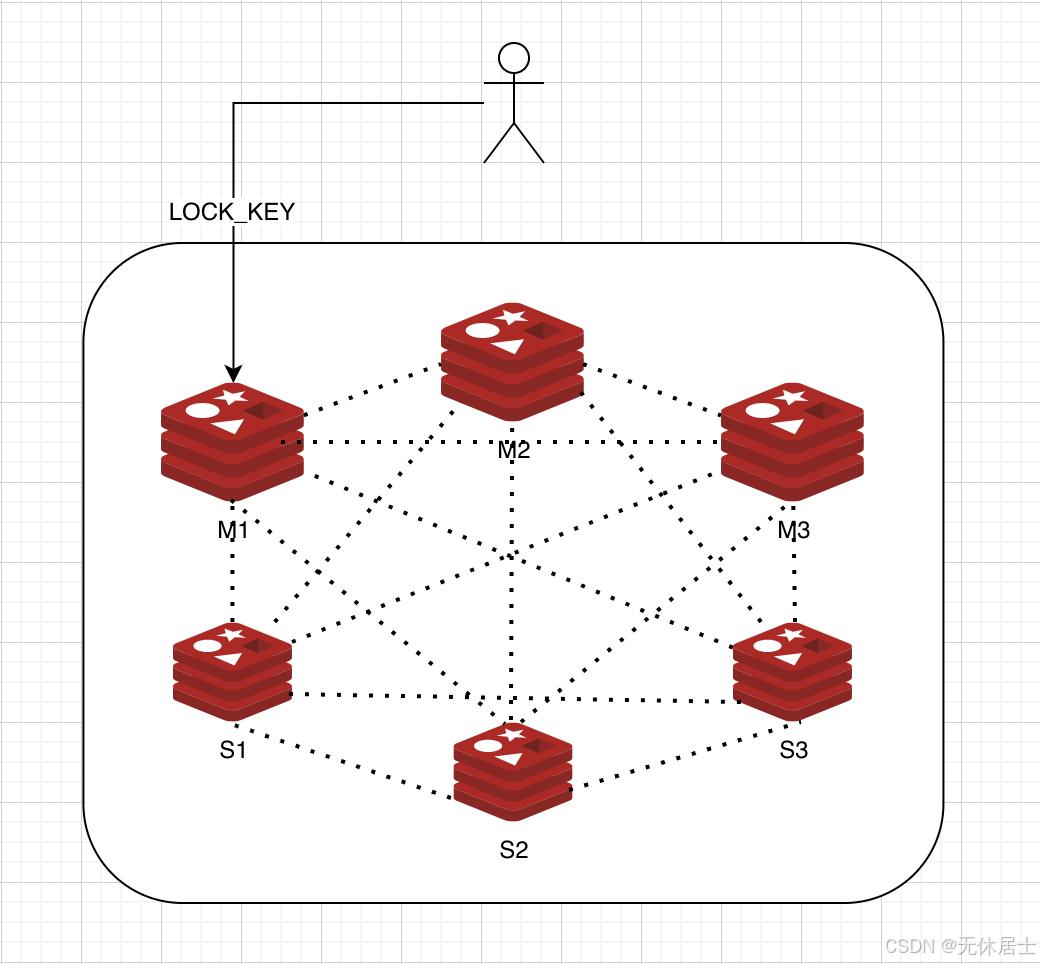
因为它只会存在于某一个Redis Master上,而Redis又不是基于CP模型的。那么就会有很大概率存在锁丢失的情况。以如下场景为例:
1、线程T1在M1中加锁成功。
2、M1出现故障,但是由于主从同步延迟问题,加锁的KEY并没有同步到S1上。
3、S1升级为Master节点。
4、另一个线程T2在S1上也加锁成功,从而导致线程T1和T2都获取到了分布式锁。
而RedLock方法就是根除普通基于Redis分布式锁而生的(无论是主从模式、sentinel模式还是cluster模式)!官方把RedLock方法当作使用Redis实现分布式锁的规范算法,并认为这种实现比普通的单实例或者基于Redis Cluster的实现更安全。
RedLock定义
首先,我们要掌握RedLock的第一步就是了解它的定义。这一点,官方网站肯定是最权威的。接下来的这段文字摘自 http://redis.cn/topics/distlock.html
在Redis的分布式环境中,我们假设有N个Redis Master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制(这句话非常重要,如果没有理解这句话,也就无法理解RedLock。并且由这句话我们可以得出,RedLock依赖的环境不能是一个由N主N从组成的Cluster集群模式,因为Cluster模式下的各个Master并不完全独立,而是存在Gossip协调机制的)。
接下来,我们假设有3个完全相互独立的Redis Master单机节点,所以我们需要在3台机器上面运行这些实例,如下图所示(请注意这张图中3个Master节点完全相互独立):
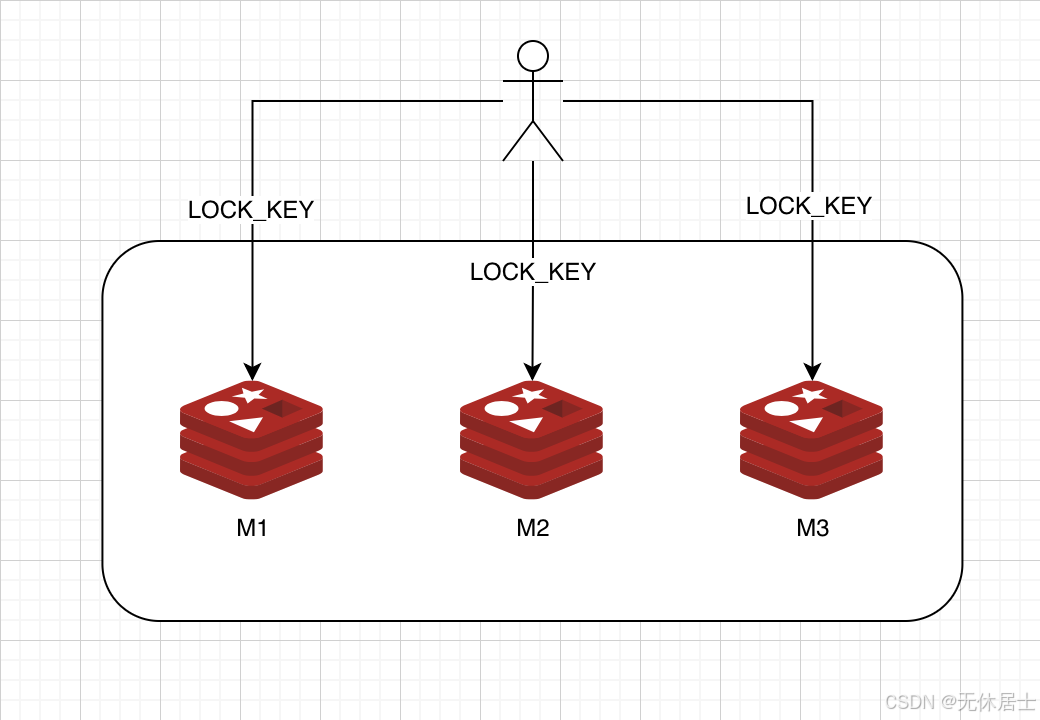
为了取到锁,客户端应该执行以下操作:
- 获取当前Unix时间,以毫秒为单位。
- 依次尝试从N个Master实例使用相同的key和随机值获取锁(假设这个key是LOCK_KEY)。当向Redis设置锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试另外一个Redis实例。
- 客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数的Redis节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功。
- 如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果)。
- 如果因为某些原因,获取锁失败(没有在至少N/2+1个Redis实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些Redis实例根本就没有加锁成功)。
基于Redisson实现RedLock
RedLock方案并不是很复杂,但是如果我们自己去实现一个工业级的RedLock方案还是有很多坑的。幸运的是,Redisson已经为我们封装好了RedLock的开源实现,假设基于3个单机Redis实例实现RedLock分布式锁,即第二张图所示的RedLock方案,其源码如下所示,非常简单:
Config config1 = new Config();
config1.useSingleServer().setAddress("redis://192.168.0.1:6379")
.setPassword("afeiblog").setDatabase(0);
RedissonClient redissonClient1 = Redisson.create(config1);
Config config2 = new Config();
config2.useSingleServer().setAddress("redis://192.168.0.2:6379")
.setPassword("afeiblog").setDatabase(0);
RedissonClient redissonClient2 = Redisson.create(config2);
Config config3 = new Config();
config3.useSingleServer().setAddress("redis://192.168.0.3:6379")
.setPassword("afeiblog").setDatabase(0);
RedissonClient redissonClient3 = Redisson.create(config3);
String resourceName = "LOCK_KEY";
RLock lock1 = redissonClient1.getLock(resourceName);
RLock lock2 = redissonClient2.getLock(resourceName);
RLock lock3 = redissonClient3.getLock(resourceName);
// 向3个redis实例尝试加锁
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
boolean isLock;
try {
// isLock = redLock.tryLock();
// 500ms拿不到锁, 就认为获取锁失败。10000ms即10s是锁失效时间。
isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS);
System.out.println("isLock = "+isLock);
if (isLock) {
//TODO if get lock success, do something;
}
} catch (Exception e) {
} finally {
// 无论如何, 最后都要解锁
redLock.unlock();
}
这段源码有几个要点:
- 首先需要构造N个RLock(源码中是3个,RLock就是普通的分布式锁)。
- 然后用这N个RLock构造一个RedissonRedLock,这就是Redisson给我们封装好的RedLock分布式锁(即N个相互完全独立的节点)。
- 调用unlock方法解锁,这个方法会向每一个RLock发起解锁请求(for (RLock lock : locks) {futures.add(lock.unlockAsync());})。
- 这段源码我们是基于3个完全独立的Redis单机实例来实现的(config1.useSingleServer())。当然,我们也可以基于3个完全独立的主从(config.useMasterSlaveServers()),或者3个完全独立的sentinel集群(config.useSentinelServers()),或者3个完全独立的Cluster集群(config.useClusterServers().)。
假如我们依赖3个完全独立的Cluster集群来实现ReLock方案,那么架构图如下所示:
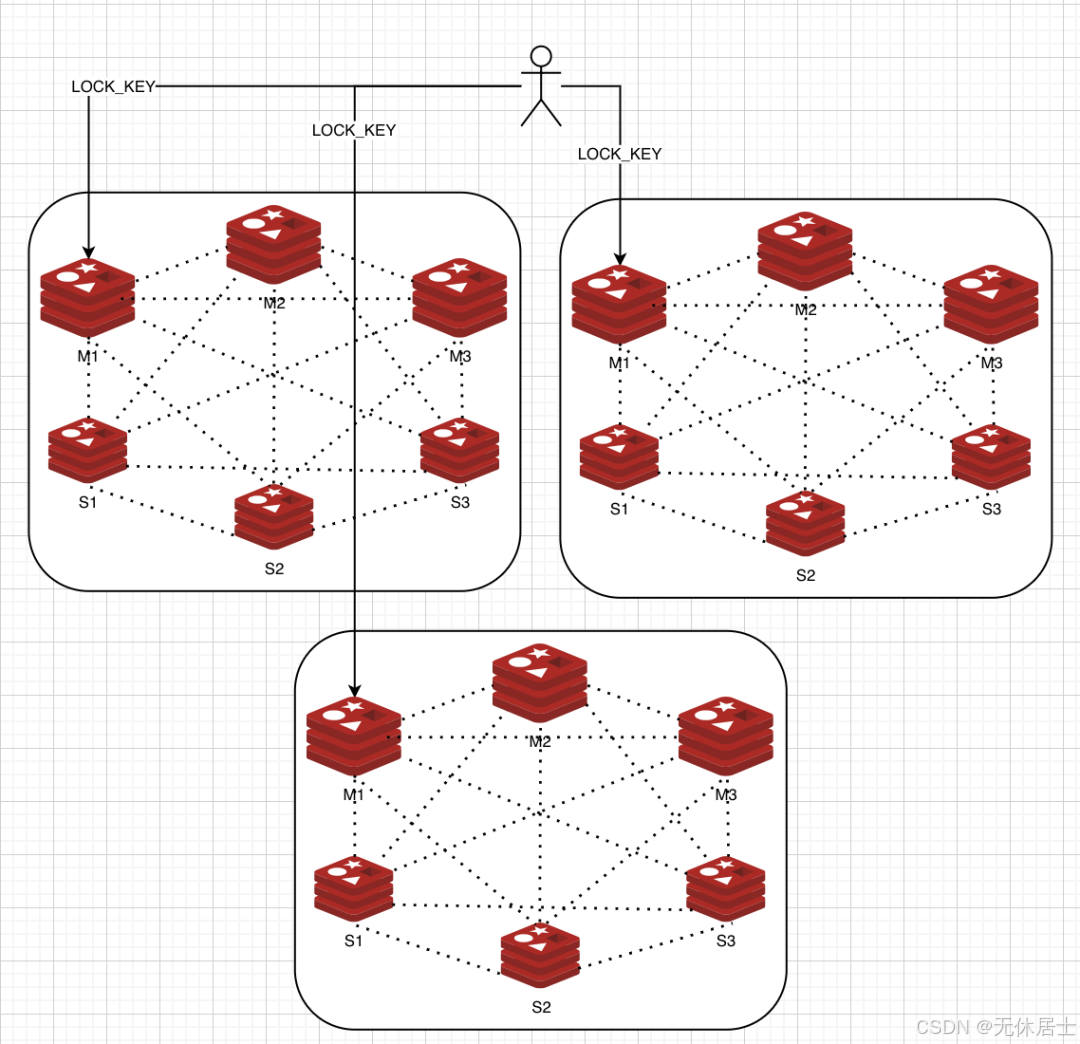
有些同学会反问,为什么需要3个Redis Cluster,一个行不行?回答这个问题之前,我们假设只有一个Redis Cluster,那么无论这个Cluster有多少个Master,我们是没办法让LOCK_KEY发送到多个Master上的,因为一个KEY只会属于Cluster中的一个Master,这一点也是没理解RedLock方案最容易犯的错误。
最后还有一个小小的注意点,Redis分布式锁加锁时value必须唯一,RedLock是怎么保证的呢?答案是UUID + threadId,源码如下:
protected final UUID id = UUID.randomUUID();
String getLockName(long threadId) {
return id + ":" + threadId;
}
写在最后
RedLock方案相比普通的Redis分布式锁方案可靠性确实大大提升。但是,任何事情都具有两面性,因为我们的业务一般只需要一个Redis Cluster,或者一个Sentinel,但是这两者都不能承载RedLock的落地。如果你想要使用RedLock方案,还需要专门搭建一套环境。所以,如果不是对分布式锁可靠性有极高的要求(比如金融场景),不太建议使用RedLock方案。当然,作为基于Redis最牛的分布式锁方案,你依然必须掌握的非常好,以便在有需要时(比如面试)能应付自如。



















 2020
2020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











